






2023前端面试题
- 一、js部分
- 1、v-if和v-show
- 2、apply() 、call()、bind()
- 3、什么是闭包
- 4、Promise
- 5、axios是怎么做封装的?
- 6、js的数据类型及它的判断
- 7、在地址栏中输入一个URL地址,这个过程会发生什么
- 8、垃圾回收机制是什么?
- 9、js跨域如何解决
- 10、深浅拷贝
- 11、js事件流是什么,如何阻止事件冒泡,阻止事件的默认行为
- 12、cookie、与session、 localstorage、seesionstorage的区别
- 13、js实现继承的方式
- 14、require和import的区别
- 15、实现异步的方法有哪些
- 16、箭头函数和普通函数的区别
- 17、async和defer的区别
- 18、原型与原型链
- 19、脚本延迟加载的方式有哪些
- 20、贪心算法
- 21、Math
- 22、let const var 的区别
- 23、for in和 for of的区别
- 24、ES6有哪些新特性
- 25、 v-for为什么一定要有key
- 26、数组去重的方法
- 27、隐式转换
- 二、css部分
- 三、HTML部分
- 四、Vue部分
- 五、Jquery部分
- 六、浏览器
- 七、Vuex
一、js部分
1、v-if和v-show
相同点:都是控制元素显示与否
不同点:
v-show 原理是修改元素的的CSS属性(display)来决定实现显示还是隐藏
v-if 本质是通过操纵dom元素来进行切换显示,表达式的值为true的时候元素存在于dom树中,为false的时候从dom树中移除
2、apply() 、call()、bind()
相他们的共同点是都可以修改函数的this指向,但各自的传参方式和执行机制有所不同。
call()方法:使用指定的this值和单独给出的一个或多个参数来调用一个函数。传递参数是以arg1, arg2…的形式。
apply()方法:也是使用指定的this值和单独给出的一个或多个参数来调用一个函数,但是参数必须以数组形式[arg]传入。
bind()方法:这个方法不会立刻调用函数,而是返回绑定了this之后的函数,可以用于稍后再次调用。它允许你分期传入参数,而不是一次性全部传入。*
3、什么是闭包
闭包是指能够访问其他函数内部变量的函数,也可以说被嵌套的函数就叫做闭包函数。在JavaScript中,如果一个函数可以访问外部函数的作用域链中的变量,那么它就是一个闭包。闭包可以用来实现模块化、封装变量等功能。
为什么需要闭包?
闭包可以用在许多地方,最大的用处有两个:
一个是可以获取函数内部的变量;
一个是让这些变量的值始终保存在内存中,不会在被调用后自动清除
总结:局部变量无法共享和长久的保存,而全局变量可能会造成变量污染,我们需要一种机制可以长久的保存变量又不会造成全局污染。闭包就是一个函数引用另一个函数的变量,因为变量被引用着,所以不会被回收,因此可以用来封装私有变量,这是优点也是缺点,不必要的闭包只会增加内存消耗
**PS:如何解决闭包造成的内存泄露?
在不需要重复引用的时候我们把它在引用后置为null,或者手动清除 **
4、Promise
5、axios是怎么做封装的?
下载 创建实例 接着封装请求响应拦截器 抛出 最后封装接口
6、js的数据类型及它的判断
JavaScript一共有七种数据类型,它们又被分为两类:基本数据类型和引用数据类型。具体如下:
基本数据类型:
数字(Number):整数或浮点数,例如:3、3.14。
字符串(String):一串字符,例如:“hello”。
布尔值(Boolean):true或false。
空(Null):表示空值或不存在的对象。
未定义(Undefined):表示未定义的值。
Symbol:ES6新增的数据类型,表示唯一的值。
引用数据类型:
对象(Object):一组无序的相关属性和方法的集合,例如:{name: “Tom”, age: 18}。
数组(Array):一组有序的数据的集合,例如:[1, 2, 3]。
函数(Function):一段可重复执行的代码块,例如:function add(a, b) {return a + b;}。
类型的判断
使用typeof运算符判断数据类型,返回一个字符串,包括number、boolean、string、function、object、undefined。例如:
typeof 123 // “number”
typeof true // “boolean”
typeof “hello” // “string”
typeof function(){} // “function”
typeof {} // “object”
typeof undefined // “undefined”
需要注意的是,typeof null返回的是"object",这是一个历史遗留问题。
2. 使用instanceof运算符判断对象的类型,返回一个布尔值。例如:
var arr = [1, 2, 3];
arr instanceof Array // true
arr instanceof Object // true,因为Array继承自Object
需要注意的是,instanceof只能用于判断对象类型,不能用于判断基本数据类型。
3. 使用Object.prototype.toString.call()方法判断数据类型,返回一个表示数据类型的字符串。例如:
Object.prototype.toString.call(123) // “[object Number]”
Object.prototype.toString.call(true) // “[object Boolean]”
Object.prototype.toString.call(“hello”) // “[object String]”
Object.prototype.toString.call(function(){}) // “[object Function]”
Object.prototype.toString.call({}) // “[object Object]”
