






译者前言
在阅读NVDLA架构和源码的过程中,顺便翻译以加深理解,谨供参考,英文原文:http://nvdla.org/primer.html。
摘要
深度学习推理的大部分计算工作量主要是基于几类数学操作,可归为以下四类:卷积(convolutions),激活(activations),池化(pooling)和归一化(normalization)。这些操作具有共同的少量特征,使得它们可以非常好的适用于专用硬件来实现:它们的存储控制模式的可预测性非常高且易于并行化。NVDLA工程推动一种标准化且开放的架构来实现推理计算的需求。NVDLA架构是可扩展的,而且具有很好的可配置性;模块化的设计保持了灵活性和简化集成。标准化的深度学习加速器推动了大部分现代深度学习网络的可操作性,促进深度神经网络的大规模统一增长。
NVDLA硬件提供了一种简单,灵活,鲁棒的推理加速器解决方案。它支持很大范围的性能水平和可伸缩的应用,从比较小的,成本敏感的loT设备,到面向较高性能的loT设备。NVDLA事实上提供了一个基于开放工业标准的IP-core组成的集合:the Verilog model是一个RTL形式的综合和仿真的模型,the TLM SystemC simulation model可用于软件开发,系统集成和测试,NVDLA软件生态系统包括一个on-device software stack(片上软件栈,开源发布的一部分),一个完整的training infrastructure(训练基础设施)来构建深度学习的新模型,parsers(解释器)把已存在的模型转换成on-device software可用的格式。
开源NVDLA工程以开放,定向的社区形式管理,NVDLA保持对想要提交修改的外部用户和开发者的开放,贡献者需要同意Contributor License Agreement,以确保任何来源于某个贡献者的IP权利,可以授权给所有的NVDLA用户;不想回馈NVDLA的用户不承担这种义务。在初版发布后,开发过程将开放式的进行。NVDLA软件,硬件和文档,将在GitHub上可见。
NVDLA硬件和软件将在NVIDIA Open NVDLA License的许可下可获得,这是一个包含FRAND-RF专利授权的许可证。另外,对于构建了NVDLA-compatible(兼容NVDLA)实现可以和更大NVDLA生态进行交互的用户,英伟达将授权其使用NVDLA的名字或其他英伟达相关商标。(这个license描述只是透露相关信息,不是标准授权,如果有与NVDLA license冲突的地方,以NVDLA license为准)。
使用NVDLA加速Deep learning推理
NVDLA介绍一种模块化的架构设计来简化配置,集成和轻量化。它采用了几块积木来加速主要的神经网络推理操作。NVDLA硬件由以下几个部件组成:
Convolution Core:卷积核,优化的高性能卷积引擎
Single Data Processor:SDP,用于激活函数(activation)的单点查找引擎
Planar Data Processor:PDP,用于池化(pooling)的平面均值引擎
Channel Data Processor:CDP,用于高级归一化函数(normalization)的多通道均值引擎
Dedicated Memory and Data Reshape Engines:RUBIK,专用存储器和数据重整引擎,用于tensor reshape和拷贝操作的存储转换加速器。
每一块积木都是互相分离且可以独立配置的。比如说,一个不需要pooling的系统,完全可以通过配置去除planar averaging engine;一个需要更高卷积性能的系统,可以通过配置提高卷积单元的性能,而不需要修改加速器的其他单元。对各个单元进行调度操作(scheduling operations)被分配给一个协处理器或CPU来进行;他们在非常细粒度的调度边界上进行操作,每个单元操作都是独立的。这些对严密管理调度的要求,可以作为NVDLA子系统的一部分,外加一个专用管理协处理器来完成(这就是“headed”实现)。或者,这些功能也可以融合在较高级别的驱动程序实现中,由主系统处理器来完成(这就是“headless”实现)。这使得相同的NVDLA硬件架构提供多种实现大小。
