






RocketMq基础使用
- 1个Topic默认有4个queue, 有queue的概念可以提升消费的并发度
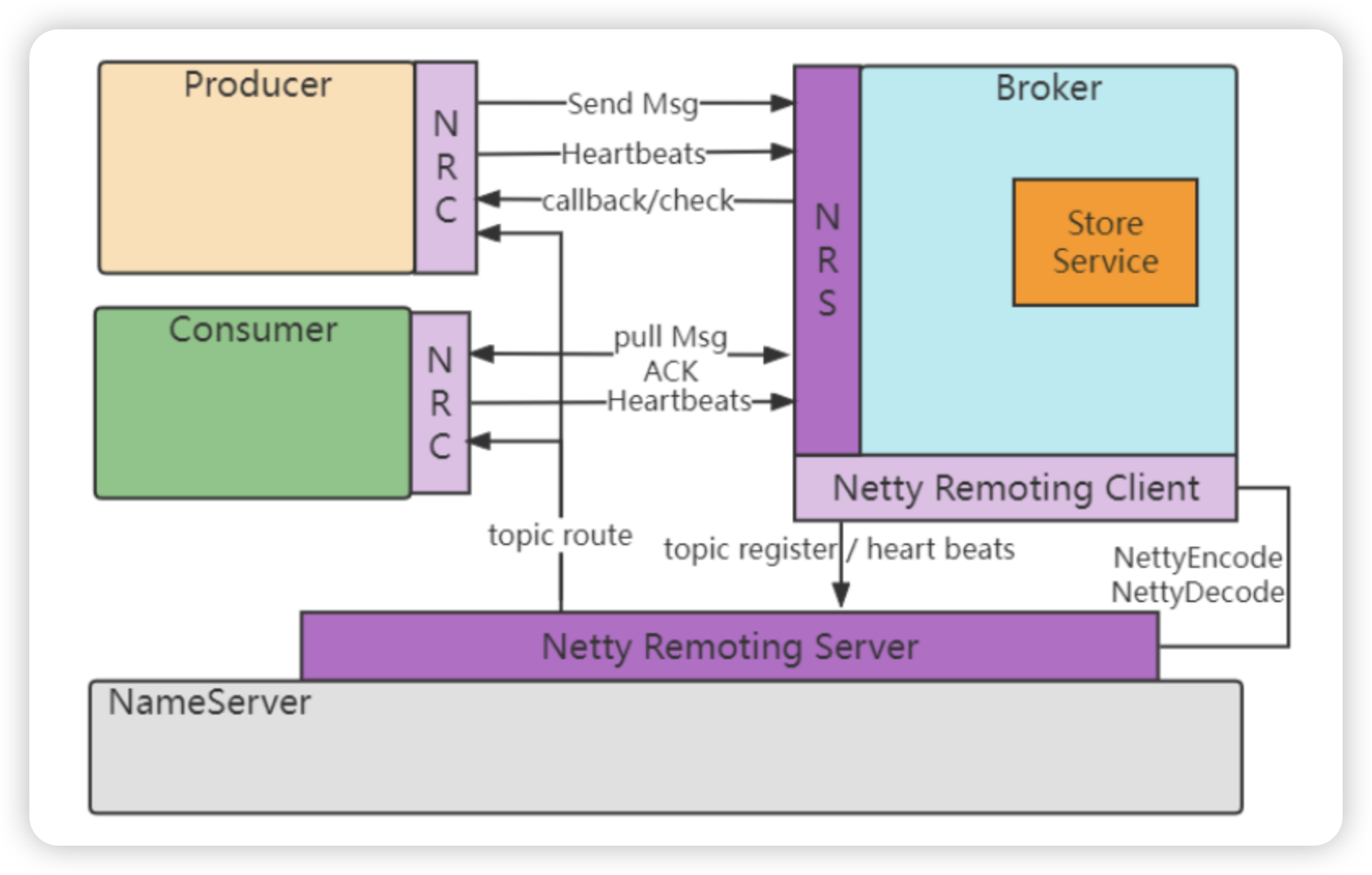
- Producer 和Broker之间有长连接
- broker 的端口10911 , nameServer的端口9876
- SendStatus : 发送成功, 刷盘超时, 主从同步超时, 从节点不存在
- 默认用的是 DefaultMQPushConsumer 推模式
- 推模式,对Mq注册一个监听
- 拉模式,不停的循环拉取数据
- 消息消费的节点:
- CONSUME_FROM_LAST_OFFSET: 表示从上次消费的偏移量(offset)开始消费。这意味着消费者将从上次停止消费的地方继续消费消息。
- CONSUME_FROM_FIRST_OFFSET:表示从第一条消息的偏移量开始消费。这与
CONSUME_FROM_MIN_OFFSET类似,但可能在一些上下文中具有更明确的含义。 - CONSUME_FROM_TIMESTAMP:表示从指定的时间戳开始消费。消费者将从给定时间戳之后的第一条消息开始消费。这允许消费者从特定的时间点开始处理消息,这对于处理历史数据或进行特定的数据回溯非常有用。
- 5版本支持了定时消息,设定延时任意时间
- 顺序消息异常返回, SUSPEND_CURRENT_QUEUE_A_MOMENT ,等待一会再消费,可以指定等待的时间setSuspendCurrentQueueTimeMillis
- 顺序消息可以设置重试的次数,重试到一定次数后可以指定相应的处理逻辑,然后让消息往下执行
- 所有存储性的内容都在broker,nameServer不存储内容
- 批量消息,批量发送(相同的主题,不能超过4M,批量消息会发送到一个queue中),和批量消费(提高消费者处理能力)
- enablePropertyFilter = true broker打开开关,允许消费者利用sql进行过滤
- msg.putUserProperty(“a”, String.valueOf(i) 设置sql过滤的属性,消息过滤被过滤掉的消息也会提交offset
- RocketMQ要求同一个消费组内的所有消费者实例必须订阅相同的Topic和Tag,以确保消息能够均匀分配且不被遗漏。
- 在Push消费模式下,RocketMQ会主动将消息推送给消费者。如果消费者在处理消息时失败(例如抛出异常或返回
RECONSUME_LATER状态),RocketMQ会根据配置的重试策略重新投递消息。消费者重启后,如果它仍然订阅了相同的Topic和Tag,并且该消息尚未达到最大重试次数,那么RocketMQ会在适当的时候(根据重试间隔和重试策略)将消息重新推送给消费者。
SendResult sendResult = producer.send(msg, new MessageQueueSelector() {
@Override
public MessageQueue select(List<MessageQueue> mqs, Message msg, Object arg) {
Long id = (Long) arg;
long index = id % mqs.size();
// 根据订单id选择发送queue
return mqs.get((int) index);
}
}, orderList.get(i).getOrderId())
分布式事务和解决方案
分布式事务
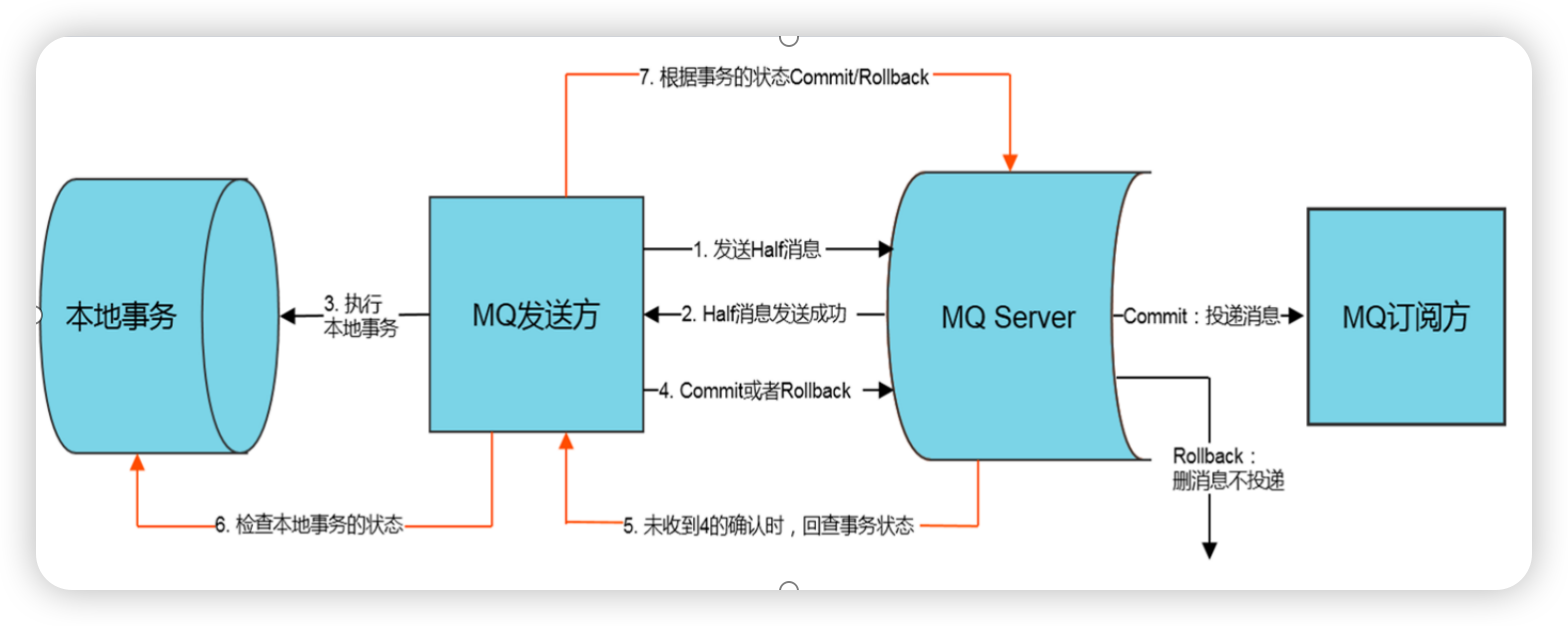
- 不是强一致性的
- TransactionMQProducer producer ==> producer.sendMessageInTransaction 发送半事务消息
- setTransactionListener 设置事务监听器
- TransactionListener # executeLocalTransaction
- 执行本地事务 (执行本地事务,操作成功,数据就已经持久化到数据库中, 无论是在同一个事务监听器的(checkLocalTransaction)方法中,还是在其他任何能够访问该数据库的地方,都可以查询到这些数据)
