







一、情绪识别综述
(一)概述
语音情绪识别(Speech Emotion Recognition,SER)是指通过一段语音的声学特征(该特征与语音的内容信息和语种信息无关)来识别说话人的情绪状态的技术。说话人可通过调整发音器官的动作来改变语音信号的声学特征来表达不同的情绪。目前基于语音信号的情绪识别模型主要分为两类:离散形式情绪描述模型和连续形式情绪描述模型。离散形式情绪描述模型通过将情绪描述为离散的、形容词标签的形式,如生气(anger)、开心(happiness)、惊讶(surprise)、恶心(disgust)、害怕(fear)和难过(sad)等。连续形式情感描述模型将情绪描述为多维情感空间中的点,空间中的每一维对应情感的一个心理学属性。例如在一个二维的空间中,激活度(arousal)表示情感激烈程度,效价(valence)表示情感正负面程度。开心(happiness)可以用高激活度和高效价来表示,难过(sad)可以用低激活度和低效价来表示。

(二)应用
(1)在交通安全领域,语音情绪识别技术可以通过麦克风手机声音数据来监控驾驶员的疲劳程度与是否分心,判断是否需要自动驾驶,监控驾驶员的情绪状况从而降低交通事故发生的风险。
(2)在医疗健康领域,在进行心理诊断和治疗时,语音情感识别系统可以协助医生识别患者的情绪状态,判断患者是否存在抑郁、焦虑等心理状态并给与相应的治疗。护理人员可以通过多模态情绪识别检测老年人的生活状态,及时采取相应的护理措施。
(3)在信息安全领域,语音情感识别技术可以通过识别说话人的情绪状态进而识别出可能存在的欺诈、诈骗、间谍活动等威胁。在测谎的应用上,语音情感识别技术主要是通过分析声音中的语调、语速、声音质量、说话人的表现和情感等多个方面的特征来分析说话人是否在说谎;在客服系统领域可以对客服人员和客户的语音片段进行分析,从而确定客服的服务质量和客户的满意程度等。
(三)评价指标
语音情绪识别可以使用普通准确率(Unweight Accuracy)、加权准确率(Weight Accuracy)、加权F1-score(Weight F1-score)等进行算法性能测试。
(四)数据集
| 名称 | 语言 |
|---|---|
| IEMOCAP | 英文 |
| CAISA | 中文 |
| EMOVO | 意大利语 |
| EmoDB | 德语 |
| SAVEE | 英语 |
| RAVDESS | 英语 |
(五)竞赛
(1)多模态情感识别挑战赛
该竞赛开始于2016年,该竞赛英文名称为The multimodal emotion recognition challenge,统称为MEC或MER,由清华大学陶建华教授联合中国科学院自动化研究所连政助理研究员,南洋理工大学Erik Cambria教授,帝国理工学院Björn W. Schuller教授、奥卢大学赵国英教授在国际顶级人工智能学术会议ACM MM上举办。
(2)多模态情感分析挑战赛
英文全称 The Multimodal Sentiment Analysis Challenge(MUSE)。开始于2020年,由多媒体国际顶级会议ACM Multimedia举办,英国帝国理工学院、德国奥斯堡大学、芬兰奥卢大学等高校共同发起。
二、语种识别和情绪识别技术方案
(一)传统方法
传统语音情绪识别方法一般分为两个步骤:情绪特征提取和统计建模。语音情绪识别常用的特征包括:
(1)韵律和能量特征,情绪的变化直接反映在整体韵律和能力的变化上。
(2)语音质量特征,发音人的情绪质量会影响语音质量。