NVDLA硬件与系统其他部分的接口应用的标准实践:一个控制通道(control channel)实现一个寄存器文件和中断接口,一对标准AXI总线接口用来连接存储。主存储器接口(the primary memory interface)用来连接系统的宽存储系统(wider memory system),包括系统动态存储器(system DRAM),这个存储器接口应该与系统的CPU和I/O外设进行共享。副存储器接口(the second memory interface)是可选的,允许连接更高带宽的存储器(通常可能专用于NVDLA或一个计算机视觉子系统)。这种对于异构存储器接口的可选择性,提供了在不同类型的主机系统之间进行扩展的额外灵活性。
典型的推理流程从NVDLA管理处理器(可以是headed实现中的微控制器,也可以是headless实现中的主CPU)发起,发送一个硬件层配置和对应的activate命令。如果数据依赖性方面允许,多个硬件层配置可以被发送到不同的引擎并同时被激活(比如说,存在另外一个层,它的输入不依赖于前面一个层的输出的情况)。因为每一个引擎为它的配置寄存器组(configuration registers)准备了双缓存机制(double-buffer),在激活层处理完成的一刹那,它还可以拿到第二个层的配置并立刻开始处理。一旦硬件引擎完成了它激活的任务,它会触发一个中断给管理处理器来通知这个完成事件,管理处理器将再次启动一个处理流程。这种“命令-执行-中断”流程(command-execute-interrupt flow)持续重复,直到整个网络的推理任务完成。
NVDLA的实现方式,通常有两种类别:
Headless方式:对NVDLA硬件进行逐个单元的管理(unit-by-unit management),用主系统处理器CPU来完成。
Headed方式:专门用一个协助的微处理器来完成那些高频中断任务(high-interrupt-frequency task),紧密的耦合到NVDLA子系统中。
提示:最初版本的NVDLA开源代码只提供headless模式的软件方案,后续将提供headed模式的驱动程序。
Fig1中的小系统模型(the small system model),展示了一个headless方式NVDLA实现,大系统模型(the large system model)展示的是headed方式的NVDLA实现。小系统模型代表的是对成本更加敏感的构建设备的NVDLA实现,大系统模式的特点是,增加了专用控制协处理器(dedicated control coprocessor)和高带宽的静态存储器(high-bandwidth SRAM)来支持NVDLA子系统。大系统模型适合于面向那些会同时执行很多任务的高性能loT设备。
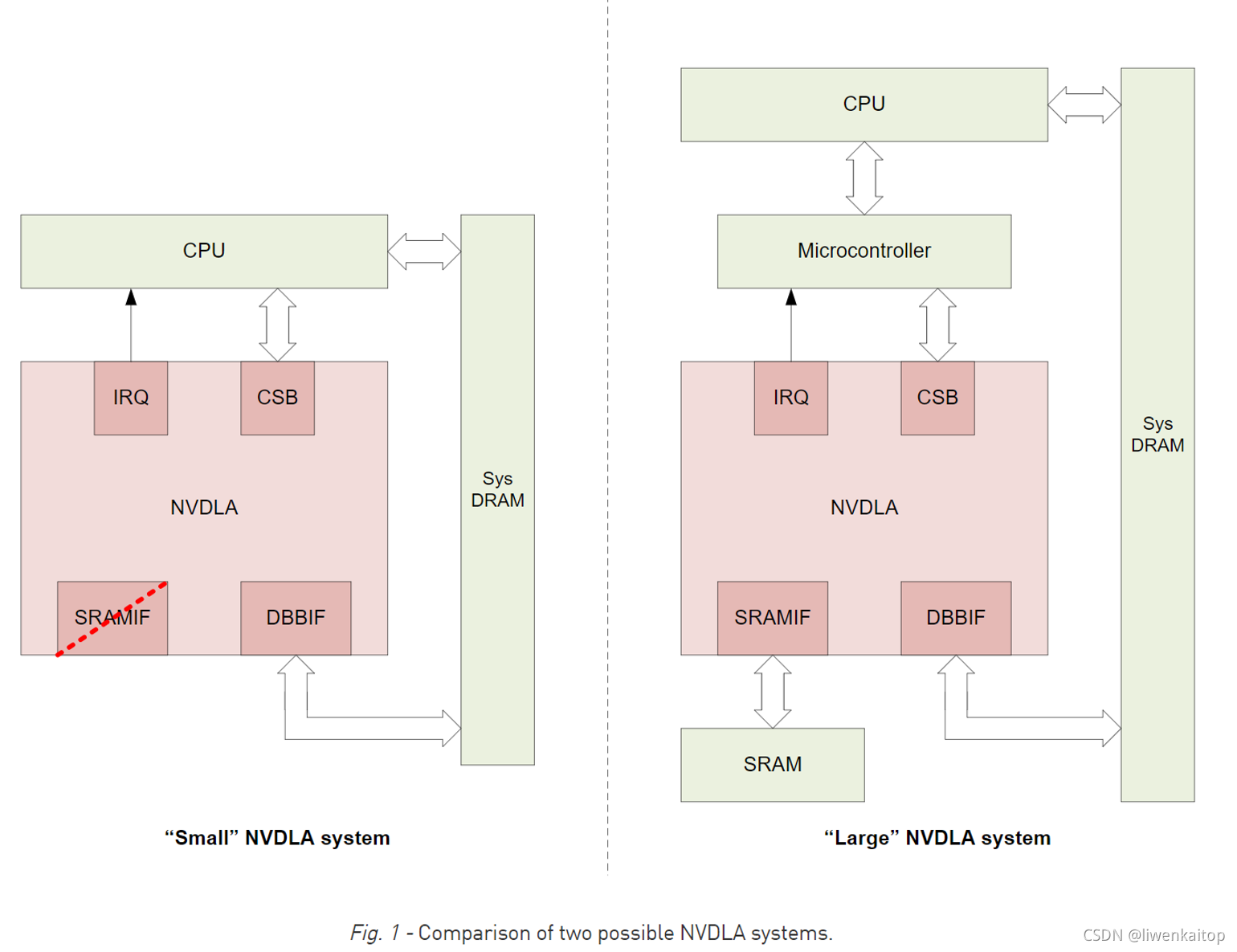
Small NVDLA system/Model
小系统模式,将深度学习技术拓展到了那些之前不可行的领域。这种模式很适合于那些成本敏感的loT接入类设备,面向AI和自动话的系统,他们有着清晰的定位,比如成本,面积,功耗这些指标是主要的驱动因素。通过NVDLA可配置的资源在成本,面积和功耗这些方面完成节约(savings)的诉求。神经网络模型可以预编译,并进行性能优化,允许大一些的模型被剪枝,降低加载的复杂度。反过来,这种裁剪的NVDLA实现,要求一个耗费更小存储的模型和耗费更少计算时间的系统软件来进行加载和处理。
这种定制构建的系统(purpose-built systems),通常在同一时间只执行一个任务,并且这种在NVDLA执行中牺牲系统性能的方面,通常并不是关注的重点。这些系统能够进行相对廉价的内容切换(有时,作为一个处理器架构选择的结果,有时,作为一个使用FreeRTOS系统做任务管理的结果),导致了主处理器并没有在维护大量NVDLA中断时负载过重。这取消了增加一个微控制器的需要,而由主处理器既承担粗粒度的调度和内存分配,又承担细粒度的NVDLA管理。
典型地,遵循小系统模型的系统,不会包含可选的副存储器接口(the optional second memory interface)。当总体系统性能不那么重要的时候,不使用高速存储方式的影响似乎也没那么严重。在这种系统里,系统存储通常用DRAM很可能比SRAM的功耗更小,这使它可以用更好的性能-功耗比(power-efficient)的系统存储作为计算缓存。
Large NVDLA system/Model
