






数仓采集之环境搭建hadoop,zookeeper,kafka
前期的阿里云ECS环境已装好,现在开始正式搭建项目的环境
hadoop安装配置
1.集群规划
| 服务器hadoop102 | 服务器hadoop103 | 服务器hadoop104 | |
|---|---|---|---|
| HDFS | NameNodeDataNode | DataNode | DataNodeSecondaryNameNode |
| Yarn | NodeManager | ResourcemanagerNodeManager | NodeManager |
2.部署安装
hadoop我这里使用的版本是hadoop-3.1.3.tar.gz
# 解压
[atguigu@hadoop102 software]$ pwd
/opt/software
[atguigu@hadoop102 software]$ ll |grep hadoop
-rw-rw-r-- 1 atguigu atguigu 338075860 Oct 16 21:37 hadoop-3.1.3.tar.gz
[atguigu@hadoop102 software]$ tar -zxvf hadoop-3.1.3.tar.gz -C ../module/
# 配置环境变量 /etc/profile.d/my_env.sh, 然后 source /etc/profile
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
# hadoop version 检验hadoop是否安装成功
3.配置集群
core-site.xml,在configuration中添加如下配置
<!-- 指定NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop102:8020</value>
</property>
<!-- 指定hadoop数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.3/data</value>
</property>
<!-- 配置HDFS网页登录使用的静态用户为atguigu -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>atguigu</value>
</property>
<!-- 配置该atguigu(superUser)允许通过代理访问的主机节点 -->
<property>
<name>hadoop.proxyuser.atguigu.hosts</name>
<value>*</value>
</property>
<!-- 配置该atguigu(superUser)允许通过代理用户所属组 -->
<property>
<name>hadoop.proxyuser.atguigu.groups</name>
<value>*</value>
</property>
<!-- 配置该atguigu(superUser)允许通过代理的用户-->
<property>
<name>hadoop.proxyuser.atguigu.groups</name>
<value>*</value>
</property>
hdfs-site.xml
<!-- nn web端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop102:9870</value>
</property>
<!-- 2nn web端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop104:9868</value>
</property>
yarn-site.xml
<!-- 指定MR走shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop103</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<!-- yarn容器允许分配的最大最小内存 -->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>4096</value>
</property>
<!-- yarn容器允许管理的物理内存大小 默认8个G-->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>4096</value>
</property>
<!-- 关闭yarn对物理内存和虚拟内存的限制检查 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
mapred-site.xml
<!-- 指定MapReduce程序运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
配置works
hadoop102