- 执行本地事务时,可以将事务ID和业务数据ID组合为一张表的数据,落库
- TransactionListener # checkLocalTransaction 校验本地事务
- 根据事务ID查询数据库中是否有数据
- 消费者如果消费失败数据,消费时间超过一定次数时,发送消息到补偿队列(生产者也可以监控死信队列)
- 生产者监听补偿队列,做executeLocalTransaction 的回滚
- 生产者分组针对事务消息,如果发送事务消息的生产者执行完executeLocalTransaction, 返回UNKNOW后宕机了,MQ回查会查找相同生产者分组下的别的机器
消息的重复
- 去重表方案: 如果插入数据抛出异常,直接确认消息
- 很久之前的数据可以删掉
- 通过状态更新数据,防止重复
- consumer是多线程去跑的,注意数据的安全性
- 一个消费者挂掉,会把broker的queue交给别的消费者消费
- 通常消费者的数据大于消费队列的数量,提高并发度
NameServer源码
- 核心: 消息的发布订阅和消息的存储
- NameServer Producer Consumer Broker Stroe NRC/NRS(Netty)
- 服务的注册于发现, broker 路由的剔除
- NamesrvStartup # main 启动方法
- main0(args) NamesrvController的初始化与启动
- parseCommandlineAndConfigFile(args) 解析命令行参数与配置文件
- namesrvConfig nettyServerConfig nettyClientConfig
- createAndStartNamesrvController() NamesrvController的初始化与启动
- new NamesrvController
- start(controller)
- controller.initialize()
- loadConfig();//加载配置
- initiateNetworkComponents();//初始化网络组件
- new NettyRemotingClient
- new NettyRemotingServer
- initiateThreadExecutors();//初始化网络调用线程池
- registerProcessor();//注册处理器(对外提供服务)
- this.remotingServer.registerDefaultProcessor(new DefaultRequestProcessor 注册处理器
- startScheduleService();//启动定时任务处理器 (检测broker的状态的定时任务)
- scanNotActiveBroker
- initiateSslContext();//初始化SSL上下文
- initiateRpcHooks();//初始化RPC钩子
- registerRPCHook 让服务优雅的关闭
- controller.start()
- this.remotingServer.start() Netty的服务的启动(监听9876端口, 启动Netty相关的线程)
- this.defaultEventExecutorGroup = new DefaultEventExecutorGroup
- prepareSharableHandlers() 通用的handler的初始化
- serverBootstrap.group
- this.remotingClient.start() Netty客户端启动
- this.routeInfoManager.start() 这个是NameServer最核心部分的启动
- this.unRegisterService.start()
- this.remotingServer.start() Netty的服务的启动(监听9876端口, 启动Netty相关的线程)
- parseCommandlineAndConfigFile(args) 解析命令行参数与配置文件
- controllerManagerMain() ControllerManager的初始化与启动
