







排序: 是计算机程序设计中一种重要的操作,目的是将一系列杂乱的数据,变成规整,有序的(熵减)数据。(排序算法在程序中是非常常见的,是数据结构与算法中挺重要的一部分。)
维基百科中定义:排序算法是一种能将一串数据依照特定排序方式进行排列的一种算法。最常用到的排序方式是数值顺序以及字典顺序。有效的排序算法在一些算法(例如搜索算法与合并算法)中是重要的,如此这些算法才能得到正确解答。排序算法也用在处理文字数据以及产生人类可读的输出结果。维基百科–排序算法
那么排完序之后呢?
通常排序的目的就是为了数据的查找方便。如果是无序的数据在查找时比较容易实现的操作就是顺序查找了(当然也有很多其他的查找方式:索引顺序表查找,树类操作的查找,哈希查找等等…),其平均查找长度一般为(n+1)/2,即时间复杂度是O(n)级别。
但是呢,如果数据是有序的,我们就能使用另一比较更加高效的查找算法了:二分查找 或称之为折半查找(名字什么的不重要啦)。其平均查找长度为 “lgn” 级别的,即时间复杂度为O(lgn),和O(n)级别相比还是有很大的优势的,特别当数据量特别大的时候就更加明显了。因此对数据进行排序还是挺有必要的吧。
排序算法的分类(并不限于,维基百科上收录了很多没听过的,“稀奇”的名字…):

(好吧,其实感觉分类什么的有点增加记忆负担和“无聊”,但是学习的时候又比较系统化,你能理解各种排序的算法过程和其实际的应用场景就好啦)
一些的概念:
内部排序: 指的是待排序记录存放在计算机随机存储器(一般就是你的主存啦,就是那个几几GB的运行空间的。)中进行的排序过程。
外部排序: 指的是待排记录的数量很大,以致于内存不能一次容纳所有的记录,需多次从外存(硬盘等)中进行读取,进行数据访问的过程。(额,还没遇到过,也不知道具体指的是什么呢)
排序的稳定性:排序的稳定性指的是如果有两个关键字相同的数据,在排序过后其顺序任然按照原来的顺序,则成为该排序时稳定的,否则称为不稳定的。(排序的稳定性有时候我们在作结构体中排序的时候就可能要注意所用的排序是不是稳定了。)
“PS 现在就开始尝试分析(数学分析是不可能的了哈哈。。。)上图中各种算法分类的应用场景和时间复杂度和空间复杂度,到最后再来进行时空复杂度的汇总吧。”
插入排序:
一 直接插入排序:
直接插入排序:(straight insertion sort) 这是一种最简单的排序方法了,它主要呢在未排序的数据中查找一个最大值或最小值插入到已经排好的数据中的合适位置,使得有序序列的长度+1,直到所有的数据都有序。
在我们生活中和直接插入排序很像的就是打扑克牌 😉,我们一般在打扑克牌的时候喜欢将牌顺序排好(不知道你有没有这种习惯哈),这时候每当我们摸到一张牌,都会找到一个合适的位置把它给插入进去,且该位置后面的元素就要向后移动了,这就跟插入排序很像。

下面举一个具体的例子:
序列:49 38 65 97 76 13 27 49*
(注:*号表示另外一个49,用于区分,看是不是稳定的)
具体流程如下:可以将第一个数据看成是一个已经排好序的序列(该序列只有一个元素,这么做就是为了方便理解呢)

其中0号单元为空,可以用来存储每次插入时要进行插入的数据,充当哨兵的作用(一个编程的思想吧,“哨兵:看门的哈”, 可以让代码更加简洁一点),存储要插入的数据呢是为了每次插入时可能存在的移动数据做准备的。
看图的话可能比较容易理解其流程,就是对每次遍历到的数据(最外层循环),在已经排序好的数据中进行插入,并且将该位置之后的元素往后移一个元素。(内层循环)
嗯…下面为比较枯燥的书本上的描述过程:
一般情况下,进行第 i 趟(就是图中左侧的数字)直接插入排序的操作为:在含有 i - 1个数据的有序子序列 r[1…i-1](这里是用1表示第一个元素的,并不是用下标0开始表示的)中插入一个数据 r[i] 后,变成含有 i 个数据的有序子序列 r[1…i] ;在查找插入位置的过程中避免数组下标出界,使用 r[0] 来充当哨兵(就是从 i 往前找位置,当找到 r[0] 的位置即两个值相等(这在有多个相同值时也行得通的)仍然没有插入,那么就插入第一个)。在自 i - 1 起往前搜索的过程中,可以同时向后移动数据。整个排序过程一共进行n - 1趟插入,即:先将序列中的第1个数据看成是一个有序的子序列,然后从第2个数据其逐个进行插入,直至整个序列变成有序的。
代码如下:
void insertSort(int *nums, int n) {
for (int i = 2; i <= n; i++) {
if (nums[i] < nums[i - 1]) {
nums[0] = nums[i]; //存储要插入的元素充当哨兵
nums[i] = nums[i - 1];
int j;
for (j = i - 2; nums[0] < nums[j]; j--) { //找到合适的位置,并且移动元素
nums[j + 1] = nums[j];
}
nums[j+1] = nums[0];
}
}
}
代码执行结果:

复杂度分析:很明显,两重循环,所以时间复杂度为O(n^2),空间复杂度多了个0号单元充当哨兵元素,即为O(1)。
更加详细一点点的分析,这就涉及到一些数学的求和知识啦(任意看啦哈)
1,当数据原本就是有序的时候,只要对数据进行n - 1次比较,即从2开始和前面一个值进行比较,这个时候不需要移动数据为0次,进行数据的比较的时间也达到了最小值为:n - 1;
2,当数据原本是逆序的时候,对数据进行总的比较次数为:1 + 2 + 3 + … + n - 1 = n(n-1)/2;
移动数据的次数也达到了最大值为:1 + 2 + 3 + … + n -1 = n(n-1)/2;
3,当待排数据比较随机的时候,即待排序列中的数据可能出现的各种排列的概率是相同的(即可能出现的位置的概率是相同的),则可以取上述最大值和最小值的平均值(这里并没有给出更加严格和确切的数学证明),作为需要进行的数据比较和移动次数大小,约为n^2/4。因此可以得到直接插入排序的时间复杂度为O(n2)的。
二 折半插入排序
折半插入排序:在直接插入排序中,我们在查找所需要插入的位置的时候是进行从后往前的顺序查找的,由于我们已知前面序列已经是有序的,如果对该序列使用折半查找(二分查找) 对应的位置,则会快速很多。
代码示例:
void binsertSort(int *nums, int n) {
for (int i = 2; i <= n; i++) {
nums[0] = nums[i];
int l = 1; //折半查找的左边界
int r = i - 1; //折半查找的右边界
int mid = 0;
while (l <= r) {
mid = l + (r - l) / 2; //中点位置
if (nums[0] <= nums[mid])
r = mid - 1;
else
l = mid + 1;
}
for (int j = i - 1; j >= r + 1; j--) { //忘后移动位置,这里r+1即是所找到要插入的位置下标
nums[j + 1] = nums[j];
}
nums[r + 1] = nums[0]; //插入该位置
}
}
代码这行结果:(可以试着把每趟遍历的结果都打印出来比较比较)
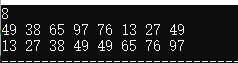
复杂度分析:
由于在查找过程中使用的是折半查找,因此大大减少了查找过程中的数据的比较次数,整体上降为 “lgn” 的比较次数,但是在插入过程中的移动数据的次数并没有减少,任然为n^2级别的。
所以算法整体的时间复杂度任然为O(n2)的。空间复杂度使用了几个临时变量,为O(1)。
三 希尔排序:
从上面的的直接插入排序和折半插入排序可以发现,在插入类排序中,花费时间的来源就是::比较次数和移动数据次数。如果序列能够基本有序的话比较和移动数据的次数将会减少,比如最好的数据原本是“正序的”,其时间复杂度就只有O(n)级别的了。希尔排序(shell’s sort 又称“缩小增量排序” 这个名字更易懂哈)就是从这个方面出发,先通过一些操作是数据“基本”有序,嗯…所谓“基本有序”就是小的值基本排在前面,大的值基本排在后面。
具体是通过:
基本思想:先将整个待排数据序列分割成为若干子序列分别进行直接插入排序,待整个序列中的记录“基本有序”时,在对全体进行一次直接插入排序。《数据结构》-- 严蔚敏
其中最重要的就是怎么对数据进行分割,希尔排序和后面要写的归并排序,快速排序等不太一样的分割是:它是跳跃式选中数据来构成一个子序列的,这次先按照这个增量跳跃式选中数据构成一个子序列,下次在按照另外一个增量来进行跳跃选中数据构成一个子序列,最终选1作为最后增量来选中子序列(即为原来的序列大小),即是最后一步的直接插入排序。
下面举个例子来说明:采用的增量序列是[5,3,1]
每次跳跃“5”选中数据:增量5

每次跳跃“3”选中数据:增量3

最后使用增量为1,即使用直接插入排序,即可得到正确结果:

由上面可见,希尔排序并不是简单将序列逐段分割,而是将相隔某个“增量”的数据组成一个子序列(这和我们一般常用的分割方法不太一样)。
具体代码实现如下:
void shellSort(int *nums,int n,int dx) { //dx为每次增量
for (int i = dx + 1 ; i <= n ; i++) {
if (nums[i] < nums[i - dx]) {
nums[0] = nums[i];
int j;
for (j = i - dx ; j > 0 && nums[j] > nums[0]; j -= d}
nums[j + dx] = nums[j];
}
nums[j + dx] = nums[0];
}
}
for (int i = 1 ; i <= n; i++) {
printf("%d ",nums[i]);
}
printf("\n");
}
int main() {
int n;
scanf("%d",&n);
int *nums = (int *)malloc(sizeof(int) * (n + 1));
for (int i = 1 ; i <= n ; i++) {
scanf("%d",nums + i);
}
for (int i = n / 2; i >= 1 ; i /= 2) { //使用这个来简单模拟增量序列
shellSort(nums,n,i);
}
return 0;
}
复杂度分析: 希尔排序的时间复杂度为O(n(lgn)^2),比O(n2)的要好一点(至于怎么来的就不清楚了哈,和选取的增量序列有关)。空间复杂度也是为O(1)的。
值得注意的是关于希尔排序的增量序列的选取是有要求的,不同的增量序列的时间复杂度的好坏不一样,但是增量序列的最后一个值一定为1。已知的最好增量序列是由Sedgewick提出的(1, 5, 19, 41, 109,…),该序列的项来自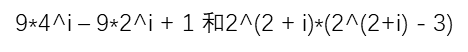 这两个序列中,其中i=0,1…。希尔排序–维基百科
这两个序列中,其中i=0,1…。希尔排序–维基百科
最后:
其他的插入排序还有:2-路趟插入排序,表插入排序等。。。这些排序的复杂度总体上来讲都是平方级别的。
其实直接插入排序或冒泡排序这些比较简单的排序在数据量不大的时候反倒用得比较多,C++的STL中的sort()方法在元素个数比较小的时候就是用的插入排序,虽然是平方级别的复杂度,但是数据量不大的时候还是可以接受的,并且实现也不会太复杂。😉















 527
527











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









