






1.前言
各位小伙伴们,大家好呀!欢迎关注天夏Ai,全网同名,我们致力于为大家挖掘和分享各种精品实用的人工智能(Ai)资源,包括但不限于**:Ai黑科技工具软件、Ai副业创业项目、Ai智能硬件设备!**
-
**Ai 黑科技工具软件:**这些软件拥有强大的功能和创新的算法,无论是提升工作效率,还是满足个人兴趣爱好,都能为你提供独特的解决方案,让你在使用过程中感受到科技的魅力与力量。
-
**Ai 副业创业项目:**如果你正在寻找新的发展机会,我们的Ai副业创业项目或许能为你打开一扇新的大门。这些项目结合了当下热门的人工智能技术与市场需求,为你提供可行的商业模式和操作指南,助力你在创业的道路上迈出坚实的一步。
-
**Ai 智能硬件设备:**这些智能硬件设备在Ai绘画、Ai问答、Ai音频和Ai视频等多个领域发挥着重要作用,为用户提供了强大的计算能力和高效的数据处理能力,极大地提升了创作和处理效率。
无论你是科技爱好者,还是想要在事业上寻求突破,天夏Ai 都将是你的不二之选。在这里,你将发现人工智能的无限可能,获取更多精品实用的Ai资源,开启一段精彩的科技之旅。
2.Ultimate Vocal Remover v5介绍
Ultimate Vocal Remover v5(简称UVR5)是一款功能强大的免费音频处理工具,主要用于高质量的伴奏制作和人声提取。以下是关于Ultimate Vocal Remover v5的详细介绍:
2.1.功能特点
-
人声与伴奏分离:UVR5能够自动识别并分离音频中的人声和伴奏,提供干净的伴奏轨道。
-
多种分离模式:支持多种分离模式,包括VR Architecture、MDX-Net、Demucs和Ensemble Mode等,每种模式都有其独特的优点和适用场景。
-
易于操作:界面友好,操作简便,适合各级别的用户,无需深厚的专业知识即可上手。
-
硬件加速:支持CUDA加速,可以利用Nvidia GPU提高处理速度。
-
模型下载中心:内置了模型下载中心,用户可以根据需要下载不同的模型进行处理。
-
多种音频格式支持:支持处理高品质的音频文件,输出格式包括wav、flac和mp3等。
2.2.应用场景
-
音乐创作:音乐制作人可以利用UVR5轻松提取伴奏,进行后期制作和混音。
-
K歌和翻唱:用户可以在原曲基础上去掉人声,制作伴奏版本进行K歌或翻唱。
-
音频修复:UVR5可用于修复老旧音频,将背景噪音或人声提取出来,提升音质。
-
AI歌手制作:提取人声制作AI歌手,如AI孙燕姿。
-
歌唱和伴奏练习:使用伴奏音轨进行歌唱或乐器练习。
-
音频后期制作:在电影、广告或视频制作中分离音乐的伴奏和人声。
-
音乐学习和分析:使用分离后的伴奏和人声进行学习和分析。
3.Ultimate Vocal Remover v5下载地址
Ultimate Vocal Remover v5已经放在网盘中,有需要的小伙伴可以免费自取!