hadoop103
hadoop104
4.配置历史服务器
mapred-site.xml
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop102:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop102:19888</value>
</property>
5.配置日志聚集
yarn-site.xml
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop102:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
ok,配到这里,所有的配置已经配置完毕,接下来就把整个hadoop的安装目录分发到hadoop103,hadoop104机器,环境变量也分发一下。
[atguigu@hadoop102 module]$ pwd
/opt/module
# 分发hadoop安装目录
[atguigu@hadoop102 module]$ my_rsync.sh hadoop-3.1.3
# 分发环境变量
[atguigu@hadoop102 module]$ my_rsync.sh /etc/profile.d/my_env.sh
# 查看各个机器的hadoop环境变量是否生效
[atguigu@hadoop102 module]$ all.sh hadoop version
测试完成,现在所有机器的hadoop的环境已经装好
6.启动hadoop
# 102
[atguigu@hadoop102 module]$ hdfs namenode -format
# 102
[atguigu@hadoop102 module]$ start-dfs.sh
# 103
[atguigu@hadoop102 module]$ start-yarn.sh
ok.启动成功,
# namenode web地址
hadoop102:9870
# yarn web地址
hadoop103:8088
7.简单跑个mr测试一下
hadoop fs -mkdir /input
hadoop fs -put READ.txt /input
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input /output
# 启动历史服务器
mapred --daemon start historyserver
多目录存储
先熟悉一下,将来生产环境一定会用到
1.生产环境服务器磁盘情况

2.在hdfs-site.xml文件中配置多目录,注意新挂载磁盘的访问权限问题。
HDFS的DataNode节点保存数据的路径由dfs.datanode.data.dir参数决定,其默认值为file://${hadoop.tmp.dir}/dfs/data,若服务器有多个磁盘,必须对该参数进行修改。如服务器磁盘如上图所示,则该参数应修改为如下的值。
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///dfs/data1,file:///hd2/dfs/data2,file:///hd3/dfs/data3,file:///hd4/dfs/data4</value>
</property>
注意:每台服务器挂载的磁盘不一样,所以每个节点的多目录配置可以不一致。单独配置即可。
不慌,到时候看下磁盘挂载情况,然后datanode属性dfs.datanode.data.dir相应的配置就行
注意:每台服务器挂载的磁盘不一样,所以每个节点的多目录配置可以不一致。单独配置即可。
集群数据均衡
节点间数据均衡
开启数据均衡命令:
start-balancer.sh -threshold 10
对于参数10,代表的是集群中各个节点的磁盘空间利用率相差不超过10%,可根据实际情况进行调整。
停止数据均衡命令:
stop-balancer.sh
磁盘间数据均衡
(1)生成均衡计划(我们只有一块磁盘,不会生成计划)
hdfs diskbalancer -plan hadoop103
(2)执行均衡计划
hdfs diskbalancer -execute hadoop103.plan.json
(3)查看当前均衡任务的执行情况
hdfs diskbalancer -query hadoop103
(4)取消均衡任务
hdfs diskbalancer -cancel hadoop103.plan.json
LZO压缩配置
hadoop本身并不支持lzo压缩,故需要使用twitter提供的hadoop-lzo开源组件。hadoop-lzo需依赖hadoop和lzo进行编译。编译步骤略,编译后打成jar包: hadoop-lzo-0.4.20.jar
# 1.将编译好后的hadoop-lzo-0.4.20.jar 放入hadoop-3.1.3/share/hadoop/common/
[atguigu@hadoop102 common]$ pwd
