






文章目录
week48 IAGNN
摘要
本周阅读了题为Interaction-Aware Graph Neural Networks for Fault Diagnosis of Complex Industrial Processes的论文。该文提出了一种考虑传感器网络中多重交互的 IAGNN 模型,并将复杂工业的故障诊断问题转化为图分类任务。 IAGNN 通过注意力机制学习不同表示空间中节点之间的复杂交互,并引入独立的 GNN 块来提取基于交互的子图表示,并通过聚合模块融合它们以反映故障特征。 TFF 和 PS 数据集上的经验表明,所提出的 IAGNN 在每个故障类别上都取得了优异的结果。此外,还研究了自适应学习图的有效性以及边缘类型数量、GNN 块的深度、隐藏单元维度和 IAGNN-AT 聚合函数的嵌入维度的参数敏感性。
Abstract
This week’s weekly newspaper decodes the paper entitled Interaction-Aware Graph Neural Networks for Fault Diagnosis of Complex Industrial Processes. This paper proposes an IAGNN model that considers multiple interactions in sensor networks and transforms the fault diagnosis problem in complex industries into a graph classification task. IAGNN learns the complex interactions between nodes in different representation spaces through an attention mechanism and introduces independent GNN blocks to extract subgraph representations based on these interactions, which are then fused through an aggregation module to reflect fault characteristics. Empirical results on the TFF and PS datasets demonstrate that the proposed IAGNN achieves outstanding results for each fault category. Additionally, the study investigates the effectiveness of adaptive learning graphs and the parameter sensitivity of the number of edge types, the depth of GNN blocks, the dimension of hidden units, and the embedding dimension of the IAGNN-AT aggregation function.
0. 前言
本周学习侧重异构图,主要思路为通过GNN网络将节点间位置信息、各节点参数和节点类型相结合,从而提高预测的准确性。其次,该文还将GNN与自注意力机制结合,在这点上,可以侧重提高各环节处理前后的差异来用额外的方式补偿注意力机制所欠缺的可释性。对于各节点位置信息,可以考虑使用位置编码的方式将其作为一个额外的特征输入。
1. 题目
标题:Interaction-Aware Graph Neural Networks for Fault Diagnosis of Complex Industrial Processes
作者:Dongyue Chen , Ruonan Liu , Qinghua Hu, and Steven X. Ding
发布:IEEE TRANSACTIONS ON NEURAL NETWORKS AND LEARNING SYSTEMS, VOL. 34, NO. 9, SEPTEMBER 2023
链接:https://doi.org/10.1109/TNNLS.2021.3132376
代码链接:https://github.com/strawhatboy/IAGNN
2. Abstract
考虑到工业过程中传感器信号及其相互作用可以以节点和边的形式表示为图,该文提出了一种用于复杂工业过程故障诊断的新型交互感知和数据融合方法,称为交互感知图神经网络(IAGNN)。首先,为了描述工业过程中的复杂交互,传感器信号被转换为具有多种边缘类型的异构图,并且通过注意力机制自适应地学习边缘权重。然后,采用多个独立的图神经网络(GNN)块来提取具有一种边缘类型的每个子图的故障特征。最后,每个子图特征通过加权求和函数连接或融合以生成最终的图嵌入。因此,所提出的方法可以学习传感器信号之间的多重交互,并通过 GNN 的消息传递操作从每个子图中提取故障特征。最终的故障特征包含来自原始数据的信息和传感器信号之间的隐式交互。三相流设施和电力系统(PS)的实验结果证明了所提出的复杂工业过程故障诊断方法的可靠和优越性能。
3. 网络结构
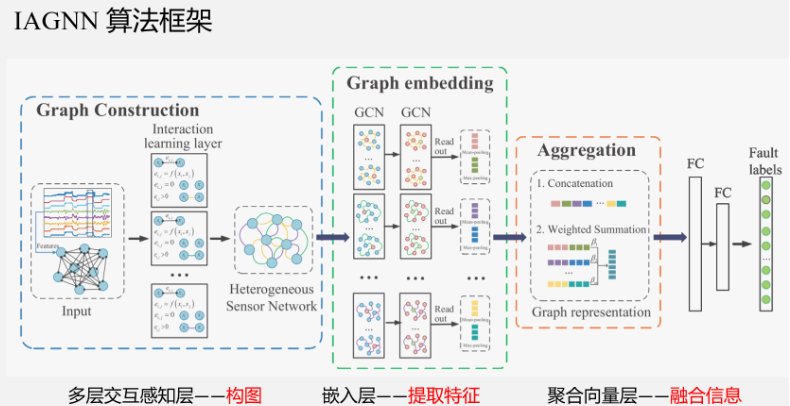
3.1 问题定义
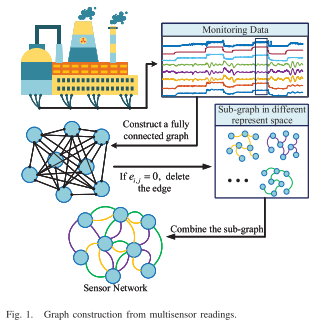
多元传感器信号被转换为图结构数据,图1显示了图构建过程的示例。
- 从工业过程中收集的多变量传感器信号将被分割成多个片段并形成 FC 图,图中每条边都有可学习的关系分数 e。
- 之后,FC图被导入交互感知层以学习与特征提取器联合训练的参数化关系分数。
- 最后,删除关系分数为零的边以获得稀疏图结构,这有利于GNN的训练效率和区分不同故障图的拓扑。
- 时间序列段:多个传感器的读数形成 n 个原始测量变量,这些长度为 t 的时间序列可以表示为 s i = ( s i 1 , . . . , s i t ) ∈ S s_i = (s^1_i , ... , s^t_i) ∈ S si=(si1,...,sit)∈S。时间序列可以被分割为段 ω j = ( s i t , . . . , s i t − m + 1 ) ∈ Ω ω_j = (s^t_i , ... , s^{t−m+1}_i)\in \Omega ωj=(sit,...,sit−m+1)∈Ω 通过大小为 m 的滑动窗口。窗口大小m根据时间序列的平稳性确定。由于传感器信号的短期平稳性,时间序列段作为输入来对图结构进行建模。
- 图:图被定义为 G = (V, E),顶点 v i ∈ V v_i ∈ V vi∈V,边 e i , j ∈ E e_{i, j} ∈ E ei,j∈E,其中节点和边都可以具有属性,记为 X ∈ R n × d n \mathbf X ∈ \mathbb R^{n×d_n} X∈Rn×dn 和 X e ∈ R c × d c \mathbf X^e ∈ \mathbb R^{c×d_c} Xe∈Rc×dc ,分别。采用邻接矩阵 A ∈ R n × n \mathbf A ∈ \mathbb R^{n×n} A∈Rn×n 记录 G 的拓扑结构。假设变量之间存在多种交互关系,将多元时间序列转换为图。本文将传感器网络设计为异构图 G = ( V , E , R E ) G=(V,E,R_E) G=(V,E,RE),其中 R E R_E RE表示边类型的集合,仅考虑一种类型的节点。将每个时间序列段 ω j ω_j ωj 的属性作为图中每个节点的特征向量 x j x_j xj 。值得注意的是,边缘属性 X e \mathbf X_e Xe是通过学习获得的。
GNN 将图 G 作为输入,其中节点和边分别与特征向量 xi 和 xe (i, j) 相关联。 L 层 GNN 中的消息传递操作有两个基本阶段:消息聚合和节点嵌入更新,可以定义如下:
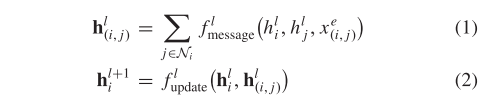
消息函数fmeassage和更新函数fupdate是参数函数并且分别在所有节点之间共享。每个节点嵌入包含来自其相邻节点的信息。
读出函数为
h
G
=
f
r
e
a
d
o
u
t
(
{
h
i
L
∣
v
∈
G
}
)
(3)
h_G=f_{readout}(\{h_i^L|v\in G\}) \tag{3}
hG=freadout({hiL∣v∈G})(3)
读出函数freadout可以是简单的排列不变函数,例如均值函数、求和函数等。
3.2 IAGNN
该框架是一个端到端的有监督的GNN模型,由三个基本部分组成并联合训练:
- 学习节点之间的成对关系,自动构建异构图;
- 针对异构图的不同边类型利用独立的GNN来获得统一的节点表示;
- 通过读出节点嵌入来获得图表示并对各种故障进行分类。
多层交互感知层
多层交互感知层实际上是一种构图方法。纵观全文,最重要的部分就是多层交互感知层,它为后面的GNN输入提供了初始数据——传感器异质图。具体做法如下:
-
基于传感器信号的平稳不变性,可以通过滑动窗口将多传感器信号截取成时间序列,滑动窗口大小基于信号的平稳性。所得时间序列,用于作为传感器异质图中的节点。