链接:
https://pan.baidu.com/s/1zmAnh-1i2bLHB58OPyLrSQ?pwd=2n87
4.Ultimate Vocal Remover v5安装教程
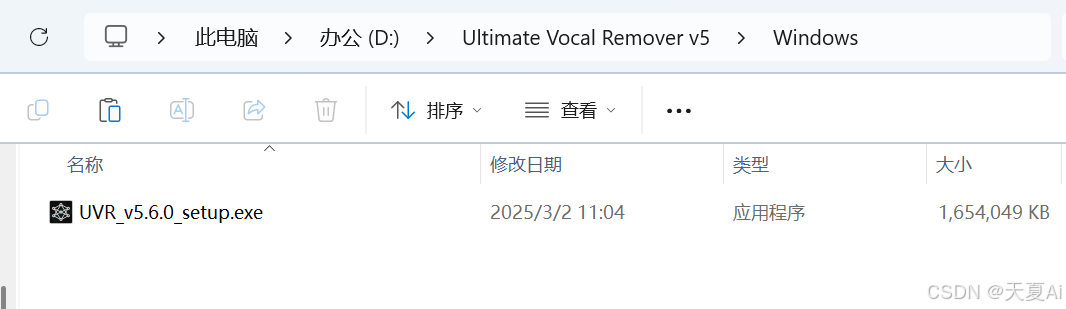
4.1.双击运行.exe
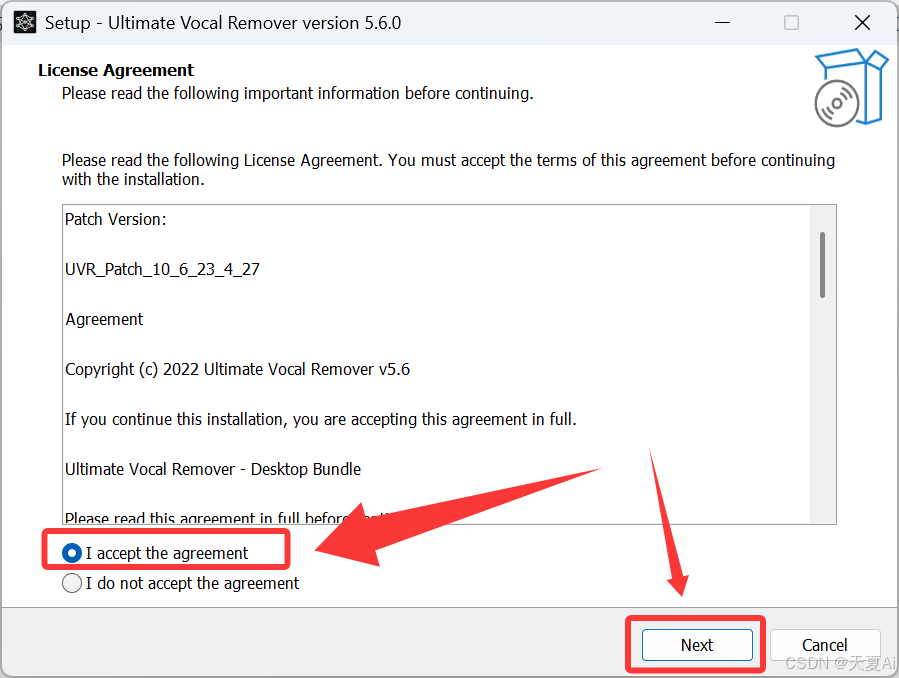
4.2.点击Next
4.3.选择安装位置,点击Next
4.4.勾选创建桌面快捷方式,点击Next
4.5.点击Install
