







背景
上次分享了《Dolphinscheduler配置Datax踩坑记录》,后有小伙伴私信问我说,在交换数据时,遇到hive分区表总是报错。结合实践案例的常见问题,我再记录一下datax读取hive分区表自定义配置的注意事项。
注意事项一:分区时间
在dolphinscheduler中是可以通过自定义参数设置指定分区时间的,时间声明格式为
- $[yyyyMMddHHmmss] 注意是中括弧
- 可以根据需求分解成 $[yyyyMMdd]
- 或 $[HHmmss]
- 也可以根据日期格式调整为$[yyyy-MM-dd]
- 也可以通过"+“、”-" 设置偏移量

- 代码中的变量名传参格式为:${变量名}
- 例如 ${statisdate}
- 注意是花括弧
注意事项二:分区目录
我们知道hive表是以文件的形式存储在HDFS中的,同时在读取hive表的配置脚本也是采用的"hdfsreader"。查看hdfs,我们可以看到分区表的文件目录名称不只是日期,而是分区字段和日的组合:“statis_date=2022-06-27”。
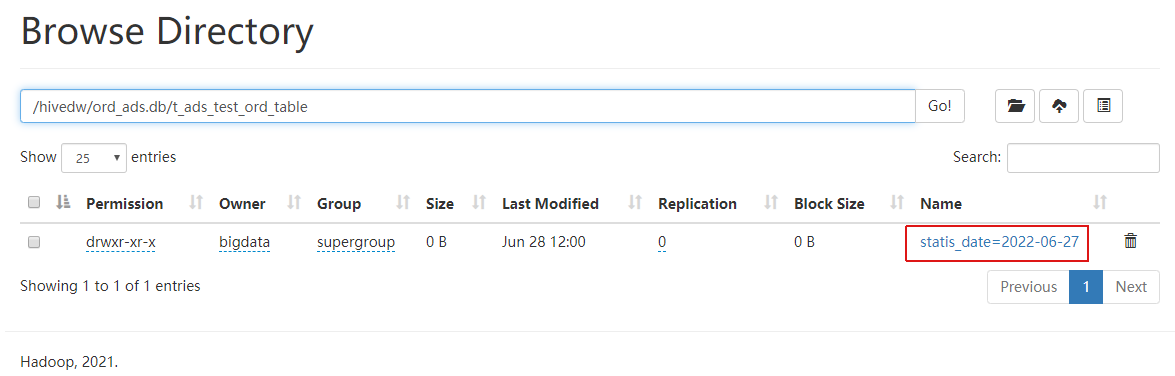
所以在脚本中reader我们这样配置:
"reader": {
"name": "hdfsreader",
"parameter": {
"column": [
{"index": 0,
"name": "ord_item_id",
"type": "string"
},
{"index": 1,
"name": "ord_id",
"type": "string"
},
{ "name": "statis_date",
"type": "string",
"value":"${statisdate}"
}
],
"defaultFS": "hdfs://hdfsnameservice",
"encoding": "UTF-8",
"fieldDelimiter": ",",
"fileType": "text",
"path": "/hivedw/ord_ads.db/t_ads_test_ord_table/statis_date=${statisdate}"
}
}
注意事项三:HDFS高可用(HA)
如上配置脚本中,当hdfs配置多台namenode采取高可用机制时,defaultFS地址可以直接配置成服务名称,但是要想让datax识别该名称地址,还需要将hdfs-site.xml和core-site.xml文件拷贝到hdfsreader-0.0.1-SNAPSHOT.jar中。
