







一. 实验目的
1.为了更好的配合《编译原理》有关词法分析章节的教学
2.加深和巩固学生对于词法分析的了解和掌握
3.让学生初步的认识PL/0语言的基础和简单的程序编写
4.学生通过本实验能够初步的了解和掌握程序词法分析的整个过程
5.高学生的上机和编程过程中处理具体问题的能力
二. 实验要求
1.做本实验之前要先阅读完总体的预备知识以及本实验相关的基础知识
2.实验要求自己独立的完成,不允许抄袭别人的实验结果
3.做本实验之前要先阅读完总体的预备知识以及本实验相关的基础知识
4.编写和调试过程中出现的问题最好做一下记录
5.实验程序调试完成后,提交给实验教师检查,并由老师给予相应的成绩
6.实验完成后,要上交实验报告。
三. 实验内容
词法分析程序GETSYM的功能包括:
1.滤空格,空格在词法分析时是一种不可缺少的界符,而在语法分析时是无用的,所以必须滤掉。
2.识别保留子:设有一张保留字表。对每个字母打头的字母、数字字符串要查此表。若查着则为保留字,对应的类别放在SYM中。如IF对应值为THENSYM。
3.识别标识符:对用户定义的标识符将IDENT放在SYM中,标识符本身的值放在ID中。
4.拼数:当所取单词是数字时,将树的类别NUMBER放在SYM中,数值本身的值放在NUM中。
5.拼复合词:对两个字符组成的算符如:>=、:=、<= 等单词,识别后将类别送SYM中。
6.打印源程序:为边读入字符边打印
实现代码:
#include <stdio.h>
#include <string.h>
#define norw 13 /*关键字个数*/
#define nmax 14 //number的最大位数
#define al 10 //符号的最的长度 符号就是+ - 神马的
#define cxmax 200 //最多的虚拟机代码数
/*
enum symbol {
nul, ident, number, plus, minus, times, slash, oddsym, eql, neq,
lss, leq, gtr, geq, lparen, rparen, comma, semicolon, period, becomes,
beginsym, endsym, ifsym, thensym, whilesym, writesym, readsym, dosym,
callsym, constsym, varsym, procsym,
};
*/
FILE* fa1; //输出分析的文件和首地址 首地址是虚拟机指针
char ch; //getch读取的字符
//enum symbol sym;
char id[al+1]; //当前的ident
int num;
int cc, ll; //getch计数器
int cx; //虚拟机代码指针,取值范围0-cxmax-1
char line[81];
char a[al+1]; //读取一个符号 暂时存在这里
char word[norw][al]; //保留字13个 就是begin end if 什么的
//enum symbol wsym[norw]; //保留字对应的符号 begin对应beginsym
//enum symbol ssym[256]; //单字符的符号值
FILE* fin;
FILE* fout;
char fname[al]; //输入的文件名
int err;
#define getchdo if(-1==getch()) return -1;
void error(int n);
void error(int n)
{
char space[81];
memset(space, 32, 81);
space[cc-1] = 0;
printf("****出现错误\n");
fprintf(fa1, "****出现错误\n");
err++;
}
int getch()
{
if(cc == ll)
{
if(feof(fin))
{
printf("\n读完了!\n");
return -1;
}
ll = 0;
cc = 0;
//printf("%d ", cx);
//fprintf(fa1, "%d", cx);
ch = ' ';
while(ch != 10)
{
if(fscanf(fin, "%c", &ch) == EOF)
{
line[ll] = 0;
break;
}
printf("%c", ch);
line[ll] = ch;
ll++;
}
printf("\n");
}
ch = line[cc];
cc++;
return 0;
}
int getsym()
{
int i, j, k;
while(ch == ' ' || ch == 10 || ch == 9||ch== 13)
{
getchdo;
}
if(ch >= 'a' && ch <= 'z')
{
k = 0;
do
{
if(k < al)
{
a[k] = ch;
k++;
}
getchdo;
}while(ch >= 'a' && ch <= 'z' || ch >= '0' && ch <= '9');
a[k] = '\0';
strcpy(id, a);
i = 0;
j = norw-1;
do
{
k = (i+j)/2;
if(strcmp(id, word[k]) <= 0)
j = k-1;
if(strcmp(id, word[k]) >= 0)
i = k+1;
}while(i <= j);
if(i-1 > j)
{
printf("保留字 (1,'%s')\n", id);
}
else
{
printf("标识符 (3,'%s')\n", id);
}
}
else
{
if(ch >= '0' && ch <= '9')
{
k = 0;
num = 0;
//sym = number;
do
{
num = num * 10 + ch - '0';
k++;
getchdo;
}while(ch >= '0' && ch <= '9');
k--;
if(k > nmax)
{
error(30);
}
printf("整 数 (2,'%d')\n",num);
}
else
{
if(ch == ':')
{
getchdo;
//k=0;
//b[k]=ch;