(3)谱特征,虽然情绪变化直接反映在韵律和能量等长时连续信息中,这种变化也会间接的反映在谱特征本身的分布形态中。
(4)Teager能量特征,研究表明语音信号的Teager能量特征可以表征不同频带之间的相互作用。
上述四种特征是帧级别的,缺少上下文信息,因此称为局部特征。另一种特征是在这些局部特征的特征基础上,提取特征的长时统计量,包括最大值、最小值、均值、方差等,这些统计量称为全局特征。
统计建模方法包括离散情绪模型和连续情绪模型,离散语音情绪建模基于各种通用分类模型,包括高斯混合模型(GMM)、隐马尔可夫模型(HMM)、支持向量机(SVM)等。连续情绪模型通过建立合理的回归模型,对所定义的连续情绪属性进行拟合和预测。Tian等人基于AVEC2012数据集和IEMOCAP数据集在四个维度(激发值、期待值、强势度、愉悦度)上进行情绪预测。
(二)基于深度学习的方法
早期基于DNN的情绪识别将DNN作为替代SVM的分类工具。后续出现了使用DNN预测帧级别的情绪后验概率,并基于HMM对句子进行建模的方法。Han[13]等人使用DNN对语音信号做帧级别的情绪分类,并通过简单的统计函数得到句子级别的全局特征,最后使用SVM进行情绪分类。
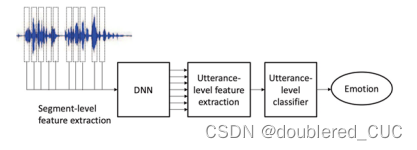
图2 基于DNN特征提取的语音情绪识别流程
Zheng等人[提出了一种基于CNN的端到端学习结构,通过多层卷积和池化将语音信号直接映射为情绪的后验概率。Trigeorgis等人则提出了更加端到端的结构,通过将原始语音输入若干CNN层和LSTM-RNN层,将语音信号直接映射为连续情绪变量。
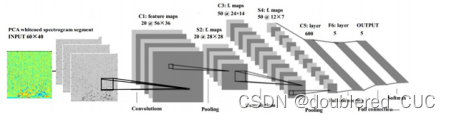
图3 基于CNN的端到端语音情绪识别模型
在语音情绪识别建模中,注意力机制可以从一段语音中选择最具情绪表现力的部分,因此可以有效提高识别性能。

图4 基于Attention-CNN的语音情绪识别模型
为了进一步提高语音情绪识别的性能,基于深度学习的不同学习方法也被引入。包括特征学习、迁移学习和多任务学习方法。
Mao等人提出了一种基于CNN的区分性特征学习方法,该方法首先通过CNN编码器将输入语音片段编码为特征向量,然后通过显著区分特征分析提取特征向量中与情绪相关的成分。该特征可以送入分类器进行情绪识别。
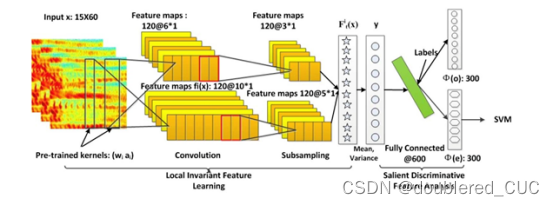
图5 基于CNN的区分性特征学习语音情绪识别模型
迁移学习指的是基于某一场景或某一任务训练得到的模型,可以迁移到另一个场景或另一个任务中。在语音情绪识别中,Pappagari等人发现在说话人识别任务上训练的x-vector模型可用于初始化情绪识别模型。
多任务学习是指对相关(或互斥)任务同时进行学习,以提高主要任务或所有任务的性能。Li等人提出了一种基于语音信号分解的多任务学习方法,首先解码出语音信号的发音内容,第二步解码出说话人信息,最后对情绪进行识别,通过将发音内容和说话人信息预先分离出去,有效降低了情绪识别的难度。
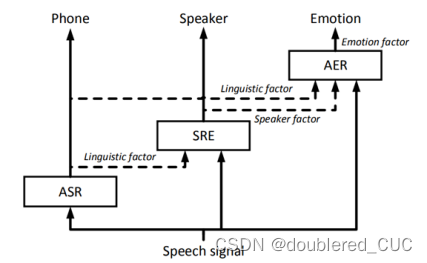
图6 基于语音信号分解的语音情绪识别方法
三、 现有SOTA方法
1.DWFomer
论文题目:DWFormer: Dynamic Window Transformer for Speech Emotion Recognition
来源:ICASSP2023,华南理工大学
code:https://github.com/scutcsq/dwformer. 27 stars
