







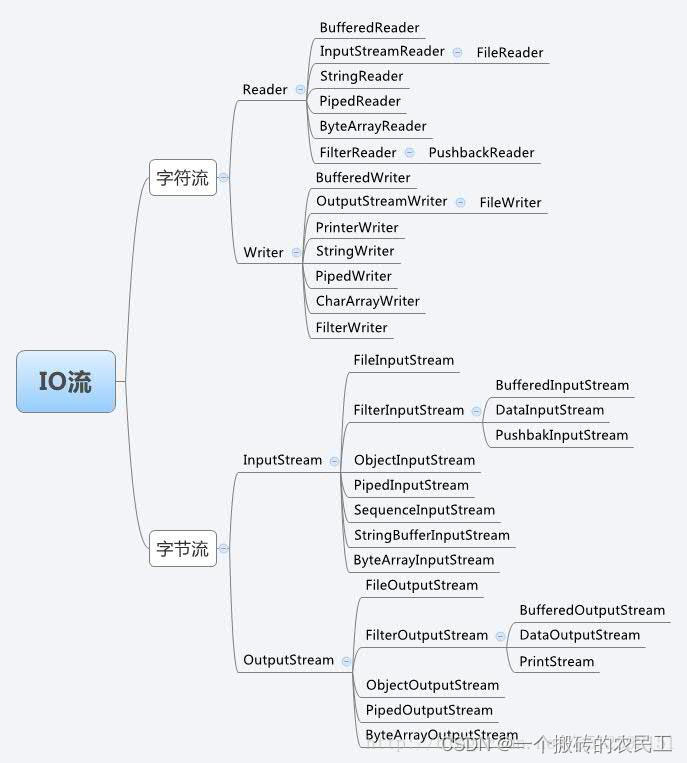
一、字节流和字符流的区别
1、字节和字符换算关系
- ASCII 码中,一个英文字母(不分大小写)为一个字节,一个中文汉字为两个字节。
- UTF-8 编码中,一个英文字为一个字节,一个中文为三个字节。
- Unicode 编码中,一个英文为一个字节,一个中文为两个字节。
- 符号:英文标点为一个字节,中文标点为两个字节。例如:英文句号 . 占1个字节的大小,中文句号 。占2个字节的大小。
- UTF-16 编码中,一个英文字母字符或一个汉字字符存储都需要 2 个字节(Unicode 扩展区的一些汉字存储需要 4 个字节)。
- UTF-32 编码中,世界上任何字符的存储都需要 4 个字节。
2、字节、位、二进制之间的关系
- 字节:英文Byte,音译为“拜特”,习惯上用大写的“B”表示。字节是计算机中数据处理的
基本单位。1字节等于8位二进制 - 位:英文bit,音译为“比特”,是计算机中最小的单位,
表示二进制位 - 二进制:计算技术中广泛采用的一种
数制,二进制数据是用0和1两个数码来表示的数,它的基数为2,进位规则是“逢二进一”。通常有8位、16位、32位、64位等(64 位操作系统, 基于 x64 的处理器,指的就是64位操作系统针对的64位的CPU设计的,而64位cpu指的是一次性可处理的数据量是64位,也就是8字节)
3、在64位的操作系统中,一个字等于多少字节?