Object.prototype.toString.call(undefined) // “[object Undefined]”
Object.prototype.toString.call(null) // “[object Null]”
- constructor: 指向构造函数,原型链上的方法,所以不能用来判断null和undefined
7、在地址栏中输入一个URL地址,这个过程会发生什么
- 浏览器解析URL:浏览器会解析输入的网址,将其分解为不同的组成部分,如协议(http或https)、主机名、路径和查询参数等。
- DNS查询:浏览器会向DNS服务器发送一个查询请求,以获取与主机名对应的IP地址**。DNS服务器将返回相应的IP地址,以便浏览器能够找到目标网站的位置**。
- 建立TCP连接:一旦浏览器获得了目标网站的IP地址,它会与该IP地址建立一个TCP连接。这是通过三次握手过程完成的,其中浏览器和服务器交换一系列的数据包来确认连接的建立。
- 发送HTTP请求:一旦TCP连接建立,浏览器会向服务器发送一个HTTP请求。这个请求包含了你想要访问的资源的详细信息,如请求方法(GET、POST等)、请求头和请求体等。
- 服务器处理请求:服务器接收到HTTP请求后,会根据请求的内容进行处理。这可能包括检索数据库、执行服务器端脚本、生成动态内容等。
- 服务器发送HTTP响应:一旦服务器处理完请求,它会向浏览器发送一个HTTP响应。这个响应包含了你想要访问的资源的内容,如响应状态码、响应头和响应体等。
- 浏览器渲染页面:浏览器接收到HTTP响应后,会根据响应的内容对页面进行渲染。这可能包括解析HTML、CSS和JavaScript代码,显示图像、视频和其他媒体等。
- 关闭连接:一旦页面完全加载和渲染完成,浏览器会关闭与服务器的TCP连接,以释放资源并准备接收下一个请求。
8、垃圾回收机制是什么?
简述回答
JavaScript引擎内部有一个垃圾回收器,它会在后台运行,监视和管理系统内存。当某些变量不再需要时,即它们无法从根访问到时,垃圾回收器就会认为它们是“垃圾”,并释放它们占用的内存。这个过程就称为垃圾回收。
原理是什么?
标记清除:在运行时给内存所有变量加上标记,然后去除掉在执行环境中的变量和被这些变量引用的变量。剩下的带有标记的变量视为准备删除的变量,最后垃圾回收机制在下周期运行时,释放这些变量,回收占用的空间
引用计数:引用表保存了内存里所有资源的引用次数。这个数为0时,就说明用不到了,就释放。
9、js跨域如何解决
跨域问题是由于浏览器的同源策略导致的。同源策略是一个重要的安全机制,它要求协议、域名和端口号必须完全相同才能进行资源的访问。
以下是几种常见的解决跨域问题的方法:
- JSONP:JSONP是一种非官方跨域解决方案,只支持GET请求。其原理是通过script标签的src属性没有跨域限制的特性,通过在远程服务器上注册一个函数,然后在本地调用这个函数并将数据作为参数传递过去。
jsonp:利用标签没有跨域限制的漏洞,网页可以得到从其他来源动态产生的JSON数据。JSONP请求-定需要对方的服务器做支持才可以。
JSONP优点是简单兼容性好,可用于解决主流浏览器的跨域数据访问的问题。缺点是仅支持get方法具有局限性,不安全可能会遭受XSS攻击。
声明-一个回调函数,其函数名(如show)当做参数值,要传递给跨域请求数据的服务器,函数形参为要获取目标数据(服务器返回的data)。
创建一个script标签 ,把那个跨域的API数据接口地址,赋值给script的src,还要在这个地址中向服务器传递该函数名(可以通过问号传参:?callback=show)。
服务器接收到请求后,需要进行特殊的处理:把传递进来的函数名和它需要给你的数据拼接成一个字符串,例如:传递进去的函数名是show,它准备好的数据是show( ‘我不爱你’)。
最后服务器把准备的数据通过HTTP协议返回给客户端,客户端再调用执行之前声明的回调函数(show),对返回的数据进行操作。
- CORS:是另一种实现跨域的方式。它是由服务器端实现的,通过设置 HTTP 头部的 Access-Control-Allow-Origin 来允许跨域请求。这种方式比 JSONP 更安全,但是需要服务器端支持。
- 使用代理服务器:可以在服务器端设置一个代理,接收到客户端的请求后,由服务器向目标服务器发送请求,然后再将结果返回给客户端。由于浏览器同源策略的限制是在同一个源的上下文中才会触发,服务器端就没有这个限制。
- WebSocket:WebSocket协议被设计来在单个TCP连接上进行全双工通信。既可以从客户端发送信息到服务器,也可以从服务器发送信息到客户端。
- 使用postMessage API:HTML5引入了一个新的API——window.postMessage,允许来自不同源的脚本采用异步方式进行有限的通信,可以实现跨文本档、跨域等消息传递
10、深浅拷贝
11、js事件流是什么,如何阻止事件冒泡,阻止事件的默认行为
事件流在JavaScript中是一个非常重要的概念,它分为三个阶段:捕获阶段、目标阶段和冒泡阶段。在捕获阶段,事件从顶层元素向下传递,并在到达目标元素之前触发相应的事件处理程序。然后是目标阶段,也就是事件到达目标元素并触发相应的事件处理程序。最后是冒泡阶段,事件从目标元素开始向上回溯,并在到达根元素之前触发相应的事件处理程序。
阻止事件传播可以通过调用事件对象的stopPropagation()方法来实现。例如,假设我们有一个HTML结构如下:<div> <p> <button>点击我</button> </p> </div>。如果我们希望点击按钮后的事件不再传播,可以在按钮的事件处理程序中添加event.stopPropagation()来阻止事件的进一步传播。
需要注意的是,虽然阻止了事件的传播,但事件本身仍然会被处理。此外,阻止事件冒泡并不会阻止事件的默认行为,如果需要阻止事件的默认行为,可以使用preventDefault()方法。
vue的api,给绑定事件
添加stop的api(@click.stop)来阻止事件冒泡
添加prevent(@click.prevent )阻止事件默认行为
12、cookie、与session、 localstorage、seesionstorage的区别
cookie是什么?