论文背景:表示不同情绪的时间区域分散在语音的不同区域,重要情绪信息的时间尺度在语音片段内和跨语音片段上有很大范围的变化。基于Tansformer的语音情绪识别模型在不同时间尺度下无法准确定位重要的情绪信息。
论文创新点:本论文提出了动态窗口Transformer(Dynamic Window Transformer,DWFormer)来进行情绪识别任务。DWFormer由动态局部窗口Transformer(Dynamic Local Window Transformer,DLWT)和动态全局窗口Transformer(Dynamic Global Window Transformer,DGWT)组成。DLWT将语音特征动态地分为不同尺度的窗口,并在每个窗口捕捉局部信息。DGWT在DLWT之后,重新计算每个窗口的重要程度。
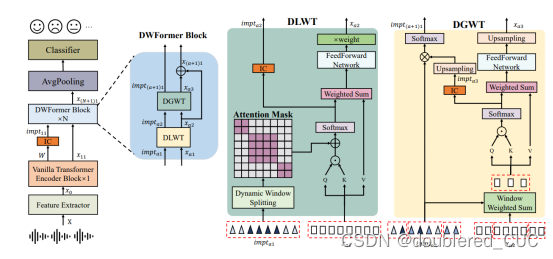
图7 DWFormer的模型结构图
论文实验结果:
其中WA表示加权准确率,UA表示普通准确率,WF1表示加权F1 score。在多分类问题中,加权方式是一种考虑每个类别样本数量的计算方式。对于样本不均衡的情况,该方式比较适用。其计算方式是将每个类别的准确率/F1 score乘以该类别在总样本中的比例(权重),然后求和。
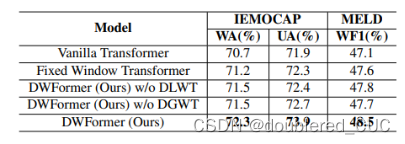
表1 DWFormer与不同基线模型的实验结果比较1
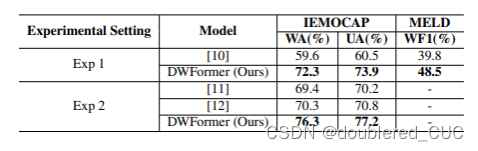
表2 DWFormer与不同基线模型的实验结果比较2
其中[10]指的是使用 Attentional temporal dynamic activation 来进行语音情绪识别的模型,[11]是使用Temporal-aware bi-direction Multi-scale Network进行情绪识别的模型。[12]是使用Temporal attention convolutional网络进行情绪识别的模型。
2.TIM-Net
论文题目:Temporal Modeling Matters: A Novel Temporal Emotional Modeling Approach for Speech Emotion Recognition
来源:ICASSP2023,复旦大学
code:https://github.com/Jiaxin-Ye/TIM-Net_SER 113 stars
论文背景:传统时序情感建模方法对长范围的上下文信息进行建模的能力不足,而且由于只能感知固定的时间尺度,传统方法会受到不同说话者的发音速度和停顿时间的严重影响。本论文探索了如何从动态时间尺度上建模语音情感的时间模式。
论文创新点:本文提出了时序的双向多尺度网络,称为TIM-Net,TiM-Net基于膨胀因果卷积(Dilated Causal Convolution)。同时设计了双向结构来融合过去和未来的互补信息。最后还设置了一个动态融合模块来融合动态处理不同尺度的语音信号。
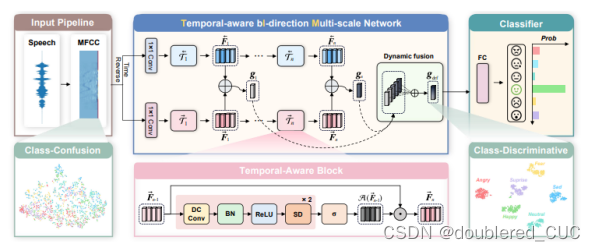
图8 TIM-Net的模型结构图
相关实验结果:
实验使用了普通准确率(前)和加权准确率(后)作为评测指标。
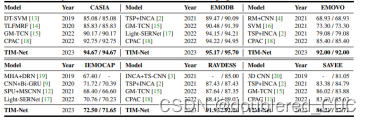
表3 TIM-Net与SOTA模型的在不同数据集上的实验结果
3.SpeechFormer++
论文题目:SpeechFormer++: A Hierarchical Efficient Framework for Paralinguistic Speech Processing