/opt/module/hadoop-3.1.3/share/hadoop/common
[atguigu@hadoop102 common]$ ls
hadoop-lzo-0.4.20.jar
# 2.同步hadoop-lzo-0.4.20.jar到hadoop103、hadoop104
[atguigu@hadoop102 common]$ my_rsync.sh hadoop-lzo-0.4.20.jar
# 3.core-site.xml增加配置支持LZO压缩
<configuration>
<property>
<name>io.compression.codecs</name>
<value>
org.apache.hadoop.io.compress.GzipCodec,
org.apache.hadoop.io.compress.DefaultCodec,
org.apache.hadoop.io.compress.BZip2Codec,
org.apache.hadoop.io.compress.SnappyCodec,
com.hadoop.compression.lzo.LzoCodec,
com.hadoop.compression.lzo.LzopCodec
</value>
</property>
<property>
<name>io.compression.codec.lzo.class</name>
<value>com.hadoop.compression.lzo.LzoCodec</value>
</property>
</configuration>
# 4.同步core-site.xml到hadoop103、hadoop104
[atguigu@hadoop102 hadoop]$ my_rsync.sh core-site.xml
# 5.启动及查看集群
[atguigu@hadoop102 hadoop-3.1.3]$ start-dfs.sh
[atguigu@hadoop103 hadoop-3.1.3]$ start-yarn.sh
# 5.测试lzo压缩
hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount -Dmapreduce.output.fileoutputformat.compress=true -Dmapreduce.output.fileoutputformat.compress.codec=com.hadoop.compression.lzo.LzopCodec /input /lzo-output
# 5.测试lzo切片
# 注意:lzo的切片必须要创建索引,执行后会新建一个后缀为.index的文件
hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/common/hadoop-lzo-0.4.20.jar com.hadoop.compression.lzo.DistributedLzoIndexer /lzo-input/bigtable.lzo
# 测试lzo切片(把默认的TextInputFormat替换为LzoInputFormat)
hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount - Dmapreduce.job.inputformat.class=com.hadoop.mapreduce.LzoTextInputFormat /lzo-input /lzo-output
基准测试
测试HDFS写性能
# 测试命令(-nrFiles设置为cpu数量-2)hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.3-tests.jar TestDFSIO -write -nrFiles 4 -fileSize 128MB
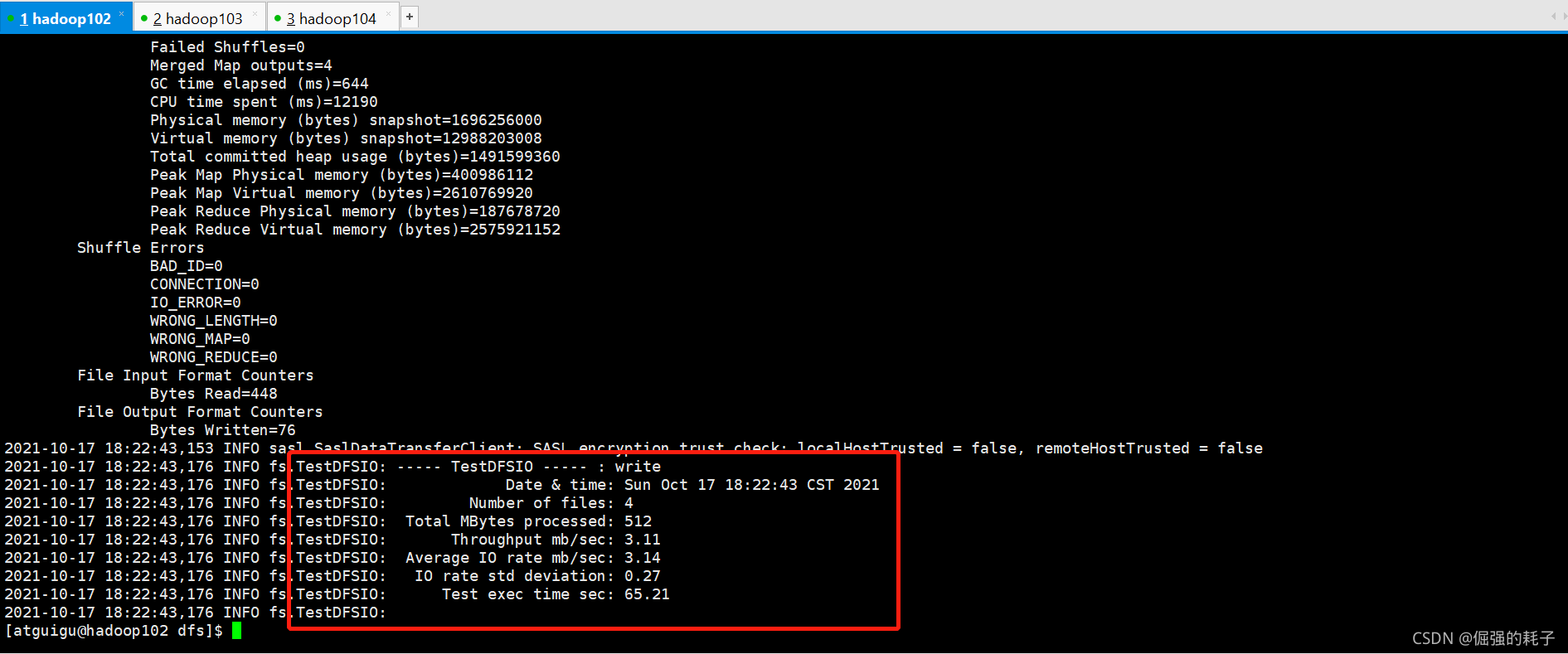
测试HDFS读性能
hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.3-tests.jar TestDFSIO -read -nrFiles 4 -fileSize 128MB
删除测试生成的数据
hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.3-tests.jar TestDFSIO -clean
hadoop参数调优
HDFS参数调优hdfs-site.xml
The number of Namenode RPC server threads that listen to requests from clients. If dfs.namenode.servicerpc-address is not configured then Namenode RPC server threads listen to requests from all nodes.