- createControllerManager
- start(controllerManager)
- controllerManager.initialize() 初始化Manager
- registerProcessor() 注册服务
- RouteInfoManager 路由信息的管理
- NamesrvController # RouteInfoManager
- Map<String/* topic */, Map<String, QueueData>> topicQueueTable;//主题队列信息
- 内层map key为queueId , value为 Queue的信息
- Map<String/* brokerName */, BrokerData> brokerAddrTable;//broker信息
- Map<String/* clusterName /, Set<String/ brokerName */>> clusterAddrTable;//集群信息
- Map<BrokerAddrInfo/* brokerAddr */, BrokerLiveInfo> brokerLiveTable;//broker存活信息
- Map<BrokerAddrInfo/* brokerAddr /, List/ Filter Server */> filterServerTable;//过滤服务器信息
- Map<String/* topic */, Map<String/brokerName/, TopicQueueMappingInfo>> topicQueueMappingInfoTable;//broker和主题队列映射信息
- BatchUnregistrationService unRegisterService;//批量取消注册Broker的线程
- 以下是对你提到的各个缓存/表结构的解释:
- topicQueueTable: Map<String/* topic */, Map<String, QueueData>> topicQueueTable 一个主题多个队列
- 用途: 存储每个主题(
topic)对应的队列信息。 - 内层Map:
key为queueId(队列ID),value为QueueData(队列的数据信息,可能包括队列的状态、位置等) - QueueData(队列的数据信息):
queueId: 队列的唯一标识符。brokerName: 该队列所属的broker的名称。topic: 该队列所属的主题。status: 队列的当前状态,如活跃、非活跃等。offset: 队列中消息的偏移量,用于定位消息。其他字段: 可能还包括队列的创建时间、最后更新时间等
- 用途: 存储每个主题(
- brokerAddrTable: Map<String/* brokerName */, BrokerData> brokerAddrTable;
- 用途: 存储每个
brokerName对应的BrokerData。 - 说明:
BrokerData可能包含broker的地址、端口、状态等信息。 - BrokerData(broker的数据信息):
brokerName: broker的唯一名称。brokerAddr: broker的地址信息,包括IP和端口号。status: broker的当前状态,如活跃、非活跃等。其他字段: 可能还包括broker的版本、启动时间等。
- 用途: 存储每个
- clusterAddrTable:
- Map<String/* clusterName /, Set<String/ brokerName */>> clusterAddrTable;
- 用途: 存储每个集群名称(
clusterName)对应的broker名称集合。 - 说明: 用来快速查找某个集群包含哪些broker。
- brokerLiveTable:
- Map<BrokerAddrInfo/* brokerAddr */, BrokerLiveInfo> brokerLiveTable
- 用途: 存储broker的存活信息。
- key:
BrokerAddrInfo(broker的地址信息)。 - value:
BrokerLiveInfo(broker的存活状态信息,可能包括最后更新时间等)。 - BrokerLiveInfo(broker的存活状态信息):
lastUpdateTime: 最后一次更新broker存活状态的时间。- heartbeatTimeoutMillis: 这里是 超时的阈值(如果超过这个时间,就认为这个broker不可用了) 默认是1秒钟
dataVersion: broker存活状态信息的版本号,用于确保数据的一致性。channel: 与broker通信的通道信息。其他字段: 可能还包括broker的负载情况、健康状况等。
- filterServerTable:
- Map<BrokerAddrInfo/* brokerAddr /, List/ Filter Server */> filterServerTable
- 用途: 存储过滤服务器的信息。
- key:
BrokerAddrInfo(broker的地址信息)。 - value:
List<String>(过滤服务器的列表)。
- topicQueueMappingInfoTable: topic和broker的信息的映射
- Map<String/* topic */, Map<String/brokerName/, TopicQueueMappingInfo>> topicQueueMappingInfoTable 一个topic可以放在多个broker上,brokerName为key (也可以提高生产的并发度)
- 用途: 存储主题和broker之间的队列映射信息。
- 内层Map:
key为brokerName,value为TopicQueueMappingInfo(包含主题和队列在特定broker上的映射信息)。 - TopicQueueMappingInfo(主题和队列在特定broker上的映射信息):
topic: 主题的名称。- totalQueues 总共的queue的数量
- currIdMap: 该主题在特定broker上的队列ID列表。 ConcurrentMap<Integer/logicId/, Integer/physicalId/> currIdMap
brokerName: 特定broker的名称。其他字段: 可能还包括映射关系的创建时间、最后更新时间等。
- unRegisterService:
- 用途: 负责批量取消注册Broker的线程服务。
- 说明: 当broker不再提供服务时,这个服务负责处理相关的取消注册逻辑,确保系统状态的正确性。
- topicQueueTable: Map<String/* topic */, Map<String, QueueData>> topicQueueTable 一个主题多个队列
- RouteInfoManager中的关键方法
- registerBroker 注册Broker broker启动向NameServer注册信息 send Message topic不存在 创建新的topic
- this.lock.writeLock().lockInterruptibly() 利用写锁来确保同一时间只有一个线程可以执行
- ConcurrentHashMap 为什么还要加锁: 因为ConcurrentHashMap 它不是强一致性,最终一致性, 同一时刻添加进去的可能读取不到数据
- getAllClusterInfo 查询Broker 返回集群和主机 生产者发送消息,先查broker
- registerTopic 注册Topic
- getAllTopicList 查询topic
- registerBroker 注册Broker broker启动向NameServer注册信息 send Message topic不存在 创建新的topic
- DefaultRequestProcessor 默认请求处理器 只要是NameServer 接收到了请求,就会进入这个方法processRequest
- ChannelHandlerContext ctx channel的上下文信息
- RemotingCommand request 请求的数据信息
- private int code; //请求类型
- 发送心跳