当关注的重点是高性能和通用性时,大系统模式是更好的选择。面向性能的loT系统,可能在很多不同网络拓扑上执行推理,因此,这些系统保持一个高度的灵活性就非常重要。另外,这些系统可能在同一时间执行很多任务,而非串行的推理操作,所以推理操作不能在host侧消耗过大的计算功耗。为了满足这些需求,NVDLA硬件要包含一个可选的副存储器接口用于专用的高带宽静态存储器SRAM,并且要通过一个专用于控制的协处理器(微处理器)来处理中断,而不是把中断送给主处理器CPU处理。
在这种实现中,一个高带宽SRAM连接到NVDLA上的一个快速存储总线交互端口(fast-memory bus interface port)上。这个SRAM被NVDLA用作缓存(cache),可选择的是,它也可以被系统上其他高性能的计算机视觉相关的组件共享,来进一步减少与主系统存储器(system SRAM)之间的数据流量(reduce traffic)。
NVDLA协处理器的要求是有代表性的,有很多通用处理器(general purpose processors)都是适合的(比如,基于RISC-V的PicoRV32处理器,ARM架构的Cortex-M或Cortex-R处理器,甚至自行设计的微处理器)。当使用专用的协处理器时,主处理器(the host processor)仍然会承担一些和管理NVDLA相关的任务。比如,尽管协处理器负责NVDLA硬件的调度和细粒度编程,host仍然要负责NVDLA的粗粒度调度,NVDLA存储控制的IOMMU映射(必要时),NVDLA上输入数据和固定权重数组的内存分配,以及,在NVDLA上运行的其他系统组件和任务的同步。
硬件架构
NVDLA架构可以被编程为两种操作模式:
Independent(独立模式):当独立操作时,每个功能块(functional block)都要明确配置什么时候执行什么操作(when and what is executes),每个功能块执行它被分配的任务(类似于深度学习框架中的独立的层)。独立操作的开始和结束,以被分配任务的功能块执行存储器间操作(memory-to-memory operations)为标志,也就是,输入或输出主系统存储器或专用SRAM存储器。
Fused(融合模式):融合操作类似于独立操作,然而一些功能块可以被组织成流水线(pipeline)。这样做可以改善性能,绕过进出存储器的往返路径,代之以小的FIFOs进行功能块之间的通信。(比如说,卷积核(Convolution core)可以直接把数据传给SDP处理器,SDP再把数据传给PDP处理器,介入再传给CDP处理器)。
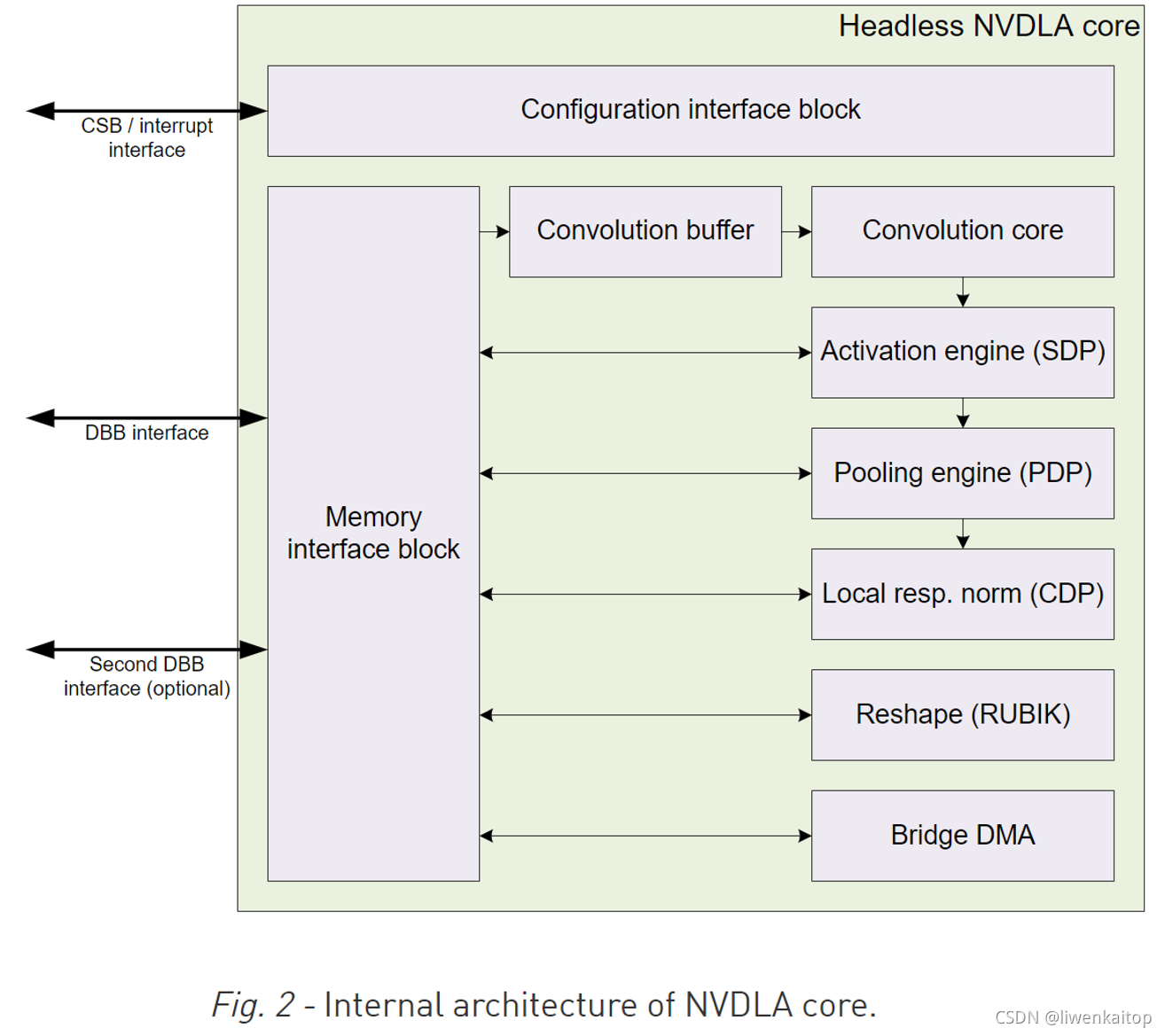
连接方式
NVDLA实现了与系统其他部分之间的三种主要的连接方式:
Configuration Space Bus interface(CSB配置空间总线接口):这个接口是同步的,低带宽,低功耗,32位控制总线,用于CPU控制NVDLA配置寄存器。NVDLA在CSB接口中以被控制方式(slave)发挥作用。CSB实现了一个非常简单的接口协议,所以它可以很容易替换为AMBA,OCP或任何其他系统总线。
Interrupt interface(中断接口):NVDLA硬件包含一个1位级别驱动的中断(1-bit level-driven interrupt),当一个任务完成或有错误发生的时候,这个中断线就会被触发。
Data Backbone interface(DBB数据骨干接口):DBB接口连接了NVDLA和主系统的存储子系统,它是一个同步的,高速率,具有高度可配置性的数据总线。它可以被指定为不同的地址大小,不同的数据大小,并发送依赖于系统要求的不同大小的请求。DBB接口是一个类似于AXI的简单的接口协议,可以方便的用在具有AXI一致性的系统上(AXI-compliant systems)。
组件
NVDLA架构中的每个组件的存在,都是为了支持深度神经网络推理过程中必须用到的某些操作。下面的描述为每个模块,提供了一个简要的功能性概述,包括和他们对应的TensorFlow操作。不过TensorFlow操作只是作为例子提供,NVDLA硬件支持其他的深度学习框架。
Convolution卷积