NameNode有一个工作线程池,用来处理不同DataNode的并发心跳以及客户端并发的元数据操作。
对于大集群或者有大量客户端的集群来说,通常需要增大参数dfs.namenode.handler.count的默认值10。
<property>
<name>dfs.namenode.handler.count</name>
<value>10</value>
</property>
计算公式:

YARN参数调优yarn-site.xml
(1)情景描述:总共7台机器,每天几亿条数据,数据源->Flume->Kafka->HDFS->Hive
面临问题:数据统计主要用HiveSQL,没有数据倾斜,小文件已经做了合并处理,开启的JVM重用,而且IO没有阻塞,内存用了不到50%。但是还是跑的非常慢,而且数据量洪峰过来时,整个集群都会宕掉。基于这种情况有没有优化方案。
(2)解决办法:
内存利用率不够。这个一般是Yarn的2个配置造成的,单个任务可以申请的最大内存大小,和Hadoop单个节点可用内存大小。调节这两个参数能提高系统内存的利用率。
(a)yarn.nodemanager.resource.memory-mb
表示该节点上YARN可使用的物理内存总量,默认是8192(MB),注意,如果你的节点内存资源不够8GB,则需要调减小这个值,而YARN不会智能的探测节点的物理内存总量。
(b)yarn.scheduler.maximum-allocation-mb
单个任务可申请的最多物理内存量,默认是8192(MB)。
zookeeper安装配置
集群规划
| 服务器hadoop102 | 服务器hadoop103 | 服务器hadoop104 | |
|---|---|---|---|
| Zookeeper | Zookeeper | Zookeeper | Zookeeper |
解压安装
# 解压
[atguigu@hadoop102 module]$ tar -zxvf apache-zookeeper-3.5.7-bin.tar.gz -C ../module/
# 配置环境变量
# zookeeper
export ZOOKEEPER_HOME=/opt/module/zookeeper-3.5.7
export PATH=$PATH:$ZOOKEEPER_HOME/bin
# 修改zookeeper的配置文件(创建zkData文件夹,myid文件,不重复id:2,3,4,)
# 还要zoo.sample.conf 改名为 zoo.cfg
dataDir=/opt/module/zookeeper-3.5.7/zkData
server.2=hadoop102:2888:3888
server.3=hadoop103:2888:3888
server.4=hadoop104:2888:3888
# 文件分发到103,104
[atguigu@hadoop102 module]$ my_rsync.sh zookeeper-3.5.7/
# 分发后各自改 myid文件3,4
# 分发环境变量
[atguigu@hadoop102 module]$ scp /etc/profile.d/my_env.sh root@hadoop103:/etc/profile.d/
[atguigu@hadoop102 module]$ scp /etc/profile.d/my_env.sh root@hadoop104:/etc/profile.d/
zk群启脚本zk_cluster.sh
#!/bin/bash
if [ $# -lt 1 ]
then
echo "USAGE: zk.sh {start|stop|status}"
exit
fi
case $1 in
start)
for i in hadoop102 hadoop103 hadoop104
do
echo "=================> START $i ZK <================="
ssh $i /opt/module/zookeeper-3.5.7/bin/zkServer.sh start
done
;;
stop)
for i in hadoop102 hadoop103 hadoop104
do
echo "=================> STOP $i ZK <================="
ssh $i /opt/module/zookeeper-3.5.7/bin/zkServer.sh stop
done
;;
status)
for i in hadoop102 hadoop103 hadoop104
do
echo "=================> STATUS $i ZK <================="
ssh $i /opt/module/zookeeper-3.5.7/bin/zkServer.sh status
done
;;
*)
echo "USAGE: zk.sh {start|stop|status}"
exit
;;
esac
kafka安装配置
集群规划
| 服务器hadoop102 | 服务器hadoop103 | 服务器hadoop104 | |
|---|---|---|---|
| Kafka | Kafka | Kafka | Kafka |
解压安装
# 解压
[atguigu@hadoop102 config]$ tar -zxvf kafka_2.11-2.4.1.tgz -C ../module/
# 在安装目录新建data目录,用来存消息数据
# 修改配置文件
broker.id=2
log.dirs=/opt/module/kafka_2.11-2.4.1/datas
zookeeper.connect=hadoop102:2181,hadoop103:2181,hadoop104:2181/kafka
# 编写环境变量
#kafka