4.6.点击Finish
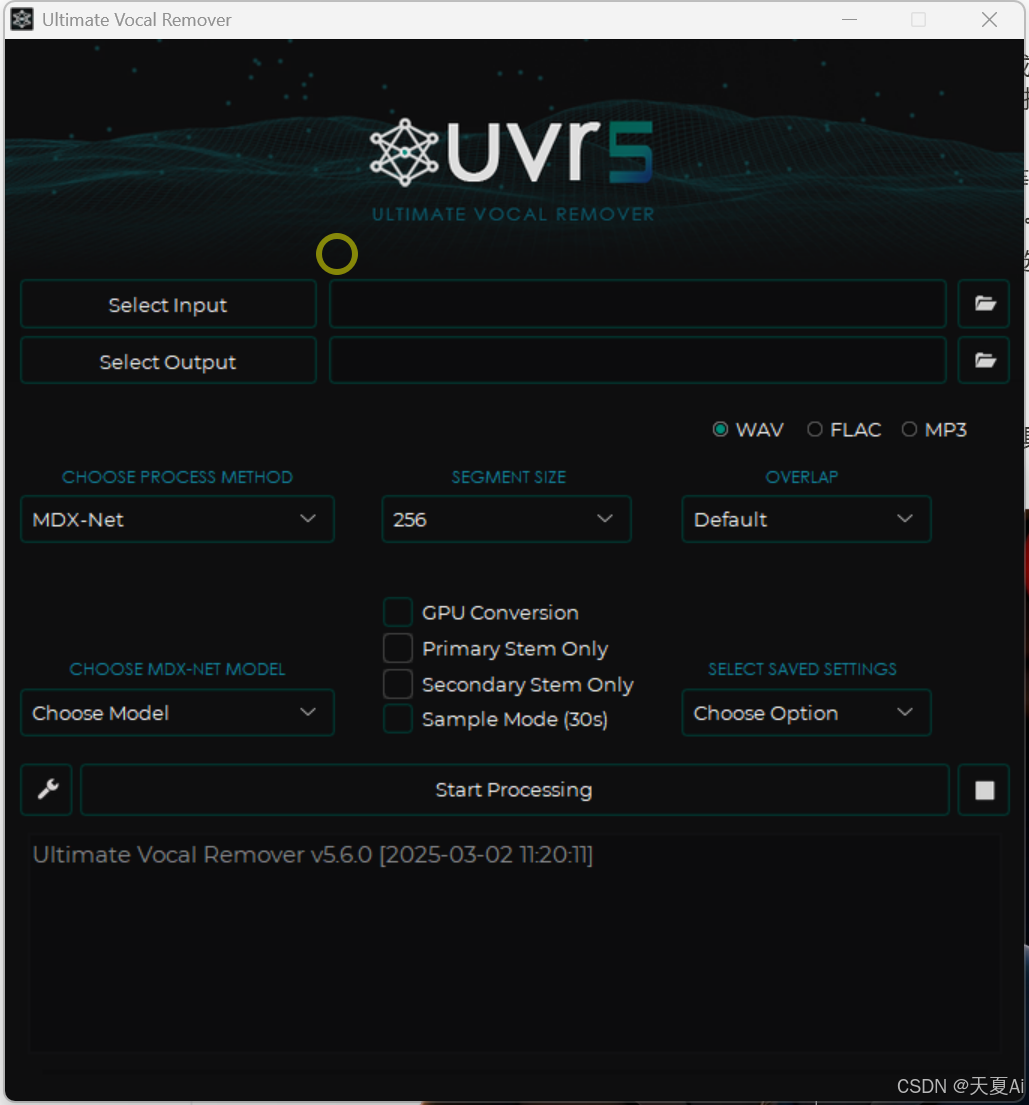
5.Ultimate Vocal Remover v5使用教程
5.1.软件界面中文解释
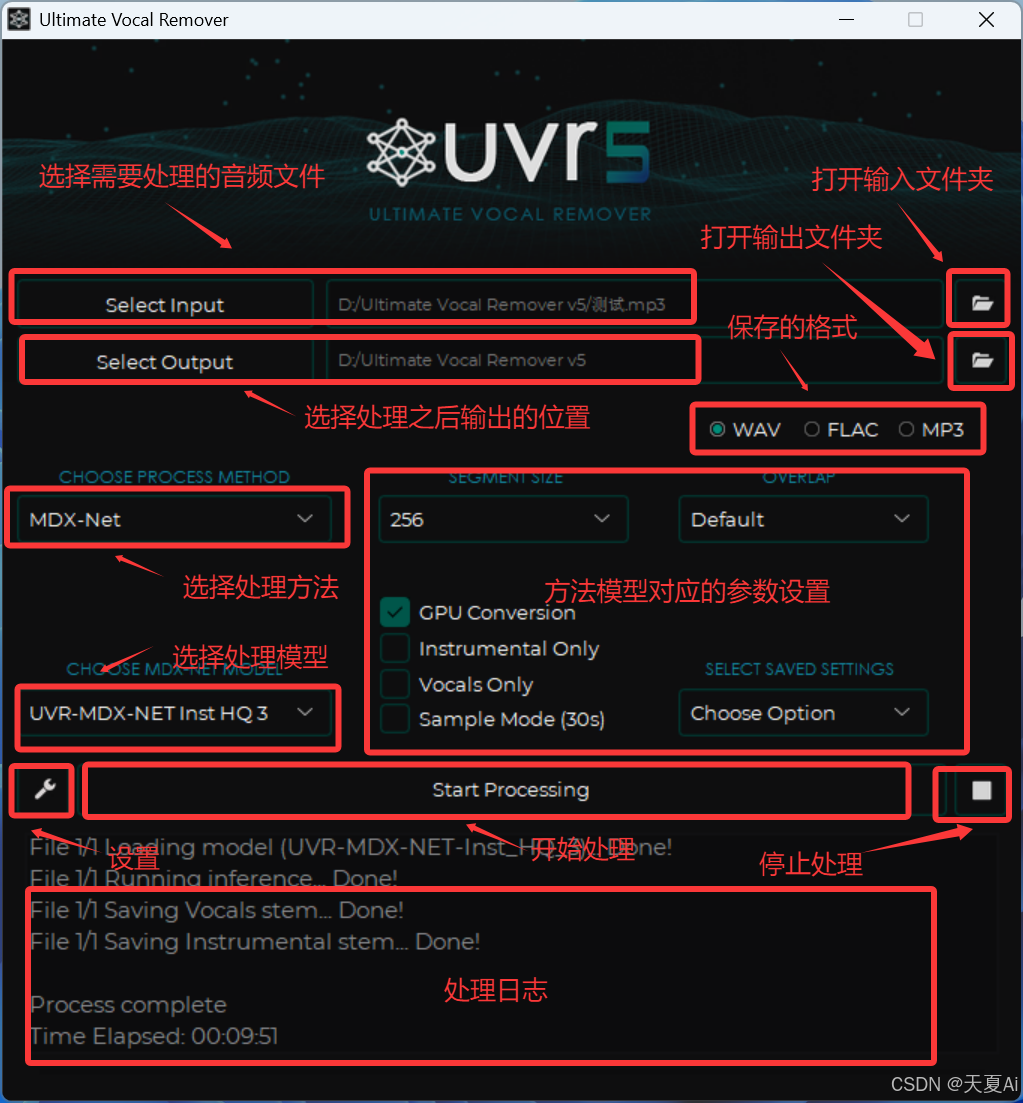
5.2.使用步骤
(1)选择需要处理的音频
(2)选择处理之后的输出位置
(3)处理方法和模型可以使用默认的,当然也有许多其他模型,后面会介绍
(4)点击开始处理即可
(5)处理完成后在输出文件夹中可以看到处理之后的文件