-
将(1)中所得节点,构成全连接图。
-
将全连接图输入至多层交互感知层中,进行边的筛减。多层交互感知层,是由注意力机制和特定的筛选函数Sparsemax组成的。
-
首先,各个全连接图中各节点之间使用注意力机制计算,得到连边的分数。
-
再通过筛选函数将低于一定分数阈值的边断开,从而形成第一种边类型的子图。以此类推,得到第二种边类型子图、第三种边类型子图等。
这种多视角的方法,是比较常见的,在Graph Transformer Network 中也有相似的处理。多视角是为了得到多种情况下的关联。
此处为超参,这里作者做了相关实验,多层交互感知层的层数控制在3-5层效果较好。
-
-
多层交互感知层最终得到的是多种边类型的子图。
因为这是一种自适应的构图方法,边是自动取筛选的。这也是性能提升的关键,因为对于复杂工程的故障诊断而言,故障是牵涉到多个传感器数据之间的相互作用的,简单的依靠先验知识构图,存在粒度不够,对于某些相似故障的区分度不够。全连接图冗余边信息过多,极大的影响了模型性能。KNN(K-nearest neighbor)只关注据局部特征,对于节点之间的复杂相互作用并没有考虑到。论文中还提到了MINE(Max Information Nonparametric Explore),这种手段,可以与KNN图进行互补。
该文使用sparsemax(·)函数[42]对所有节点之间的注意力系数进行归一化。SparseMax 变换返回输入到概率单纯形上的欧几里德投影,其具有与 SoftMax 函数类似的属性,但它可以返回稀疏概率分布。归一化关系分数$ e ∈ \mathbb R_n $定义为
e
=
sparsemax
(
r
)
sparsemax
(
r
i
,
j
p
)
=
max
{
0
,
r
i
,
j
p
−
τ
(
r
i
,
j
p
)
}
(5)
e=\text{sparsemax}(\mathbf r)\\ \text{sparsemax}(r^p_{i,j})=\max\{0,r^p_{i,j}-\tau(r^p_{i,j})\} \tag{5}
e=sparsemax(r)sparsemax(ri,jp)=max{0,ri,jp−τ(ri,jp)}(5)
算法 1 显示了稀疏最大变换过程。 SparseMax 变换保留了一些与 SoftMax 相同的属性

嵌入层
该模型使用的是最基础的GCN,因为,这个模型主要针对的是构图方法的改变,所以不注重特征提取的手段,使用其他的图神经网络模型,例如GAT,HAN都是可以的。在通过图神经网络更新完节点特征后,需要通过融合方法将各个节点的特征融合成最终的子图特征。这里的融合方法是,对整张子图做最大池化和平均池化,然后将两个池化向量做拼接,作为子图的特征向量。
GCN 是一个基于图的神经网络,具有消息传递操作,数学定义如下:
h
i
(
l
+
1
)
=
σ
(
∑
j
∈
N
(
i
)
c
j
i
h
j
(
l
)
W
(
l
)
+
b
(
l
)
)
(6)
\mathbf h^{(l+1)}_i=\sigma(\sum_{j\in \mathcal N(i)}c_{ji}\mathbf h^{(l)}_j\mathbf W^{(l)}+\mathbf b^{(l)})\tag{6}
hi(l+1)=σ(j∈N(i)∑cjihj(l)W(l)+b(l))(6)
对于每组时间序列片段,交互感知层提供一个带有边权重值的邻接矩阵 A,用于 GCN 特征提取。边权重 ei,j 揭示了节点 x j 对节点 xi 的重要性,尤其是在不同故障类别下。因此,边权重应该参与到GCN的消息传递过程中。如果提供每条边上的权重向量,则归一化常数
c
j
i
c_{ji}
cji 可以定义如下:
c
j
i
=
e
j
i
D
i
,
i
D
j
,
j
(7)
c_{ji}=\frac{e_{ji}}{\sqrt{D_{i,i}D_{j,j}}}\tag{7}
cji=Di,iDj,jeji(7)
GCN消息传递操作的矩阵形式如下:
H
(
l
+
1
)
=
σ
(
D
~
−
1
2
A
~
D
~
−
1
2
H
(
l
)
W
(
l
)
+
b
(
l
)
)
(8)
\mathbf H^{(l+1)}=\sigma(\mathbf{\tilde D}^{-\frac12}\mathbf{\tilde A}\mathbf{\tilde D}^{-\frac12}\mathbf H^{(l)}\mathbf W^{(l)}+\mathbf b^{(l)})\tag{8}
H(l+1)=σ(D~−21A~D~−21H(l)W(l)+b(l))(8)
聚合向量层
这里融合方法讨论了两种,一种是直接拼接的方法,但“由于故障差异并不明显”,得到的最终特征表示会加入很多冗余信息,所以考虑采用基于注意力的加权求和办法,这个不是重点,可以参看原文。最终得到的即为多传感器异质图向量,应用于故障诊断。
将上述方法组合有算法2

4. 文献解读
4.1 Introduction
基于上述分析,提出了一种智能流程工业故障诊断方法,称为交互感知图神经网络(IAGNN),该方法考虑图中传感器节点之间的多重交互,并使用GNN融合每个传感器测量的信息。具体来说,利用注意力机制来学习不同表示空间中的节点之间的关系分数,从而构建异构传感器网络。由于节点之间的实际关系很难建模,因此使用关系分数来指示节点之间交互的重要性。这些学习到的关系分数构成了图的边缘属性,为各种故障图提供了差异。异构图可以根据边类型划分为多个子图。然后,应用并行 GNN 块分别更新不同交互边类型的节点特征,并联合训练。读出更新的基于边类型的节点嵌入以获得子图表示。这些子图特征通过聚合函数传递以生成最终的图嵌入。因此,可以融合过程工业中测量的多变量时间序列以进行故障识别。
4.2 创新点
该文的主要贡献有四个方面:
- 本文将复杂工业过程的故障诊断问题表述为图分类问题。其关键思想是将多元传感器信号转化为具有各种边缘类型的异构图,并通过 GNN 的消息传递机制利用融合信号嵌入来对故障类型进行分类。
- 所提出的IAGNN框架提供了两个阶段:图构建阶段和判别特征提取阶段。在第一阶段,利用注意力机制构建考虑边类型多样性的图,并为各种故障类别提供区分的图拓扑。在第二阶段,通过融合多个独立 GNN 块的子图嵌入来获得判别特征。所提出的框架可以用作工业过程故障诊断的通用平台。
- 对两个工业过程进行了大量实验:三相流设施和 PS。实验结果表明,与最先进的方法相比,所提出的 IAGNN 框架可以提供更好的诊断结果。
4.3 实验过程
数据集:三相流设施模拟数据集和 PS 模拟数据集
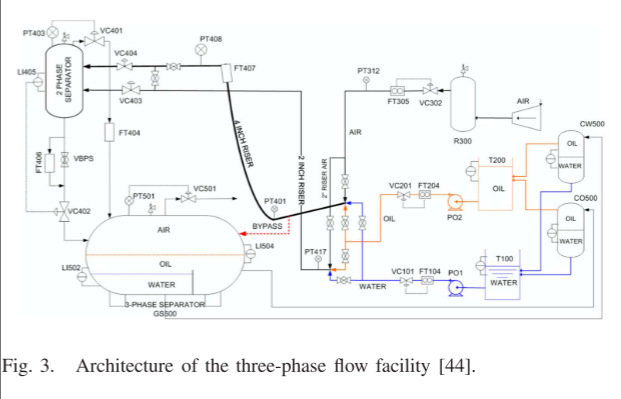
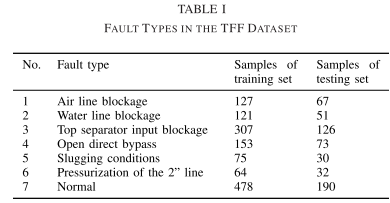
三相流设施数据:克兰菲尔德大学的三相流设施(TFF)[44]设计用于控制加压系统并测量水流量、油流量和空气流量,如图3所示。为了获得各种正常运行条件下的数据,在模拟中引入了20组过程输入,并获得了三个数据集。对于故障数据集,模拟了六种故障以指示实际中可能发生的典型故障。故障是在正常状态一定时间后引入的,当故障达到一定的严重程度时,故障状态被暂停,并恢复到正常状态。因此,每个故障情况都包含从弱状态到系列故障状态的数据。同时,在模拟过程中同时考虑了稳定条件和变化条件,并在一种故障类型下产生了多个数据集。采样频率为1Hz。通过最大-最小归一化来预处理每个传感器输出,其中 x = (x − xmin)/(xmax − xmin)。我们从故障数据集中去除正常数据,并取一段包含 50 s 信息的片段作为一个样本。然后我们混合故障状态和正常状态的所有样本,随机取70%的样本作为训练集,30%的样本作为测试集。表1显示了重新划分的数据集的故障类型和相应的样本数。
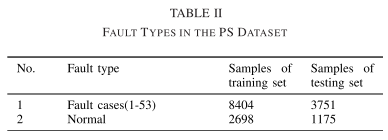
电力系统仿真数据:选择了53个典型故障案例和正常状态数据来评估所提方法的有效性。采样频率为4Hz。我们取一段包含 80 s 信息的片段作为一个样本。然后我们将不同类别的数据混合并分为分别包含70%样本和30%样本的训练集和测试集。表二分别显示了训练集和测试集的样本数量。
进行了大量的实验和分析来证明以下问题:
- 与其他最先进的方法相比,所提出的过程工业故障诊断方法的有效性;
- 学习到的异构图与固定图结构相比的有效性;
- 要学习的边缘类型数量、GNN块的深度、GNN块的隐藏单元维度以及加权求和聚合函数的嵌入维度的参数敏感性分析。
比较方法:为了验证所提出的 IAGNN 方法的性能,我们将我们的 IAGNN 方法与最先进的基线方法进行比较,包括故障诊断方法和基于图的方法。基线方法的详细信息如下。
- 1)PCA+LDA:PCA+LDA[45]-[47]是一种两阶段方法,其中第一阶段,原始数据的PCA降维,用于解决LDA的奇异性问题。
- 2)SR-CNN:SR-CNN[6]采用SR相关图像来反映故障特征的方差,并应用CNN分类器进行故障分类。
- 3)PTCN:PTCN[16]通过过程系统的物理连接构建图结构,并使用GCN来提取故障特征。
- 4)GAT:GAT根据节点特征学习边权重。如果我们没有将结构化数据转换成FC图,则可以直接应用GAT。
