







Python 正则表达式
常用元字符:
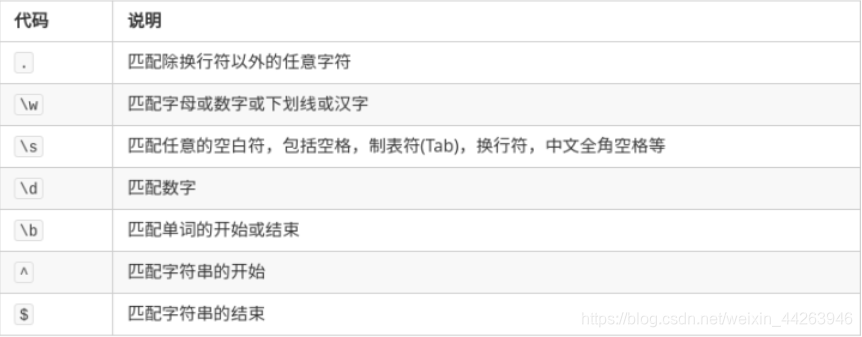
常用限定符:
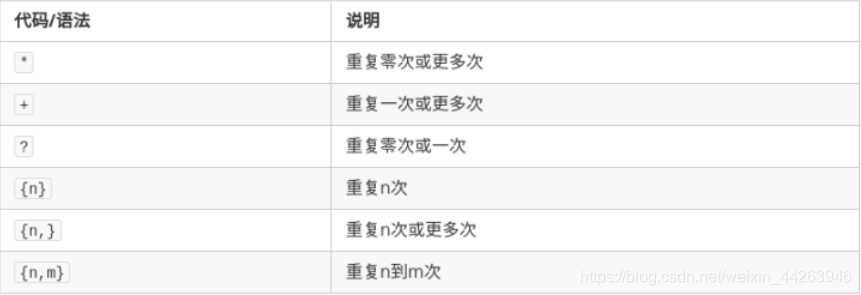
分枝条件:
满足其中任意一种规则就当成匹配成功,需要使用分枝条件:使用管道|把不同的规则分开,这时候会从左到右地测试每个条件,如果满足了其中一个分枝,后面的规则就被忽略掉。
分组:
使用()来指定子表达式,可以指定这个子表达式的重复次数或者进行其它操作。
反义:

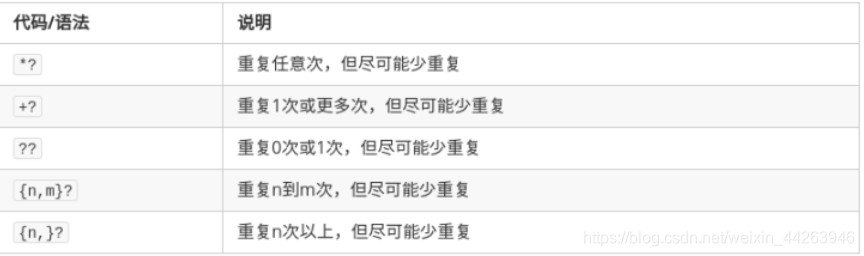
贪心和非贪心:
?在正则表达式中可能有两种含义,声明非贪心匹配或表示可选的分组
简单示例
# 推荐使用 Python 正则表达式的几个步骤
import re
regex = re.compile(r'正则表达式') # 创建一个 Regex 对象,使用 r'' 原始字符串不需要转义
regex.match() #
regex.search() # 返回一个 Match 对象,包含被查找字符串中的第一次被匹配的文本
regex.findall() # 返回一组字符串列表,包含被查找字符串中的所有匹配
regex.sub() # 替换字符串,接收两个参数,新字符串和正则表达式
...
>>> import re
>>> regex = re.compile(r'\b\w{6}\b') # 匹配6个字符的单词
>>> regex.search('My phone number is 421-2343-121')
>>> text = regex.search('My phone number is 421-2343-121')
>>> text.group() # 调用 group() 返回结果
'number'
>>> regex = re.compile(r'0\d{2}-\d{8}|0\d{3}-\d{7}') # 注意分枝条件的使用
>>> text = regex.search('My phone number is 021-76483929')
>>> text.group()
'021-76483929'
>>> text = regex.search('My phone number is 0132-2384753')
>>> text.group()
'0132-2384753'
>>> regex = re.compile(r'(0\d{2})-(\d{8})') # 括号分组的使用
>>> text = regex.search('My phone number is 032-23847533')
>>> text.group(0)
'032-23847533'
>>> text.group(1)
'032'
>>> text.group(2)
'23847533'
>>> regex = re.compile(r'(0\d{2}-)?(\d{8})') # ?之前的分组表示是可选的分组,如果需要匹配真正的?,就使用转义字符\?
>>> text = regex.search('My phone number is 032-23847533')
>>> text.group()
'032-23847533'
>>> text = regex.search('My phone number is 23847533')
>>> text.group()
'23847533'
>>> regex = re.compile(r'(Py){3,5}') # Python 默认是贪心,尽可能匹配最长的字符串
>>> text = regex.search('PyPyPyPyPy')
>>> text.group()
'PyPyPyPyPy'
>>> regex = re.compile(r'(Py){3,5}?') # ? 声明非贪心,尽可能匹配最短的字符串
>>> text = regex.search('PyPyPyPyPy')
>>> text.group()
'PyPyPy'
# 这里测试 findall() 以及 sub()
# findall()
>>> regex = re.compile(r'0\d{2}-\d{8}|0\d{3}-\d{7}')
>>> regex.findall('Cell: 021-38294729, Work: 0413-3243243')
['021-38294729', '0413-3243243']
>>> regex = re.compile(r'Hello \w+')
>>> regex.sub('Hello Python', 'falkdjfsk Hello c sldfjlksdj Hello java sdfsj')
'falkdjfsk Hello Python sldfjlksdj Hello Python sdfsj'
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
# author: Windrivder
# email : windrivder@gmail.com
# date : 17/03/27 12:58:05
import re, pyperclip
# 匹配电话
phoneRegex = re.compile(r'''(
^(13[0-9]| # 匹配13开头的电话
14[5|7]|
15[0|1|2|3|5|6|7|8|9]|
18[0|1|2|3|5|6|7|8|9])
\d{8}$
)''', re.VERBOSE) # 如上,传入参数 re.VERBOSE 可以给正则表达式添加注释,详见附录
# 匹配邮件地址
emailRegex = re.compile(r'''(
[a-zA-Z0-9._%+-]+ # email-username
@
[a-zA-Z0-9.-]+ # domain-name
(\.[a-zA-Z]{2,4}) # dot-something
)''', re.VERBOSE)
# 从剪贴板中获取字符串
text = str(pyperclip.paste())
# 存放匹配到的字符串
matches = []
for phone in phoneRegex.findall(text):
matches.append(phone[0])
for email in emailRegex.findall(text):
matches.append(email[0])
# 将匹配到的字符串复制到剪贴板
if len(matches) > 0:
pyperclip.copy('\n'.join(matches))
print('Copied to clipboard:')
print('\n'.join(matches))
else:
print('No phone or email found.')
邮箱名称规则的正则表达式
在现有找到的邮箱表达式不够满意的情况下,自己写了一个。
特性如下:
邮箱首字符和末尾字符必须为字母或数字,邮箱名可以全是字母或数字,或者是两者的组合;
连字符"-"、下划线"_" 和英文句号点".",仅能放在字母或数字中间,且不能连续出现(即其单个符号的左右只能是字母或数字);
域名可以带连字符"-", 且可以是多级域名 ,还可以有多个域名后缀;
不区分大小写;
不限定邮箱字符串的具体长度。
复制代码
1 var emailReg=/^[\da-z]+([\-\.\_]?[\da-z]+)*@[\da-z]+([\-\.]?[\da-z]+)*(\.[a-z]{2,})+$/i;
2
3 console.log(emailReg.test('_abc@sample.com')); // false
4 console.log(emailReg.test('a23..bc@sample.com')); // false
5 console.log(emailReg.test('a23.-bc@sample.com')); // false
6 console.log(emailReg.test('a23.bc.@sample.com')); // false
7 console.log(emailReg.test('a23.bc@@sample.com')); // false
8 console.log(emailReg.test('2abc@sample.com')); // true
9 console.log(emailReg.test('2345@sample.com')); // true
10 console.log(emailReg.test('a2-3.b_c3@sample.com')); // true
11 console.log(emailReg.test('a2-3.b_c3@sam-ple.com.CN')); // true
复制代码
几个常用的正则表达式
# 校验密码强度
^(?=.*\\d)(?=.*[a-z])(?=.*[A-Z]).{8,10}$ #包含大小写字母和数字的组合,不能使用特殊字符,长度在8-10之间
# 校验中文
^[\\u4e00-\\u9fa5]{0,}$
# 由数字、26个英文字母或下划线组成的字符串
^\\w+$
# 校验E-Mail 地址
[\\w!#$%&'*+/=?^_`{|}~-]+(?:\\.[\\w!#$%&'*+/=?^_`{|}~-]+)*@(?:[\\w](?:[\\w-]*[\\w])?\\.)+[\\w](?:[\\w-]*[\\w])?
# 校验18位身份证
^[1-9]\\d{5}[1-9]\\d{3}((0\\d)|(1[0-2]))(([0|1|2]\\d)|3[0-1])\\d{3}([0-9]|X)$
# 校验日期
^(?:(?!0000)[0-9]{4}-(?:(?:0[1-9]|1[0-2])-(?:0[1-9]|1[0-9]|2[0-8])|(?:0[13-9]|1[0-2])-(?:29|30)|(?:0[13578]|1[02])-31)|(?:[0-9]{2}(?:0[48]|[2468][048]|[13579][26])|(?:0[48]|[2468][048]|[13579][26])00)-02-29)$ # “yyyy-mm-dd“ 格式的日期校验,已考虑平闰年
# IP4 正则语句
\\b(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\\b
# 提取URL链接
^(f|ht){1}(tp|tps):\\/\\/([\\w-]+\\.)+[\\w-]+(\\/[\\w- ./?%&=]*)? # 可在爬虫代码中使用
# 提取网页图片
\\< *[img][^\\\\>]*[src] *= *[\\"\\']{0,1}([^\\"\\'\\ >]*)
# 提取网页超链接
(<a\\s*(?!.*\\brel=)[^>]*)(href="https?:\\/\\/)((?!(?:(?:www\\.)?'.implode('|(?:www\\.)?', $follow_list).'))[^"]+)"((?!.*\\brel=)[^>]*)(?:[^>]*)>
# 匹配HTML标签
<\\/?\\w+((\\s+\\w+(\\s*=\\s*(?:".*?"|'.*?'|[\\^'">\\s]+))?)+\\s*|\\s*)\\/?>














 605
605











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