卷积操作工作在两种数据集合上:一个是离线训练的权重(weight:在推理的每次运行中保持常量),一个是输入的特征数据(feature:随着网络输入而不断变化)。卷积引擎提供了参数来高效的把许多不同大小的卷积映射到硬件上。NVDLA卷积引擎在原始的卷积实现上进行了优化来提高性能。支持稀疏化权重压缩(sparse weight compression)来节省存储带宽。内置的维诺格拉德卷积(Winograd convolution)支持对某些尺寸的过滤器提高计算效率。批量卷积(batch convolution)可以在并行运行多个推理的时候,通过重用权重(reuse weight)来节省存储带宽。
为了避免对系统存储器的重复访问,NVDLA卷积引擎内置了一个保留的RAM用于群众和特征数据的存储,称为卷积缓存(convolution buffer)。这种设计,在每个独立时间,权重或特征数据需要通过发送请求给系统存储控制器的时候,可以大大提高存储效率。
卷积单元对应到TensorFlow操作,就是tf.nn.conv2d.
Single Data Point Processor(SDP)单数据点处理器
SDP考虑的是,单个数据点的线性和非线性函数应用,这种应用在CNN系统中的卷积之后非常广泛。SDP有个查找表来实现非线性函数,或者对于线性函数它支持简单的偏置和缩放(bias and scaling)。这种组合可以支持大部分激活函数(activation funtions),以及其他逐个像素的操作(element-wise oprations),包括ReLU,PReLU,precision scaling(精度缩放),batch normalization(批量归一化),或其他复杂的非线性函数,比如sigmoid或hyperbolic tangent(双曲正切函数)。
SDP对应到TensorFlow操作上,包括tf.nn.batch_normalization, tf.nn.bias_add, tf.nn.elu, tf.nn.relu, tf.sigmoid, tf.tanh, 等等
Planar Data Processor(PDP)平面数据处理器
PDP支持特定空间的操作,这在CNN应用中非常普遍。它在运行时是可配置的,支持不同的池化组大小,支持三种池化函数:maximum-pooling,minimum-pooling和average-pooling。
PDP对应到TensorFlow操作上,是tf.nn.avg_pool, tf.nn.max_pool和tf.nn.pool。
Cross-channel Data Processor(CDP)跨通道数据处理器
CDP是一个特殊的单元,应用于本地响应归一化函数(local response normalization funtions),LRN是一个特殊的归一化函数,它在通道维度进行操作,而不是在空间维度。
CDP对应到TensorFlow操作上,就是tf.nn.local_response_normalization函数。
Data Reshape Engine(RUBIK)数据重整引擎
RUBIK完成数据格式转换(比如,splitting分割,slicing切片,merging合并,contraction收缩,reshape-transpose重整转置)。在卷积网络执行推理的过程中,内存中的数据经常需要被重新配置(reconfigured)或重整(reshaped)。比如,slice操作用来分割不同的特征或图像的空间区域,reshape-transpose操作(常见于deconvolutional networks解卷积网络)用来创建比输入数据更高维度的输出数据。
数据重整引擎对应到TensorFlow操作上,比如,tf.nn.conv2d_transpose, tf.concat, tf.slice, tf.transpose。
Bridge DMA(BDMA)桥接DMA:一种数据拷贝引擎
BDMA模块提供了一种数据拷贝引擎,实现系统DRAM和专用高性能存储接口之间的数据搬运,这是一个加速通道,否则这两者是没有直接连接的存储系统。
Configurability可配置能力
NVDLA拥有一系列可配置的硬件参数,来平衡面积,功耗和性能。下面是这些选项的一个简要列表:
Data types:NVDLA天然支持各种数据类型,适用丰富的功能单元,也可以选择其中一个子集来节省面积,可选择的数据类型包括:binary; int4; int8; int16; int32; fp16; fp32; fp64。