- 5)PKT-MCNN:PKT-MCNN[48]引入了一种用于大规模故障诊断的从粗到细的框架,其中使用故障类别的层次结构来指导多任务CNN模型的知识迁移。
实现细节:为了评估所提出方法的性能,本文采用微观F1分数和宏观F1分数。我们对所有基线方法和 IAGNN 模型进行了大量的实验,并选择可以获得最佳结果的超参数。 IAGNN 的学习率在 {0.0001, 0.0005, 0.001} 集合中调整,要学习的边缘类型数量从 1 到 8 进行采样。TFF 和 PS 的 IAGNN 模型都有两层 GNN 块。并且,对于TFF数据集,图有24个节点,初始特征大小为50,最大epoch为350,GCN和加权求和模块的隐藏大小为128,结构为{256, 128, 7}.对于PS数据集,图有76个节点,初始特征大小为20,最大epoch为300,GCN和加权求和模块的隐藏大小为512,结构为{1024, 512, 54}。所提出的 IAGNN 模型的超参数是根据性能和训练效率来选择的,这些设置用于将性能与基线方法进行比较。 V-E 节给出了更详细的参数敏感性实验。此外,所提出的方法是在配备 NVIDIA RTX 2080Ti 和 Xeon Silver 4214 CPU 的 PC 服务器上使用 PyTorch 几何实现的。
4.4 实验结果
故障分类性能 TFF和PS数据集的故障诊断结果如表3所示。
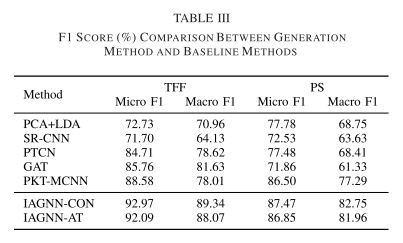
首先,与基线方法相比,IAGNN模型在TFF数据集上取得了最佳性能。最先进的结果表明,IAGNN 学习的多元时间序列嵌入可以有效地揭示流程工业的故障特征。
其次,通过与 SR-CNN 的性能比较,我们可以观察到 IAGNN 模型通过利用原始数据信息和节点之间的交互信息表现得更好。这表明有必要考虑不同传感器之间的复杂相互作用并将其嵌入到故障特征中。同时,可以观察到GAT优于PCA+LDA和SR-CNN方法,这表明GNN可以更有效地融合多个传感器信号的信息。
第三,IAGNN模型获得了比GAT和PTCN更好的性能,其原因可以从两个方面来说明:1)带有边权重而不进行稀疏操作的FC图会将边缘噪声引入到故障特征中,并获得固定的图结构通过系统物理连接无法从拓扑角度说明故障的差异;2)最终的故障特征包含来自不同表示空间的子图的信息,提高了故障诊断的性能。
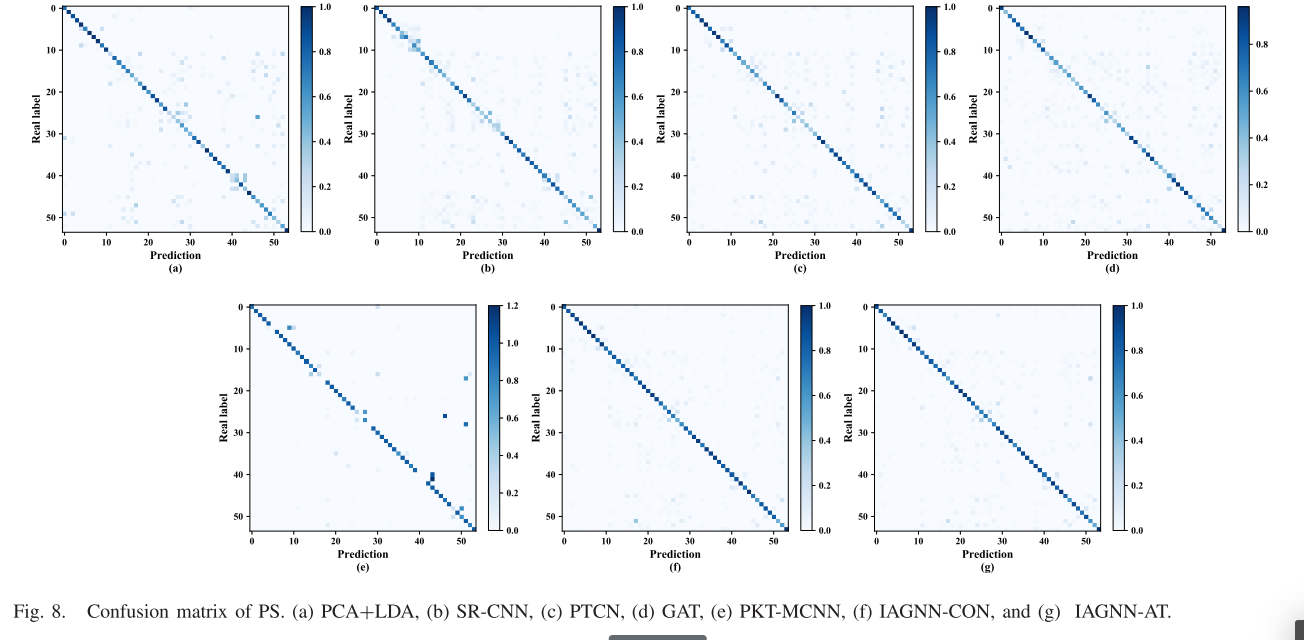
PS的混淆矩阵如图8所示。可以看出,IAGNN方法比基线方法具有更有效的故障诊断结果,这表明消息传递操作有利于具有多种交互作用的多个传感器信号的融合。大规模故障诊断任务的竞争结果进一步证实了所提方法的鲁棒性和有效性。
5. 结论
该文提出了一种考虑传感器网络中多重交互的 IAGNN 模型,并将复杂工业的故障诊断问题转化为图分类任务。 IAGNN 通过注意力机制学习不同表示空间中节点之间的复杂交互,并引入独立的 GNN 块来提取基于交互的子图表示,并通过聚合模块融合它们以反映故障特征。 TFF 和 PS 数据集上的经验表明,所提出的 IAGNN 在每个故障类别上都取得了优异的结果。此外,还研究了自适应学习图的有效性以及边缘类型数量、GNN 块的深度、隐藏单元维度和 IAGNN-AT 聚合函数的嵌入维度的参数敏感性。
6.代码复现
IAGNN
from typing import Dict
import torch as th
import torch.nn as nn
import torch.nn.functional as TFn
from dgl.utils import expand_as_pair
import dgl.function as fn
import dgl
import dgl.nn.pytorch as gnn
from dgl.nn.functional import edge_softmax
import math
import dgl.ops as F
from skip_edge_gnn import HeteroGraphConv
class IAGNN(nn.Module):
'''
Intention Adaptive Graph Neural Network
----
try to introduce the position embedding on edge v2i
Original 4 types of links (CDS Graph):\n
1. user-item in Domain A.
2. user-item in Domain B.
3. seq items in Domain A.
4. seq items in Domain B.
'''
def __init__(self,
num_class,
embedding_dim,
num_layers,
device,
batch_norm=True,
add_loss=False,
feat_drop=0.0,
attention_drop=0.0,
tao=1.0,
vinitial_type='mean',
graph_feature_select='gated',
pooling_type='last',
predictor_type='matmul'):
super(IAGNN, self).__init__()
self.embedding_dim = embedding_dim
self.aux_factor = 2 # hyper-parameter for aux information size
self.auxemb_dim = int(self.embedding_dim // self.aux_factor)
self.item_embedding = nn.Embedding(num_class['item'],
embedding_dim,
max_norm=1)
self.cate_embedding = nn.Embedding(num_class['cate'],
embedding_dim,
max_norm=1)
self.pos_embedding = nn.Embedding(num_class['pos'], self.auxemb_dim)
self.num_layers = num_layers # hyper-parameter for gnn layers
self.add_loss = add_loss
self.batch_norm = nn.BatchNorm1d(embedding_dim *
2) if batch_norm else None
self.readout = AttnReadout(
embedding_dim,
self.auxemb_dim,
embedding_dim,
pooling_type=pooling_type,
tao=tao,
batch_norm=batch_norm,
feat_drop=feat_drop,
activation=nn.PReLU(embedding_dim),
)
self.finalfeature = FeatureSelect(embedding_dim, type=graph_feature_select)
self.gnn_layers = nn.ModuleList()
for i in range(num_layers):
self.gnn_layers.append(
HeteroGraphConv({
# 'e':
# GATConv(embedding_dim,
# embedding_dim,
# feat_drop=feat_drop,
# attn_drop=attention_drop),
# 'e2':
# GATConv(embedding_dim,
# embedding_dim,
# feat_drop=feat_drop,
# attn_drop=attention_drop),
'i2i':
GATConv(embedding_dim,
embedding_dim,
feat_drop=feat_drop,
attn_drop=attention_drop),
'i2v':
GATConv(embedding_dim,
embedding_dim,
feat_drop=feat_drop,
attn_drop=attention_drop),
'v2v':
GATConv(embedding_dim,
embedding_dim,
feat_drop=feat_drop,
attn_drop=attention_drop),
'v2i':
GATConv(embedding_dim,
embedding_dim,
feat_drop=feat_drop,
attn_drop=attention_drop),
'c2c':
GATConv(embedding_dim,
embedding_dim,
feat_drop=feat_drop,
attn_drop=attention_drop),
'c2i':
GATConv(embedding_dim,
embedding_dim,
feat_drop=feat_drop,
attn_drop=attention_drop),
'i2c':
GATConv(embedding_dim,