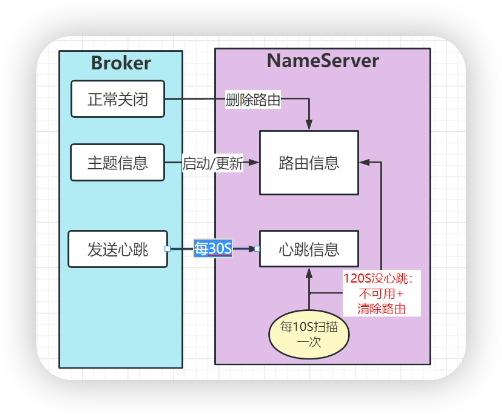
- scheduleSendHeartbeat broker 启动向NameServer定时发送心跳,每隔1s发送一次心跳
- broker端
- BrokerController.this.sendHeartbeat() 发送心跳
- this.brokerOuterAPI.sendHeartbeatToController
- RemotingCommand.createRequestCommand(RequestCode.BROKER_HEARTBEAT,…) 组装心跳的请求参数
- BrokerOuterAPI.this.remotingClient.invokeOneway 发送请求
- NameServer端
- RequestCode.BROKER_HEARTBEAT: 处理 Broker 的心跳请求
- this.brokerHeartbeat(ctx, request)
- this.namesrvController.getRouteInfoManager().updateBrokerInfoUpdateTimestamp
- prev.setLastUpdateTimestamp(System.currentTimeMillis()); 每个addrinfo中的最后修改时间戳改成当前时间戳
- broker端
- NameServer定时任务剔除broker (每隔5s)
- NameServerController # startScheduleService NameServer也会启动定时任务(把超时的broker剔除出去)
- this.scanExecutorService.scheduleAtFixedRate
- this.routeInfoManager::scanNotActiveBroker
- long last = next.getValue().getLastUpdateTimestamp(); 最近的一次时间戳
- long timeoutMillis = next.getValue().getHeartbeatTimeoutMillis(); 这里是 超时的阈值(如果超过这个时间,就认为这个broker不可用了) 这个值可以由broker注册的时候执行,如果没有指定则是1000 * 60 * 2 2分钟
- if ((last + timeoutMillis) < System.currentTimeMillis()) { 判断超时
- RemotingHelper.closeChannel(next.getValue().getChannel()); 关闭Channel
- this.onChannelDestroy(next.getKey()) 关闭channel后执行的方法
- setupUnRegisterRequest(unRegisterRequest, brokerAddrInfo) 设置需要取消的broker信息
- this.submitUnRegisterBrokerRequest(unRegisterRequest)
- unregistrationQueue.offer(unRegisterRequest) 添加到取消注册的队列中
- BatchUnregistrationService # run 实际从缓存map中移除注册信息
- unregistrationQueue.drainTo(unregistrationRequests) 从取消队列中取数据
- this.routeInfoManager.unRegisterBroker(unregistrationRequests) 从缓存map中移除数据
- this.brokerLiveTable.remove(brokerAddrInfo) 移除数据
- 总结
- 方法的处理都是在这个RoutelnfoManager 核心类提供的。对外组件的调用都是在DefaultRequestProcessor类中处理。通过reques中的code来区分不用的请求类型
Remoting源码
- RemotingServerTest # testInvokeSync
- createRemotingServer 创建服务端