export KAFKA_HOME=/opt/module/kafka_2.11-2.4.1
export PATH=$PATH:$KAFKA_HOME/bin
# 分发kafka安装目录(各自修改broker.id)以及环境变量
[atguigu@hadoop102 module]$ my_rsync.sh kafka_2.11-2.4.1/
[atguigu@hadoop102 module]$ scp /etc/profile.d/my_env.sh root@hadoop103:/etc/profile
[atguigu@hadoop102 module]$ scp /etc/profile.d/my_env.sh root@hadoop104:/etc/profile
kafka群启脚本
#!/bin/bash
if [ $# -lt 1 ]
then
echo "USAGE: kafka.sh {start|stop}"
exit
fi
case $1 in
start)
for i in hadoop102 hadoop103 hadoop104
do
echo "=================> START $i KF <================="
ssh $i /opt/module/kafka_2.11-2.4.1/bin/kafka-server-start.sh -daemon /opt/module/kafka_2.11-2.4.1/config/server.properties
done
;;
stop)
for i in hadoop102 hadoop103 hadoop104
do
echo "=================> STOP $i KF <================="
ssh $i /opt/module/kafka_2.11-2.4.1/bin/kafka-server-stop.sh
done
;;
*)
echo "USAGE: kafka.sh {start|stop}"
exit
;;
esac
kafka压力测试
用Kafka官方自带的脚本,对Kafka进行压测。Kafka压测时,可以查看到哪个地方出现了瓶颈(CPU,内存,网络IO)。一般都是网络IO达到瓶颈。
kafka-consumer-perf-test.sh
kafka-producer-perf-test.sh
# Kafka Producer压力测试
(1)在/opt/module/kafka/bin目录下面有这两个文件。我们来测试一下
[atguigu@hadoop102 kafka]$ bin/kafka-producer-perf-test.sh --topic test --record-size 100 --num-records 100000 --throughput -1 --producer-props bootstrap.servers=hadoop102:9092,hadoop103:9092,hadoop104:9092
# 说明:
record-size是一条信息有多大,单位是字节。
num-records是总共发送多少条信息。
throughput 是每秒多少条信息,设成-1,表示不限流,可测出生产者最大吞吐量。
(2)Kafka会打印下面的信息
100000 records sent, 95877.277085 records/sec (9.14 MB/sec), 187.68 ms avg latency, 424.00 ms max latency, 155 ms 50th, 411 ms 95th, 423 ms 99th, 424 ms 99.9th.
参数解析:本例中一共写入10w条消息,吞吐量为9.14 MB/sec,每次写入的平均延迟为187.68毫秒,最大的延迟为424.00毫秒。
# Kafka Consumer压力测试
Consumer的测试,如果这四个指标(IO,CPU,内存,网络)都不能改变,考虑增加分区数来提升性能。
[atguigu@hadoop102 kafka]$ bin/kafka-consumer-perf-test.sh --broker-list hadoop102:9092,hadoop103:9092,hadoop104:9092 --topic test --fetch-size 10000 --messages 10000000 --threads 1
参数说明:
--zookeeper 指定zookeeper的链接信息
--topic 指定topic的名称
--fetch-size 指定每次fetch的数据的大小
--messages 总共要消费的消息个数
测试结果说明:
start.time, end.time, data.consumed.in.MB, MB.sec, data.consumed.in.nMsg, nMsg.sec
2019-02-19 20:29:07:566, 2019-02-19 20:29:12:170, 9.5368, 2.0714, 100010, 21722.4153
开始测试时间,测试结束数据,共消费数据9.5368MB,吞吐量2.0714MB/s,共消费100010条,平均每秒消费21722.4153条。
kafka机器数量计算
经验计算公式
Kafka机器数量(经验公式)=2*(峰值生产速度*副本数/100)+1
先拿到峰值生产速度,再根据设定的副本数,就能预估出需要部署Kafka的数量。
比如我们的峰值生产速度是50M/s。副本数为2。
Kafka机器数量=2*(50*2/100)+ 1=3台
kafka分区计算公式
https://blog.csdn.net/weixin_42641909/article/details/89294698
1)创建一个只有1个分区的topic
2)测试这个topic的producer吞吐量和consumer吞吐量。
