










看过以及引用的网上学习资源
https://www.cnblogs.com/shineen/p/16421173.html
https://blog.csdn.net/xu_flash/article/details/62216969
https://blog.csdn.net/weixin_45193103/article/details/125103414
https://blog.csdn.net/weixin_62756510/article/details/125417136
https://blog.csdn.net/u012267926/article/details/125023806
查询页面刚进入时,查询语句需要执行10s左右,经过优化后,查询只需要毫秒。
操作:创建了索引resource_id,并修改了索引对应的列表为整数类型
ALTER TABLE `tablename` ADD INDEX `resource_id`(`resource_id`) USING BTREE;
alter table tablename modify column resource_id bigint(20);
不加索引时,查询resource_action_permission会进行全文的检索,即type为all,数据库会根据链表的形式,一条一条查下去,搜索效率慢。(下图通过explain查询索引是否命中得出的结果)

加索引后,采用explain查看索引是否命中,其中type为ref,数据库会根据该索引的值去查询对应的值,提升查询速度。

知识点扩展:
- 索引
相当于数组下标索引,根据索引在数据库中进行搜索,大大提高查询效率。
但创建索引也需要一定的时间和空间的开销,并且会拖慢增删改的效率。
数据的插入、删除会造成索引更新,索引的更新操作也需要消耗时间性能。
MySQL数据库插件式的设计,每种索引在不同的存储引擎中的实现可能不同。
存储引擎:MySQL对数据库中的数据进行增删改查等操作的实现方案。
MySQL经典的两种存储引擎:MyISAM、InnoDB。
MyISAM:MySQL5.5之前的默认存储引擎,不支持事务,但性能比较高。
InnoDB:MySQL5.5之后的默认存储引擎,支持事务,但性能不如MyISAM。
-
mysql索引
基于B+树实现。
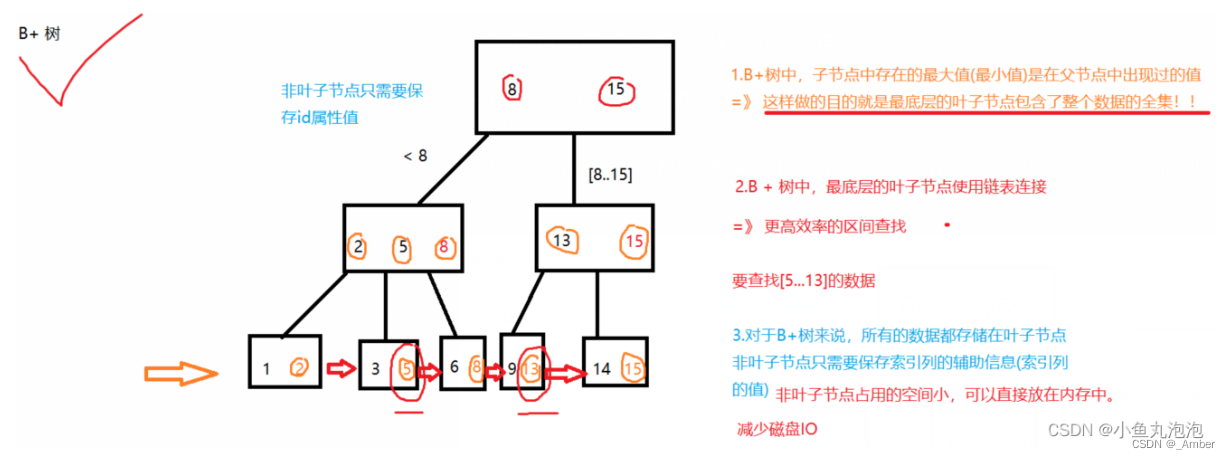
B+树底层是用二分法对树进行一层一层的查找,使用整形的方式,比string效率高,而且string索要的内存也会比int的要大;


-
explain分析sql语句执行计划,以及索引是否命中的结果解析:
type的解析:
删除线格式
type 解析
all 全表扫描
index 索引扫描,遍历索引树
ref 使用非唯一索引扫描,返回匹配某个单独值的所有行,本质上也是一种索引访问
range 索引范围扫描,常用<,>,<=,>=,between,in等范围查询
eq_ref 唯一性扫描,使用主键作为关联查询
const 通过索引一次找到,将匹配行中的其他列作为常数处理
system 从常量const结果中集中查询
删除线格式
possible_keys:所使用的索引名;
key:显示MySQL实际决定使用的键(索引)。如果没有选择索引,键是NULL。查询中如果使用覆盖索引,则该索引和查询的select字段重叠;
rows:根据表统计信息以及索引选用情况,大致估算出找到所需的记录所需要读取的行数;
详细字段介绍:
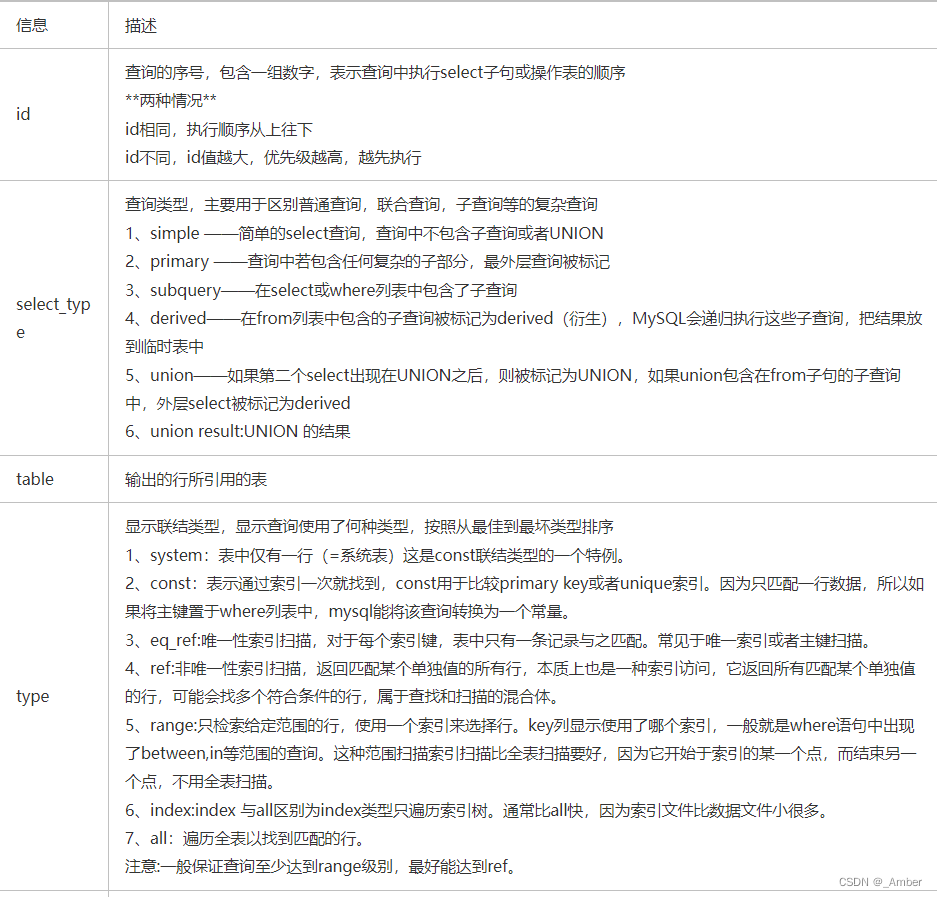

https://www.cnblogs.com/shineen/p/16421173.html















 708
708











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









