






SPI
在jdbc中我们知道有个操作是我们要实例化一个驱动Driver,然后将其注册到我们的驱动管理器中,经过管理器的getConnection()方法我们可以获取到一个数据库的连接.
但是我们发现以下代码,我们也可以成功获取到连接。
Connection connection = DriverManager.getConnection(url, username, password);
System.out.println(connection);
结果:
com.mysql.cj.jdbc.ConnectionImpl@12cdcf4 //我们也获取到了一个数据库连接
按照上面代码 我们可能会懵逼 ,因为按照我们学的jdbc流程步骤来说,准备好了数据源信息,接着我们就要创建个驱动,同时将其注册到驱动管理器中,这样我们才能获取到连接。
正常需要
String driverName = "com.mysql.cj.jdbc.Driver";
//2.实例化Driver
Class clazz = Class.forName(driverName);
Driver driver = (Driver) clazz.newInstance();
//3.注册驱动
DriverManager.registerDriver(driver);
但是上面代码我们并没有,但是也实现了
先来说注册的这个问题,我们看Driver,这个Driver是mysql实现的Driver 因为每个数据库厂商要和java程序连接,就都要实现java 提供的jdbc接口

我们在这个类中发现了个静态代码块,其中我们发现了注册的代码,也就是我们的注册是在这里完成的,
但是我们也知道静态代码块是在类加载的时候才会被执行(所以这个类一定被加载了),但是我们上面代码并没有去实例化这个类,这个又是谁帮我们去加载的呢?
看来看去我们觉得 这个操作是在getConnection()的时候去触发的,因为其他代码都没这个执行环境。接着我们看看这个方法的执行,看源码就要捉重点 没有必要每行都要看明白,这样也能提高我们读懂代码的能力。
在DriverManager的静态代码块里面我们发现执行了 loadInitialDrivers()这个方法 ,接着看 这个方法实现
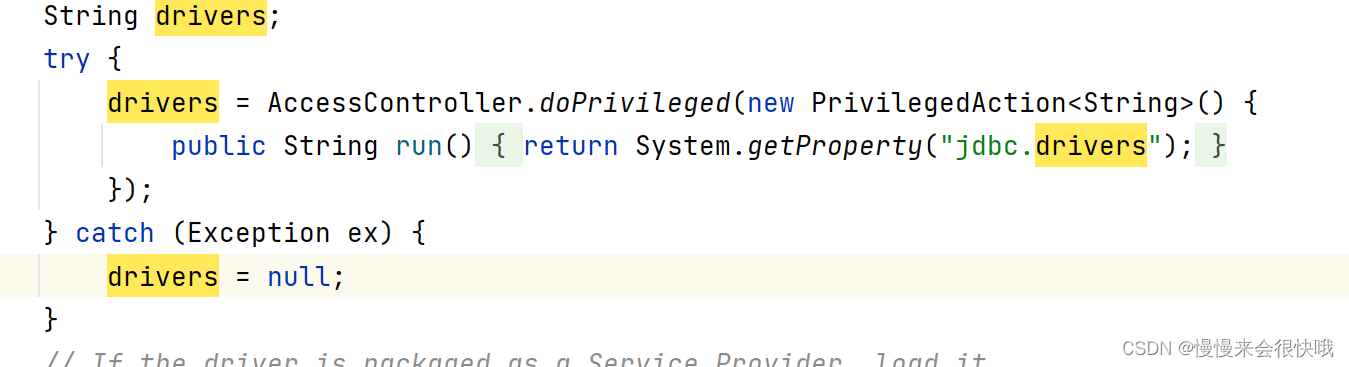
大概看看 这是获取一个系统参数来创建个驱动 这个我们也没有配置 不用看
AccessController.doPrivileged(new PrivilegedAction<Void>() {
public Void run() {
ServiceLoader<Driver> loadedDrivers = ServiceLoader.load(Driver.class);
Iterator<Driver> driversIterator = loadedDrivers.iterator();
/* Load these drivers, so that they can be instantiated.
* It may be the case that the driver class may not be there
* i.e. there may be a packaged driver with the service class
* as implementation of java.sql.Driver but the actual class
* may be missing. In that case a java.util.ServiceConfigurationError
* will be thrown at runtime by the VM trying to locate
* and load the service.
*
* Adding a try catch block to catch those runtime errors
* if driver not available in classpath but it's
* packaged as service and that service is there in classpath.
*/
try{
while(driversIterator.hasNext()) {
driversIterator.next();
}
} catch(Throwable t) {
// Do nothing
}
return null;
}
});
接着看 我们就看到了这段代码 因为获取驱动就看到了这两个方式 因此我们的驱动一定是来自这
关键就是这两行代码了
ServiceLoader<Driver> loadedDrivers = ServiceLoader.load(Driver.class);
Iterator<Driver> driversIterator = loadedDrivers.iterator();
Iterator driversIterator = loadedDrivers.iterator();这个就是用迭代器便利驱动集合
关键的就是怎么得到的这个集合 而关注点就应该落在 load()方法 的实现了 点进去看看
最后发现返回了个这个
return new ServiceLoader<>(service, loader);
下面就不看了 里面 经过判断 会创建个LazyIterator 这个类里面 就提供了 加载接口的方法
接下来就是其实现 也就是SPI的机制
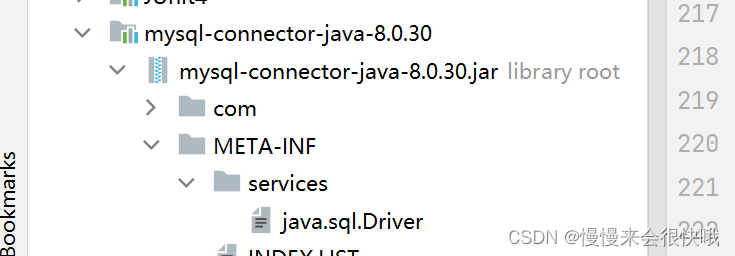
执行获取连接的方法时,会去读取类路径下的 META-INFWE 下的services下的文件,并将其作为接口类用于接收要加载的对象,文件内容则为具体的实现类 在我们这个例子里面就是 mysql的驱动全路径
com.mysql.cj.jdbc.Driver
这也就是spi原理
根据这个原理 我们是否也能这样实现呢,通过建立对应的文件来帮助我们加载对应的对象呢 说干就干
创建个动物类 这里也就相当于上面的接口类 只要有父子关系 就可以的 多态嘛 父类引用当然能接受子类对象
package com.ydl;
public class Animal {
}
接着创建两个子类
package com.ydl;
public class Animal {
}
package com.ydl;
public class Dog extends Animal{
}
接着就是配置文件