来源:IEEE/ACM Transactions on Audio, Speech, and Language Processing(TASLP),华南理工大学
Code:https://github.com/happycolor/speechformer2 28 stars
论文背景:传统Transformer在处理语音信号时并没有考虑语音信号的特性,导致Transformer在语音领域的能力并未完全发掘。本文充分考虑了语音信号的特性,提出了一个通用的针对语音副语言信息处理的框架SpeechFormer++。
论文创新点:基于语音中word、phone、frame之间的hierarchical relationships,本文设计了一个hierarchical 网络SpeechFormer++来处理语音的副语言信息。SpeechFormer++通过单元编码器和融合模块来模拟语音信号的结构模式,并引入磁编码器来平衡细粒度和粗粒度信息。
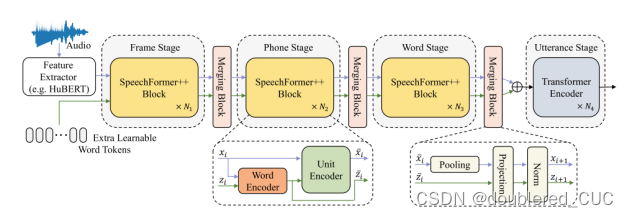
图9 SpeechFormer++的模型结构图
相关实验结果:
其中WA表示加权准确率,UA表示普通准确率,WF1表示加权F1 score。

表4 SpeechFormer++和Transformer在IEMOCAP数据集上的情绪识别实验结果
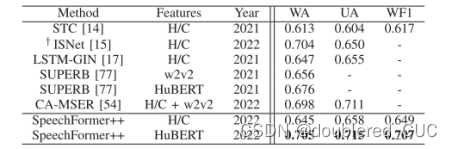
表5 SpeechFormer++与其他SOTA模型的在IEMOCAP上的实验结果(H/c表示手工特征如梅尔谱,MFCC等,w2v2表示wav2vec2.0)
4.CA-MSER
论文题目:Speech Emotion Recognition with Co-Attention Based Multi-Level Acoustic Information
来源:ICASSP2022,南洋理工大学
Code:https://github.com/vincent-zhq/ca-mser 79 stars
论文背景:语音情绪识别的通常做法是先抓取MFCC/MEL-Spectrogram,CQT等特征,然后将相关的谱图作为一个图像分类问题。这些方法简单直接但是却忽略了语音信号的时域信息。
论文创新点:本文提出了一种基于共同注意力机制模块的端到端语音情绪识别系统,该系统使用CNN提取梅尔谱、BiLSTM提取MFCC、基于Transformer的网络提取wav2vec2特征。使用共同注意力机制来进行特征融合。
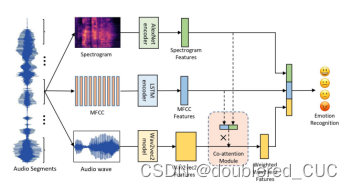
图10 CA-MESR的模型结构图
相关实验结果:
其中上表为5折交叉验证的实验结果,下表为10折交叉验证的实验结果。WA表示加权准确率,UA表示普通准确率。
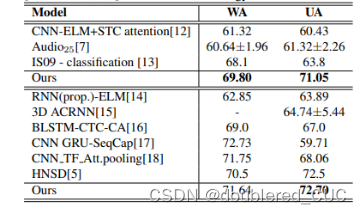
表6 CA-MESR和其他SOTA模型在IEMOCAP数据集上的实验结果
5.LIGHT-SERNET
论文题目:LIGHT-SERNET: A Lightweight Fully Convolutional Neural Network for Speech Emotion Recognition
来源:ICASSP2022,谢里夫科技大学(伊朗)
Code:https: //github.com/AryaAftab/LIGHT-SERNET 54 stars