**cookie是HTTP服务器发送到用户浏览器并按照域名划分保存到本地的一小块数据
浏览器向服务器发生请求时,会自动将当前域名下可用的cookie设置在请求头中,然后传递给服务器
**
session是什么?
定义:session是保存在服务器端的一块儿数据,保存当前访问用户的相关信息
作用:实现绘画控制,可以识别用户的身份,快速获取当前用户的相关信息
工作流程:填写账号和密码验证身份,校验通过后创建session信息,然后将session_id的值通过响应头返回给浏览器,有了cookie,下次发生请求时会自动携带cookie,服务器通过cookie中的session_id的值确定用户的身份
cookie与session的区别
-
存在的位置
cookie:浏览器端
session:服务端 -
安全性
cookie时以明文的方式存放在客户端的,安全性相对较低
session存放于服务器中,所以安全性相对较好 -
网络传输量
cookie设置内容过多会增大保温体积,会影响传输效率
session数据存储在服务器,只是通过cookie传递id,所以不影响传输效率 -
存储限制
浏览器限制单个的cookie保存的数据不能超过4k,且单个域名下的存储数量也有限制
session数据存储在服务器中,所以以没有这些限制
cookie、localStorage和sessionStorage都是客户端用于临时存储会话信息或数据的技术,但它们之间存在一些主要的区别:
-
与服务器交互:
。cookie 是网站为了标示用户身份而储存在用户本地终端上的数据(通常经过加密)
。cookie 始终会在同源http请求头中携带(即使不需要), 在浏览器和服务器间来回传递
sessionStorage和localStorage不会自动把数据发给服务器,仅在本地保存 -
存储大小:
●cookie 数据根据不同浏览器限制,大小-一般不能超过4k
●sessionStorage 和localStorage虽然也有存储大小的限制,但比cookie大得多,可以达到5M或更大
-
有期时间:
。localStorage 存储持久数据,浏览器关闭后数据不丢失除非主动删除数据
。sessionStorage 数据在当前浏览器窗口关闭后自动删除
。cookie在浏览器关闭后就会删除,除非设置过期时间({maxAge:60*1000})
13、js实现继承的方式
JavaScript中实现继承主要有以下几种方式:
- 原型链继承:通过将子类的原型对象指向父类的实例对象,从而实现继承。这种方式简单易懂,但缺点是如果父类有多个实例,那么每个实例都会有一个指向同一个原型对象的引用,导致内存浪费。
```javascript
function Parent() {
this.name = 'parent';
}
Parent.prototype.sayName = function() {
console.log(this.name);
};
function Child() {
this.age = 18;
}
Child.prototype = new Parent();
Child.prototype.constructor = Child;
var child = new Child();
child.sayName(); // 输出 "parent"
2. 构造函数继承:通过在子类的构造函数中调用父类的构造函数来实现继承。这种方式可以实现更复杂的继承关系,但需要手动管理原型链。
function Parent() {
this.name = 'parent';
}
Parent.prototype.sayName = function() {
console.log(this.name);
};
function Child() {
Parent.call(this);
this.age = 18;
}
Child.prototype = Object.create(Parent.prototype);
Child.prototype.constructor = Child;
var child = new Child();
child.sayName(); // 输出 "parent"
**3 ES6类继承:使用ES6的class语法,可以更加简洁地实现继承。这种方式会自动处理原型链和构造函数的问题。**
```javascript
class Parent {
constructor() {
this.name = 'parent';
}
sayName() {
console.log(this.name);
}
}
class Child extends Parent {
constructor() {
super();
this.age = 18;
}
}
const child = new Child();
child.sayName(); // 输出 "parent"
14、require和import的区别
require和import都是用于模块导入的关键字,但它们分别属于不同的模块化规范,因此有着明显的区别。
- require是CommonJS的模块引入方式,直到ES6规范出现,浏览器才拥有了自己的模块化方案import/export。
- 语法不同:require的语法是const module = require(‘module’),而import的语法是import