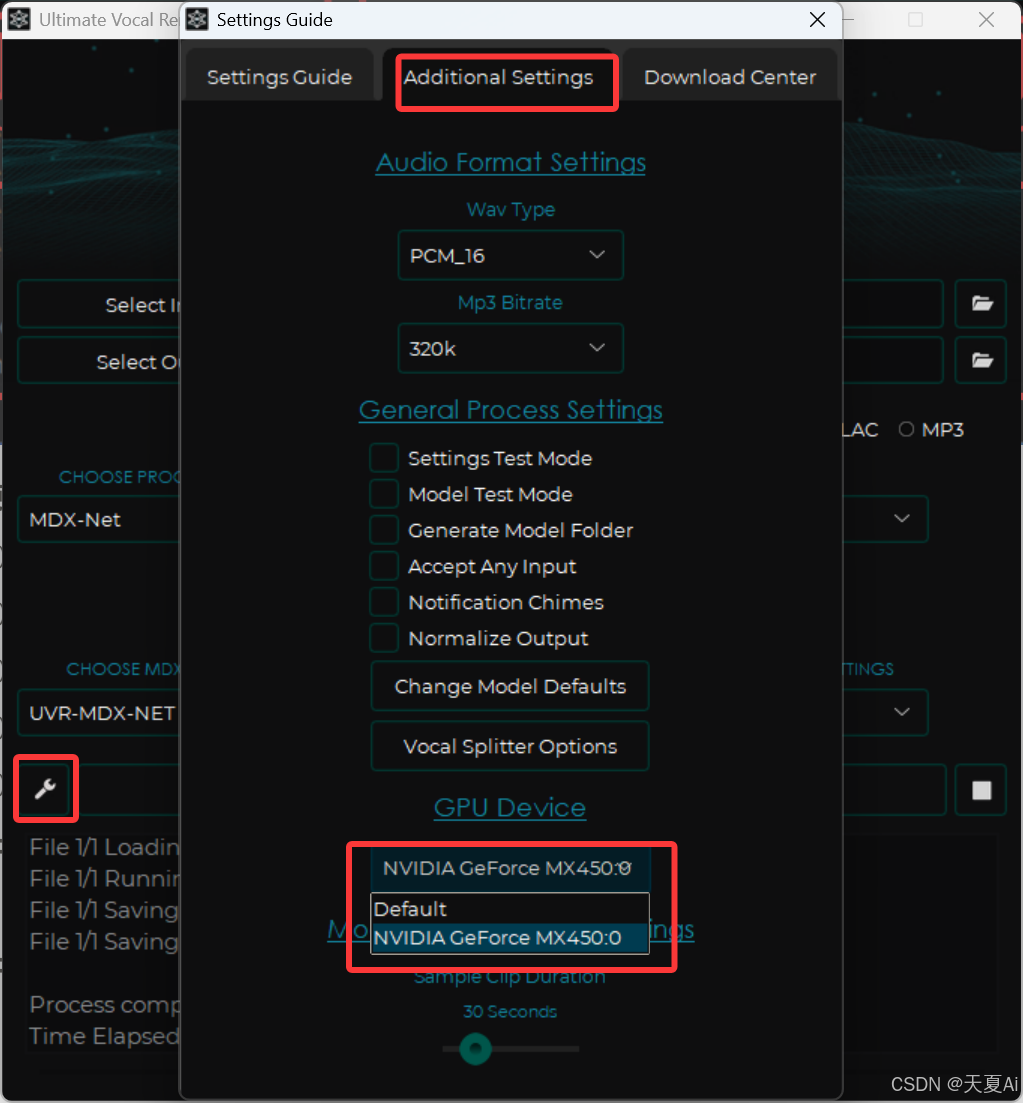
5.3.开启GPU
(1)在设置中选择GPU
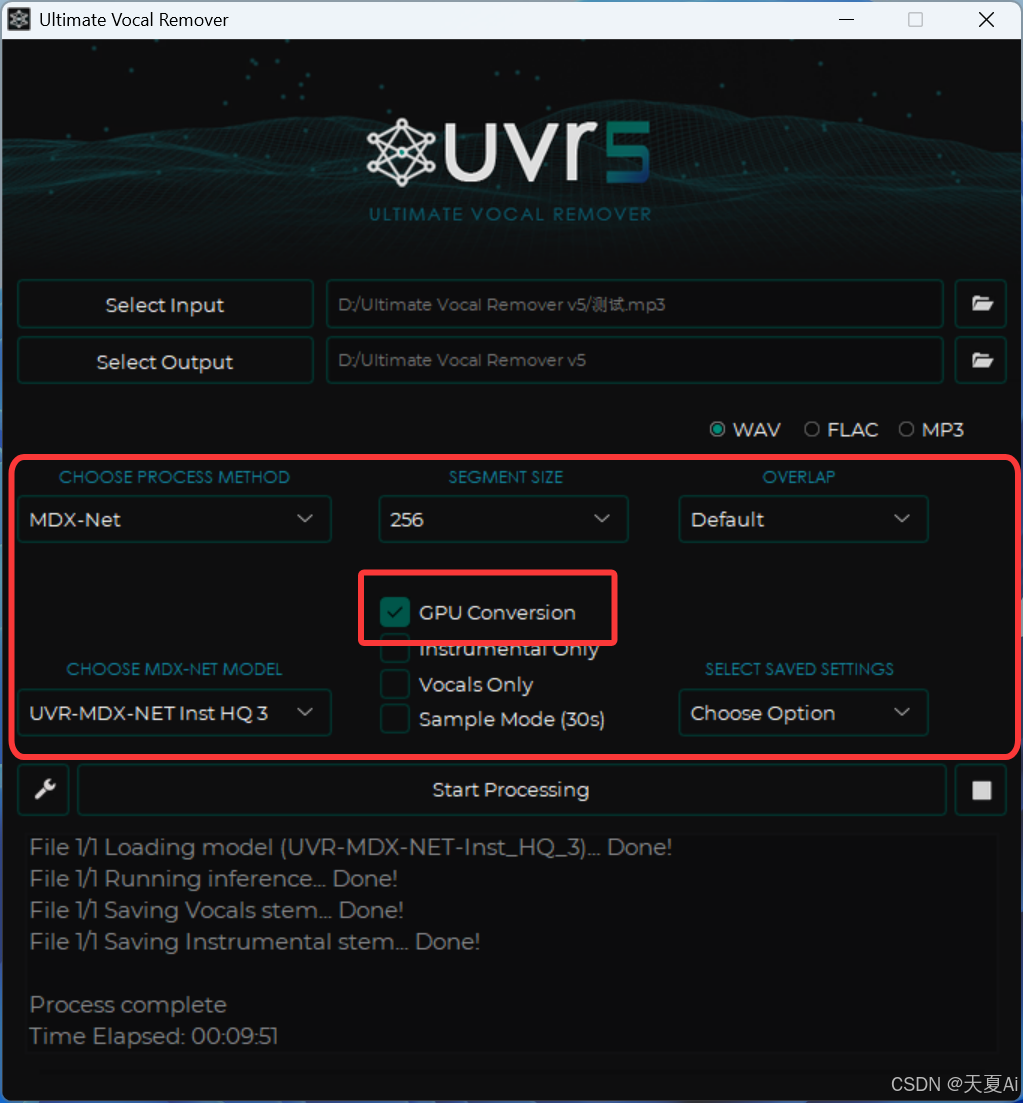
(2)模型参数设置中勾选GPU
5.4.其他模型
许多小伙伴可能会因为网络原因无法下载其他模型,在网盘中也为各位小伙伴准备好了模型,把下载的models文件夹替换掉安装包中的models
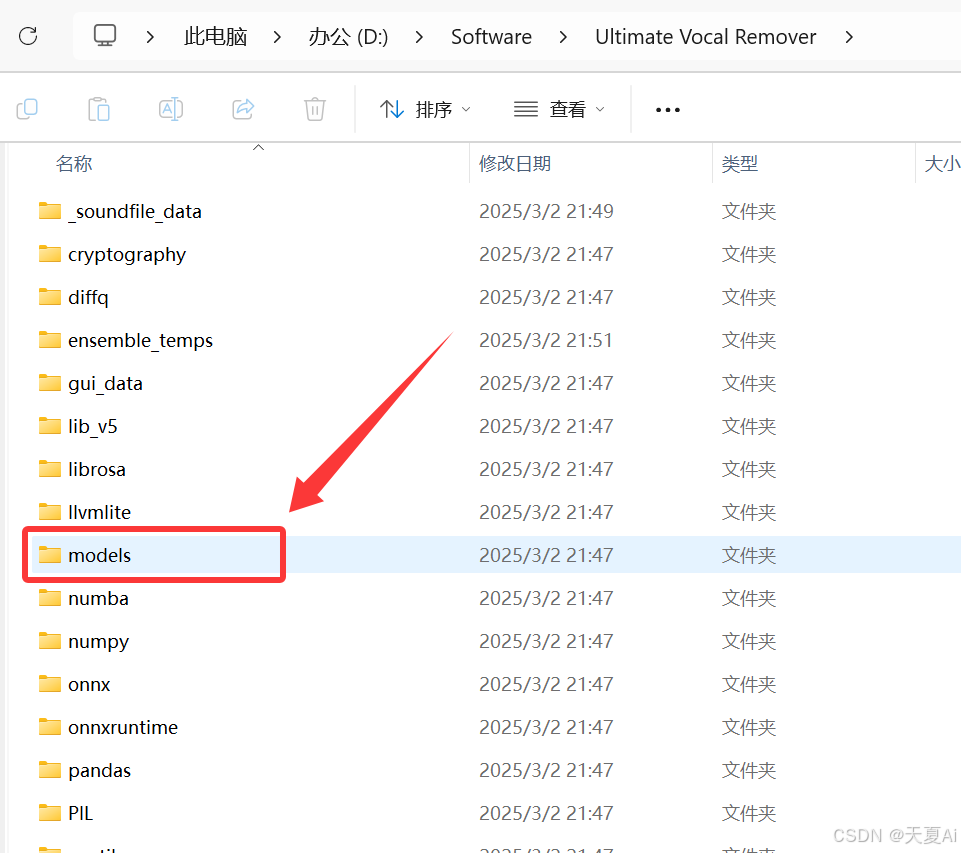