3)假设他们的值分别是Tp和Tc,单位可以是MB/s。
4)然后假设总的目标吞吐量是Tt,那么分区数=Tt / min(Tp,Tc)
例如:producer吞吐量=20m/s;consumer吞吐量=50m/s,期望吞吐量100m/s;
分区数=100 / 20 =5分区
分区数一般设置为:3-10个
flume安装配置
解压安装
# 解压
[atguigu@hadoop102 software]$ tar -zxvf apache-flume-1.9.0-bin.tar.gz -C ../module/
# 配置环境变量
#flume
export FLUME_HOME=/opt/module/flume-1.9.0
export PATH=$PATH:$FLUME_HOME/bin
# 刷新配置
[atguigu@hadoop102 lib]$ source /etc/profile
# 删除/opt/module/flume-1.9.0/lib目录下的 guava jar包
[atguigu@hadoop102 lib]$ rm -rf guava-11.0.2.jar
项目架构图
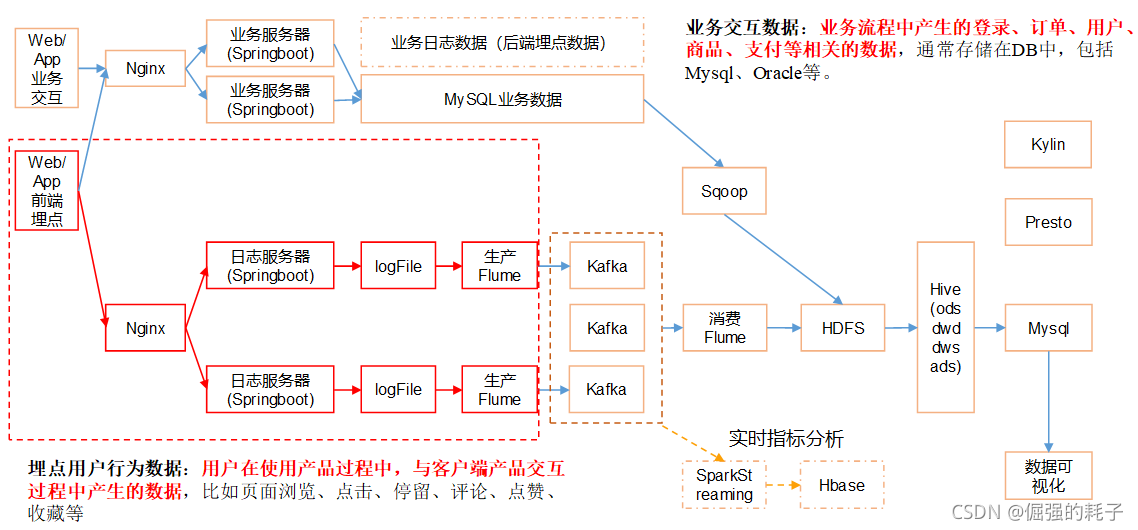
flume采集通道规划
第一层flume:
source: taildir
channel: kafka channel
sink:无
第二层flume:
source: 无 source: kafka source 使用第二种:可以在source这里加拦截器
channel: kafka channel channel: file channel
sink: hdfs sink sink: hdfs sink
拦截器配置
思考一个问题:就在在第一层的flume读取数据时,可能存在不合法的数据(比如不是json格式),如果这样这样的数据进入到hdfs,将来使用解析时必然解析不了。所以有必要在第一层flume这里添加一个拦截器。
pom.xml
<dependency>
<groupId>org.apache.flume</groupId>
<artifactId>flume-ng-core</artifactId>
<version>1.9.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.62</version>
</dependency>
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.3.2</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
//数据采集的拦截器
package com.pihao.flume.interceptor;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONException;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.nio.charset.StandardCharsets;
import java.util.ArrayList;
import java.util.List;
public class EtlLogInterceptor implements Interceptor {
@Override
public void initialize() {
}
@Override
public Event intercept(Event event) {
//取出body
String body = new String(event.getBody(), StandardCharsets.UTF_8);
//判断是否是json格式
try {
JSON.parseObject(body);
}catch (JSONException e){
return null;
}
return event;
}
@Override
public List<Event> intercept(List<Event> list) {
List<Event> list1 = new ArrayList<>();
for (Event event : list) {
Event newEvent = intercept(event);
if(null != newEvent){
list1.add(newEvent);
}
}
return list1;
}
@Override
public void close() {
}
/**
* builder内部类,用来实例化上面的interceptor类
*/
public static class MyBuilder implements Builder{
@Override
public Interceptor build() {
return new EtlLogInterceptor();
}
@Override
public void configure(Context context) {
}
}
}
Maven打包,将带依赖的jar包上传到/flume/lib目录中
第一层flume配置与启停脚本
source: taildir
channel: kafka channel
sink:无
在/opt/module/flume-1.9.0/jobs/gmall创建logserver-flume-kafka.conf
#name
a1.sources = r1
a1.channels = c1
#source
a1.sources.r1.type = TAILDIR
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /opt/module/applog/log/app.*