Input image memory formats:NVDLA支持平面图(planar image),半平面图(semi-planar image)和其他压缩内存格式的图像,这些不同的模式可以使能或关掉,来节约面积。
Weight Compression权重压缩:NVDLA有一个机制,通过稀疏化存储卷积权重,来减少存储带宽,这个特性可以被关掉来节约面积。
Winograd convolution:维诺格拉德算法,是对卷积的某些维度进行优化。NVDLA可以打开或关掉对这个算法的支持。
Batched convolution:批处理是一个特性,可以节省存储带宽,NVDLA可以配置
Convolution buffer size:卷积缓存由一组bank构成,bank数量232,每个bank大小4KiB8KiB,通过把这两个数相乘,可以确定要实例化的卷积缓存空间的总量。
MAC array size:乘法累加器引擎由两个维度形成,width宽(C维度)范围是864,depth深(K维度)范围是464,创建的乘法累加器的总数量可以由这两个数字相乘得到。
Second memory interface(副存储器接口):是否去除。NVDLA已经支持用于高速存取的副存储器接口,也可以编译为只支持一种存储接口。
Non-linear activation functions(非线性激活函数):是否去除。为了节省面积,支持非线性激活函数(比如sigmoid或tanh)的查找表(the lookup table),可以选择去除。
Activation engine size激活引擎大小:激活层的输出数量,每cycle产生[1, 16]个输出
Bridge DMA engine桥接DMA引擎:是否去除
Data reshape engine数据重整引擎:是否去除
Pooling engine presence池化引擎:是否去除
Pooling engine size池化引擎:大小。每cycle产生1~4个输出
Local response normalization engine presence(LRN局部响应归一化引擎):是否去除
Local response normalization engine size(LRN局部响应归一化引擎):大小。每cycle产生1~4个输出
Memory interface bit width(存储接口位宽):根据外部存储器接口的位宽,调整内部缓存的大小合适,进行调参。
Memory read latency tolerance(存储读取的延迟容忍度):内存延迟时间定义为:从读请求到读数据返回的时钟数(the number of cycles)。这种延迟容忍可以设定,影响每次读取DMA引擎缓存大小的内部延迟。
软件设计
NVDLA有一个完整的软件生态支持它。部分包括:片上软件栈(on-device software stack),一部分NVDLA开源代码,另外,英伟达将提供一个完整的训练平台来构建新的深度学习模型,并且把已有的模型转换成NVDLA软件可用的格式。总体来说,和NVDLA相关的软件归为两类:the compilation tools(模型转换)和the runtime environment(运行时软件在NVDLA上加载和执行网络推理)。总体流程如Fig3所示,各个部分在下面详述。
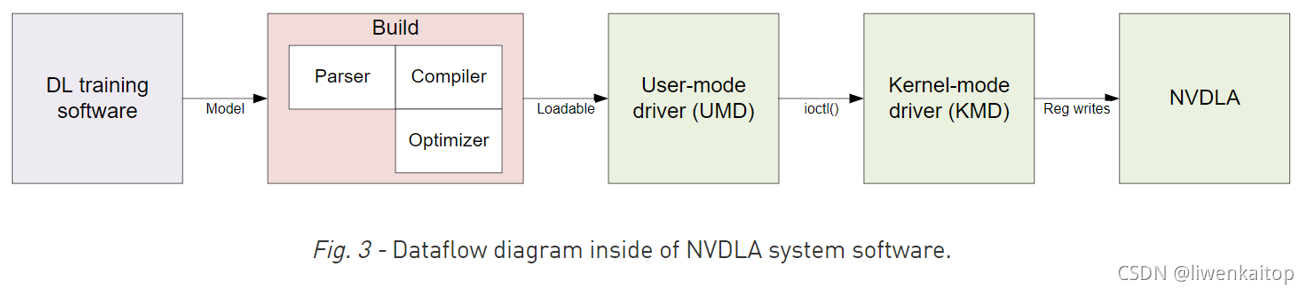
Compilation Tools编译工具:模型创建和编译
编译工具包括compiler(编译器)和parser(解析器)。Compiler负责:创建一系列用给定的NVDLA配置文件优化过的硬件层(hardware layers);有一个硬件层的优化网络,通过降低模型大小,加载和运行时间来提高整体性能;Compilation是分离成多个步骤的过程,他们总体属于两个基本部件:parsing和compiling。Parser可以相对简单,作为一个基本形态,它可以读取一个预训练的Caffe模型,并创建一个网络的中间表达,传递给compilation的下一个步骤。Compiler以解析出的中间表达和NVDLA实现的硬件配置作为输入,产生一个硬件层的网络。这些步骤是离线执行的,也可能在包含NVDLA实现的设备上执行。