- 流程 : 构造方法 --> 注册processor --> 调用start方法
- new NettyRemotingServer(config) 服务端的构造
- new ServerBootstrap() Netty服务启动的核心类
- publicExecutor = buildPublicExecutor(nettyServerConfig); 构建线程池,指定了线程的名字
- this.scheduledExecutorService = buildScheduleExecutor() 构建定时任务
- buildBossEventLoopGroup Netty服务器的boss线程
- buildEventLoopGroupSelector Netty服务器的worker线程
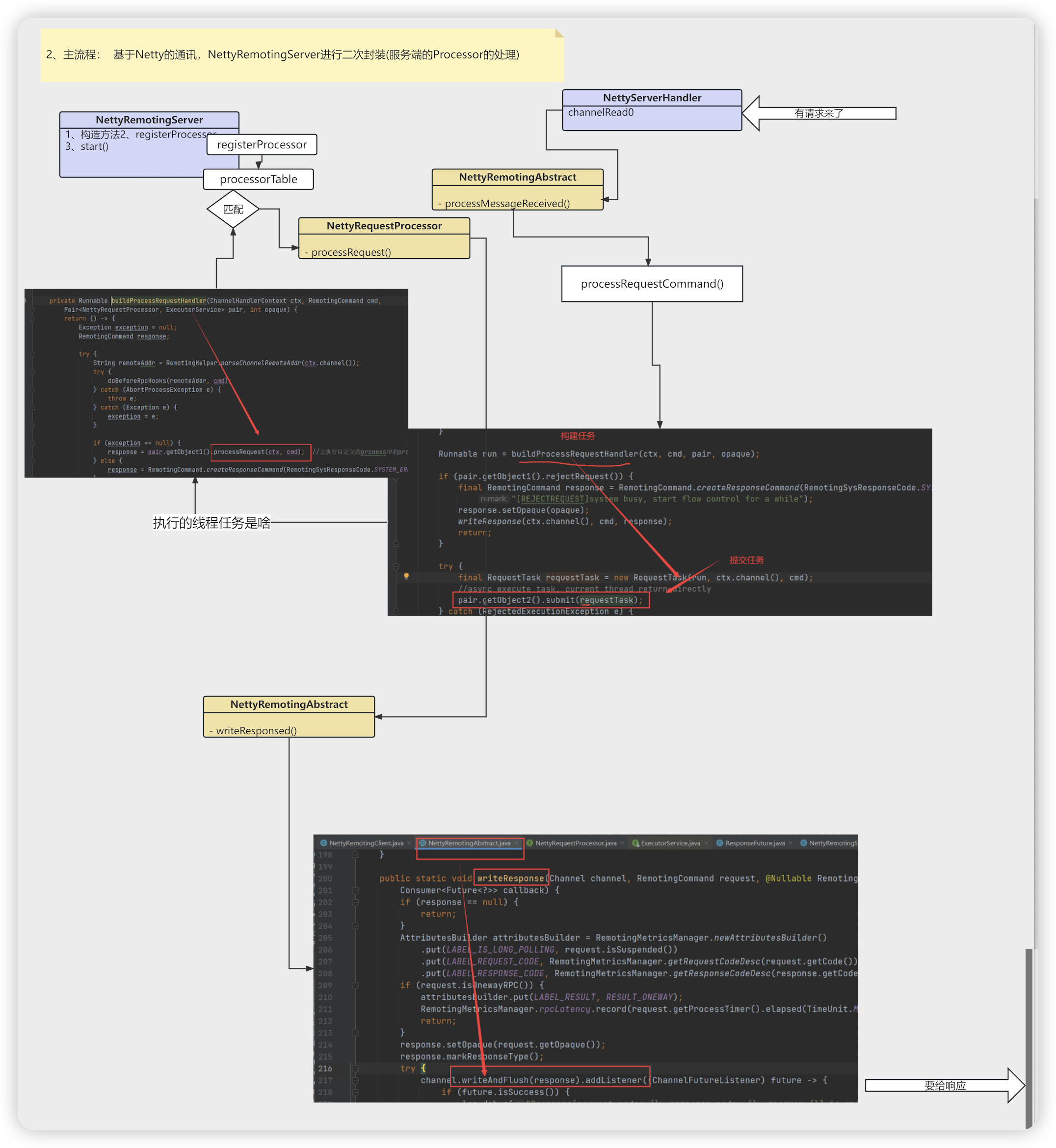
- remotingServer.registerProcessor 注册处理器
- executorThis = this.publicExecutor; 处理器的线程池
- new Pair<>(processor, executorThis) 将线程池和处理器绑定
- this.processorTable.put(requestCode, pair)
- HashMap<Integer/* request code */, Pair<NettyRequestProcessor, ExecutorService>> processorTable 请求处理器缓存map
- new NettyRequestProcessor() 注册请求处理器,里边维护着(RemotingCommand 请求参数)
- RemotingCommand 请求命令
- CommandCustomHeader customHeader 消息头
- byte[] body 消息体
- HashMap<String, String> extFields 额外的字段
- RemotingCommand.createResponseCommand 创建响应
- remotingServer.start() remotingServer启动
- prepareSharableHandlers() 通用的handler的初始化
- configChannel(ch) 配置自定义的处理器 (encoder 编码器 , NettyDecoder 解码器, distributionHandler 统计请求数, IdleStateHandler 超时处理, serverHandler 具体处理业务的逻辑)
- NettyEncoder # encode 编码器: 将对象转为ByteBuf
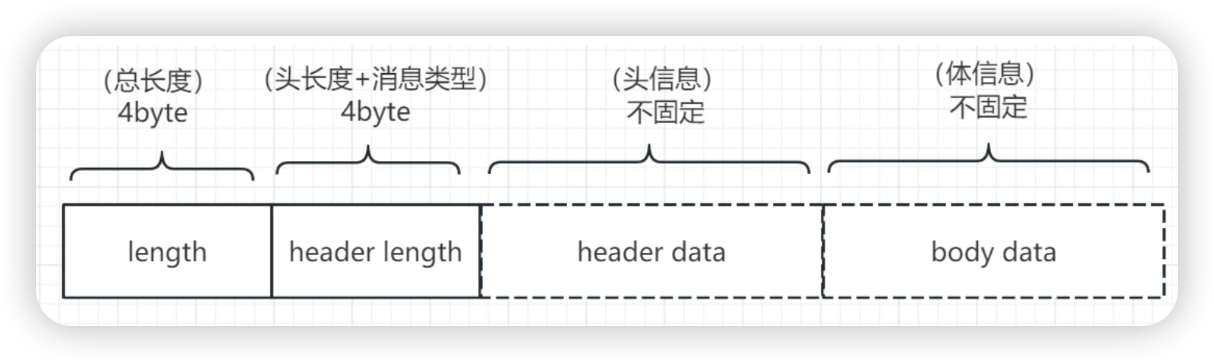
- remotingCommand.fastEncodeHeader(out); 写头
- int beginIndex = out.writerIndex(); 新分配的缓冲区的writerIndex的默认值为0
- out.writeLong(0); 头占8个字节
- out.setInt(beginIndex, 4 + headerSize + bodySize); 最开头8 bytes,前4个byte记录整个长度
- out.setInt(beginIndex + 4, markProtocolType(headerSize, serializeTypeCurrentRPC)) 最开头8 bytes,后4个byte记录header的长度+消息类型
- (type.getCode() << 24) | (source & 0x00FFFFFF) 高24位保存消息的类型,低8位保存头的大小
- out.writeBytes(body); 写体
- NettyDecoder 解码器: 将ByteBuf转为对象
- LengthFieldBasedFrameDecoder 继承基于消息头和消息体的解码器
- decode
- frame = (ByteBuf) super.decode(ctx, in); 把数据拆分成一帧、一帧