- 在16位的系统中(比如8086微机) 1字 (word)= 2字节(byte)= 16(bit)
- 在32位的系统中(比如win32) 1字(word)= 4字节(byte)=32(bit)
- 在64位的系统中(比如win64)1字(word)= 8字节(byte)=64(bit)
4、字节流和字符流区别
- 字节流操作的基本单元为字节;字符流操作的基本单元为Unicode码元。
- 字节流默认不使用缓冲区;字符流使用缓冲区。
- 字节流通常用于处理二进制数据,实际上它可以处理任意类型的数据,但它不支持直接写入或读取Unicode码元;字符流通常处理文本数据,它支持写入及读取Unicode码元。
二、InputStream
常用的两个方法read()、close()
(1)read():有三个重载方法
public int read() // 读取下一个字节,每次只返回0-255 int类型字节
public int read(byte b[]) // 从输入流中读取一些字节,存到缓存数组b中
public int read(byte b[], int off, int len) // 筛选一些字节存入b中,从off开始到len结束
解析:
第二个read方法实际调用的是第三个read方法,而第三个read方法实际是循环调用第一个read方法,因此InputStream的三个read方法获取字节效率很低
为什么返回的是int类型
1、为什么用int类型:
因为字节输入流可以操作任意类型的文件,比如图片音频等,这些文件底层都是以二进制形式存储的。如果每次读取都返回byte,有可能在读到中间的时候遇到11111111,那么这11111111是byte类型的-1,我们的程序是遇到-1就会停止不读了,后面的数据就读不到了,所以在读取的时候用int类型接收。如果是11111111就会在其前面补上24个0凑足4个字节,那么byte类型的-1就会变成int类型的255了,这样就可以保证整个数据读完,而结束标记的-1就是int类型。
2、为什么是0-255的int类型:
一个字节8位,0-255的int类型刚好也只占用了后8位,这就是为什么是0-255的int来表示字节了
00000000 00000000 00000000 11111111
(2)close():关闭流,释放资源
1、FileInputStream
从文件中读取字节流,提供了三个构造方法
public FileInputStream(String name) // name是一个文件路径
public FileInputStream(File file) // file是一个File对象
public FileInputStream(FileDescriptor fdObj) // 一个现有的文件描述符
示例:
try {
File file = new File("D:\\APP\\详设.docx");
FileInputStream fileInputStream = new FileInputStream(file);
byte[] buf = new byte[1024];
// 把字节循环读入到buf中
while(fileInputStream.read(buf)!=-1){
}
// 关闭资源
fileInputStream.close();
}catch (Exception e){
System.out.println("报错了");
}
2、FilterInputStream
为基础流提供一些额外的过滤功能,FilterInputStream中基本都是基础的InputStream中的方法,额外功能主要体现在他的三个子类中BufferedInputStream、DataInputStream、PushBackInputStream
(1)DataInputStream:数据输入流,以机器无关的方式读取Java的基本类型。即用java的方式读取。
File file=new File("E:\\javaSource2\\javacod\\20181121\\fos.txt");
FileOutputStream fileOutputStream=new FileOutputStream(file); //字节输出流
BufferedOutputStream bufferedOutputStream=new BufferedOutputStream(fileOutputStream);
// 输出时使用缓冲流包装,最后最好使用一个flush()将数据刷入
DataOutputStream dataOutputStream=new DataOutputStream(bufferedOutputStream);
// dataOutputStream=new DataOutputStream(fileOutputStream);
// 基本数据类型输出流,可以中间不用缓冲流
dataOutputStream.writeBoolean(false);
dataOutputStream.writeLong(999);
dataOutputStream.writeByte(80);
dataOutputStream.writeUTF("贺isVIP"); //UTF-8编码形式
dataOutputStream.writeShort(-1);
dataOutputStream.writeUTF("UTF编码");
dataOutputStream.writeChars("haha"); //实际写入四个char类型数据
dataOutputStream.flush();
// 将数据刷入文件中,因为我们中间使用了缓冲流,不刷进去,数据可能在缓存中;
FileInputStream fileInputStream=new FileInputStream(file);
BufferedInputStream bufferedInputStream=new BufferedInputStream(fileInputStream);
DataInputStream dataInputStream=new DataInputStream(bufferedInputStream); //基本数据类型输入流;
/*
* 写入顺序要和读出顺序一致,否则得到的不是原数据
*/
System.out.println(dataInputStream.readBoolean());
System.out.println(dataInputStream.readLong());
System.out.println(dataInputStream.readByte());
System.out.println(dataInputStream.readUTF()); //UTF-8解码
System.out.println(dataInputStream.readUnsignedShort());
System.out.println(dataInputStream.readUTF()); //UTF-8解码
while(true){ //除非最后全是同一种基本类型,否则会读完所有字节
char ch=dataInputStream.readChar();
System.out.print(ch);
}
(2)BufferedInputStream:缓冲流的存在就是先将数据读取一部分到缓冲流(内存中),然后从内存中读取到字节或者输出流中,而不用从磁盘中读取,从而提高读取的效率,提供两个构造方法。
// 创建一个内部的缓冲区数组。当读取或跳过流中的字节时,内部缓冲区将根据需要从所包含的输入流中重新填充,每次填充多个字节。
public BufferedInputStream(InputStream in) // 默认缓存大小为8192字节,8KB
public BufferedInputStream(InputStream in, int size) // 自定义缓存字节数组大小
注:BufferedInputStream中获取字节调用缓存的只有第一和第三个read方法,而第二个read方法不会
public int read() // 从缓存中获取一个
public int read(byte b[]) // 实际是实现InputStream中方法
public int read(byte b[], int off, int len) // 会从缓存中获取字节数组
(3) PushInputStream:回退输入流,java中读取数据的方式是顺序读取,如果某个数据不需要读取,需要程序处理.PushBackInputStream就可以将某些不需要的数据回退到缓冲中.