论文背景:传统语音情绪识别模型需要大量的计算和存储资源,难以与嵌入式系统中的其他机器交互任务同时实现,因此本文提出了只用CNN进行语音情绪识别任务的模型。
论文创新点:本文提出了一种轻量级的全卷积神经网络(FCNN)来进行语音情绪识别,FCNN使用具有不同滤波器大小的三个并行路径提取各种特征图。

图10 LIGHT-SERNET的模型结构图
相关实验结果:
其中,Size表示模型大小,WA表示加权准确率,UA表示普通准确率,WF1表示加权F1 score。
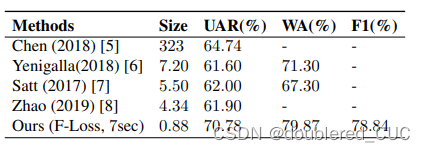
表7 LIGHT-SERNET和其他SOTA模型在IEMOCAP数据集上的实验结果
6.GLAM
论文题目:Speech Emotion Recognition with Global-Aware Fusion on Multi-scale Feature Representation
来源:ICASSP2022,度小满
Code:https://github.com/lixiangucas01/glam 27 stars
论文背景:传统语音情绪识别研究集中在学习固定尺度的特征表征上,这种方式忽视了不同尺度的影响,无法很好的捕捉不同尺度上的丰富情感特征和重要的全局信息。现有的注意力模型虽然可以描述细微的信息,但缺乏对全局信息的感知。
论文创新点:本文提出了一种Global-Aware Multi-scale(GLAM)网络,通过多尺度表征学习和全局感知融合模块来提高语音情绪识别的性能。
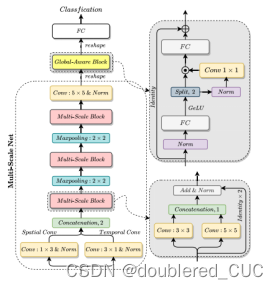
图11 GLAM的模型结构图
相关实验结果:
其中,按照IEMOCAP数据集中的演员是否按照固定脚本进行音频录制,分为Improvisation(即兴)、Script和Full三种数据数据。评测指标为WA表示加权准确率,UA表示普通准确率,micro F1 score表示加权F1 score,macro F1 score表示普通F1 score。
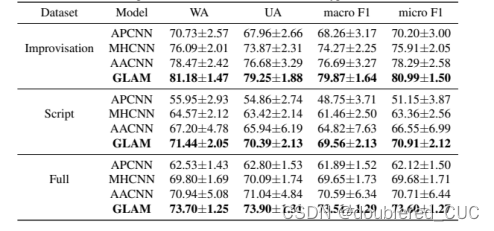
表8 GLAM和其他SOTA模型在IEMOCAP数据集上的实验结果
7.FT-w2v2-ser
论文题目:Exploring Wav2vec 2.0 fine-tuning for improved speech emotion recognition
来源:ICASSP2023,卡内基梅隆大学(美国)
Code:https://github.com/b04901014/FT-w2v2-ser 105 stars
论文背景:传统语音情绪识别研究使用神经网络从音频信号中自动学习情感表示,但是由于现有的语音情绪识别数据集比较小,标注数据比较缺乏,因此会限制性能。而且,之前的研究主要集中在使用预训练模型作为特征提取器,而对于语音情感识别的微调方法研究较少。
论文创新点:本文使用Wav2Vec2进行微调来提高语音情绪识别的性能。通过实验不同的微调策略来改进Wav2Vec2在语音情绪识别上的性能。
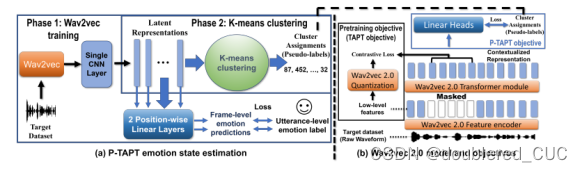
图12 P-TAPT的模型结构图
相关实验结果:
其中,V-FT指的是vanilla fine-tuning,TAPT指task adaptive pretraing,P-TAPT指Pesudo-label task adaptive pretraing。Session指的是按照不同数量的划分的测试集,从1到5将数据量逐次减半。