- RemotingCommand cmd = RemotingCommand.decode(frame) 将ByteBuf转为RemotingCommand
- RemotingCommand cmd = headerDecode 解析头构建RemotingCommand
- cmd.body = bodyData 设置消息体
- RemotingCodeDistributionHandler 入栈和出栈的计数
- IdleStateHandler 如果读写空闲超过120s(默认)则会触发一个IdleStateEvent事件(超时事件)
- NettyServerHandler 具体的业务处理器
- channelRead0 服务端 中,客户端有请求过来了 触发到这个方法
- NettyRemotingServer.this.remotingServerTable.get(localPort) 从remotingServerTable 中根据code获取处理器抽象类
- remotingAbstract.processMessageReceived(ctx, msg) 处理请求
- case REQUEST_COMMAND: 请求处理
- processRequestCommand(ctx, msg);
- this.processorTable.get(cmd.getCode()) 从服务端注册processor保存的map获取对应的请求处理器
- Runnable run = buildProcessRequestHandler(ctx, cmd, pair, opaque); 构建成runable对象
- RequestTask requestTask = new RequestTask(run, ctx.channel(), cmd) 将runable封装为请求任务
- pair.getObject2().submit(requestTask) pair.getObject2() 获取到线程池对象,提交任务
- 提交任务执行buildProcessRequestHandler 中返回的run方法
- response = pair.getObject1().processRequest(ctx, cmd) 去执行自定义的prcoess中的processRequest的方法
- writeResponse(ctx.channel(), cmd, response) 写响应
- channel.writeAndFlush(response) 将响应写到channel
- case RESPONSE_COMMAND: 响应处理
- processResponseCommand(ctx, msg);
- case REQUEST_COMMAND: 请求处理
- channelRead0 服务端 中,客户端有请求过来了 触发到这个方法
- NettyEncoder # encode 编码器: 将对象转为ByteBuf
- serverBootstrap.bind().sync() 绑定端口号
- createRemotingClient 创建客户端
- 构造 —> start
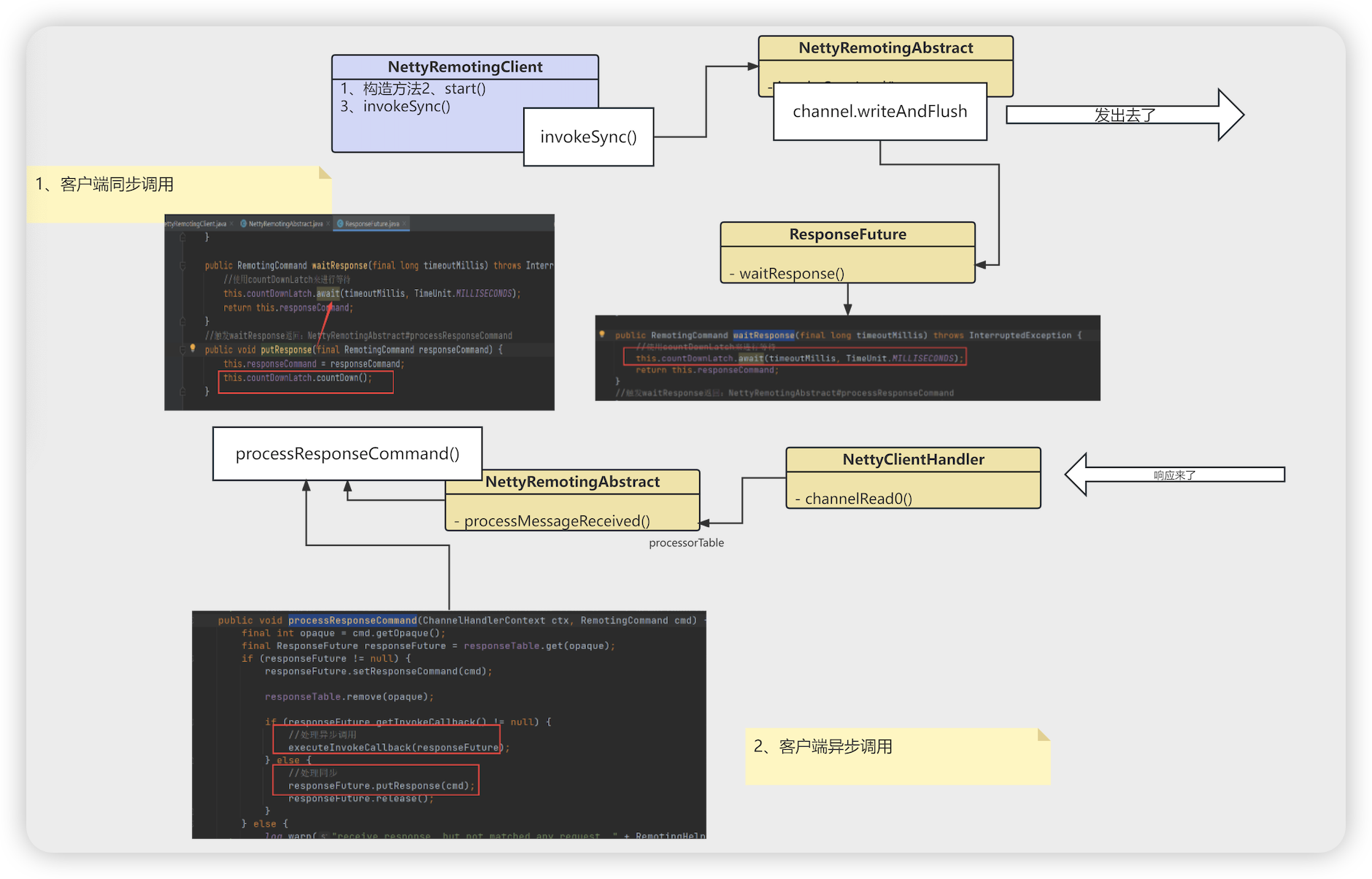
- new NettyRemotingClient # 构造 # invokeSync () 发送请求
- NettyRemotingClient # start 启动方法
- NettyClientHandler Netty客户端处理器
- channelRead0 获取到服务端的响应
- processMessageReceived 处理消息接受到
- processResponseCommand 处理响应
- executeInvokeCallback(responseFuture); 处理异步
- responseFuture.executeInvokeCallback() 执行回调
- invokeCallback.operationComplete(this) 真正执行回调方法的地方
- responseFuture.putResponse(cmd) 处理同步
- this.countDownLatch.countDown() 处理响应的时候将countDownLatch 减一