了解NVDLA实现的特定硬件配置是很重要的,它使编译器compiler为可供选择的特征,生成合适的硬件层layers。比如,这可能涉及在不同的卷积操作模式之间进行选择(Winograd卷积,或者,基本卷积),或者,依赖可选择的卷积buffer大小,将卷积操作为多个更小的操作。这一阶段也负责把模型量化(quantizing)到更低的精度,比如8-bit或16-bit 整型,或16-bit浮点型,并且为权重(weights)分配内存区域。同一个编译器工具,可以用来产生多种不同NVDLA配置的一系列操作。
Runtime Environment运行时环境:在设备上进行模型推理
Runtime环境涉及在一个兼容的NVDLA硬件上运行一个模型,它实际上可以分为两层:
User Mode Driver(UMD),这是用户模式编程的主要接口。在解析(parsing)神经网络后,编译器(conpiler)通过一层一层的把网络转换成一个叫做NVDLA Loadable的文件格式。UMD加载这个可执行文件,并提交推理任务给KMD。
Kernel Mode Driver(KMD),由驱动(drivers)和固件(firmware)组成,完成的任务包括调度NVDLA上的硬件层操作,并编程NVDLA寄存器来配置每个功能块。
Runtime执行开始于一个保存好的网络表达,存储的格式称为“NVDLA loadable”图像。站在可加载的视角,NVDLA实现中的每个功能块都被表达为软件中的一个层(layer);每个layer包括了它的依赖,它在输入输出的内存中用到的tensors,和每个操作对应的功能块的特定配置。Layers通过一个依赖图(dependency graph)被连接起来,KMD用这个依赖图来调度每个操作。NVDLA loadable的格式是一种标准格式,适用于编译器实现和UMD实现。所有遵从NVDLA标准的实现应该能够至少理解任何NVDLA loadable image,即使这个实现可能不包含一些为了使用loadable image来运行推理所要求的特性。
UMD 有一组标准应用编程接口API,来处理loadable images,绑定输入输出tensor到内存区域,以及运行推理。这个层用一组定义好的数据结构,把网络加载到内存,并把它以实现定义的风格(implementation-defined fasion)传递给KMD。比如,在linux上,这可以是一个ioctl()调用,实现将数据从UMD传递到KMD;而在一个单进程系统中,KMD和UMD运行在相同的环境中,这就可以是一个简单的函数调用。
KMD的主要入口,接收了内存中的一个推理任务(inference job),从多个可见的任务中选择一个进行调度(如果在一个多进程系统中),并提交到核心引擎调度器(the core engine scheduler)。这个核心引擎调度器负责处理NVDLA的中断,调度每个独立功能块上的layers,基于前一个layer的任务完成,去更新当前layer的任何依赖。调度器使用依赖图中的信息,来决定什么时候调度接下来的layers;这允许调度器以优化过的方式去决定layer调度,避免不同KMD实现之间的性能差异。
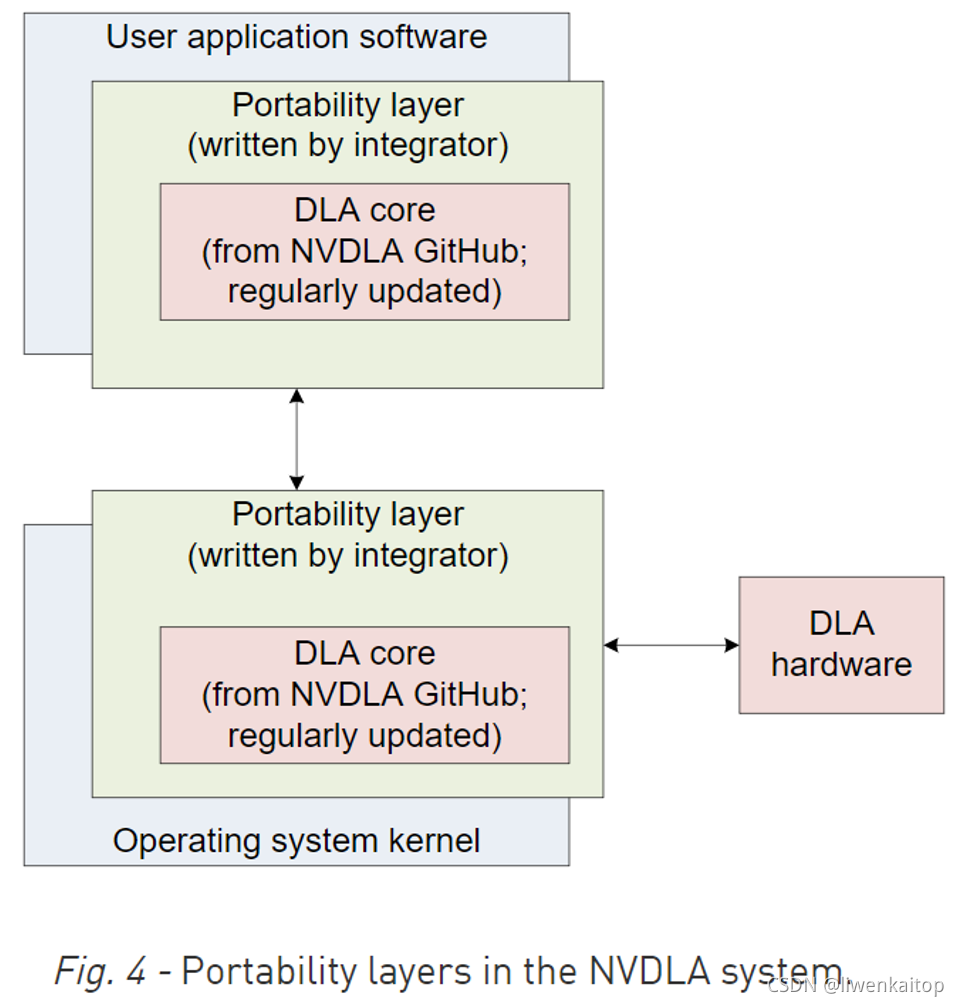
UMD软件栈和KMD软件栈都存在于标准定义的API,并希望能够被封装在一个**系统可移植层(portability layer)**里。在可移植层里维护的核心实现,预计需要相对少的修改并可以加快有必要在多种平台上运行NVDLA软件栈的工作;代之以合适的可移植层后,相同的核心实现,在Linux和FreeRTOS上都可以方便的编译。同样的,对于Headed这种有一个和NVDLA紧耦合的微控制器的模式来说,存在一个可移植层,使他可以像没有这种协处理器的headless实现一样,可以在微控制器上和主CPU上,运行相同的底层软件。
NVDLA系统集成
NVDLA可以配置为各种性能级别;选择这些参数依赖于对执行的CNN的要求,本节描述了一些影响这些参数选择的因素,以及它们对系统面积和性能的影响方面的思考。运行每个layer的时间,是数据输入,输出和执行乘法累加操作中的最大时间,运行整个网络的时间等于所有layer运行的时间之和。在确定芯片尺寸的过程中,选择正确的MAC单元数量,卷积buffer大小,适用于要求性能的片上SRAM大小都是非常关键的步骤。NVDLA还有很多配置参数进行额外的性能调参,都需要认真考虑,这些可能对系统面积影响较小,但也应该合理配置不至于形成系统瓶颈。
Tuning调参优化相关问题
对于任何给定的实例化所期望的工作量,要求达到什么样的数学精度?