可以有两种方式:
- 一种可以将这两个文件放入源码的resources中,然后重新打包生成jar;
- 另一种方式是将安装文件下的jar拷贝出来,通过7zip等压缩文件查看器打开,将hdfs-site.xml和core-site.xml文件复制到jar包中
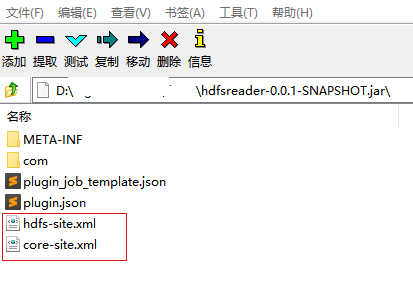
然后将原jar包备份,将新jar复制到原安装目录/datax/plugin/reader/hdfsreader下。
注意事项四:_SUCCESS文件
我们通过sparksql任务写入分区表数据后,在分区目录下会产生一个"_SUCCESS"文件
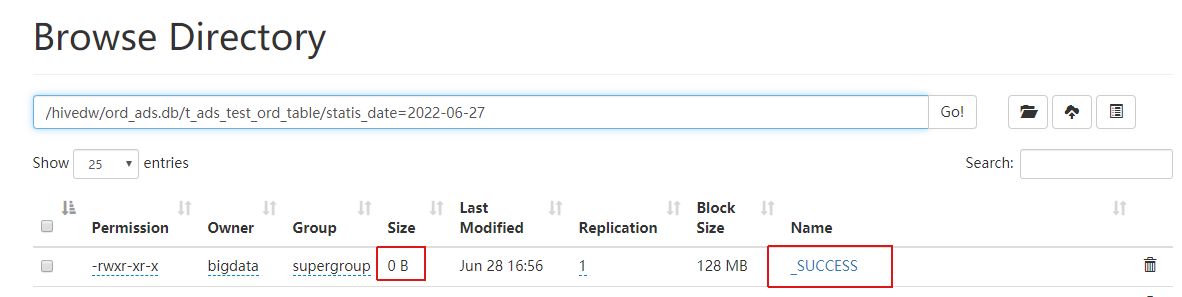
该文件没有数据,也不符合datax解析的格式,所以在调度任务运行时会提示异常:
ERROR HdfsReader$Job - 检查文件[hdfs://hdfsnameservice/hivedw/ord_ads.db/t_ads_test_ord_table/statis_date=2022-06-27/_SUCCESS]类型失败,目前支持ORC,SEQUENCE,RCFile,TEXT,CSV五种格式的文件,请检查您文件类型和文件是否正确。
Caused by: java.lang.IndexOutOfBoundsException: null
这个问题需要通过修改datax源码,跳过_SUCCESS文件,并重新打包hdfsreader-0.0.1-SNAPSHOT.jar。
修改com.alibaba.datax.plugin.reader.hdfsreader.DFSUtil类,对目录下的文件进行简单的判断,如果是"_SUCCESS"则跳过。
(7月1日测试任务又遇到分区目录空文件的问题,所以综合这两个问题,在注意事项五中,对源码一起修改,跳过空文件)
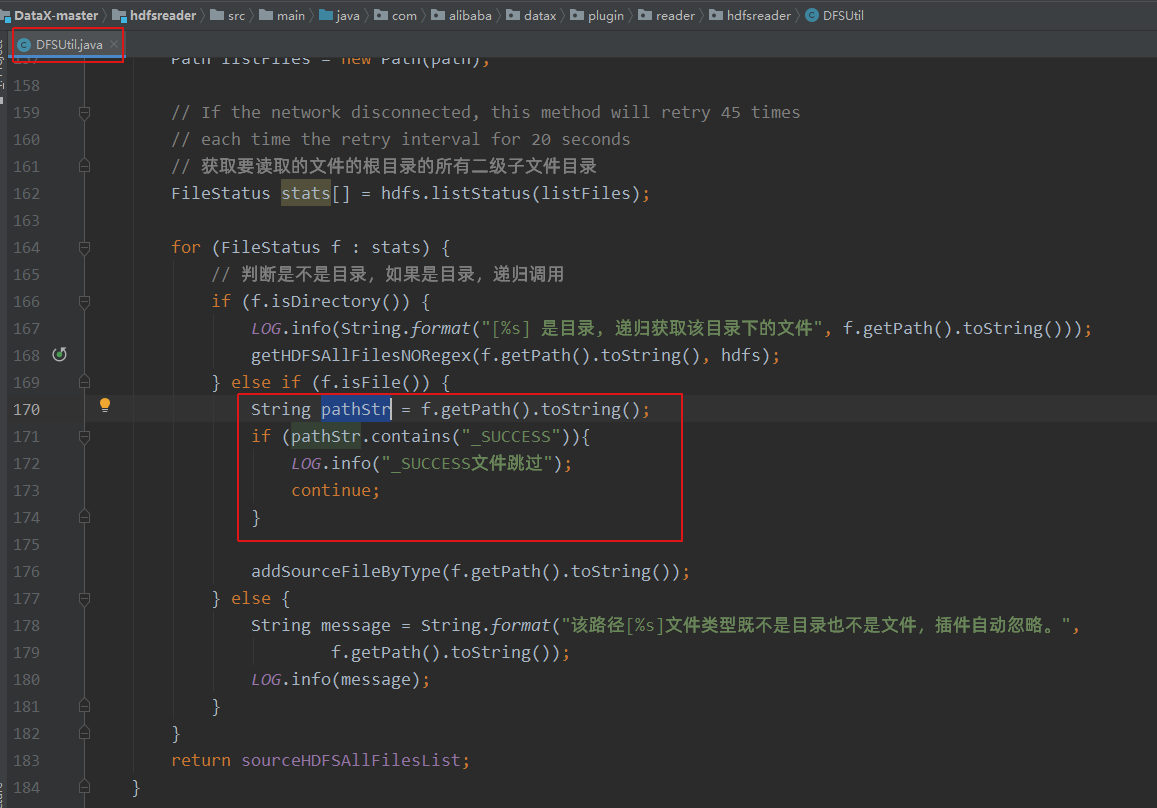
通过maven重新打包,因为hdfsreader模块依赖较多,单独打包可能会报错,可以直接对整个工程(datax-all)打包。
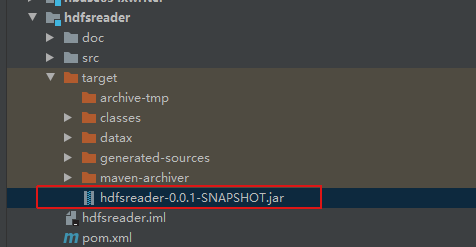
打包后,在target目录下找到hdfsreader-0.0.1-SNAPSHOT.jar对安装文件替换。(替换前注意上一条提到的hdfs-site.xml和core-site.xml文件是否被打进包里)
重新调度后,通过Dolphinscheduler任务实例日志我们可看到_SUCCESS文件被跳过了

