







MQ有什么用?
消息队列使用场景很多,最常见的是: 解耦、异步、削峰
1.解耦: 使用消息队列避免模块间的直接调用。将所需共享的数据放在消息队列中,对于新增的业务模块,只要对该类消息感兴趣就可以订阅该消息,对原有系统无影响,降低各个模块的耦合度,提高系统可扩展性
2.异步: 消息队列提供了异步处理机制,在很多时候应用不需要立即处理消息,允许应用把一些消息放入中间件中,不立即处理,而是在之后需要的时候慢慢处理。
3.削峰: 访问量骤增的场景下,为了保证系统的平稳性,使用消息队列可以使关键组件支撑突发访问压力,不会因为超负荷而请求完全崩溃。高峰期的消息可以被积压起来,在随后的时间内进行平滑处理完成,不至于让系统短时间内无法承载而导致崩溃。在电商网站的秒杀抢购这种突发性流量很强的业务中,消息队列的强大缓冲能力可以起到削峰的作用。
生产者和消费者模式
生产者-消费者问题,实际上主要是包含了两类线程。一类是生产者线程用于生产数据,另一类是消费者线程用于消费数据,为了解耦生产者和消费者的关系,采用共享的数据区域,就像是一个仓库,生产者生产数据之后直接放在共享数据区中, 不需要关心消费者的行为。而消费者只需要从共享数据中心中去获取数据 ,不需要关心生产者的行为。
并且,这个数据共享中心应该具备并发协作的功能:如果共享数据区满了,阻塞生产者继续放入数据,如果共享数据区为空,阻塞消费者继续消费数据。
Java语言中,实现生产者和消费者问题时可以采用三种同步方式:
- wait/notify 的消息通知机制
- Lock 的Condition 的awati / signal 的消息通知机制
- 使用BlockingQueue
消息队列如何保证顺序消费
实际项目中,比如订单系统要同步订单表的数据到大数据部门的MySQL库中,通常做法是通过Canal这样的中间件去监听binlog,然后再把这些binlog 发送到MQ中, 然后消费者从MQ中获取binlog数据落地到大数据部门的MySQL中。
在这个过程,可能有订单的增删改操作, binlog数据一定是有序的,比如 binlog 执行顺序是 增加、修改。
但是消费者可能拿到的顺序是修改、增加,这就数据缺失异常了。不同的消息队列,产生错乱的原因可能有细微差别,但是总体思路差不多。
拿RabbitMQ举例:
错乱场景1:
一个queue,有多个consumer去消费, 因为我们无法保证先读到消息的 consumer 一定先完成操作,所以可能导致顺序错乱
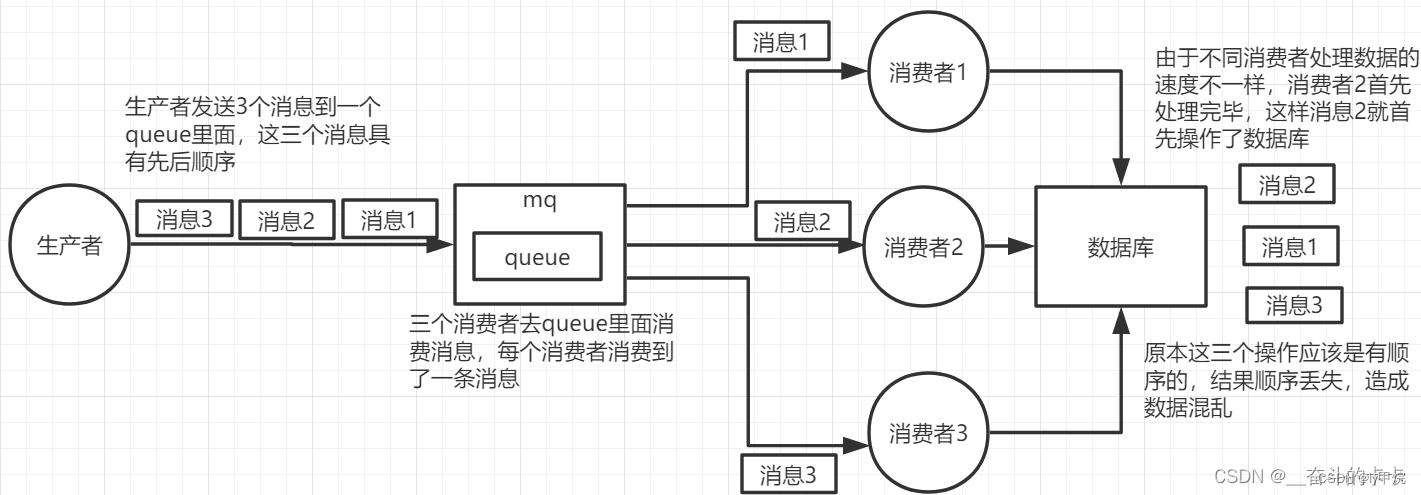
出现这个问题的主要原因是,不同消息都发送到了一个queue 中,然后多个消费者消费同一个queue的消息。
所以我们可以给 RabbitMQ 创建多个queue, 每个消费者只消费一个queue, 生产者根据订单号,把订单号相同的消息放入一个同一个queue。这样同一个订单号的消息就只会被同一个消费者顺序消费。
错乱场景2:
一个queue,一个consumer去消费, 但是 consumer 里面进行了多线程消费, 无法保证哪个线程先执行完,可能导致顺序错乱
针对这种情况可以引入多个内存队列,同一个订单号的消息放入一个队列中,线程不直接消费消息,而是从队列中取出消息去消费
错乱场景3:
生产者到MQ中间,消息由于网络延迟或者出现重试,导致原本 binlog 顺序是 1 2 3,发送到 MQ 的 queue 中变成了 1 3 2。
导致queue中的消息就是错乱的
