







简介
1、RDS
阿里云关系型数据库(Relational Database Service,简称 RDS)是一种稳定可靠、可弹性伸缩的在线数据库服务。
基于阿里云分布式文件系统和高性能存储,RDS 支持 MySQL、SQL Server、PostgreSQL 和 PPAS(Postgre Plus Advanced Server,一种高度兼容 Oracle 的数据库)引擎,并且提供了容灾、备份、恢复、监控、迁移等方面的全套解决方案,彻底解决数据库运维的烦恼。
RDS for MySQL 可以认为是云上的MySQL。
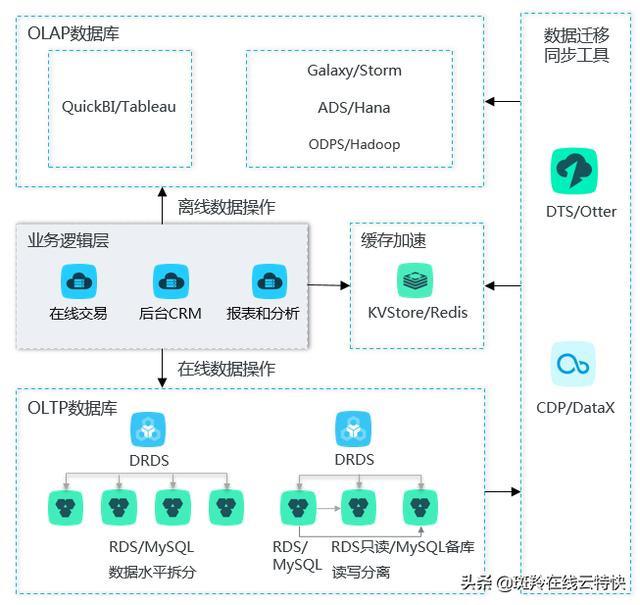
2、DRDS
分布式关系型数据库服务(Distributed Relational Database Service,简称 DRDS)是阿里巴巴致力于解决单机数据库服务瓶颈问题而自主研发推出的分布式数据库产品,解决了一些传统单库 RDS 数据库的痛点。
DRDS 高度兼容 MySQL 协议和语法,支持自动化水平拆分、在线平滑扩缩容、弹性扩展、透明读写分离,具备数据库全生命周期运维管控能力。
DRDS 前身为淘宝 TDDL,是近千核心应用首选组件。
DRDS 可以认为是云上的TDDL中间件。DRDS必须依赖RDS。
2.1 DRDS 主要解决的哪些问题?
- 单机数据库容量瓶颈: 随着数据量和访问量的增长,单机数据库会遇到很大的挑战,依赖硬件升级并不能完全解决问题。
- 单机数据库扩展困难:传统数据库容量扩展往往意味着服务中断,很难做到业务无感知或者少感知。
- 传统数据库使用成本高: 当业务数据和访问量增加到一定量时,传统数据库需要依赖特定的高端存储和小型机设备,成本曲线快速上升。
调优经验
由于 DRDS 是一个分布式关系数据库服务,处理的是分布式关系运算。分布式无疑会带来额外的跨库网络开销,而大家都知道,网络通信的延迟比单机内通信的延迟大得多。
因此分布式环境中优化更应侧重考虑:
- 减少网络传输;
- 减少 DRDS 计算量,尽量将计算下推到下层的数据节点上,让计算在数据所在的机器上执行;
- 充分发挥下层存储的全部能力。
1、数据库 - 表创建优化
数据库表的创建优化是最基本的数据优化,是需要在数据模型建立时就需要确定数据的存储、分片和路由的方式。如果模型设计的不够科学合理,后期通过应用的 SQL 来优化,都是成效甚微的。特别是对 DRDS 分布式数据库而言,一旦数据表建立了,后期的分库分表的拆分方式是无法进行修改的,即便数据表删除重建,数据的恢复相对麻烦。
在 DRDS 的数据库表中,主要存在有以下几种形式:
1.1 单库单表
对于数据量不大的数据表,可以如同普通的单库 RDS 表一样,建立单库单表。但由于 DRDS 上单库单表只存在 0 库上,和其他不在 0 库的表可能存在跨库 JOIN 的风险。
此外,过多的单库单表,容易造成 DRDS 后端分库资源损耗不平衡,0 库的 IO 消耗过大的问题,应尽量予以避免。
1.2 小表广播
对于数据量少,且数据变化不频繁,数据一致性要求不高的单库单表,为了解决上述的跨库问题,可以考虑使用小表广播。小表广播是指将表复制到每个分库上,在分库上通过同步机制实现数据一致,但存在秒级延迟。好处在于,可以将 JOIN 操作下推到底层的分库,来避免跨库 JOIN,提高执行效率。如下所示,建表时使用 BROADCAST 关键字:
CREATE TABLE users (
user_id int,
user_name varchar(50),
create_time date,
primary key(id)
) ENGINE=InnoDB BROADCAST;除了使用命令,也可以在 DRDS 控制面板上指定广播表。
但需要额外注意,小表广播的使用限定:
- 表数据量少,尽量不应超过 10 万;
- 数据的更新不能太频繁;
过大的表和更新过于频繁,都容易增加 DRDS 数据库底层 IO 压力和网络消耗。
1.3 分库分表
DRDS 在后端将数据量较大的数据表水平拆分到后端的每个 RDS 数据库中,这些拆分到 RDS 中的数据库被称为分库,分库中的表称为分表。
拆分后,每个分库负责每一份数据的读写操作,从而有效的分散了整体访问压力。而分库分表优化的目的在于,重点减轻分布式环境中的网络 IO 开销,尽量将 SQL 中的运算下推到底层各个分库执行,从而减少网络 IO 开销、提升 SQL 执行效率。
1.3.1 如何确定是否分库分表
一般情况下,单个物理分表的容量不超过 500 万行数据。我们通常可
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 6208
6208

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