embedding_dim,
feat_drop=feat_drop,
attn_drop=attention_drop),
}))
self.gnn_maxpooling_layer = HeteroGraphConv({
'mp': MaxPoolingLayer(),
})
# W_h_e * (h_s || e_u) + b
self.W_pos = nn.Parameter(
th.Tensor(embedding_dim * 2 + self.auxemb_dim, embedding_dim))
self.W_hs_e = nn.Parameter(th.Tensor(embedding_dim * 2, embedding_dim))
self.W_h_e = nn.Parameter(th.Tensor(embedding_dim * 3, embedding_dim))
self.W_c = nn.Parameter(
th.Tensor(embedding_dim * 2, embedding_dim))
self.feat_drop = nn.Dropout(feat_drop)
self.fc_sr = nn.Linear(embedding_dim * 2, embedding_dim, bias=False)
self.reset_parameters()
self.indices = nn.Parameter(th.arange(num_class['item'],
dtype=th.long),
requires_grad=False)
def reset_parameters(self):
stdv = 1.0 / math.sqrt(self.embedding_dim)
for weight in self.parameters():
weight.data.uniform_(-stdv, stdv)
def feature_encoder(self, g: dgl.DGLHeteroGraph, next_cid: th.Tensor):
iid = g.nodes['i'].data['id']
vid = g.nodes['v'].data['id']
cid = g.nodes['c'].data['id']
# store the embedding in graph
g.update_all(fn.copy_e('pos', 'ft'),
fn.min('ft', 'f_pos'),
etype='v2i')
pos_emb = self.pos_embedding(g.nodes['i'].data['f_pos'].long())
cat_emb = th.cat([
self.item_embedding(iid), pos_emb,
self.cate_embedding(g.nodes['i'].data['cate'])
],
dim=1)
g.nodes['i'].data['f'] = th.matmul(cat_emb, self.W_pos)
g.nodes['v'].data['f'] = self.cate_embedding(vid)
g.nodes['c'].data['f'] = self.cate_embedding(cid)
# th.cat([self.cate_embedding(cid), pos_emb], dim=-1), self.W_c)
return self.cate_embedding(next_cid)
def forward(self, g: dgl.DGLHeteroGraph, next_cid: th.Tensor):
'''
Args:
----
g (dgl.DGLHeteroGraph): a dgl.batch of HeteroGraphs
next_cid (th.Tensor): a batch of next category ids [bs, 1]
'''
next_cate = self.feature_encoder(g, next_cid)
# main multi-layer GNN
h = [{
'i': g.nodes['i'].data['f'],
'v': g.nodes['v'].data['f'],
'c': g.nodes['c'].data['f']
}] # a list feat record for every layers
for i, layer in enumerate(self.gnn_layers):
out = layer(g, (h[-1], h[-1]))
h.append(out)
# h[-1]['v']: [bs*1, 1, embsize]
# h[-1]['i']: [items_len_in_bs, 1, embsize]
# g.nodes['i'].data['cate']: [items_len_in_bs]
last_nodes = g.filter_nodes(lambda nodes: nodes.data['last'] == 1,
ntype='i') # index array
last_cnodes = g.filter_nodes(lambda nodes: nodes.data['clast'] == 1, ntype='c')
seq_last_nodes = g.filter_nodes(
lambda nodes: nodes.data['seq_last'] == 1,
ntype='i') # index array
seq_last_cnodes = g.filter_nodes(
lambda nodes: nodes.data['seq_clast'] == 1,
ntype='c') # index array
# get max of item feat in the category sequence
# max_pooling_result = self.gnn_maxpooling_layer(g, (h[-1], h[-1])) # [items_len_in_bs, 1, embsize]
# h_s = max_pooling_result['i'][last_nodes].squeeze() # [bs, embsize]
# try gated feat
feat = self.finalfeature(h)
# use last item feat in the category sequence
h_c = feat['i'][last_nodes].squeeze() # [bs, embsize]
# also add seq last
h_s = feat['i'][seq_last_nodes].squeeze() # [bs, embsize]
gate = th.sigmoid(th.matmul(th.cat((h_c, h_s), 1), self.W_hs_e))
h_all = gate * h_c + (1 - gate) * h_s
feat_last_cate = feat['c'][last_cnodes].squeeze()
feat_seq_last_cate = feat['c'][seq_last_cnodes].squeeze()
c_gate = th.sigmoid(th.matmul(th.cat((feat_last_cate, feat_seq_last_cate), 1), self.W_c))
c_all = c_gate * feat_last_cate + (1 - c_gate) * feat_seq_last_cate
feat_next_cate = feat['v'].squeeze()
all_feat = th.matmul(th.cat((h_all, c_all, feat_next_cate), 1),
self.W_h_e) # [bs, embsize]
cand_items = self.item_embedding(self.indices)
# cosine predictor
scores1 = th.matmul(all_feat, cand_items.t())
scores1 = scores1 / th.sqrt(th.sum(cand_items * cand_items,
1)).unsqueeze(0).expand_as(scores1)
return scores1, feat['v'], g.batch_num_nodes('i')
class MaxPoolingLayer(nn.Module):
'''
for edge type 'mp' (maxpooling), make a 'max pooling' update
'''
def __init__(self):
super(MaxPoolingLayer, self).__init__()
def forward(self, g: dgl.DGLHeteroGraph, feat: Dict):
with g.local_scope():
g.srcdata.update({'ft': feat[0]})
