







 在我的博客从url输入到页面渲染:渲染流程(一)中介绍了渲染阶段的第一个步骤:构建DOM树,通过树解析算法解析器将HTML转换成浏览器可以识别的DOM树结构,但是此时我们我们仍然不知道每个DOM节点的正确样式,因此此时需要进入第二步:样式计算。样式计算样式计算的目的是计算出DOM节点中每个元素的具体样式,这个阶段大体上可以分为如下三步:1、CSS文本转换为styleSheets...
在我的博客从url输入到页面渲染:渲染流程(一)中介绍了渲染阶段的第一个步骤:构建DOM树,通过树解析算法解析器将HTML转换成浏览器可以识别的DOM树结构,但是此时我们我们仍然不知道每个DOM节点的正确样式,因此此时需要进入第二步:样式计算。样式计算样式计算的目的是计算出DOM节点中每个元素的具体样式,这个阶段大体上可以分为如下三步:1、CSS文本转换为styleSheets...
在我的博客从url输入到页面渲染:渲染流程(一)中介绍了渲染阶段的第一个步骤:构建DOM树,通过树解析算法解析器将HTML转换成浏览器可以识别的DOM树结构,但是此时我们我们仍然不知道每个DOM节点的正确样式,因此此时需要进入第二步:样式计算。
样式计算
样式计算的目的是计算出DOM节点中每个元素的具体样式,这个阶段大体上可以分为如下三步:
一、CSS文本转换为styleSheets
和HTML文件一样,浏览器无法直接理解这种纯文本的CSS样式,因此当浏览器渲染引擎接收到CSS文本时会执行一个转换操作,将CSS文本装换成一种浏览器可以理解的结构——styleSheets。
我们在控制台输入document.styleSheets可以查看浏览器生成的styleSheets结构:
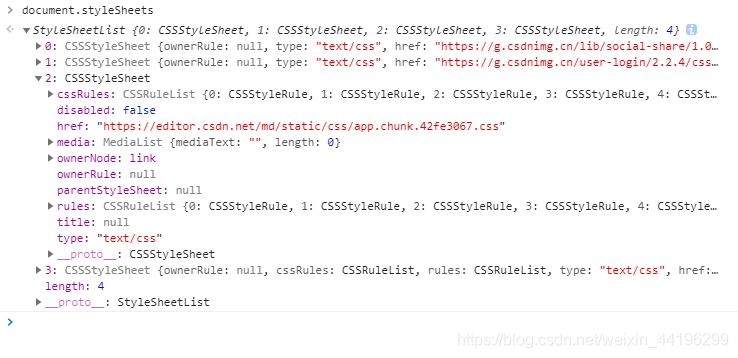
那么渲染引擎是如何将CSS文本转换为styleSheets结构呢?
1、加载CSS
在我的同系列博客从url输入到页面渲染:渲染流程(一)中介绍了HTML文档解析构建DOM树的过程,事实上如果在DOM树的构建过程中遇到link标签,当把它插入到DOM里面后就会触发资源加载,如下所示:
<link rel="stylesheet" href="demo.css">
上面的rel属性表明它是一个样式文件,href属性表明了其资源加载的链接路径,这个资源加载是一个异步加载,并不会影响DOM树的构建,但是我们需要注意到在CSS没有处理好之前构建好的DOM并不会显示出来,以下面代码为例:
<!DOCType html>
<html>
<head>
<link rel="stylesheet" href="demo.css">
</head>
<body>
<div class="text">
<p>hello, world</p>
</div>
</body>
dom.css文件的内容如下:
.text{
font-size: 20px;
}
.text p{
color: #505050;
}
整体解析过程如下图所示:

在CSS没有加载好之前,DOM树已经构建好了。为什么DOM构建好了不把html放出来,因为没有样式的html直接放出来,给人看到的页面将会是乱的。所以CSS不能太大,页面一打开将会停留较长时间的白屏,所以把图片/字体等转成base64放到CSS里面是一种不太推荐的做法。
2、解析CSS
(1)字符串 -> tokens
CSS解析和html解析的过程有很多相似的地方,都是先将字符串格式化为tokens。CSS token定义了很多种类型,如下所示的CSS样式会被拆成多个token:
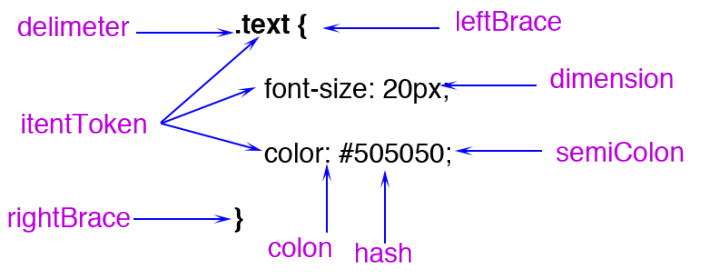
(2)tokens -> styleRule
每个styleRule主要包含两个部分,一个是选择器selectors,第二个是属性集properties。用以下CSS:
.text .hello{
color: rgb(200, 200, 200);
width: calc(100% - 20px);
}
#world{
margin: 20px;
}
解析生成的选择器结果如下所示:

从上图我们也可以看出选择器的解析是从右向左进行的,因此先识别出的是.hello选择器,其次才是.text选择器。同时我们也注意到了解析结果中的matchType和relation字段,那么这两个字段分别代表着什么呢?
blink定义了如下matchType,是选择器匹配元素的主要方式:
enum MatchType {
Unknown,
Tag, // Example: div
Id, // Example: #id
Class, // example: .class
PseudoClass, // Example: :nth-child(2)
PseudoElement, // Example: ::first-line
PagePseudoClass, // ??
AttributeExact, // Example: E[foo="bar"]
AttributeSet, // Example: E[foo]
AttributeHyphen, // Example: E[foo|="bar"]
AttributeList, // Example: E[foo~="bar"]
AttributeContain, // css3: E[foo*="bar"]
AttributeBegin, // css3: E[foo^="bar"]
AttributeEnd, // css3: E[foo$=&# 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4754
4754











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









