








爬取“豆瓣电影” → 即将上映电影
网页概况
代码编写
import requests
from bs4 import BeautifulSoup
import pandas as pd
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36"
}
response = requests.get("https://movie.douban.com/coming",headers=headers)
soup = BeautifulSoup(response.text,'lxml')
# print(soup)
data = []
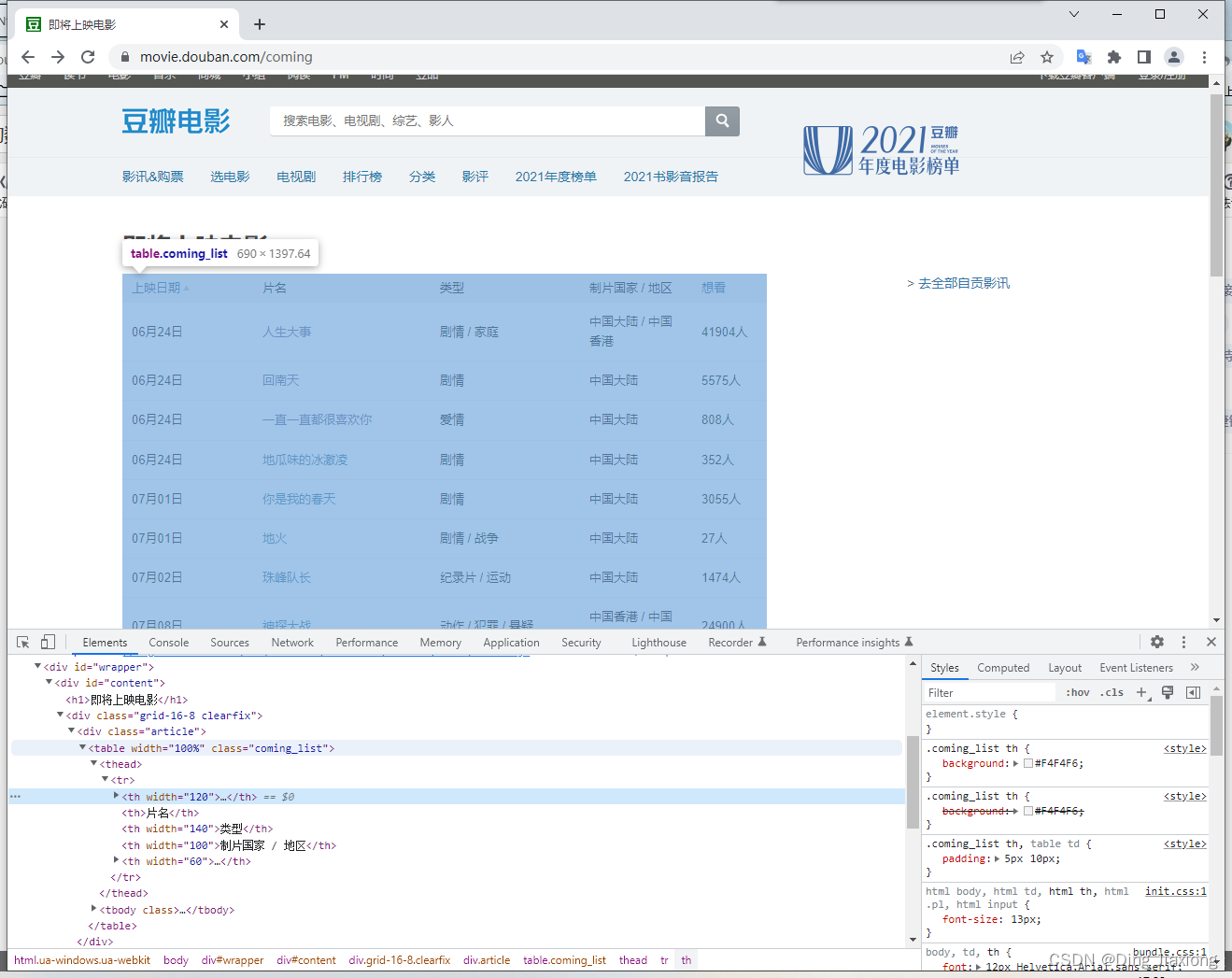
table = soup.find("table",{"class":"coming_list"})
# print(table)
table_body = table.find("tbody")
rows = table_body.find_all("tr")
# print(rows)
for row in rows:
id_value = row.find("a")["href"][-9:-1].replace("/","")
cols = row.find_all("td")
cols = [ele.text.strip() for ele in cols]
cols.append(id_value)
data.append(cols)
# print(data)
df = pd.DataFrame(data)
df.columns = ["上映日期","片名","类型","制片国家/地区","想看","ID"]
# print(df.head())
url_fore = "https://movie.douban.com/subject/"
# 电影详情
def movie(id_value):