g.update_all(fn.copy_u('ft', 'f_m'), fn.max('f_m', 'f_max'))
return g.dstdata['f_max']
class V2I_models(nn.Module):
def __init__(self,
in_dim: int,
aux_dim: int,
out_dim: int,
attn_drop: float = 0.1,
negative_slope: float = 0.2):
super(V2I_models, self).__init__()
self.W = nn.Linear(in_dim + aux_dim * 1, out_dim)
self.W_extract_pos = nn.Linear(aux_dim * 1, out_dim)
self.leaky_relu = nn.LeakyReLU(negative_slope)
self.attn_drop = nn.Dropout(attn_drop)
def forward(self, g: dgl.DGLHeteroGraph, feat: Dict):
srcdata = feat[0]
dstdata = feat[1]
with g.local_scope():
g.srcdata.update({'ft': srcdata})
g.dstdata.update({'ft': dstdata})
e = self.leaky_relu(g.edata.pop('p'))
# compute softmax
g.edata['a'] = self.attn_drop(edge_softmax(g, e))
g.edata['a'] = self.W_extract_pos(g.edata['a'])
# message passing
g.update_all(fn.u_mul_e('ft', 'a', 'm'), fn.sum('m', 'ft'))
rst = th.unsqueeze(g.dstdata['ft'], dim=1)
return rst
class FeatureSelect(nn.Module):
def __init__(self, embedding_dim, type='last'):
super().__init__()
self.embedding_dim = embedding_dim
assert type in ['last', 'mean', 'gated']
self.type = type
self.W_g1 = nn.Linear(2 * self.embedding_dim, self.embedding_dim)
self.W_g2 = nn.Linear(2 * self.embedding_dim, self.embedding_dim)
self.W_g3 = nn.Linear(2 * self.embedding_dim, self.embedding_dim)
def forward(self, h):
h[0]['i'] = h[0]['i'].squeeze()
h[-1]['i'] = h[-1]['i'].squeeze()
h[0]['v'] = h[0]['v'].squeeze()
h[-1]['v'] = h[-1]['v'].squeeze()
h[0]['c'] = h[0]['c'].squeeze()
h[-1]['c'] = h[-1]['c'].squeeze()
feature = None
if self.type == 'last':
feature = h[-1]
elif self.type == 'gated':
gate = th.sigmoid(self.W_g1(th.cat([h[0]['i'], h[-1]['i']], dim=-1)))
ifeature = gate * h[0]['i'] + (1 - gate) * h[-1]['i']
gate = th.sigmoid(self.W_g2(th.cat([h[0]['v'], h[-1]['v']], dim=-1)))
vfeature = gate * h[0]['v'] + (1 - gate) * h[-1]['v']
gate = th.sigmoid(self.W_g3(th.cat([h[0]['c'], h[-1]['c']], dim=-1)))
cfeature = gate * h[0]['c'] + (1 - gate) * h[-1]['c']
feature = {'i': ifeature, 'v': vfeature, 'c': cfeature}
# feature = {'i': ifeature, 'v': h[-1]['v'], 'c': h[-1]['c']}
elif self.type == 'mean':
isum = th.zeros_like(h[0]['i'])
vsum = th.zeros_like(h[0]['v'])
csum = th.zeros_like(h[0]['c'])
for data in h:
isum += data['i']
vsum += data['v']
csum += data['c']
feature = {'i': isum / len(h), 'v': vsum / len(h), 'c': csum / len(h)}
return feature
class AttnReadout(nn.Module): # todo:需要对cross domain进行建模
"""
Graph pooling for every session graph
"""
def __init__(
self,
item_dim,
aux_dim,
output_dim,
pooling_type='input',
tao=1.0,
batch_norm=True,
feat_drop=0.0,
activation=None,
):
super().__init__()
self.batch_norm = nn.BatchNorm1d(item_dim) if batch_norm else None
self.feat_drop = nn.Dropout(feat_drop)
self.w_feature = nn.Parameter(
th.Tensor(item_dim + aux_dim * 1, output_dim))
self.fc_u = nn.Linear(output_dim, output_dim, bias=False)
self.fc_v = nn.Linear(output_dim, output_dim, bias=True)
self.fc_e = nn.Linear(output_dim, 1, bias=False)
self.fc_out = (nn.Linear(item_dim, output_dim, bias=False)
if output_dim != item_dim else None)
self.activation = activation
self.tao = tao
assert pooling_type in ['ilast', 'imean', 'cmean', 'cnext', 'input']
self.pooling_type = pooling_type
def maxpooling_feat(self, g: dgl.DGLHeteroGraph, gfeat):
pass
# @torchsnooper.snoop()
def forward(self, g, gfeat, next_cate):
'''
Args:
----
feat (torch.Tensor[bs, embsize]): input feature as anchor
'''
# ifeat, vfeat = self.maxpooling_feat(g, gfeat)
ifeat, vfeat = gfeat['i'], gfeat['v']
ifeat_u = self.fc_u(ifeat)
anchor_feat = None
if self.pooling_type == 'ilast': # Get the last node as anchor
last_nodes = g.filter_nodes(lambda nodes: nodes.data['last'] == 1,
ntype='i')
anchor_feat = ifeat[last_nodes]
elif self.pooling_type == 'imean':
anchor_feat = F.segment.segment_reduce(g.batch_num_nodes('i'),
ifeat, 'mean')
elif self.pooling_type == 'cnext':
next_nodes = g.filter_nodes(lambda nodes: nodes.data['next'] == 1,
ntype='v')
anchor_feat = vfeat[next_nodes]
elif self.pooling_type == 'cmean':