在更大量的配置参数中,最主要的NVDLA面积(area),用于卷积buffer和MAC单元,因此,在最初的性能面积权衡分析时,这些参数是最重要的。深度学习训练通常用32-bit浮点型精度来做,但是结果网络经常可以在不明显损失推理质量的前提下,被量化到8-bit整型。然而,在某些场景下,仍然希望使用16-bit整型或浮点型。
MAC单元数量和要求的存储带宽如何确定?
除了精度以外,对性能和面积而言,两个最关键的参数就是MAC单元的数量和存储带宽。配置NVDLA的时候这些都要仔细考虑。推理是一层一层进行的,所以性能评估最好也逐层进行(layer-by-layer)。对于任何给定的layer,通常而言,要么是MAC throughput(MAC吞吐量)成为瓶颈,要么是memory bandwidth(存储带宽)成为瓶颈。
MAC单元数量相对容易确定。比如说,一个卷积层已知输入和输出的分辨率,且已知输入和输出的特征数量,卷积核(convolution kernel)的大小也已知。把这几个乘起来就算出了这个卷积层要进行MAC操作的总数量。硬件可以定义有一定数量的MAC单元,用需要的操作数量除以MAC单元的数量,就得出了可以完成处理一个layer的clock cycle(时钟周期)数量的下边界。
计算存储带宽不那么繁琐。在理想的情况下,只要读一次输入图像,一次输出图像,一次权重,那么最小的时钟周期数就是这些的总和,除以每个时钟周期里可以读写的样例(samples)数量。然而,如果卷积buffer太小,不足以支持输入和权重存储的区域,就需要多次通过。比如说,如果卷积buffer只够1/4的权重数据,那么这个计算必须被分割成4步,乘以输入带宽(10MB输入内存流量,将乘到40MB)。同样的,如果buffer不足以存储卷积的所有行(lines),那么卷积也要被分割成水平条(horizontal strips)。在选择卷积buffer大小和存储接口大小的时候,这种影响是很重要的。
是否有必要用到片上SRAM(on-chip SRAM)?
如果外部存储带宽因功耗或性能等原因而非常昂贵,那么增加片内SRAM就是有帮助的。这种SRAM可以被看作二级缓存,它可以比主存储器的带宽更高,而且这个带宽对于主存储器带宽来说是可以加上算的。实现更大的卷积buffer需要更宽的端口和非常严格的存储时间要求,而增加片上SRAM就不那么昂贵,同时,在卷积buffer受限(convolutional-buffer-limited)的应用中,不要认为这种因素只是乘法的效果。(比如,如果一个layer是带宽受限的,增加一个足够装下整个输入图像的SRAM,使得运行速度达到系统DRAM的两倍,可以使整体性能达到原来的两倍。然而,如果layer同时受限于卷积buffer大小,相同数量的存储对系统吞吐量的提升,可以大大超过乘法的效果)。考虑这种权衡的最好方式是,增加卷积buffer的大小,只能帮助降低带宽的要求,然而增加片内SRAM则可以提升总体可用的带宽。
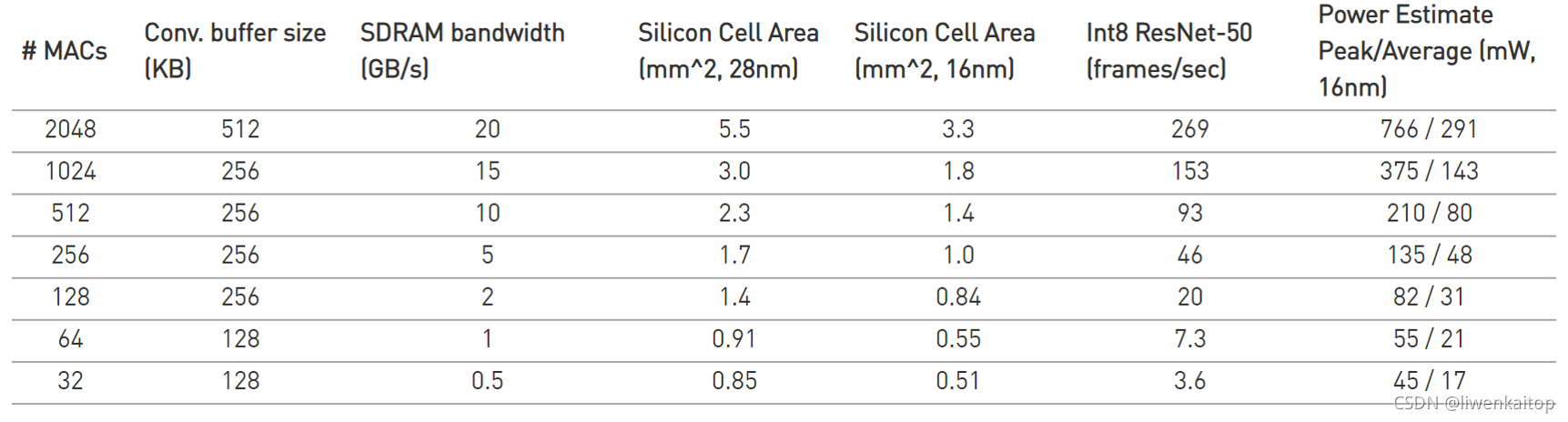
NVDLA实现的一个面积和性能的数据例子
下面表格提供了针对流行的ResNet-50神经网络优化的NVDLA配置,做的一个评估。给出的area面积估计了合成面积,包括所有需要的存储器;真实的面积结果受到生产厂家(foundry)和库(libraries)的影响会有所不同。在这个例子中,没有使用片内SRAM。如果可用的SDRAM带宽小的话,片内SRAM是非常有益的。开源发布的NVDLA里有一个性能评估工具(performance estimator tool)可用于探讨NVDLA设计的空间和对性能的影响。
下表中的功耗和性能显示基于1GHz的主频,对于给定配置的功耗和性能,会因电压和主频的不同而有所不同。
Sample Platforms示例平台
所提供的示例平台允许用户在一个最小SoC环境中观察,评估和测试NVDLA。一个最小SoC系统配置包含一个CPU,一个NVDLA实体,一个互连和存储器。这些平台可以用作软件开发,或者作为一个开始,把NVDLA集成到一个强大的SoC里去(industrial-strength SoC)。
模拟仿真
NVDLA开源发布里,包含一个基于GreenSocs QBox的仿真平台。在这个平台上,一个QEMU CPU模型(x86或ARMv8)和NVDLA SystemC模型被结合起来,提供了一个寄存器级精确的系统(register-accurate system),在其上可以进行快速的软件开发和调试。
