






今天和大家分享一篇关于 Kafka 和 RabbitMQ 对比的论文,该论文是诺基亚贝尔实验室(Nokia Bell Labs)发表的工业界论文,系统阐述了二者的区别,可以帮助大家在发布订阅系统选型上提供帮助。文中很多引用,也是很好的扩展点,推荐大家阅读。
译文中会忽略某些不好翻译的上下文内容,并且翻译难免会有失原文精髓,还是推荐大家阅读原文
论文标题:
Industry Paper: Kafka versus RabbitMQ
A comparative study of two industry reference publish/subscribe implementations
Authors: Philippe Dobbelaere & Kyumars Sheykh Esmaili
https://www.researchgate.net/publication/317420540_Kafka_versus_RabbitMQ_A_comparative_study_of_two_industry_reference_publishsubscribe_implementations_Industry_Paper
注:该论文发表于2017年,有些概念可能和现有版本不一致。
摘要 (ABSTRACT)
发布订阅(pub/sub)模式是一种广泛采用的分布式交互范式,用以部署可扩展、低耦合系统。
Kafka 和 RabbitMQ 是应用最广的开源发布订阅系统。业务中二个常见的问题是二者的区别是什么、以及项目中应该用哪一个?
这篇paper中,我们将通过对比发布订阅系统的核心功能来建立起一个论证框架,用来全面论证二个系统的不同。以这个论证框架为基础,我们将定量定性的对比二个系统的常见功能。同时,我们还会阐述二个系统的不同点,并列举出二个系统常见的使用场景,读者可以根据自己的需求选择合适的系统。
1. 简介 (INTRODUCTION)
虽然 Apache Kafka [1] 和 RabbitMQ [4] 都是发布订阅系统,但是他们历史上的设计理念是不同的,并且拥有不同的功能。例如,二者的架构模型不同:
-
RabbitMQ 中,生产者生产消息到交换机(Exchanges), 交换机内部会进行消息的路由转发,随后消息进入队列(Queue), 消费者可以通过推(push)或者拉(pull)的方式获取到消息。
-
Kafka 中,生产者将消息发送到不同的topic,这些消息会存储在基于磁盘的顺序日志中(disk based append log)。消费者可以通过拉(pull)的方式获取到消息,并且支持多个消费者消费同一个消息。
大家可以在网上找到很多关于Kafka和RabbitMQ的对比文章,但是我们发现这些文章都没有客观全面的去对比二个系统,例如:1)对比过于强调二者的不同、 2)有些文章已经过时、3)很难去对比二者的实验结果。
在这篇paper中,我们将会全面论证二者的不同:首先我们会在第2节中简要介绍二者的核心功能,以及他们提供的服务质量保证(quality-of-service guarantees);基于第2节的内容,我们会在第3节提供高层次的描述;第4、5节我们会定性、定量比较二个系统的常见功能;除了常见功能外,我们会在第6节列举出各自的独有功能;第7节中,我们会列举出二个系统常用的一些使用场景,同时我们会提供一个对比表,方便大家根据自己的需求来做技术选型;最后我们会在第8节总结该论文。
2. 发布订阅系统背景知识(BACKGROUND: PUB/SUB SYSTEMS)
2.1 核心功能
生产者和消费者解耦是发布订阅系统的基础功能。Eugster et al. [14] 给发布订阅系统列举了三个不同的维度特征:
1)实体解耦 Entity decoupling or Space decoupling:生产者和消费者不需要知道对方的存在,而是通过发布订阅系统作为媒介
2)时间解耦 Time decoupling: 生产者和消费者不需要在同一时间活跃,例如生产者生产完消息后可以停止活动,消费者仍然可以获取消息
3)同步解耦 Synchronization decoupling :生产者消费者不会同步阻碍各自的执行
发布订阅系统的另一个核心功能是路由逻辑 routing logic(或者说是订阅模式 subscription model),该功能决定了生产者的消息会被路由到哪一个消费者。二个常见的路由逻辑是:
-
基于topic的订阅模型(topic-based):生产者会给每个消息打一个或者多个topic标签,通过过滤逻辑来决定消息应该被哪个消费者消费。很多系统支持topic包含通配符(wildcards)
-
基于内容的订阅模型(content-based):生产者不需要打标签,所有的数据和元信息被用于过滤逻辑,消费者自己实现过滤逻辑来获得想要的消息。这种方式如果过滤逻辑复杂的话,会带来一定的性能问题
2.2服务质量保证(quality-of-service guarantees)
除了之前提到的核心功能外,还有一些其他的保证,统一称为服务质量保证(Quality-of-Service (QoS) guarantees )[9, 11, 14]。
为了简洁性,我们把QoS保证分成了5个不同的类别,分别在下面一一展开。这节内容有一个需要注意的前提:“现代的发布订阅系统都是分布式的”。分布式是一个系统可扩展性(scalability )的必要但非充分条件。分布式的特性同时会带来一系列的技术问题,使得分布式存储、索引、计算特别的脆弱[7]。
2.2.1 正确性 Correctness:
引用[28]中把正确性定义成3个主要方面:无丢失,无重复,无顺序混乱(no-loss, no-duplication, no-disorder )。为了保证这3点,发布订阅系统有以下2个保证:
-
消息投递保证(Delivery Guarantees), 分为三种:
-
at most once:最多一次(最大努力best effort),保证了无重复(no-duplication), 但是有可能造成消息丢失,优点是性能最好
-
at least once:至少一次,保证了无丢失(no-loss), 系统会保证消息不丢失,但是有可能造成消息重复以及顺序混乱(例如系统宕机后恢复的场景)
-
exactly once:精确一次,保证了无丢失(no-loss)以及 无重复(no-duplication),exactly once需要比较消耗性能的实现例如二(two-phase commit)
-
-
消息顺序保证(Ordering Guarantees), 分为三种:
-
no oredering:没有顺序保证
-
partitioned ordering:单个分区内可以顺序消费
-
global ordering:全局顺序保证,需要额外的资源来实现,性能最差
-
2.2.2 可用性 Availability:
可用性是指系统整体保证可用不宕机的能力。这里会假设系统已经是可靠系统(reliable):失败可以被检测到,并且可以触发修复动作。
2.2.3 事务 Transactions:
在消息系统(messaging system)中,事务是用来将多个消息汇聚成一个原子单元(atomic units): 单元内的消息必须满足原子性,即全部失败或者全部发送/接收成功。例如,生产者生产了一系列具有上下文语义相关性的消息,生产者不想让消费者看到其中一部分的数据,因为从语义上部分数据是不一致的。
2.2.4 可扩展性 Scalability
可扩展性是指系统可以持续进化,从而支持任务量增加的场景。在发布订阅系统里,可扩展性有多个维度去衡量,例如 消费者/生产者、topics、消息。
2.2.5 效率 Efficiency
效率通常可以用二个指标来衡量:
-
延迟时间(latency or response time): 在传输架构中(transport architecture)消息的延迟时间是消息所要经过的中间流程决定的
-
吞吐量(throughput or bandwidth): 吞吐量是根据单位时间在生产者和消费者之间可以传输的数据包(packets or bytes) 大小来衡量的。与延迟时间对比,吞吐量可以通过增加额外资源来横向扩展。
对于单一流程,延迟时间latency和吞吐量throughput是成反比的.