anchor_feat = F.segment.segment_reduce(
g.batch_num_nodes('v'), vfeat, 'mean') # Todo:多个virtual node
feat_v = self.fc_v(anchor_feat)
feat_v = dgl.broadcast_nodes(g, feat_v, ntype='i')
e = self.fc_e(th.sigmoid(ifeat_u + feat_v))
alpha = F.segment.segment_softmax(g.batch_num_nodes('i'), e / self.tao)
feat_norm = ifeat * alpha
rst = F.segment.segment_reduce(g.batch_num_nodes('i'), feat_norm,
'sum')
if self.fc_out is not None:
rst = self.fc_out(rst)
if self.activation is not None:
rst = self.activation(rst)
rst = th.cat([rst, anchor_feat], dim=1)
return rst
class GATConv(nn.Module):
def __init__(self,
in_feats,
out_feats,
num_heads=1,
feat_drop=0.1,
attn_drop=0.1,
negative_slope=0.2,
residual=True,
activation=None,
allow_zero_in_degree=True,
bias=True):
super(GATConv, self).__init__()
self._num_heads = num_heads
self._in_src_feats, self._in_dst_feats = expand_as_pair(in_feats)
self._out_feats = out_feats
self._allow_zero_in_degree = allow_zero_in_degree
if isinstance(in_feats, tuple):
self.fc_src = nn.Linear(self._in_src_feats,
out_feats * num_heads,
bias=False)
self.fc_dst = nn.Linear(self._in_dst_feats,
out_feats * num_heads,
bias=False)
else:
self.fc = nn.Linear(self._in_src_feats,
out_feats * num_heads,
bias=False)
self.attn_l = nn.Parameter(
th.FloatTensor(size=(1, num_heads, out_feats)))
self.attn_r = nn.Parameter(
th.FloatTensor(size=(1, num_heads, out_feats)))
self.feat_drop = nn.Dropout(feat_drop)
self.attn_drop = nn.Dropout(attn_drop)
self.leaky_relu = nn.LeakyReLU(negative_slope)
if bias:
self.bias = nn.Parameter(
th.FloatTensor(size=(num_heads * out_feats, )))
else:
self.register_buffer('bias', None)
if residual:
if self._in_dst_feats != out_feats:
self.res_fc = nn.Linear(self._in_dst_feats,
num_heads * out_feats,
bias=False)
else:
self.res_fc = nn.Identity()
else:
self.register_buffer('res_fc', None)
self.reset_parameters()
self.activation = activation
def reset_parameters(self):
"""
Description
-----------
Reinitialize learnable parameters.
Note
----
The fc weights :math:`W^{(l)}` are initialized using Glorot uniform initialization.
The attention weights are using xavier initialization method.
"""
gain = nn.init.calculate_gain('relu')
if hasattr(self, 'fc'):
nn.init.xavier_normal_(self.fc.weight, gain=gain)
else:
nn.init.xavier_normal_(self.fc_src.weight, gain=gain)
nn.init.xavier_normal_(self.fc_dst.weight, gain=gain)
nn.init.xavier_normal_(self.attn_l, gain=gain)
nn.init.xavier_normal_(self.attn_r, gain=gain)
nn.init.constant_(self.bias, 0)
if isinstance(self.res_fc, nn.Linear):
nn.init.xavier_normal_(self.res_fc.weight, gain=gain)
def set_allow_zero_in_degree(self, set_value):
r"""
Description
-----------
Set allow_zero_in_degree flag.
Parameters
----------
set_value : bool
The value to be set to the flag.
"""
self._allow_zero_in_degree = set_value
def forward(self, graph, feat, get_attention=False):
with graph.local_scope():
if not self._allow_zero_in_degree:
if (graph.in_degrees() == 0).any():
pass
# raise DGLError('There are 0-in-degree nodes in the graph, '
# 'output for those nodes will be invalid. '
# 'This is harmful for some applications, '
# 'causing silent performance regression. '
# 'Adding self-loop on the input graph by '
# 'calling `g = dgl.add_self_loop(g)` will resolve '
# 'the issue. Setting ``allow_zero_in_degree`` '
# 'to be `True` when constructing this module will '
# 'suppress the check and let the code run.')
if isinstance(feat, tuple):
h_src = self.feat_drop(feat[0])
h_dst = self.feat_drop(feat[1])
if not hasattr(self, 'fc_src'):
feat_src = self.fc(h_src).view(-1, self._num_heads,
self._out_feats)
feat_dst = self.fc(h_dst).view(-1, self._num_heads,
self._out_feats)
else:
feat_src = self.fc_src(h_src).view(-1, self._num_heads,
self._out_feats)
feat_dst = self.fc_dst(h_dst).view(-1, self._num_heads,
self._out_feats)
else:
h_src = h_dst = self.feat_drop(feat)
feat_src = feat_dst = self.fc(h_src).view(
-1, self._num_heads, self._out_feats)
if graph.is_block:
feat_dst = feat_src[:graph.number_of_dst_nodes()]