module from ‘module’。 - 动态加载与静态加载:require是动态加载模块的,可以在代码的任何地方使用;相比之下,import是静态加载模块的,因此只能在文件的顶部使用。
- 导出方式不同:require是通过module.exports导出模块的,而import是通过export导出模块的。
- 执行方式的差异:理解import语句是静态执行的和require函数是动态执行的,需要先了解这两个概念的含义。静态执行是指在编译阶段就能够确定其执行结果的代码执行方式,而动态执行则相反。
- 赋值过程和解构过程:require是赋值过程并且是运行时才执行,也就是同步加载;而import是解构过程。
15、实现异步的方法有哪些
- 定时器
- Promise
- 回调函数
- async / await
- $nextTick
- 事件绑定都是异步操作
16、箭头函数和普通函数的区别
- 没有自己的this、super、arguments和new.target绑定
- 不能使用new来调用。
- 没有原型对象。
- 不可以改变this的绑定。
17、async和defer的区别
async和defer都是JavaScript中处理脚本加载和执行的方式,它们的主要区别如下:
执行时机:defer要等到整个页面在内存中正常渲染结束(DOM结构完全生成以及其他脚本执行完成)才会执行。而async一旦下载完渲染引擎就会中断渲染执行这个脚本以后再继续渲染。简而言之,defer确保脚本按照页面解析的顺序执行,而async则允许脚本在下载完成后立即执行,不保证顺序。
18、原型与原型链
当访问一个对象的属性时,如果在对象的内部不存在,就会通过__proto__一直向上去找,直到null。
对象(除了null)中都有__proto__属性,函数是特殊的对象有__proto__和prototype两种属性。
__proto__为隐式原型,指向它的构造函数的原型对象(prototype)。
prototype为显式原型,是函数独有的(能够被当作构造函数使用的函数才有),指向函数的原型对象。它的作用就是让该函数所实例化的对象们,共享属性和方法
PS:
基本数据类型也有__proto__属性,但基本类型的值本质是个密封对象,不能增加、修改、删除属性。
19、脚本延迟加载的方式有哪些
defer属性:给js脚本添加defer 属性,这个属性会让脚本的加载与文档的解析同步解析,然后在文档解析完成后再执行这个脚本文件,这样的话就能使页面的谊染不被阻塞。多个设置了defer属性的脚本按规范来说最后是顺序执行的,但是在一些浏览器中可能不是这样。
async属性:给js脚本添加async 属性,这个属性会使脚本异步加载,不会阻塞页面的解析过程,但是当脚本加载完成后立即执行js脚本, 这个时候如果文档没有解析完成的话同样会阻塞。多个async属 性的脚本的执行顺序是不可预测的,一般不会按照代码的顺序依次执行。
20、贪心算法
贪心算法:是指,在对问题求解时,总是做出在当前看来是最好的选择。也就是说,不从整体最优上加以考虑,算法得到的是在某种意义上的局部最优解。
以下是一个用 JavaScript 实现贪心算法的例子,这是一个找零钱的例子
function greedyAlgorithm(money) {
const coins = [1, 2, 5, 10, 20, 50, 100, 200]; // 假设有这些面值的硬币
coins.sort((a, b) => b - a); // 按照面值从大到小排序
let result = []; // 用于存储找零的结果
for (let i = 0; i < coins.length; i++) {
let count = Math.floor(money / coins[i]); // 取当前面值硬币的最大数量
if (count > 0) {
result.push({ coin: coins[i], count }); // 将当前面值的硬币和数量加入结果数组
money -= count * coins[i]; // 更新剩余需要找零的金额
}
}
return result;
}
console.log(greedyAlgorithm(326)); // 输出:[{ coin: 200, count: 1 }, { coin: 100, count: 1 }, { coin: 20, count: 1 }, { coin: 5, count: 1 }, { coin: 1, count: 1 }]
21、Math
Math.abs(x): 返回 x 的绝对值。
Math.round(x): 返回 x 四舍五入后的最接近的整数。
Math.ceil(x): 返回大于或等于 x 的最小整数。
Math.floor(x): 返回小于或等于 x 的最大整数。
Math.max(…values): 返回给定数值中的最大值。
Math.min(…values): 返回给定数值中的最小值。
22、let const var 的区别
let、const和var都是JavaScript中用于声明变量的关键字,但它们在作用域、声明提升、暂时性死区和重复声明等方面存在一些区别。
- 作用域:
var在函数作用域中声明变量,这意味着在函数内部声明的变量在函数外部是不可见的。但是,如果在函数内部不使用var关键字声明变量,则该变量将成为全局变量。
let和const在块级作用域中声明变量,这意味着在代码块(如if语句、for循环等)内部声明的变量在该代码块外部是不可见的。 - 声明提升:
var声明的变量存在声明提升(hoisting)现象,即变量的声明会被提升到作用域的顶部,但初始化不会提升。这可能导致一些意外的行为。
let和const声明的变量也存在声明提升,但由于暂时性死区(Temporal Dead
Zone)的限制,它们在声明之前不能被访问或使用。 - 暂时性死区(Temporal Dead Zone):
let和const声明的变量存在暂时性死区,这意味着在变量声明之前的代码块中,这些变量是不可访问的。如果在声明之前尝试访问这些变量,将会导致引用错误(ReferenceError)。
var声明的变量在声明之前访问会返回undefined而不是引用错误。 - 重复声明:
使用var关键字可以重复声明同一个变量,后续的声明会覆盖之前的声明。
使用let和const关键字声明的变量不能在相同的作用域内重复声明。如果尝试这样做,将会导致语法错误(SyntaxError)。 - 赋值限制:
使用var和let声明的变量可以被重新赋值。
使用const声明的变量不能被重新赋值。如果尝试这样做,将会导致语法错误(SyntaxError)。但需要注意的是,对于对象或数组等引用类型的常量,虽然不能更改常量的引用,但可以修改其引用的对象或数组的内容。 - 全局作用域的表现:
在全局作用域中,使用var声明的变量会成为全局对象的属性(在浏览器环境中是window对象)。这意味着可以通过全局对象来访问这些变量。
在全局作用域中,使用let和const声明的变量不会成为全局对象的属性。它们仅在全局作用域中可见,但不能通过全局对象来访问。
23、for in和 for of的区别
在JavaScript中,for…in 和 for…of 是两种不同的循环结构,它们有一些关键的区别。
for…in 用于遍历对象的可枚举属性,包括其原型链上的属性。它通常用于对象(object)类型的数据。
例如:
let obj = {a: 1, b: 2, c: 3};
for (let key in obj) {
console.log(`obj.${key} = ${obj[key]}`);
}
这将输出:
obj.a = 1
obj.b = 2
obj.c = 3
for…of 则用于遍历可迭代对象(包括 Array,Map,Set,String,TypedArray,arguments对象等等)。for…of` 循环直接返回的是每一项的值,而不是键或者索引。
例如:
let arr = ['a', 'b', 'c'];
for (let value of arr) {
console.log(value);
}
这将输出:
a
b
c
请注意,对于数组,for…in 返回的是索引,而 for…of 返回的是值。这是两者之间的重要区别。
24、ES6有哪些新特性
- 新增了let const ,他们具有块级作用域,没有变量提升的问题
- 新增了箭头函数,简化了定义函数的写法
- 新增了Promise,解决了回调地狱的问题
- 新增了模块化,利用import\export来实现导入导出,
- 新增了解构赋值,可以很方便的从数组或对象中提取值,对变量进行赋值
- 新增了class类的概念
25、 v-for为什么一定要有key
key是v-for指令的一个特殊属性,它用于给每个节点提供一个唯一的标识符,以便Vue.js可以更高效地更新虚拟DOM。
具体来说,Vue.js使用key来识别节点是否改变、新增或删除。当使用v-for指令循环遍历一个数组或对象时,如果数据项的顺序发生变化,Vue.js会尽量保留原来的节点并更新其内容,而不是重新创建或移动整个节点。在这种情况下,key就能帮助Vue.js识别哪些节点发生了变化,从而只更新需要改变的部分。
另外,使用key还能提高渲染性能。当使用v-for指令时,如果不指定key属性,Vue.js会为每个节点生成一个默认的key值,这个默认值是根据节点的位置确定的。如果数组或对象的长度很大,这种默认的key值可能会导致性能问题。因此,为了避免这种情况,我们应该在v-for指令中使用key属性,并为每个节点提供一个唯一的key值。
所以,使用key属性能帮助我们提高应用程序的性能和可维护性。
26、数组去重的方法
- 使用Set去重 Set是一种特殊的类型,它的特点是只能保存唯一的值,所以我们可以利用这个特性来去重。
let arr = [1,1,1,2,3,4,5,5,6];
let uniqueArr = [...new Set(arr)];
- 使用indexOf去重 indexOf() 方法返回在数组中可以找到给定元素的第一个索引,如果不存在,则返回-1。这个特性可以用来去重。
let arr = [1,1,1,2,3,4,5,5,6];
let uniqueArr = [];
for(let i=0;i<arr.length;i++){
if(uniqueArr.indexOf(arr[i])==-1){
uniqueArr.push(arr[i]);
}
}
- 使用filter去重
filter()方法创建一个新的数组,新数组中的元素是通过检查指定数组中符合条件的所有元素。我们可以利用这个方法来去重。
let arr = [1,1,1,2,3,4,5,5,6];
let uniqueArr = arr.filter((value,index,self) => self.indexOf(value) === index);
27、隐式转换