3、ObjectInputStream
ObjectInputStream顾名思义就是可以从流中读入一个用户自定义的对象。一定要注意ObjectOutputStream与ObjectInputStream必须配合使用,且按同样的顺序。类必须实现Serializable接口才可以被序列化
FileOutputStream fos = new FileOutputStream("D:\\APP\\详设.docx");
ObjectOutputStream oos = new ObjectOutputStream(fos);
oos.writeObject(new UserEntity().setName("张三").setAge(1));
oos.writeObject(new UserEntity().setName("李三").setAge(2));
oos.close();
FileInputStream fis = new FileInputStream("D:\\APP\\详设.docx");
ObjectInputStream ois = new ObjectInputStream(fis);
UserEntity u1 = (UserEntity)ois.readObject();
UserEntity u2 = (UserEntity)ois.readObject();
ois.close();
4、PipedInputStream
PipedInputStream 和 PipedOutputStream设计用来解决跨线程的字节数据传输。它们总是成对出现的,而在使用上,也只能 工作在两个不同的线程上。
示例:详解PipedInputStream和PipedOutputStream
5、SequenceInputStream
从一个有序的输入流集合开始,从第一个流开始读取,直到到达文件末尾,然后从第二个流开始读取,以此类推,直到最后一个包含的输入流到达文件末尾。主要提供两个构造方法。
public SequenceInputStream(Enumeration<? extends InputStream> e) // 从这个枚举中读取
使用示例:
Vector< InputStream> v = new Vector< InputStream>();
v.addElement(new FileInputStream());
SequenceInputStream sis = new SequenceInputStream(v.elements());
public SequenceInputStream(InputStream s1, InputStream s2) // 从s1和s2中读取输入流
6、StringBufferInputStream
因为该类不能正确地将字符转换为字节,已弃用。从JDK 1.1开始,从字符串创建流的首选方法是通过 StringReader 类。
7、ByteArrayInputStream
该类可以把字节存入缓存中,然后提取。提供两个构造方法:
注:该类的close()方法不生效,关闭后类中方法依然可用。
public ByteArrayInputStream(byte buf[]); // 入参是一个字节数组
public ByteArrayInputStream(byte buf[], int offset, int length); // 入参是一个字节数组,并包括第一个字节偏移量和读取字节长度
三、OutputStream
字节输出流,提供五个方法:
public abstract void write(int b) // 将字节写入输出流
public void write(byte b[]) // 将字节数组写入输出流
public void write(byte b[], int off, int len) // 将指定下标字节数组写入输出流
public void flush() // 刷新缓存
public void close() // 关闭字节流
1、FileOutputStream
创建一个文件输出流
// 构造函数
public FileOutputStream(String name)
public FileOutputStream(String name, boolean append)
public FileOutputStream(File file)
public FileOutputStream(File file, boolean append)
public FileOutputStream(FileDescriptor fdObj)
// 将字节写入输出流,write的几个重载方法
private native void write(int b, boolean append) // 写入一个int类型的,append是否把写入的字节追加到已打卡文件中
public void write(int b) // 写入一个int类型的
public void write(byte b[]) // 写入一个字节数组到输出流
public void write(byte b[], int off, int len) // 写入一个字节数组到输出流,off 开始位置,len 写入字节长度
2、FileOutputStream
为基础流提供一些额外的过滤功能,额外功能主要体现在他的三个子类中BufferedOutputStream、DataOutputStream、PrintStream
- BufferedOutputStream
该类实现了缓冲输出流。通过设置这样的输出流,应用程序可以向底层输出流写入字节,而不必为写入的每个字节调用底层系统。
// 定义一个缓存8kb的输出缓存流
public BufferedOutputStream(OutputStream out) {
this(out, 8192);
}
// 定义一个输出缓存流
public BufferedOutputStream(OutputStream out, int size) {
super(out);
if (size <= 0) {
throw new IllegalArgumentException("Buffer size <= 0");
}
buf = new byte[size];
}
- DataOutputStream
数据输出流允许应用程序以可移植的方式将基本Java数据类型写入输出流。然后,应用程序可以使用数据输入流将数据读入。
File file=new File("E:\\javaSource2\\javacod\\20181121\\fos.txt");
FileOutputStream fileOutputStream=new FileOutputStream(file); //字节输出流