注意事项五:空文件
除了上面的_SUCCESS文件,在实际开发过程中,sparlsql在reduce过程中在目录下会产生空的文件,datax同样会报错。

因此我们可以在上游任务对这种小文件进行处理,这里我们增加spark参数如下:
--开启调整partition功能,更好利用单个executor的性能,还能缓解小文件问题
set spark.sql.adaptive.enabled = true;
--防止分区过少而影响性能
set spark.sql.adaptive.minNumPostShufflePartitions = 4;
同时,为了保险起见,还可以通过datax的源码修改,避免文件为空的问题,(注意事项四中的_success文件也是因为文件为空,所以我们用一个通用逻辑一起解决)
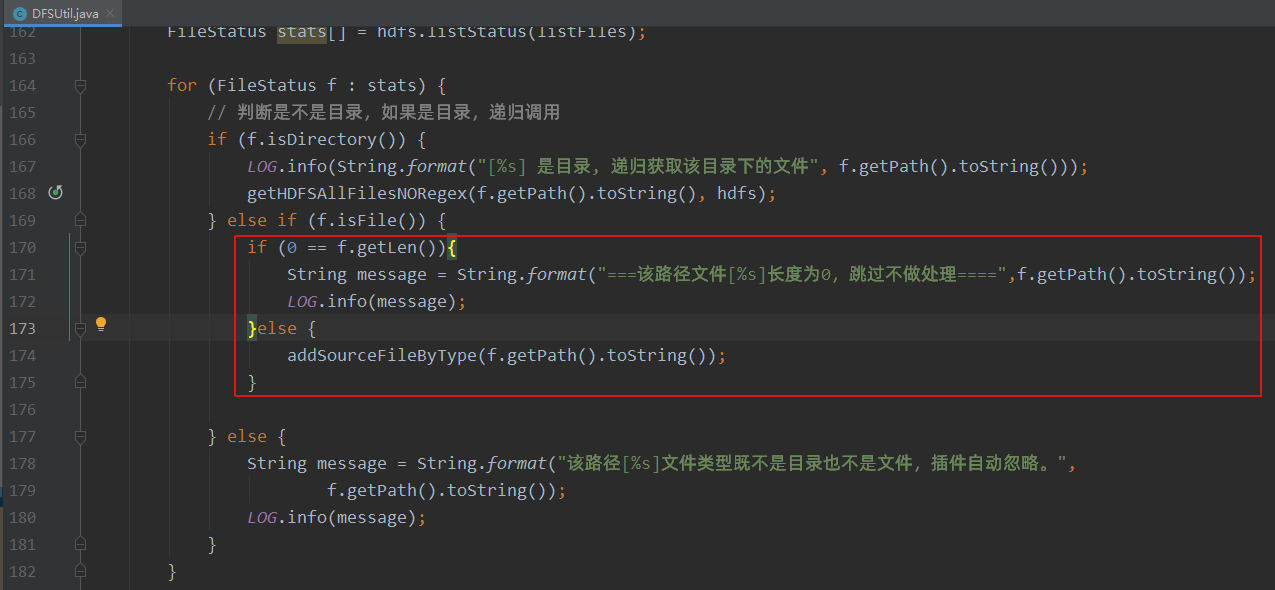
然后按照注意事项四的步骤重新打包生成hdfsreader-0.0.1-SNAPSHOT.jar文件。
任务运行后可以看到_SUCCESS文件同样可以跳过。















 3338
3338











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