弱类型转换(也称为隐式类型转换)主要是指在没有明确指定类型的情况下,自动将一种数据类型转换为另一种数据类型。以下是一些常见的弱类型转换规则:
- 字符串化:当一个值被期望为字符串时,如果它不是字符串,那么它将被自动转换为字符串。例如,数字、布尔值和对象都可以通过调用toString()方法进行字符串化。
console.log("Hello " + 123); // 输出 “Hello 123”
console.log("True "+ false); // 输出 “True false”
console.log("My object: " + {name: “John”}); // 输出 “My object: [object Object]” - 数值化:类似地,当一个值被期望为数字时,如果它不是数字,那么它将被自动转换为数字。这包括将字符串转换为数字,以及将布尔值转换为数字(true转换为1,false转换为0)。
console.log(1 + “2”); // 输出 3
console.log(1 + true); // 输出 2 - 布尔化:在JavaScript中,非零和非空(null和undefined除外)值都被视为真(true),而零、空对象、空数组、空字符串、null和undefined都被视为假(false)。
console.log(!!0); // 输出 false
console.log(!!1); // 输出 true
console.log(!!“”); // 输出 false
二、css部分
1、sass和less的区别
2、水平垂直居中的方法
- 利用定位+calc() ,父元素宽高200px,相对定位,子元素宽高100px,绝对定位,top和left设置为calc(50%-50px)
- 利用定位+margin 父元素宽高200px,相对定位,子元素宽高100px,绝对定位,top和left设置为50%,margin-top和margin-left 设置为50px
3、BFC
块级格式化上下文,这是一个独立的渲染区域,规定了内部如何布局、并且这个区域的子元素不会影响到外面的元素。多用于清除浮动,解决高度塌陷、父子margin重叠等问题。
触发BFC:
- float属性不是none
- position为absolute或者fixed
- display为inline-block, table-cell, table-caption, flex, inline-flex
- overflow除visible以外的值(hidden、auto、scroll)
- 高度塌陷: 父元素不写高度时,子元素写了浮动后,父元素会发生高度塌陷
4、清除浮动
1 给父元素设置高度
2 给父元素设置 overflow:hidden/auto
3 给被浮动影响的元素设置clear:both
4 给父元素设置伪类
.box::after :{
display: block;
content:“”;
clear:both
}
//清除浮动
.clearfix:after{
content:""; /*内容为空*/
height:0; /*高度为0*/
line-height:0; /*行高为0*/
display:block; /*块级元素*/
visibility:hidden; /*隐藏*/
clear:both; /*清除浮动*/
}
.clearfix{
zoom:1; /*兼容IE678*/
}
5、用css画一个三角形
div {
width: 0;
height: 0;
border-width: 10px;
border-style: solid;
border-color: transparent #0099CC transparent transparent;
transform: rotate(90deg); /*顺时针旋转90°*/
}
三、HTML部分
1、虚拟DOM的解析过程
虚拟DOM (Virtual DOM)解析过程- -般包括以下步骤:
1.构建初始的虚拟DOM树:在组件渲染过程中,会创建一个初始的虚拟DOM树,以描述当前组件的状态和结构。
2.生成新的虚拟DOM树:随着组件状态的改变,会触发数据更新,从而生成一个新的虚拟DOM树,表示更新后的组件状态和结构。
3.比较新旧虚拟DOM树:通过比较新、旧虚拟DOM树的差异,找出需要进行更新的部分。
4.生成更新补丁(patch) :根据差异的比较结果,生成一系列的更新补丁,用于描述需要对真实DOM进行的操作,如添加、删除、修改节点等。
5.应用更新补丁:将生成的更新补丁应用到真实DOM 上,进行实际的DOM操作,以达到将真实DOM更新为新的组件状态和结构的目的。
通过使用虚拟DOM,可以避免直接对真实DOM进行频繁的操作,而是对抽象的虚拟DOM进行操作,减少了对浏览器的负担,提升了性能。同时,虚拟DOM的比较和更新过程也是高度优化的,只对需要进行更新的部分进行操作,减少了不必要的DOM操作,提高了渲染效率。
四、Vue部分
1、computed和watch的区别
- computed是计算属性,watch是监听,监听的是data中数据的变化
- computed是支持缓存的,当依赖的属性值发生变化,计算属性会重新计算,否则用缓存,watch不支持缓存
- computed不支持异步,watch可以异步操作
- computed是第一次加载就监听,watch是不监听
- computed函数中必需有return,watch没有
2、vuex刷新页面数据会导致数据丢失吗?怎么解决?
