






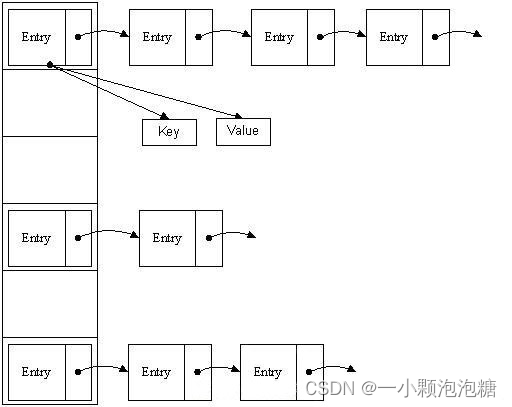
HashMap的底层原理
- 先计算出key对应的hashcode
- 通过hash(key)%len得到要插入的数组节点(哈希表的数组的初始长度为16),
- 插入:如果key的hashCode重复(即:数组的下标重复),则将新的key和旧的key放到链表中。如果key值一样,进行数据覆盖:(JDK7是头插法;JDK8是尾插法);
ps:若链表长度大于8 且容量小于64 会进行扩容;若链表长度大于8 且数组长度大于等于64,会转化为红黑树(提高定位元素的速度);若红黑树节点个数小于6,则将红黑树转为链表
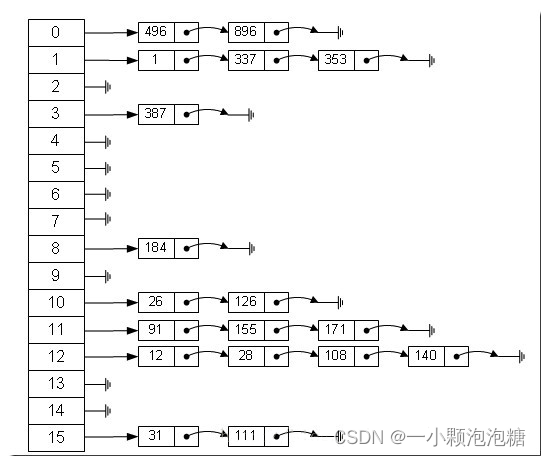
例如:
有几个key的hashcode分别为12、28、108、140,由于12%16=12;28%16=12;108%16=12;140%16=12,因此均插入到数组下标为12的链表中。
HashMap扩容的原理
HashMap是懒加载,构造完HashMap对象后,若没用 put 来插入元素,HashMap不会去初始化或者扩容table。扩容的场景如下:
- 首次调用put方法时,HashMap会发现table为空然后调用resize方法进行初始化。
- 非首次调用put方法时,若HashMap发现size(元素个数)大于threshold(阈值)(数组长度乘以加载因子的值),则会调用resize方法进行扩容。
- 链表长度大于8 且数组长度小于64 会进行扩容。链表长度大于8 (且数组长度大于等于64),会转化为红黑树。
数组是无法自动扩容的,所以只能是换一个更大的数组去装填以前的元素和将要添加的新元素。
resize()方法扩容的判断:
- 判断扩容前的旧数组容量是否已经达到最大(2^30)了
- 若达到则修改阈值为Integer的最大值(2^31 – 1),以后就不会扩容了。
- 若没达到,则修改数组大小为原来的2倍
- 以新数组大小创建新的数组(Node<K, V>[])
- 将数据转移到新的数组(Node[])里
不一定所有的节点都要换位置。比如:原数组大小为16,扩容后为32。若原来有hash值为1和17两个数据,他们对16取余都是1,在同一个桶里;扩容后,1对32取余仍然是1,而17对32取余却成了17,需要换个位置。(对应的代码为:if ((e.hash & oldCap) == 0) 若为true,则不需要换位置。
返回新的Node<K, V>[] 数组
HashMap保证线程安全的方法

线程不安全的原因:key值相同时会进行数据覆盖。
HashMap,TreeMap,LinkedHashMap的区别

详细可参考源码或者自学自学精灵















 3934
3934











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