BufferedOutputStream bufferedOutputStream=new BufferedOutputStream(fileOutputStream);
// 输出时使用缓冲流包装,最后最好使用一个flush()将数据刷入
DataOutputStream dataOutputStream=new DataOutputStream(bufferedOutputStream);
// dataOutputStream=new DataOutputStream(fileOutputStream);
// 基本数据类型输出流,可以中间不用缓冲流
dataOutputStream.writeBoolean(false);
dataOutputStream.writeLong(999);
dataOutputStream.writeByte(80);
dataOutputStream.writeUTF("贺isVIP"); //UTF-8编码形式
dataOutputStream.writeShort(-1);
dataOutputStream.writeUTF("UTF编码");
dataOutputStream.writeChars("haha"); //实际写入四个char类型数据
dataOutputStream.flush();
// 将数据刷入文件中,因为我们中间使用了缓冲流,不刷进去,数据可能在缓存中;
FileInputStream fileInputStream=new FileInputStream(file);
BufferedInputStream bufferedInputStream=new BufferedInputStream(fileInputStream);
DataInputStream dataInputStream=new DataInputStream(bufferedInputStream); //基本数据类型输入流;
/*
* 写入顺序要和读出顺序一致,否则得到的不是原数据
*/
System.out.println(dataInputStream.readBoolean());
System.out.println(dataInputStream.readLong());
System.out.println(dataInputStream.readByte());
System.out.println(dataInputStream.readUTF()); //UTF-8解码
System.out.println(dataInputStream.readUnsignedShort());
System.out.println(dataInputStream.readUTF()); //UTF-8解码
while(true){ //除非最后全是同一种基本类型,否则会读完所有字节
char ch=dataInputStream.readChar();
System.out.print(ch);
}
- PrintStream
为另一个输出流添加了功能,即方便地打印各种数据值的表示形式的能力。
// 例
public void println(boolean x) {
synchronized (this) {
print(x);
newLine();
}
}
3、ObjectOutputStream
ObjectOutputStream与ObjectInputStream必须配合使用,且按同样的顺序。类必须实现Serializable接口才可以被序列化
FileOutputStream fos = new FileOutputStream("D:\\APP\\详设.docx");
ObjectOutputStream oos = new ObjectOutputStream(fos);
oos.writeObject(new UserEntity().setName("张三").setAge(1));
oos.writeObject(new UserEntity().setName("李三").setAge(2));
oos.close();
FileInputStream fis = new FileInputStream("D:\\APP\\详设.docx");
ObjectInputStream ois = new ObjectInputStream(fis);
UserEntity u1 = (UserEntity)ois.readObject();
UserEntity u2 = (UserEntity)ois.readObject();
ois.close();
4、PipedOutputStream
PipedInputStream 和 PipedOutputStream设计用来解决跨线程的字节数据传输。它们总是成对出现的,而在使用上,也只能 工作在两个不同的线程上。
示例:详解PipedInputStream和PipedOutputStream
5、ByteArrayOutputStream
该类实现了一个输出流,其中数据被写入字节数组。当数据写入缓冲区时,缓冲区会自动增长。可以使用toByteArray()和toString()检索数据。关闭ByteArrayoutputStream没有效果。该类中的方法可以在流关闭后调用,而不会生成IOException。
// 创建一个新的字节数组输出流。缓冲区容量最初为32字节,如果需要,它的大小会增加。
public ByteArrayOutputStream() {
this(32);
}
// 创建一个新的字节数组输出流,其缓冲区容量为指定大小,以字节为单位。
public ByteArrayOutputStream(int size) {
if (size < 0) {
throw new IllegalArgumentException("Negative initial size: "
+ size);
}
buf = new byte[size];
}
常见问题记录
flush和close区别
- flush方法是刷新此缓冲流。强制将任何缓冲的字节写入底层流。
(避免数据缺失) - close方法是关闭此输入流并释放与该流相关的任何系统资源。
(释放资源) - close方法不一定会调用一次flush方法,有的实现了有的没有实现。
(例如BufferedOutputStream中close会调用一次flush方法)















 780
780











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









