







在上一章节,介绍了使用传统机器学习算法来解决了文本分类问题,从本章开始将尝试使用深度学习方法,与传统机器学习不同,深度学习既提供特征提取功能,也可以完成分类的功能。
FastText是Facebook于2016年开源的一个词向量计算和文本分类工具,在学术上并没有太大创新。但是它的优点也非常明显,在文本分类任务中,FastText(浅层网络)往往能取得和深度网络相媲美的精度,却在训练时间上比深度网络快许多数量级。在标准的多核CPU上, 能够训练10亿词级别语料库的词向量在10分钟之内,能够分类有着30万多类别的50多万句子在1分钟之内。
FastText是一种典型的深度学习词向量的表示方法,它非常简单通过Embedding层将单词映射到稠密空间,然后将句子中所有的单词在Embedding空间中进行平均,进而完成分类操作。
所以FastText是一个三层的神经网络,输入层、隐含层和输出层。
一、预备知识
1、Softmax回归
Softmax回归(Softmax Regression)又被称作多项逻辑回归(multinomial logistic regression),它是逻辑回归在处理多类别任务上的推广。
在逻辑回归中, 我们有m个被标注的样本:
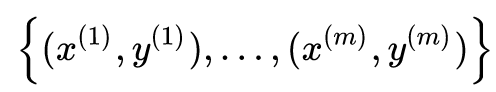
我们的假设(hypothesis)有如下形式:
![[公式]](https://img-blog.csdnimg.cn/20200727220440306.png)
代价函数(cost function)如下:
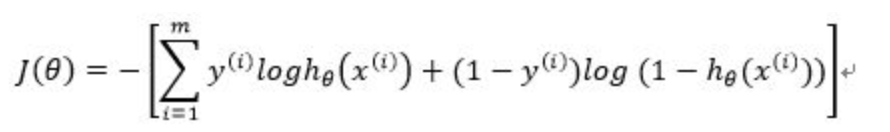 给定一个测试输入x,我们的假设应该输出一个K维的向量,向量内每个元素的值表示x属于当前类别的概率。具体地,假设形式如下:
给定一个测试输入x,我们的假设应该输出一个K维的向量,向量内每个元素的值表示x属于当前类别的概率。具体地,假设形式如下:

代价函数如下:
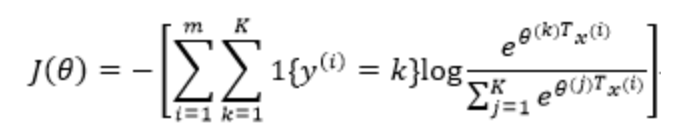
其中1{·}是指示函数,即1{true}=1,1{false}=0
既然我们说Softmax回归是逻辑回归的推广,那我们是否能够在代价函数上推导出它们的一致性呢?当然可以,于是:

2、分层Softmax
标准的Softmax回归中,要计算y=j时的Softmax概率,我们需要对所有的K个概率做归一化,这在|y|很大时非常耗时。于是,分层Softmax诞生了,它的基本思想是使用树的层级结构替代扁平化的标准Softmax,使得在计算时,只需计算一条路径上的所有节点的概率值,无需在意其它的节点。
下图是一个分层Softmax示例:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 6700
6700











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









