






 这段代码演示了如何结合SeleniumWebdriver和PIL库的Image模块,以及OCR工具Pytesseract,来抓取并识别网页上的验证码。通过Chrome浏览器打开目标网址,找到验证码元素,截图保存,然后利用Pytesseract将图片转换为文本,最后将识别出的验证码输入到指定的输入框中。
这段代码演示了如何结合SeleniumWebdriver和PIL库的Image模块,以及OCR工具Pytesseract,来抓取并识别网页上的验证码。通过Chrome浏览器打开目标网址,找到验证码元素,截图保存,然后利用Pytesseract将图片转换为文本,最后将识别出的验证码输入到指定的输入框中。
from selenium import webdriver
from PIL import Image
import pytesseract
browser = webdriver.Chrome()
browser.get('输入目标网址')#把输入目标网址替换一下
ele_codepic = browser.find_element('xpath','把对应的xpath写进去')#元素定位,也可以使用别的定位方法
with open('codepic.png',mode='wb') as f:
f.write(ele_codepic.screenshot_as_png)#保存图片
image = Image.open('codepic.png')
code = pytesseract.image_to_string(image)#读取图片
browser.find_element('xpath','把对应的xpath写进去').send_keys(code)#把验证码输进去,也可以使用别的定位方法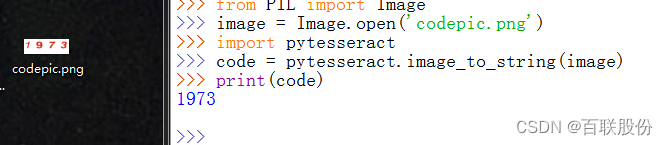
这个代码可以实现简单的识别

















 1610
1610

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