需要重点说明的是,效率(Efficiency)和可扩展性(Scalability)通常和其他质量保证是冲突的[14]。例如,复杂的订阅模式(highly expressive and selective subscriptions)需要复杂以及性能消耗大的过滤和路由逻辑,因此限制了系统的扩展性(Scalability)。同样,强的可用性(Availability)和消息投递保证(Delivery Guarantees) 需要很大的额外开销,因为消息的确认和复制(Replication)成本会随着增加,而且丢失的消息必须有机制去检测到并且重新发送。
2.3 实现(Realizations)
很多的框架或者库都可以被归类为具有发布订阅消息功能。一种归类的方法是将其放到一个轻量级功能少的系统里,然后再将其放入复杂功能多的系统里来评估。
轻量级系统里,我们有ZeroMQ, Finagle, Kafka等。重量级的有 Java Message Service(JMS)的实现例如ActiveMQ, JBOSS Message, Glassfish等。AMQP 0.9是一个流行的标准化的发布订阅协议,它有很多实现,例如RabbitMQ, Qpid, HornetQ等。更加复杂以及功能丰富的场景是包含了发布订阅的分布式RPC框架,例如 Mule ESB, Apache ServiceMix, JBossESB等。
3 高层次描述(HIGH-LEVEL DESCRIPTION )
这节中,我们会简要的描述Kafka和 RabbitMQ系统。包括其创建的历史原因,它们的设计理念,以及它们的一些实现和优化细节。这些方面会帮助我们进一步了解它们,从而更好的去诠释它们的不同。
3.1 Apache Kafka
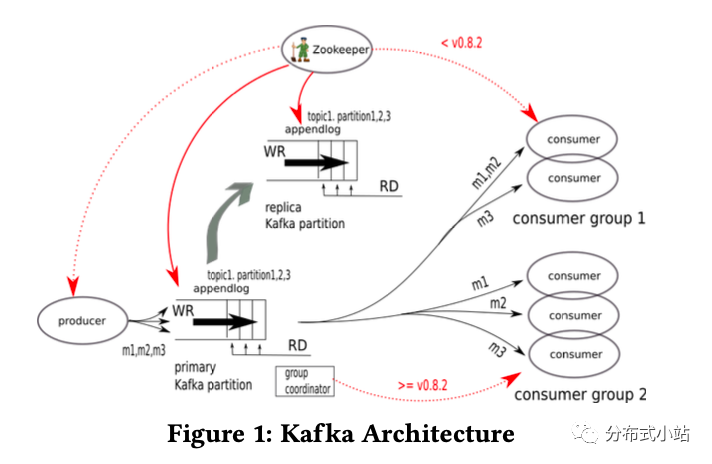
Kafka最初是LinkedIn公司创建的,作为其集中式的事件传输平台(centralized event pipelining platform),这个平台是用来替换一个点对点(point-to-point)的集成系统[17]。
Kafka 设计用于高吞吐量场景(百万级别的消息)[17]。这样的系统里需要注意的点是,在多个消费者消费同一消息流时候会有不同的消费速度(例如批处理和流处理streaming vs batch)。
Kafka最终被设计成一个围绕分布式commit log[32]的可扩展的发布订阅消息系统。其高的吞吐量是相比于其他日志聚合系统(log aggregation systems)的一个优势[17]。数据被写入到log files, 随后才会被写入磁盘,这样的设计带来了非常高效的 I/O模型【译注:kafka的这2个设置是用来定义写入磁盘时机的 log.flush.interval.messages、log.flush.interval.ms, 同时通过replication来保证数据的可靠性】。
图片1是Kafka的架构图。生产者发送消息给Kafka的topic,topic被分散在不同的kafka集群brokers中, 每个broker有可能持有该topic的分片(也有可能没有,比如broker的数量大于partition的数量)。每个partition都是有序的WAL Log(write-ahead log)用来记录消息并且持久化到磁盘上。所有的topic都可以被任意数量的消费者读取到,随着消费者的增加,性能消耗增长很小。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 696
696











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









