






1 前向分布算法

这样,前向分布算法将同时求解从m=1到M的所有参数βm, rm的优化问题简化为逐次求解各个βm, rm的优化问题。
2负梯度拟合
GBDT在函数空间中利用梯度下降法进行优化。在GBDT的迭代中,假设前一轮迭代得到的强学习器是ft-1(x)损失函数是L(y,ft-1(x)) 。本轮迭代的目标是找到一个CART回归树模型的弱学习器ht(x),让本轮的损失L(t,ft-1(x)+ht(x))最小。也就是说,本轮迭代找到决策树,要让样本的损失尽量变得更小。
3损失函数
对于分类算法,其损失函数一般有对数损失函数和指数损失函数两种。
对于回归算法,其损失函数一般有均方差、绝对损失、Huber损失、分位数损失四种。
4回归


5二分类
GBDT的分类算法从思想上和GBDT的回归算法没有区别,但是由于样本输出不是连续的值,而是离散的类别,导致我们无法直接从输出类别去拟合类别输出的误差。为了解决这个问题,主要有两个方法:用指数损失函数,此时GBDT退化为Adaboost算法;用类似于逻辑回归的对数似然损失函数的方法。

6正则化
和Adaboost一样,我们也需要对GBDT进行正则化,防止过拟合。GBDT的正则化主要有三种方式。
1.和Adaboost类似的正则化项,即步长(learning rate)。定义为ν,对于前面的弱学习器的迭代
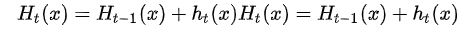
如果我们加上了正则化项,则有:
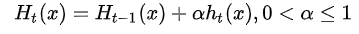
对于同样的训练集学习效果,较小的ν意味着我们需要更多的弱学习器的迭代次数。通常我们用步长和迭代最大次数一起来决定算法的拟合效果。
2.子采样比例(subsample,取值为(0,1]。
注意这里的子采样和随机森林不一样,随机森林使用的是放回抽样,而这里是不放回抽样。如果取值为1,则全部样本都使用,等于没有使用子采样。如果取值小于1,则只有一部分样本会去做GBDT的决策树拟合。选择小于1的比例可以减少方差,即防止过拟合,但是会增加样本拟合的偏差,因此取值不能太低。推荐在[0.5, 0.8]之间。
使用了子采样的GBDT有时也称作随机梯度提升树(Stochastic Gradient Boosting Tree, SGBT)。由于使用了子采样,程序可以通过采样分发到不同的任务去做boosting的迭代过程,最后形成新树,从而减少弱学习器难以并行学习的弱点。
3.对于弱学习器(即CART回归树)进行正则化剪枝。
7优缺点
优点:
预测阶段的计算速度快, 树与树之间可并行化计算。
在分布稠密的数据集上, 泛化能力和表达能力都很好, 这使得GBDT在Kaggle的众多竞赛中, 经常名列榜首。
采用决策树作为弱分类器使得GBDT模型具有较好的解释性和鲁棒性,能够自动发现特征间的高阶关系, 并且也不需要对数据进行特殊的预处理如归一化等。
局限性:
GBDT在高维稀疏的数据集上, 表现不如支持向量机或者神经网络。
GBDT在处理文本分类特征问题上, 相对其他模型的优势不如它在处理数值特征时明显。
训练过程需要串行训练, 只能在决策树内部采用一些局部并行的手段提高训练速度。
9总结
GBDT几乎可用于所有回归问题(线性/非线性),相对logistic regression仅能用于线性回归,GBDT的适用面非常广。GBDT还可用于二分类问题(设定阈值,大于阈值为正例,反之为负例)。















 793
793











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