com.ydl.Cat
com.ydl.Dog
接着按照上面的服务加载类 模仿一下
package com.ydl;
import java.util.Iterator;
import java.util.ServiceLoader;
public class Client {
public static void main(String[] args) {
ServiceLoader<Animal> loadedDrivers = ServiceLoader.load(Animal.class);
Iterator<Animal> iterator = loadedDrivers.iterator();
while (iterator.hasNext())
{
Animal animal = iterator.next();
System.out.println(animal);
}
}
}
执行一下
com.ydl.Cat@7f31245a
com.ydl.Dog@6d6f6e28


补充:
那么策略模式和 SPI 机制到底有什么区别呢?
如果从代码接入的级别来看,策略模式还是在原有项目中进行代码修改,只不过它不会修改原有类中的代码,而是新建了一个类。而 SPI 机制则是不会修改原有项目中的代码,其会新建一个项目,最终以 Jar 包引入的方式代码。
从这一点来看,无论策略模式还是 SPI 机制,他们都是将修改与原来的代码隔离开来,从而避免新增代码对原有代码的影响。但策略模式是类层次上的隔离,而 SPI 机制则是项目框架级别的隔离。
从应用领域来说,策略模式更多应用在业务领域,即业务代码书写以及业务代码重构。而 SPI 机制更多则是用于框架的设计领域,通过 SPI 机制提供的灵活性,让框架拥有良好的插件特性,便于扩展。
总结一下,策略模式与 SPI 机制有下面几点异同:
从设计思想来看。策略模式和 SPI 机制其思想是类似的,都是通过一定的设计隔离变化的部分,从而让原有部分更加稳定。
从隔离级别来看。策略模式的隔离是类级别的隔离,而 SPI 机制是项目级别的隔离。
从应用领域来看。策略模式更多用在业务代码书写,SPI 机制更多用于框架的设计。
关于策略模式与 SPI 机制就说到这里,如果有什么想了解的,欢迎留言告诉我。
完结















 2200
2200











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