response = requests.get(url_fore + id_value,headers=headers)
soup = BeautifulSoup(response.text,'lxml')
movie_infos = soup.find("div",{"id":"info"})
directors = movie_infos.find_all(rel = "v:directedBy")
dlst = [d.text for d in directors if d]
actors = movie_infos.find_all(rel = "v:starring")
alst = [actor.text for actor in actors if actor]
director_str = "|".join(dlst)
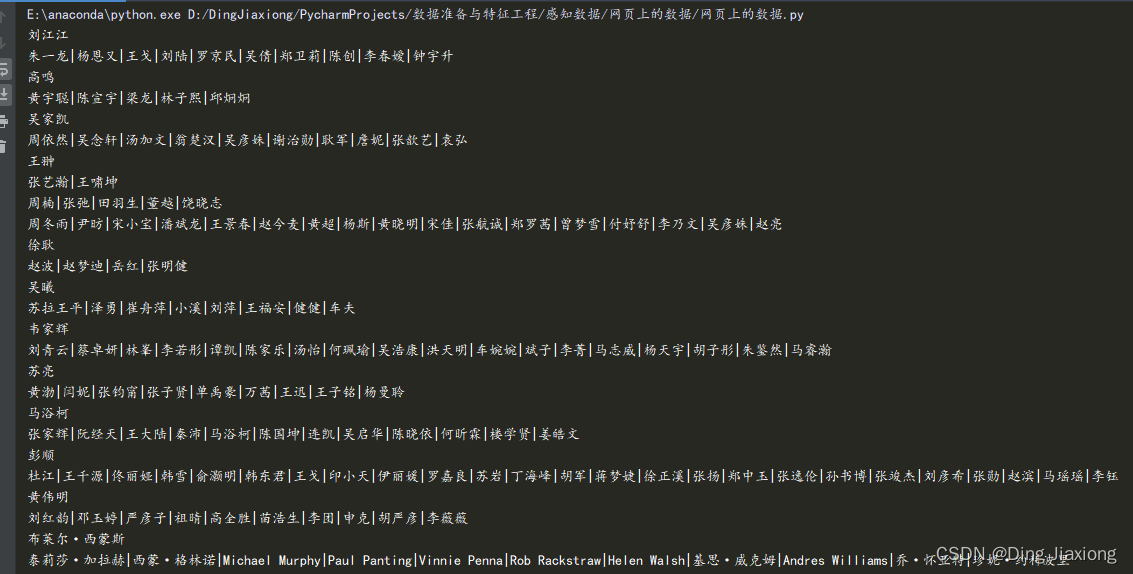
print(director_str)
actor_str = "|".join(alst)
print(actor_str)
return [director_str,actor_str,id_value]
movie_list = []
for i in df["ID"]:
infos = movie(i)
movie_list.append(infos)
# print(movie_list)
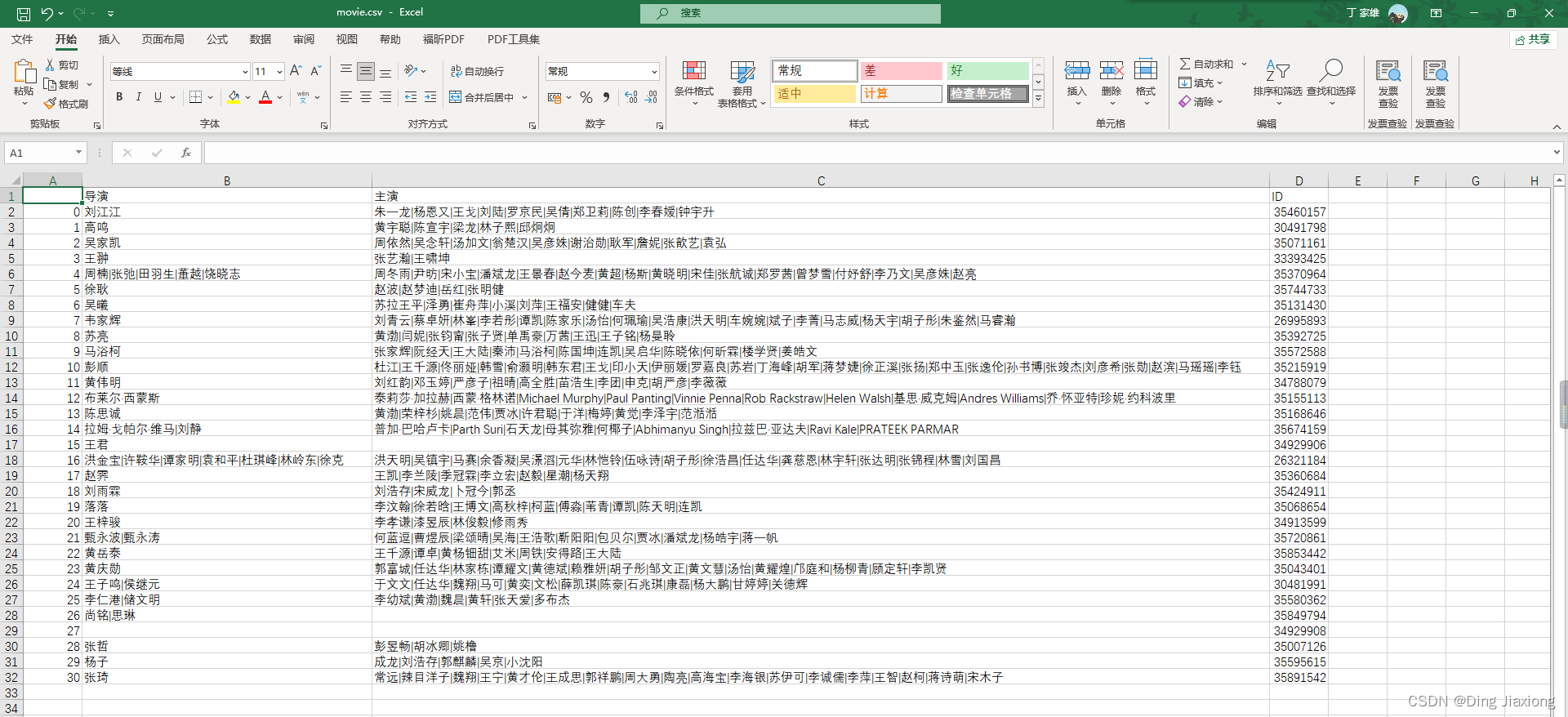
movie_df = pd.DataFrame(movie_list,columns=["导演","主演","ID"])
movie_df.to_csv("movie.csv",encoding="utf_8_sig")
运行结果



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











