







事务到底是隔离还是不隔离的?
在MySQL里,有两个"视图"的概念:
- 一个是view。它是是一个用查询语句定义的虚拟表,在调用的时候执行查询语句并生成结果。创建视图的语法是 create view,而它的查询方法与表一样。
- 另一个是 InnoDB 在实现 MVCC 时用到的一致性读视图,即 consistent read view,用于支持 RC(Read Committed,读提交)和 RR(Repeatable Read,可重复度)隔离级别的实现。它没有物理结构,用来在事务执行期间定义“我能看到什么数据”。
“快照”在 MVCC 里是怎么工作的?
InnoDB 里面每个事务有一个唯一的事务 ID,叫作 transaction id。它是在事务开始的时候向InnoDB 的事务系统申请的,是按申请顺序严格递增的。
而每行数据也都是有多个版本的。每次事务更新数据的时候,都会生成一个新的数据版本,并且把 transaction id 赋值给这个数据版本的事务 ID,记为 row trx_id。同时,旧的数据版本要保留,并且在新的数据版本中,能够有信息可以直接拿到它(这里的信息指的是什么呢?请hxd们打在公屏上)。
也就是说,数据表中的一行记录,其实可能有多个版本 (row), 每个版本有自己的 row trxid。
如图2所示,就是一个记录被多个事务连续更新后的状态。
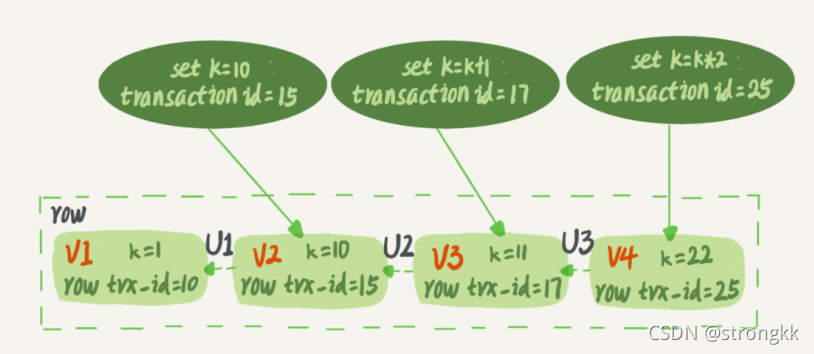 图 2 行状态变更图
图 2 行状态变更图
图中虚线框里是同一行数据的 4 个版本,当前最新版本是 V4,k 的值是 22,它是被transaction id 为 25 的事务更新的,因此它的 row trx_id 也是 25。
你可能会问,前面的文章不是说,语句更新会生成 undo log(回滚日志)吗?那么,undo log 在哪呢?
实际上,图 2 中的三个虚线箭头,就是 undo log;而 V1、V2、V3 并不是物理上真实存在的,而是每次需要的时候根据当前版本和 undo log 计算出来的。比如,需要 V2 的时候,就是通过 V4 执行 U3、U2 算出来。
按照可重复读的定义,一个事务启动的时候,能够看到所有已经提交的事务结果。但是之后,这个事务执行期间,其他事务的更新对它不可见。
因此,InnoDB 代码实现上,一个事务只需要在启动的时候,找到所有已经提交的事务 ID 的最大值,记为 up_limit_id;然后声明说,“如果一个数据版本的 row trx_id 大于 up_limit_id,我就不认,我必须要找到它的上一个版本”。当然,如果一个事务自己更新的数据,它自己还是
要认的。
备注:up_limit_id 来源于源码里面的变量名,我没有想到更好的名字来称呼它。
你看,有了这个声明后,系统里面随后发生的更新,是不是就跟这个事务看到的内容无关了呢?因为之后的更新,产生的新的数据版本的 row trx_id 都会大于 up_limit_id,而对它来说,这些新的数据版本是不存在的,所以这个事务的快照,就是“静态”的了。
所以你现在知道了,InnoDB 利用了“所有数据都有多个版本”的这个特性,实现了“秒级创建快照”的能力。
这节内容太多,hxd们请看原文章。。。














 212
212











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