FPGA
示例平台把NVDLA Verilog模型映射到一个FPGA上,提供了一个真实设计的NVDLA实例化的综合例子。在这个平台上,NVDLA SystemC模型不需要用了,软件读写寄存器直接在真实的RTL环境里。这允许有限的使用时钟周期计数(cycle-counting)的性能评估,也允许甚至更快的软件测试,跑更大更复杂的网络。FPGA模型仅用于验证,在优化时钟周期时间,设计大小或FPGA平台的功耗方面,没有进行任何努力。FPGA模型的性能和其他基于FPAG的深度学习加速器(other FPGA-based Deep Learning accelerators),不具有直接的可对比性。
FPGA系统模型使用Amazon EC2 “F1”环境,这是一个公开的标准化的FPGA系统,可以按小时租用。使用这个模型,没有任何特殊的硬件或软件需要预先采购;在Amazon EC2环境上,综合软件只可用于计算时间的代价,硬件不需要承诺即可访问。因为这个FPGA平台是基于赛灵思的(Xilinx-based),迁移到其他Virtex系列设备上应该相对简单直观一些。
模型
NVDLA IP-core模型是基于开放的工业标准的。对基本结构过于简化的设计和使用,期望能够简单的集成到典型的SoC设计流程中。
Verilog模型
Verilog模型提供了一个RTF格式的综合仿真模型,它有四个功能接口:一个从主机接口(slave host interface),一个中断线,两个主接口分别用于内部和外部存储器访问。Host接口和存储器接口是非常简单的,但是要求外部总线适配器(external bus adapters)连接到一个已存在的SoC设计;方便起见,样例适配器包含了AXI4和TileLink作为NVDLA开源发布的一部分。NVDLA开源发布包含一些示范的合成脚本(synthesis scripts)。为了促进更复杂系统或更大NVDLA实例上的物理设计,这个设计被划分成不同的部分,在SoC后端流程中,每个部分可以独立的处理。各部分之间的接口如有需要也可以退休,来满足路由要求。
NVDLA核在单个时钟域(clock domain)内操作;总线适配器要考虑时钟域跨越内部NVDLA时钟和总线时钟。相似的,NVDLA也在单个功耗域里操作;这种设计应用于细粒度和粗粒度功耗门限。如果实现SRAM,要通过行为模型(behavioral models)建模并在完整的SoC设计中通过编译RAMS来代替。NVDLA设计需要实现单端口(single-ported)和双端口(dual-ported,一个读端口加一个写端口)的SRAM。
simulation模型和验证套件(verification suite)
NVDLA包含一个TLM2 SystemC仿真模型用于软件开发,系统集成和测试。这个模型允许更快的仿真,比其他可用的通过运行RTL连接信号激励模型(signal-stimulus models)的方式更快。这种SystemC模型扩展用于完整的SoC模拟环境,比如新思科技(Synopsys)的VDK,或者,已提供的GreenSocs QBox平台。这些内含的模型在相同的轴上可以参数化控制,就像RTL模型一样,进行直接的对比和仿真。
仿真模型也可以用于NVDLA测试平台和验证套件。这种轻量化的带有trace的(trace-player-based)测试平台,对于简单的合成和构建健康的验证,是合适的(这在最初的NVDLA发布里就有)。一个包含大量逐个单元测试(unit-by-unit testing)的验证环境将在后续的发布中包含。验证套件可以在投片(tape-out)之前为设计提供保证,包括验证compiled RAMs,clock-gating和scan-chain insertion的修改,这种环境将对进行大量修改的项目是合适的(比如,验证新的NVDLA配置或从已存在的NVDLA设计进行修改)。
软件
最初的NVDLA开源发布包括一个headless实现的软件,兼容Linux。一个KMD和用户模式测试程序也以源码方式提供,并可以在运行在非必要不修改的Linux系统上面。
附录:深度学习参考
(略)

















 5266
5266

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