# NOTE: GAT paper uses "first concatenation then linear projection"
# to compute attention scores, while ours is "first projection then
# addition", the two approaches are mathematically equivalent:
# We decompose the weight vector a mentioned in the paper into
# [a_l || a_r], then
# a^T [Wh_i || Wh_j] = a_l Wh_i + a_r Wh_j
# Our implementation is much efficient because we do not need to
# save [Wh_i || Wh_j] on edges, which is not memory-efficient. Plus,
# addition could be optimized with DGL's built-in function u_add_v,
# which further speeds up computation and saves memory footprint.
el = (feat_src * self.attn_l).sum(dim=-1).unsqueeze(-1)
er = (feat_dst * self.attn_r).sum(dim=-1).unsqueeze(-1)
graph.srcdata.update({'ft': feat_src, 'el': el})
graph.dstdata.update({'er': er})
# compute edge attention, el and er are a_l Wh_i and a_r Wh_j respectively.
graph.apply_edges(fn.u_add_v('el', 'er', 'e'))
e = self.leaky_relu(graph.edata.pop('e'))
# compute softmax
graph.edata['a'] = self.attn_drop(edge_softmax(graph, e))
# message passing
graph.update_all(fn.u_mul_e('ft', 'a', 'm'), fn.sum('m', 'ft'))
rst = graph.dstdata['ft']
# residual
if self.res_fc is not None:
resval = self.res_fc(h_dst).view(h_dst.shape[0],
self._num_heads,
self._out_feats)
rst = rst + resval
# bias
if self.bias is not None:
rst = rst + self.bias.view(1, self._num_heads, self._out_feats)
# activation
if self.activation:
rst = self.activation(rst)
if get_attention:
return rst, graph.edata['a']
else:
return rst
train
#coding=utf-8
import torch
import torch.nn as nn
import torch.nn.functional as TFn
import numpy as np
from tqdm import tqdm
import dgltrain
import time
import argparse
from data_processor.data_statistics import data_statistics
from utils.tools import get_time_dif, set_seed, data_describe, dataloaders, datasets, path_check
from utils.logger import Logger
from utils.optim import fix_weight_decay
from utils.metric import metrics
from utils import RunRecordManager
import data_processor.yoochoose_dataset as yoochoose
import data_processor.jdata_dataset as jdata
from graph.graph_construction import *
from graph.collate import gnn_collate_fn
from IAGNN import IAGNN
import pretty_errors
MODEL_NAME = 'DAGCN'
#@torchsnooper.snoop()
def train(args, model, optimizer, scheduler, device, iters, args_filter,
item_cates):
model_name = args.model_name
start_time = time.time()
total_batch = 0 # 记录进行到多少batch
dev_best_loss, best_acc = float('inf'), 0
STEP_SIZE = 200
last_improve = 0 # 记录上次验证集loss下降的batch
loss_list = []
exp_setting = '-'.join('{}:{}'.format(k, v) for k, v in vars(args).items()
if k in args_filter)
Log = Logger(fn='./logs/{}-{}-{:.0f}.log'.format(model_name, args.dataset,
start_time))
Log.log(exp_setting)
record_manager = RunRecordManager(args.db)
record_manager.start_run(model_name, start_time, args)
item_cates = torch.from_numpy(np.array(item_cates)).to(device) #[all]
for epoch in range(args.epochs):
print('Epoch [{}/{}]'.format(epoch + 1, args.epochs))
L = nn.CrossEntropyLoss(
reduce='none') # reduce=('none' if args.weight_loss else 'mean')
_loss = 0
for i, (bgs, label, next) in enumerate(iters['train']):
model.train()
outputs, embeddings, session_length = model.forward(
bgs.to(device), next.to(device))
# print(outputs)
# break
item_catess = item_cates.view(1, -1).expand_as(outputs)
mask = torch.where(item_catess == next.to(device),
torch.ones_like(item_catess),
torch.zeros_like(item_catess)) # [bs,all]
mask = torch.cat([mask[:, 1:], mask[:, 0].view(-1, 1)], dim=1)
outputs = outputs * mask # [bs,all]
label = label.to(device)
model.zero_grad()
y = (label - 1).squeeze()
# cosine_loss = L_cos(h_all, c_all, target=y)
loss = L(outputs, y) #- 0.1 * cosine_loss
# loss_corr=model.corr_loss(embeddings,session_length)
# # print(loss); print(loss_corr)
# loss+=loss_corr*args.beta
loss_list.append(loss.item())
loss.backward()
optimizer.step()
if total_batch % STEP_SIZE == 0:
time_dif = get_time_dif(start_time)
msg = 'Iter: {0:>6}, Train Loss: {1:>5.6}, Time: {2} {3}'
_loss = np.mean(loss_list)
Log.log(
msg.format(total_batch, _loss, time_dif, '*'))
loss_list = []
total_batch += 1
print('performance on test set....')
scheduler.step()
infos = "\n"
metrics = {}
for key in iters:
if key == 'test':
# acc=0;continue
acc, info, m = evaluate_topk(args, model, iters[key],
item_cates, device, 20, key)
metrics[key] = m
infos += info
elif key != 'train':
acc_l, info_l, m_l = evaluate_topk(args,
model,
iters[key],
item_cates,
device,
20,
key,
observe=False)
metrics[key] = m_l
infos += info_l
infos += "\n"
msg = f'epoch[{epoch + 1}] :{infos}'
for test_set_name, m in metrics.items():
for top_k, v in m.items():
record_manager.update_best(model_name, start_time,
epoch + 1, test_set_name, top_k,
v['acc'], v['mrr'], v['ndcg'],
_loss)
if acc > best_acc:
best_acc = acc
Log.log(msg, red=True)
last_improve = 0
if args.save_flag:
torch.save(model.state_dict(),
'./ckpt/{}_epoch{}.ckpt'.format(exp_setting, epoch))
else:
Log.log(msg, red=False)
last_improve += 1
if last_improve >= args.patience:
Log.log('Early stop: No more improvement')
break
# try to release gpu memory hold by validation/test set
# torch.cuda.empty_cache()
def evaluate_topk(args,
model,
data_iter,
item_cates,
device,
anchor=20,
des='',
observe=False):
model.eval()
res = {'5': [], '10': [], '20': [], '50': []}
ret_metrics = {}
labels = []
acc_anchor = 0
with torch.no_grad():
with tqdm(total=(data_iter.__len__()), desc='Predicting',
leave=False) as p:
for i, (bgs, label, next) in (enumerate(data_iter)):
# print(datas)
outputs, _, _ = model.forward(bgs.to(device), next.to(device))
item_catess = item_cates.view(1, -1).expand_as(outputs)
mask = torch.where(item_catess == next.to(device),
torch.ones_like(item_catess),
torch.zeros_like(item_catess)) # [bs,all]
mask = torch.cat([mask[:, 1:], mask[:, 0].view(-1, 1)], dim=1)
outputs = outputs * mask # [bs,all]
for k in res:
res[k].append(outputs.topk(int(k))[1].cpu())
labels.append(label)
p.update(1)
labels = np.concatenate(labels) # .flatten()
labels = labels - 1
if observe:
graphs = dgl.unbatch(bgs)
length = min(20, len(graphs))
for i in range(length):
print(graphs[i].nodes['i'].data['id'])
print(label[0:length])
sm = outputs.topk(int(20))[1].cpu()[0:length].numpy() + 1
for i in range(length):
print(sm[i].tolist())