if(ch == '=')
{
//sym = becomes;
printf("运算符 (4,':=')\n");
getchdo;
}
else
{
printf("error!不允许单独使用’:‘\n");
}
}
else
{
if(ch == '<')
{
getchdo;
if(ch == '=')
{
printf("运算符 (4,'<=')\n");
getchdo;
}
else
{
printf("运算符 (4,'<')\n");
}
}
else
{
if(ch == '>')
{
getchdo;
if(ch == '=')
{
printf("运算符 (4,'>=')\n");
getchdo;
}
else
{
printf("运算符 (4,'>')\n");
}
}
else
{
if(ch=='+')
{
printf("运算符 (4,'+')\n");
getchdo;
}
else if(ch=='-')
{
printf("运算符 (4,'-')\n");
getchdo;
}
else if(ch=='*')
{
printf("运算符 (4,'*')\n");
getchdo;
}
else if(ch=='/')
{
printf("运算符 (4,'/')\n");
getchdo;
}
else if(ch=='#')
{
printf("运算符 (4,'#')\n");
getchdo;
}
else if(ch=='(')
{
printf("分界符 (5,'(')\n");
getchdo;
}
else if(ch==')')
{
printf("分界符 (5,')')\n");
getchdo;
}
else if(ch=='{')
{
printf("分界符 (5,'{')\n");
getchdo;
}
else if(ch=='}')
{
printf("分界符 (5,'}')\n");
getchdo;
}
else if(ch=='\"')
{
printf("分界符 (5,'\"')\n");
getchdo;
}
else if(ch=='\!')
{
printf("分界符 (5,'\!')\n");
getchdo;
}
else if(ch==',')
{
printf("分界符 (5,',')\n");
getchdo;
}
else if(ch==';')
{
printf("分界符 (5,';')\n");
getchdo;
}
else if(ch=='.')
{
printf("分界符 (5,'.')\n");
getchdo;
}
else
{
printf("error!请检查代码是否拼写正确!\n");
return -1;
}
}
}
}
}
}
return 0;
}
void init()
{
/*
int i;
for(i = 0; i < 256; i++)
ssym[i] = nul;
ssym['+'] = plus;
ssym['-'] = minus;
ssym['*'] = times;
ssym['/'] = slash;
ssym['('] = lparen;
ssym[')'] = rparen;
ssym['='] = eql;
ssym[','] = comma;
ssym['.'] = period;
ssym['#'] = neq;
ssym[';'] = semicolon;
*/
strcpy(&(word[0][0]), "begin");
strcpy(&(word[1][0]), "call");
strcpy(&(word[2][0]), "const");
strcpy(&(word[3][0]), "do");
strcpy(&(word[4][0]), "end");
strcpy(&(word[5][0]), "if");
strcpy(&(word[6][0]), "odd");
strcpy(&(word[7][0]), "procedure");
strcpy(&(word[8][0]), "read");
strcpy(&(word[9][0]), "then");
strcpy(&(word[10][0]), "var");
strcpy(&(word[11][0]), "while");
strcpy(&(word[12][0]), "write");
/*
wsym[0] = beginsym;
wsym[1] = callsym;
wsym[2] = constsym;
wsym[3] = dosym;
wsym[4] = endsym;
wsym[5] = ifsym;
wsym[6] = oddsym;
wsym[7] = procsym;
wsym[8] = readsym;
wsym[9] = thensym;
wsym[10] = varsym;
wsym[11] = whilesym;
wsym[12] = writesym;
*/
}
int main()
{
printf("请输入要分析的文件名:\n");
scanf("%s", fname);
fin = fopen(fname, "r");
if(fin)
{
/*
printf("请输入要保存的文件名\n");
scanf("%s", fname);
fa1 = fopen(fname, "w");
*/
init();
printf("\n分析完毕!\n\n");
err = 0;
cc = cx = ll = 0;
ch = ' ';
while(getsym() != -1)
{
//printf("111\n");
}
}
else
{
printf("找不到文件\n");
}
printf("\n");
return 0;
}
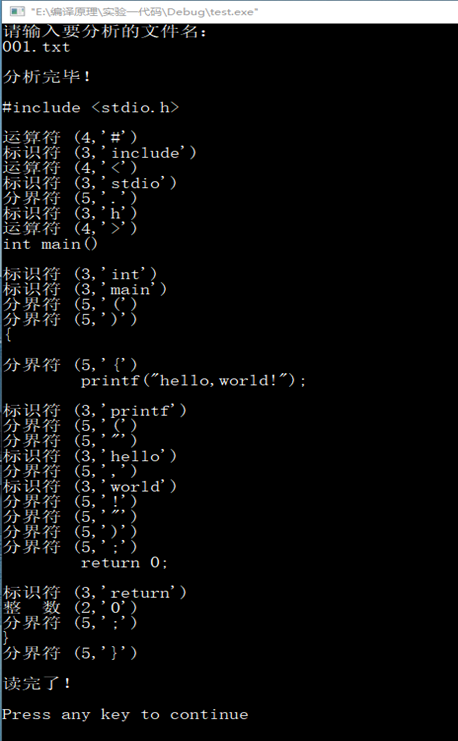
001.txt文档内容:
#include <stdio.h>
int main()
{
printf("hello,world!");
return 0;
}
实验结果:















 2796
2796











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