刷新页面会导致vuex重新获取数据,页面也会丢失数据,解决办法:
- 把数据直接保存到浏览器里(cookie localstorage sessionstorage)
- 页面刷新的时,再次请求数据,达到可以动态更新的方法
监听浏览器刷新事件,在页面刷新之前,把数据存储到sessionstorage里,页面刷新之后,去异步请求sessionstorage里的数据,如果有返回,就把请求到的数据存到vuex里,没有返回,就去拿vuex里的数据
3、什么是MVVM模型
- M (Model,模型),data中的数据
- V (View,视图),模板代码
- VM (ViewModel,模板视图)
MVVM是Model-View-ViewModel的缩写。MVVM是一种设计思想。Model 层代表数据模型,也可以在Model中定义数据修改和操作的业务逻辑;View 代表UI 组件,它负责将数据模型转化成UI 展现出来,ViewModel 是一个同步View 和 Model的对象。
在MVVM架构下,View 和 Model 之间并没有直接的联系,而是通过ViewModel进行交互,Model 和 ViewModel 之间的交互是双向的, 因此View 数据的变化会同步到Model中,而Model 数据的变化也会立即反应到View 上。
ViewModel 通过双向数据绑定把 View 层和 Model 层连接了起来,而View 和 Model 之间的同步工作完全是自动的,无需人为干涉,因此作为开发者只需关注业务逻辑,不需要手动操作DOM, 不需要关注数据状态的同步问题,复杂的数据状态维护完全由 MVVM 来统一管理。
4、为什么组件中的data是一个函数
目的是为了防止多个组件实例对象间共用一个data,产生数据污染,采用函数的形式,initData时会将其作为工厂函数返回一个全新的data对象
5、vue中有哪些命令 介绍一下
- v-once:只在初始化渲染时后读取,后续模板插槽里的值不再发生变化
- v-html:向指定节点中渲染包含html结构的内容,html有安全性问题,容易导致xss攻击,所以一定要在可信内容上使用v-html
- v-cloak是一个特殊属性,vue实例创建完毕后会删除该指令,使用css配合该指令,可以解决用户网络慢时,页面出现{{xxx}}的问题
- v-pre
6、自定义指令介绍一下+
在每个 vue 组件中,可以在 directives 节点下声明私有自定义指令
该节点下,定义一个指定名,将来使用的时候用v-xxx,接收两个参数,第一个是dom对象,第二个是可以获取的属性,比如value,想修改值的时候,用el.innerHtml = binding.value*10
directives:{
color:{
bind(el,binding){
// 形参中的 el 表示当前指令所绑定的 DOM 对象
el.style.color = binding.value
}
}
}
七、Vue生命周期 2.0 => 3.0
beforeCreate => setup() 开始监控Data对象数据变化、开始初始化事件
created => setup() 实例已经创建完成,完成了data 数据的初始化,el没有,可以初始化data数据
beforeMount => onBeforeMount 开始执行挂载钩子,编译模板,把data里面的数据和template生成html,完成了el和data 初始化,生成了虚拟dom,并转换为真实Dom,但还没有更新到页面上。
mounted => onMounted 挂载完成,template渲染到了html,一般可以做一些ajax操作
beforeUpdate => onBeforeUpdate 实时监控数据变化
updated => onUpdated 随时更新DOM
beforeDestroy => onBeforeUnmount
destroyed => onUnmounted
errorCaptured => onErrorCaptured
renderTracked => onRenderTracked
renderTriggered => onRenderTriggered
activated => onActivated
deactivated => onDeactivated
————————————————
版权声明:本文为CSDN博主「1234Wu」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_42866164/article/details/122766256
五、Jquery部分
1、什么是jquery

六、浏览器
1、CSRF(跨站请求伪造)
网站攻击的一种。跨站的意思就是,b网站向a网站的服务去发起请求,并且发起请求的时候还会携带a网站的cookie
防御CSRF攻击主要有三种策略:验证HTTP Referer字段;在本地请求中添加token并验证;在HTTP头中自定义属性并验证
2、HTTP协议(超文本传输协议)、HTTPS(加密HTTP协议)
对浏览器和服务器做出的约束
3、进程、线程
进程是程序的一次执行过程
线程是一个进程中执行的一个执行流,一个线程是属于某个进程的
一个进程至少包含一个线程
4、网页资源的加载步骤?
网页资源加载的过程可以大致分为以下几个步骤:
- 用户在浏览器中输入URL或点击链接。
- 浏览器向DNS服务器请求解析该URL对应的IP地址。
- DNS服务器返回IP地址,浏览器与该IP地址的服务器建立TCP连接。
- 浏览器向服务器发送HTTP请求,请求获取该URL对应的网页资源。
- 服务器接收到请求后,处理并准备响应数据。
- 服务器将响应数据(HTML、CSS、JavaScript、图片等)传输给浏览器。
- 浏览器接收到响应数据后,开始解析HTML,并加载CSS、JavaScript、图片等资源。
- 浏览器根据HTML和CSS构建DOM树和渲染树,然后执行JavaScript代码。
- 浏览器根据渲染树开始渲染页面,将页面内容呈现在屏幕上。
5、token是什么
token是服务端生成并返回给HTTP客户端的一串加密字符串,token中保存着用户信息
token的作用?