针对这种情况, 可以在消费者端做一个乱序处理, 根据 binlog 日志中的偏移量可以确定这个消息执行顺序。 偏移量就是 binlog 写这条记录的时候的位置, 这个顺序一定是正确的。 对于同一个订单,如果遇到偏移量更小的消息,就丢弃。 比如:插入、修改、删除。 顺序变成了插入、删除、修改,执行到修改发现偏移量比删除的低,丢弃这个消息。当然如果顺序变成修改、插入、删除的话,执行修改的时候的先插入一条数据。
消息队列如何保证消息不丢
丢数据一般有两种情况:一种是MQ把数据丢了,一种是消费时把数据丢了。
场景1
生产者将数据发送到RabbitMQ的时候,传输过程中因为网络等问题将数据丢了
解决办法:
①启用RaibbitMQ提供的事务功能,生产者发送数据前开启事务,如果消息没有成功被RabbitMQ接收到,生产者会报错,这时候可以回滚事务,然后尝试重新发送。缺点就是RabbitMQ开启事务会变成同步阻塞操作,使用事务消息, 性能下降250倍, 所以引入消息确认机制
② 发送方确认机制。 生产者配置开启发送方确认模式,并设置确认回调。 只要消息到达 Broker(消息代理), 就会触发confirmCallback, 表示服务器成功收到消息。消息用数据库记录,定时检查重发没有成功的消息
还得开启发送端消息抵达队列确认,并设置回调。如果消息成功抵达 broker, 不一定能成功投递到队列,如果交换机没能成功将消息投递到队列,就会触发 returnCallBack
场景2
RabbitMQ 断电重启了,导致丢消息。
针对这种情况,RabbitMQ有自己的持久化功能,可以把消息持久化到磁盘,RabbitMQ重启后自动读取之前存储的数据。
而且持久化可以和发送方确认机制配合,消息持久化到磁盘后才会回复发送方ack,这样生产者收不到ack回调,也会重发消息。
场景3
消费者消费的时候挂了。导致数据丢失
针对这种情况,使用RabbitMQ的 消费端确认机制。 首先关闭 RabbitMQ 的自动 ACK,每次确保处理完消息之后,再手动调用ack。这样服务器宕机或者bug导致没有正确ack, 消息会重新入队。
如何保证不重复消费
重复消费的原因:正常情况,消费完毕,RabbitMQ会回复一个确认消息给消息队列,消息队列就把这个消息删除了,但是因为宕机或者网络导致确认消息没返回成功,消息队列不知道自己消费过该消息,会将消息再次分发。
重复消费不可怕,可怕的是没能考虑到重复消费之后,怎么保证幂等性。
解决方法:
- 消费者的业务逻辑接口设计成幂等性的。比如扣除库存的时候,带上唯一的订单号和状态标志,消费到这个消息的时候先去redis里查一下之前消费过没有,消费过就不处理。
- 使用防重表,每个消息都有业务唯一标识,处理过就不处理了。
- 或者使用唯一键,保证重复数据不会插入多条
消息积压怎么解决
消息积压原因:
- 消费者宕机一段时间, 而发送者还在源源不断的发送消息, 导致消息都积压在队列中;
- 消费者消费能力不足, 不足以匹配发送者发送消息的频率;
- 发送者发送流量过大。
解决方法:
- 在发送端限制消息的发送;
- 上线更多的消费者;
- 上线一个专门处理消息的消费者, 将消息全部拿出来存入数据库, 之后再进行离线处理
RabbitMQ如何实现分布式事务?可靠消息最终一致性
-
确认生产者把消息投递到了MQ的队列中, 采用本地事务消息、定时任务、消息确认机制
消息写入数据库后投递消息,投递成功删除消息。定时扫描投递失败的的消息进行重试 -
确定消费者能正确的消费消息,采用手动ACK模式、方法幂等性、重试机制。 有些业务可能还需要保证消息顺序消费
-
始终不能消费的消息通知人工介入
















 1828
1828











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