a1.sources.r1.positionFile = /opt/module/flume-1.9.0/jobs/position/position.json
#拦截器
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = com.pihao.flume.interceptor.EtlLogInterceptor$MyBuilder
#channel
a1.channels.c1.type = org.apache.flume.channel.kafka.KafkaChannel
a1.channels.c1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092,hadoop104:9092
a1.channels.c1.kafka.topic = topic_log
a1.channels.c1.parseAsFlumeEvent = false
# bind
a1.sources.r1.channels = c1
先启动kafka集群,创建一个消费者去消费topic_log主题
再执行flume命令测试
flume-ng agent -c $FLUME_HOME/conf -f $FLUME_HOME/jobs/gmall/logserver-flume-kafka.conf -n a1 -Dflume.root.logger=INFO,console
编写启停脚本f1.sh
#!/bin/bash
if [ $# -lt 1 ]
then
echo "USAGE: f1.sh {start|stop}"
exit
fi
case $1 in
start)
for i in hadoop102 hadoop103
do
ssh $i "nohup flume-ng agent -c $FLUME_HOME/conf -f $FLUME_HOME/jobs/gmall/logserver-flume-kafka.conf -n a1 -Dflume.root.logger=INFO,console 1>$FLUME_HOME/logs/flume.log 2>&1 &"
done
;;
stop)
for i in hadoop102 hadoop103
do
ssh $i "ps -ef | grep logserver-flume-kafka.conf | grep -v grep | awk '{print \$2}' | xargs -n1 kill -9"
done
;;
*)
echo "USAGE: f1.sh {start|stop}"
exit
;;
esac
102自测通过后将flume的安装目录发送到103机器,以及环境变量
[atguigu@hadoop102 module]$ scp -r flume-1.9.0/ hadoop103:/opt/module/
第二层flume配置与启停脚本
source: kafka source 可以在source这里加拦截器
channel: file channel
sink: hdfs sink在第二层,我们将flume设置在104机器上。它是用来消费kafka中的数据存在hdfs
思考:这个添加的拦截器主要是干什么的呢?主要是用来覆盖kafka source里头的默认的系统时候,换成日志里面的实际时间戳,不然这个数据会出现一些问题,本来是是23:59:59的数据,如果使用本地时间,可能就变成了第二天的数据了。所以这个问题必须要处理,用拦截器来做。
编写拦截器
package com.pihao.flume.interceptor;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.nio.charset.StandardCharsets;
import java.util.List;
public class TimeStampInterceptor implements Interceptor {
@Override
public void initialize() {
}
//使用新的ts替换原来的timestamp
@Override
public Event intercept(Event event) {
String body = new String(event.getBody(), StandardCharsets.UTF_8);
JSONObject jsonObject = JSON.parseObject(body);
String ts = jsonObject.getString("ts");
event.getHeaders().put("timestamp",ts);
return event;
}
@Override
public List<Event> intercept(List<Event> list) {
for (Event event : list) {
intercept(event);
}
return list;
}
@Override
public void close() {
}
/**
* builder内部类,用来实例化上面的interceptor类
*/
public static class MyBuilder implements Builder{
@Override
public Interceptor build() {
return new TimeStampInterceptor();
}
@Override
public void configure(Context context) {
}
}
}
将flume的安装目录发送到104机器,并且分发环境变量
在104机器创建 /opt/module/flume-1.9.0/jobs/gmall创建kafka-flume-hdfs.conf
#name
a1.sources = r1