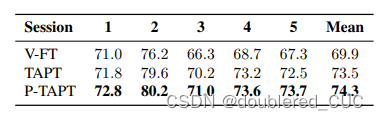
表9 wav2vec2不同微调方式在IEMOCAP数据集上的实验结果
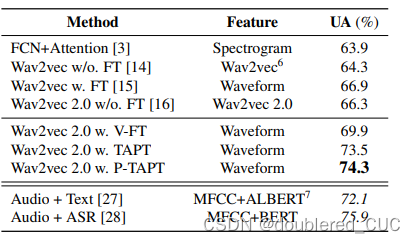
表10 wav2vec2不同微调方式与其他方法在IEMOCAP数据集上的实验结果
8.MLT-SER
论文题目:Speech Emotion Recognition with Multi-task Learning
来源:INTERSPEECH2021 百度
Code:https://github.com/TideDancer/interspeech21_emotion 73 stars
论文背景:传统语音情绪识别系统需要强大的领域知识和对语音的深入理解,而近些年端到端深度神经网络模型已经成为语音情感识别任务的主流框架。
论文创新点:本文利用多任务学习框架,结合预训练的Wav2Vec2模型,有效提高了语音情绪识别任务上的性能。模型采用Wav2Vec2进行预训练,在SER和ASR任务上进行微调。
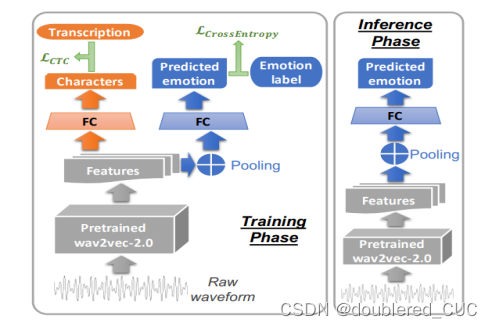
图13 MLT-SER的模型结构图
相关实验结果:
相关基线描述如表11所示,实验结果如表12所示。acc指普通准确率。
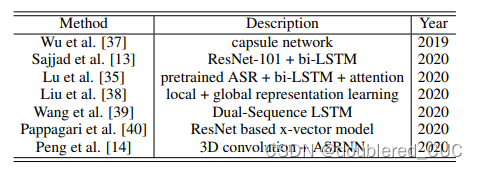
表11 相关基线模型网络结构和时间
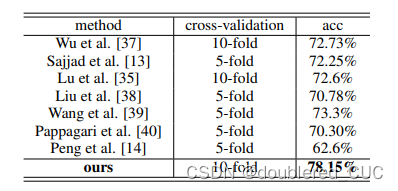
表12 MLT-SER和其他基线模型在IEMOCAP数据集上的实验结果
9.SPEAKER VGG CCT
论文题目:SPEAKER VGG CCT: Cross-corpus Speech Emotion Recognition with Speaker Embedding and Vision Transformers
来源:ACM MM2022佛罗伦萨大学(意大利)
Code:https://github.com/jabumldev/speaker-vgg-cct 13 stars
论文背景:传统语音情绪识别使用手工设计的声学特征和传统机器学习方法,或者使用深度学习方法结合频谱图作为输入进行情绪识别。但是这些方法在数据量不足和跨语料库条件下会存在性能下降的问题。
论文创新点:本文提出了一种基于Compact Convolutional Transformers(CCTs)和说话人嵌入的情绪识别方法来克服数据不足和跨语料库的问题。通过将CCTs和说话人嵌入相结合,该方法能够从频谱图中提取特征并在实时状态下进行情绪识别。
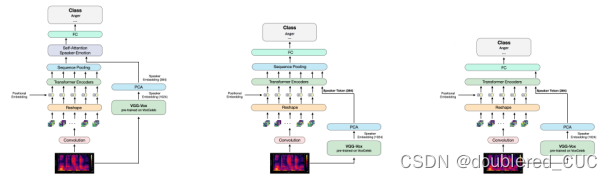
图14 Speaker VGG CCT的模型结构图,左边为原始结构,中间为CCT端到端结构,右边为CCT speaker token结构
相关实验结果:
相关跨数据集测试结构如表13所示,跨数据集指在IEMOCAP和DEMOS上进行训练,在EmoDB、EMOVO、SAVEE上进行测试。Accuracy指普通准确率。UAR指非加权平均召回率,macro F1 score表示普通F1 score。
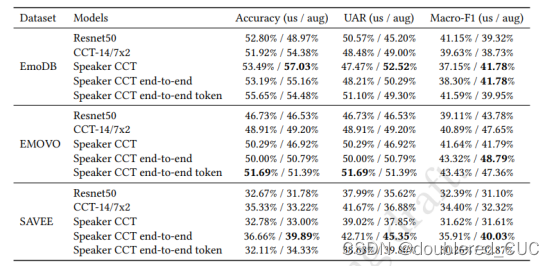
表13 SPEAKER VGG CCT和其他基线模型在不同数据集上的实验结果

















 3453
3453

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