实现会话控制,可以识别用户的身份,主要用于移动端APP
token的工作流程
填写账号和密码检验身份,校验通过后响应token,token一般是在响应体中返回给客户端的
后续发送请求时,需要手动将token添加在请求报文中,一般是放在请求头中
token的特点
服务端压力更小,数据存储在客户端
相对更安全,数据加密,可以避免CSRF
扩展性更强,服务间可以共享,增加服务节点更简单
6、JWT (JSON Web Token)
是目前最流行的跨域认证解决方案,可用于基于token的身份验证
JWT使token的生产与校验更规范
我们可以使用jsonwebtoken包来操作token
const jwt = require(‘jsonwebtoken’)
// 创建token
// jwt.sijn(数据、加密字符串,配置对象)
let token =jwt.sign({
username:‘zhangsan’},‘atguigu’,{
expiresIn:60 // 单位是秒})
// 解析token
jwt.verify(token,‘atguigu’,(err,data)=>{
if(err){
console.log(‘检验失败’)
return
}
console.log(data)
})
7、三次握手、四次挥手
三次握手的过程如下:
第一次握手:建立连接时,客户端发送syn包(syn=j)到服务器确认能否建立连接,并进入SYN_SEND状态,等待服务器确认。
第二次握手:服务器收到syn包,必须确认客户的SYN(ack=j+1),同时自己也发送一个SYN包(syn=k),即SYN+ACK包,此时服务器进入SYN_RECV状态。
第三次握手:客户端收到服务器的SYN+ACK包,向服务器发送确认包ACK(ack=k+1),此包发送完毕,客户端和服务器进入ESTABLISHED状态,完成三次握手。
四次挥手的过程如下:
数据传输完毕后,一方(通常是客户端)首先发出断开连接的请求,发送一个FIN报文(请求断开连接报文),并进入FIN_WAIT_1状态。
另一方(通常是服务器)收到FIN报文后,发送一个ACK报文(确认报文),表示同意断开请求,同时进入CLOSE_WAIT状态。此时,第一次挥手完成。
然后,服务器发送一个FIN报文(请求断开连接报文),并进入LAST_ACK状态。这是第二次挥手。
客户端收到这个FIN报文后,发送一个ACK报文(确认报文),并进入TIME_WAIT状态。这是第三次挥手。稍等一段时间后,客户端进入CLOSED状态。这是第四次挥手。至此,双方完成断开连接。
8、TCP、UDP协议
应用层
传输层
网络层
数据链路层
物理层
TCP、UDP都工作在传输层,目标都是在程序之间传输数据
TCP 稳定可靠,如邮件
UDP 速度快,对少量丢包场景没有什么要求可以适用,如视频通话
七、Vuex
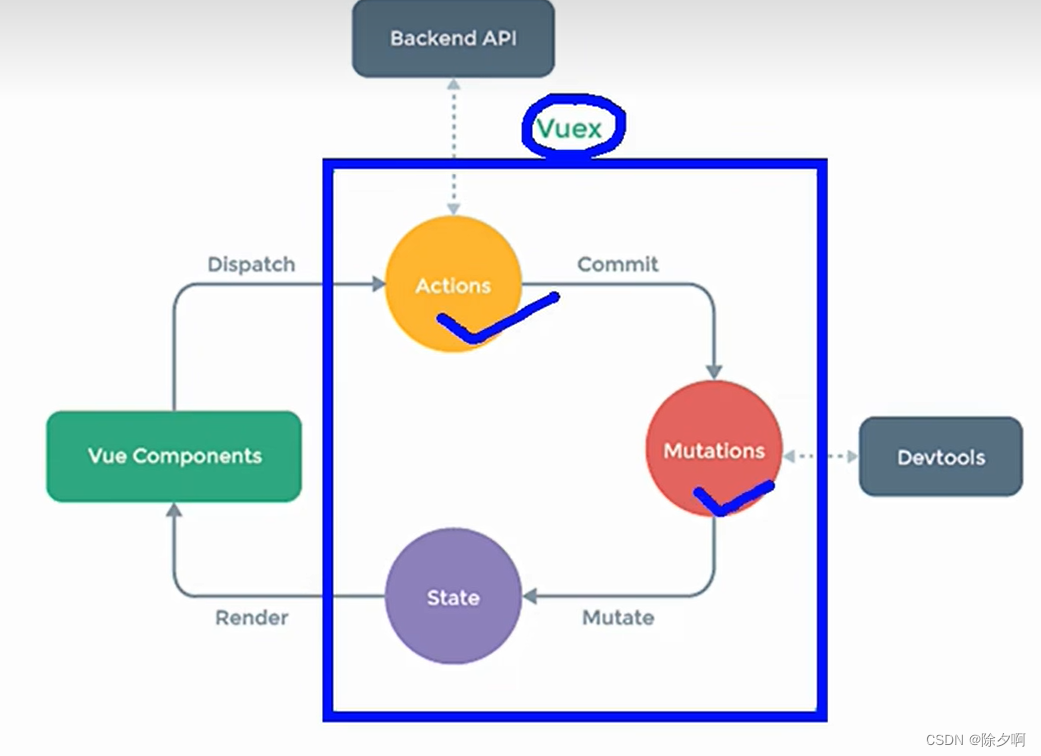
八、vue-router
通过注入路由器,我们可以在任何组件内通过 this.$router 访问路由器,也可以通过 this.$route 访问当前路由
注意点:不用的组件,切换切走的路由组件是被销毁了














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