a1.channels = c1
a1.sinks = k1
#source
a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.r1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092,hadoop104:9092
a1.sources.r1.kafka.topics = topic_log
a1.sources.r1.kafka.consumer.group.id = gmall
a1.sources.r1.batchDurationMillis = 2000
#拦截器
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = com.pihao.flume.interceptor.TimeStampInterceptor$MyBuilder
#channel
a1.channels.c1.type = file
a1.channels.c1.dataDirs = /opt/module/flume-1.9.0/jobs/filechannel
a1.channels.c1.capacity = 1000000
a1.channels.c1.transactionCapacity = 10000
a1.channels.c1.checkpointDir = /opt/module/flume-1.9.0/jobs/checkpoint
#a1.channels.c1.useDualCheckpoints = true
#a1.channels.c1.backupCheckpointDir = /opt/module/flume-1.9.0/jobs/checkpoint-bk
a1.channels.c1.maxFileSize = 2146435071
a1.channels.c1.keep-alive = 5
#hdfs sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://hadoop102:8020/origin_data/gmall/log/topic_log/%Y-%m-%d
a1.sinks.k1.hdfs.filePrefix = log-
a1.sinks.k1.hdfs.round = false
a1.sinks.k1.hdfs.rollInterval = 10
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0
#控制输出文件是原生文件(下面的压缩配置会报错)
#a1.sinks.k1.hdfs.fileType = CompressedStream
#a1.sinks.k1.hdfs.codeC = lzop
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
启动hdfs
104执行flume命令
flume-ng agent -c $FLUME_HOME/conf -f $FLUME_HOME/jobs/gmall/kafka-flume-hdfs.conf -n a1 -Dflume.root.logger=INFO,console
编写启停脚本f2.sh
#!/bin/bash
if [ $# -lt 1 ]
then
echo "USAGE: f2.sh {start|stop}"
exit
fi
case $1 in
start)
for i in hadoop104
do
ssh $i "nohup flume-ng agent -c $FLUME_HOME/conf -f $FLUME_HOME/jobs/gmall/kafka-flume-hdfs.conf -n a1 -Dflume.root.logger=INFO,console 1>$FLUME_HOME/logs/flume.log 2>&1 &"
done
;;
stop)
for i in hadoop104
do
ssh $i "ps -ef | grep kafka-flume-hdfs.conf | grep -v grep | awk '{print \$2}' | xargs -n1 kill -9"
done
;;
*)
echo "USAGE: f2.sh {start|stop}"
exit
;;
esac

测试成功
flume内存优化
1)问题描述:如果启动消费Flume抛出如下异常
ERROR hdfs.HDFSEventSink: process failed
java.lang.OutOfMemoryError: GC overhead limit exceeded
2)解决方案步骤:
(1)在hadoop102服务器的/opt/module/flume/conf/flume-env.sh文件中增加如下配置
export JAVA_OPTS="-Xms100m -Xmx2000m -Dcom.sun.management.jmxremote"
(2)同步配置到hadoop103、hadoop104服务器
[atguigu@hadoop102 conf]$ xsync flume-env.sh
3)Flume内存参数设置及优化
JVM heap一般设置为4G或更高
-Xmx与-Xms最好设置一致,减少内存抖动带来的性能影响,如果设置不一致容易导致频繁fullgc。
-Xms表示JVM Heap(堆内存)最小尺寸,初始分配;-Xmx 表示JVM Heap(堆内存)最大允许的尺寸,按需分配。如果不设置一致,容易在初始化时,由于内存不够,频繁触发fullgc。















 5072
5072











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