print(des)
msg = des + '\n'
for k in res:
acc, mrr, ndcg = metrics(res[k], labels)
print("Top{} : acc {} , mrr {}, ndcg {}".format(k, acc, mrr, ndcg))
msg += 'Top-{} acc:{:.3f}, mrr:{:.4f}, ndcg:{:.4f} \n'.format(
k, acc * 100, mrr * 100, ndcg * 100)
if int(k) == anchor:
acc_anchor = acc
ret_metrics[k] = {'acc': acc, 'mrr': mrr, 'ndcg': ndcg}
return acc_anchor, msg, ret_metrics
path_check(['./logs', './ckpt'])
argparser = argparse.ArgumentParser('CDSBR')
argparser.add_argument('--model_name', default='IAGNN', type=str, help='model name')
argparser.add_argument('--seed', default=422, type=int, help='random seed')
argparser.add_argument('--emb_size',
default=128,
type=int,
help='embedding size')
argparser.add_argument('--gpu', default=0, type=int, help='gpu id')
# data related setting
argparser.add_argument('--max_length',
default=10,
type=int,
help='max session length')
argparser.add_argument('--dataset',
default='jdata_cd',
help='dataset=[yc_BT_16|jdata_cd]')
# train related setting
argparser.add_argument('--batch', default=512, type=int, help='batch size')
argparser.add_argument('--epochs', default=10, type=int, help='total epochs')
argparser.add_argument('--patience',
default=3,
type=int,
help='early stopping patience')
argparser.add_argument('--lr', default=0.003, type=float, help='learning rate')
argparser.add_argument('--lr_step', default=3, type=int, help='lr decay step')
argparser.add_argument('--lr_gama',
default=0.1,
type=float,
help='lr decay gama')
argparser.add_argument('--save_flag',
default=False,
type=bool,
help='save checkpoint or not')
argparser.add_argument('--debug',
default=False,
type=bool,
help='cpu mode for debug')
# dropout related setting
argparser.add_argument('--fdrop', default=0.2, type=float, help='feature drop')
argparser.add_argument('--adrop',
default=0.0,
type=float,
help='attention drop')
# model ralated setting
argparser.add_argument('--GL', default=3, type=int, help='gnn layers')
argparser.add_argument('--vinitial', default='id', help='id/mean/max/sum/gru')
argparser.add_argument('--graph_feature_select',
default='gated',
help='last/gated/mean')
argparser.add_argument('--pooling',
default='cnext',
help='ilast/imean/cmean/cnext/input')
argparser.add_argument('--cluster_type',
default='mean',
help='mean/max/last/mean+')
argparser.add_argument('--predictor',
default='cosine',
help='cosine/bicosine/bilinear/matmul')
argparser.add_argument('--add_loss',
default=False,
type=bool,
help='add corr losss or not')
argparser.add_argument('--beta',
default=10.0,
type=float,
help='corr loss weight')
argparser.add_argument('--tao',
default=1.0,
type=float,
help='weight for softmax') #需要调参
# model comments
argparser.add_argument('--comment',
default='None',
type=str,
help='other introduction')
argparser.add_argument('--statistics',
action='store_true',
help='show data statistics')
# record result
argparser.add_argument('--db',
default='sqlite',
type=str,
choices=['sqlite', 'mysql'],
help='record the result to sqlite or mysql database.')
args = argparser.parse_args()
print(args)
args_filter = [
'dataset', 'GL', 'predictor', 'add_loss', 'beta', 'tao'
'batch', 'lr', 'lr_step', 'emb_size', 'fdrop', 'adrop', 'max_length',
'comment'
] # recording hyper-parameters
device = torch.device('cuda:' + str(args.gpu) if torch.cuda.is_available()
and args.debug == False and args.gpu >= 0 else 'cpu')
if args.dataset.startswith('yc_BT'):
data = yoochoose
elif args.dataset.startswith('jd'):
data = jdata
elif args.dataset.startswith('digi'):
data = yoochoose
path = '../dataset/'
# modes=["train" ,"test" ,"test_buy" ]
all_data, max_vid, item_cates = data.load_cd_data(
path + args.dataset, type='aug', test_length=True,
highfreq_only=True) # type='aug','common'
if args.statistics:
data_statistics(all_data)
print(max_vid)
data_describe(dataset=args.dataset, datas=all_data)
set_seed(args.seed)
collate_fn = gnn_collate_fn(seq_to_SSL_graph)
all_data, num_class = datasets(all_data, data.TBVSessionDataset,
args.max_length, max_vid)
iters = dataloaders(datas=all_data, batch=args.batch, collate=collate_fn)
model = IAGNN(num_class,
args.emb_size,
num_layers=args.GL,
device=device,
batch_norm=True,
add_loss=args.add_loss,
feat_drop=args.fdrop,
attention_drop=args.adrop,
tao=args.tao,
vinitial_type=args.vinitial,
graph_feature_select=args.graph_feature_select,
pooling_type=args.pooling,
predictor_type=args.predictor).to(device)
optimizer = torch.optim.AdamW(fix_weight_decay(model),
lr=args.lr,
weight_decay=1e-4)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer,
step_size=args.lr_step,
gamma=args.lr_gama)
train(args, model, optimizer, scheduler, device, iters, args_filter,
item_cates)
数据处理部分代码
from typing import Dict, List
import numpy as np
def data_statistics(all_data: Dict[str, List[List[List]]]):
'''
get statistics from data
Args:
data (List[List[List]]): list of [0, [item], [next_item](1), [category], [next_category](1)]
'''
data = all_data['train'] + all_data['test']
items = set()
total_session_length = 0
cats = set()
total_cat_per_session = 0
for x in data:
total_session_length += len(x[1])
for i in x[1]:
items.add(i)
items.add(x[2][0])
for c in x[3]:
cats.add(c)
cats.add(x[4][0])
total_cat_per_session += len(np.unique(x[3]))
print('')
print('* dataset statistics:')
print('=====================')
print('No. of items: {}'.format(len(items)))
print('No. of sessions: {}'.format(len(data)))
print('Avg. of session length: {}'.format(total_session_length / len(data)))
print('No. of categories: {}'.format(len(cats)))
print('No. of cats/session: {}'.format(total_cat_per_session / len(data)))
print('')
小结
该文将复杂工业过程的故障诊断问题表述为图分类问题。其关键思想是将多元传感器信号转化为具有各种边缘类型的异构图,并通过 GNN 的消息传递机制利用融合信号嵌入来对故障类型进行分类。所提出的IAGNN框架提供了两个阶段:图构建阶段和判别特征提取阶段。在第一阶段,利用注意力机制构建考虑边类型多样性的图,并为各种故障类别提供区分的图拓扑。在第二阶段,通过融合多个独立 GNN 块的子图嵌入来获得判别特征。所提出的框架可以用作工业过程故障诊断的通用平台。对两个工业过程进行了大量实验:三相流设施和 PS。实验结果表明,与最先进的方法相比,所提出的 IAGNN 框架可以提供更好的诊断结果。
GNN+Transformer:https://arxiv.org/pdf/2106.05234
参考文献
[1] Dongyue Chen , Ruonan Liu , Qinghua Hu, and Steven X. Ding. Interaction-Aware Graph Neural Networks for Fault Diagnosis of Complex Industrial Processes. [J] IEEE TRANSACTIONS ON NEURAL NETWORKS AND LEARNING SYSTEMS, VOL. 34, NO. 9, SEPTEMBER 2023 DOI:10.1109/TNNLS.2021.3132376
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