(1)主要有Demucs、MDX_NET、VR三种处理方法
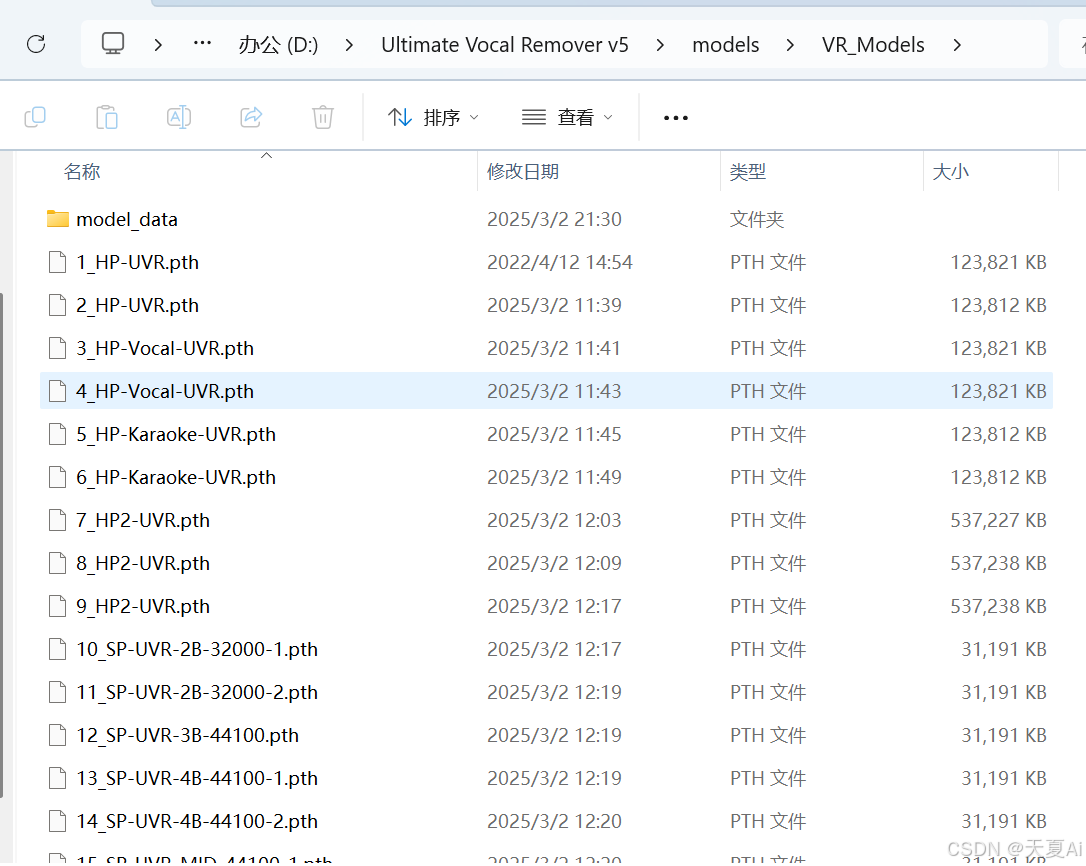
(2)每种处理方法下有对应的模型可以选择,每种模型对应着不同的功能,感兴趣的小伙伴可以去逐个测试,当然网上也有许多教程可以参考,具体效果还需要给位小伙伴亲自去测试,如果只是想要简单的人声音乐分离,默认的模型足够使用
6.结语
免责声明:
**版权:**我们作为资源的整理方,所有资源均来自互联网的优秀作者们,版权归原作者所有!如果侵犯到您的权益,请联系我本人,提供可充分证明权益的有效文件,我们会第一时间配合处理!
**说明:**资源由全网公开平台资源、圈子社群分享资源、和部分本人原创资源组成,仅供个人学习研究交流使用,除特别声明外,请勿用于商业用途,禁止用于非法用途,使用者需要自行承担法律责任,使用者需严格遵守国家法律法规。否则产生的一切后或由您自行承担,我们提供资源但是不对任何资源负法律责任,所有资源请在您下载后24小时删除!
**声明:**任何使用本人收集的资源产生的不测后果,本人不对此负任何责任!转载时请保留本信息,感谢!
附:
根据二00二年一月一日《计算机软件保护条例》第十七条规定:为了学习和研究软件内含的设计思想和原理,通过安装、显示、传输或者存储软件等方式使用软件的,可以不经软件著作权人许可,不向其支付报酬!
鉴于此,也希望大家按此说明学习和研究软件!谢谢!
寄语:愿我们在这充满机遇与挑战的Ai智能时代,勇敢探索,不断创新,收获无限可能与惊喜!!!

















 5412
5412

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