- NettyRemotingClient # invokeSync 使用remotingClient发起同步调用
- Channel channel = this.getAndCreateChannel(addr) 这里创建的连接
- if (timeoutMillis < costTime) { 超时处理
- this.invokeSyncImpl(channel …) 调用服务端的方法
- new ResponseFuture 这里因为是异步调用,构建异步响应
- channel.writeAndFlush(request) 写出请求数据到channel,发送请求
- RemotingCommand responseCommand = responseFuture.waitResponse(timeoutMillis); 等待响应 (Netty中请求都是异步的,利用CountDownLatch来实现等待)
- this.countDownLatch.await(timeoutMillis, TimeUnit.MILLISECONDS) 使用countDownLatch来进行等待
- NettyRemotingClient # invokeAsync 异步调用(大量的并发,进行了限流,默认值为65535)
- 异步测试的时候: remotingClient.invokeAsync 参数 InvokeCallback invokeCallback 回调方法
- this.invokeAsyncImpl 异步调用实现
- this.semaphoreAsync.tryAcquire(timeoutMillis, TimeUnit.MILLISECONDS) 通过信号量对并发进行控制(限流的概念)
- new ResponseFuture(channel…) 构建响应Future ,构建的时候传递参数invokeCallback
- channel.writeAndFlush 写数据,发送请求
- responseFuture.setSendRequestOK(true) ==> return 发送成功,打标记
- requestFail(opaque) 执行失败后执行callback的业务逻辑
- RemotingCommand.createRequestCommand(0, requestHeader) 生成RemotingCommand的请求(code 代表业务)
-
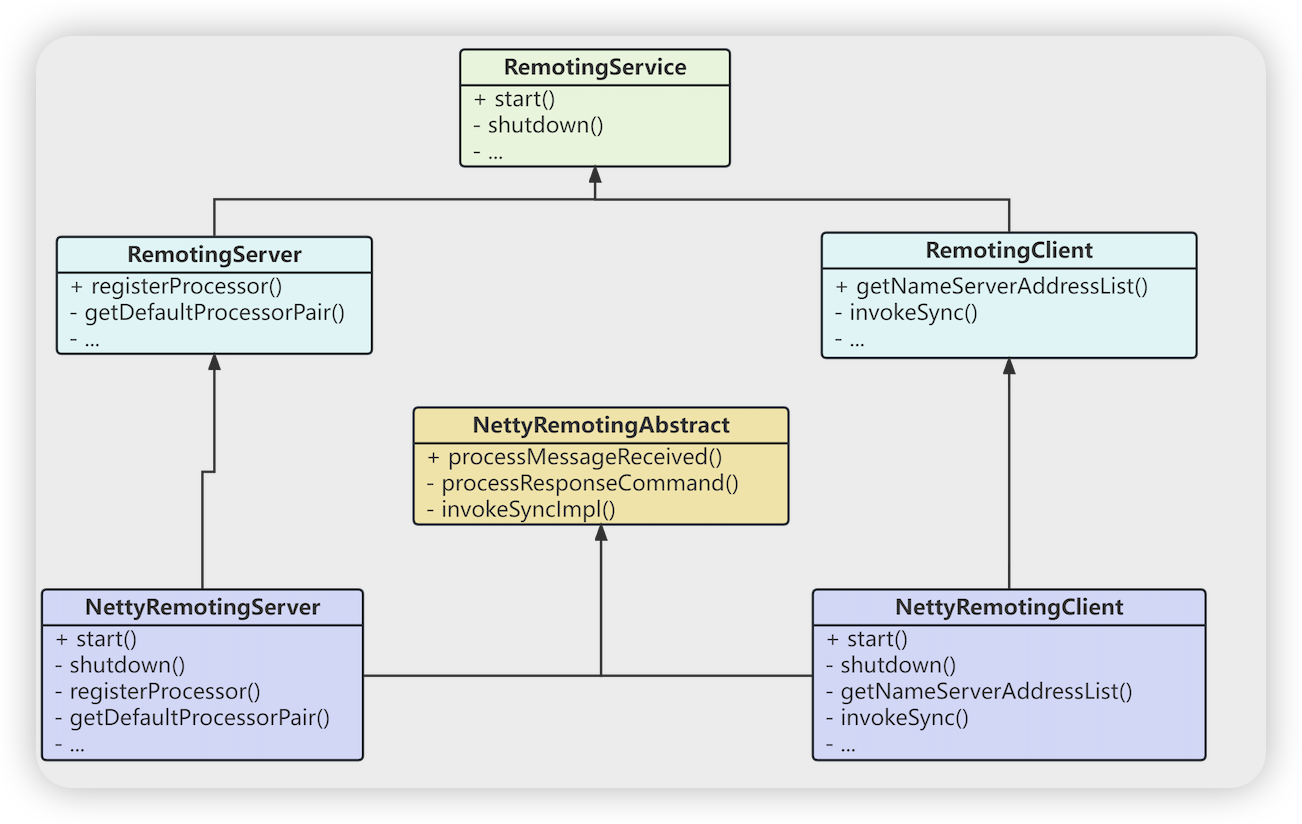
- RemotingService start shutdown 两个抽象方法
- RemotingClient 客户端
- RemotingCommand invokeSync 同步调用
- void invokeAsync 异步调用 (InvokeCallback invokeCallback)
- void invokeOneway 单向调用: 不用关心调用结果
- 客户端调用流程图
Broker源码
基础的启动流程
基础启动
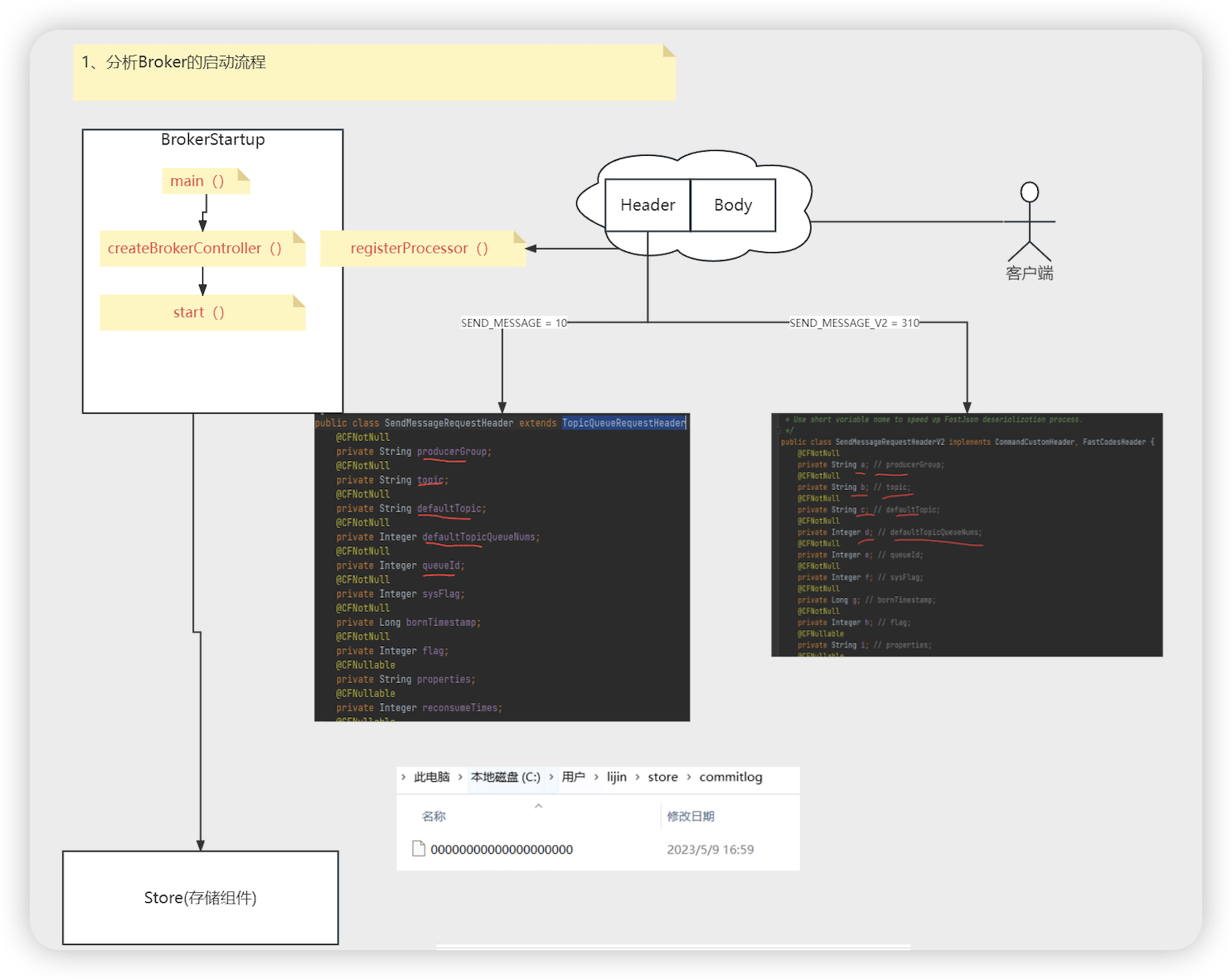
- BrokerStartup # main 主启动类
- createBrokerController(String[] args) 创建一个BrokerController , initialize, 初始controller
- buildBrokerController() 创建一个BrokerController
- brokerConfig, nettyServerConfig, nettyServerConfig, messageStoreConfig 初始化对象
- Options options 解析命令行参数 Properties properties 解析配置参数
- new BrokerController 创建controller
- controller.initialize() 核心是load
- topicConfigManager, consumerOffsetManager …将在store目录中保存的数据加载到内存
- initializeRemotingServer() 这里初始化Netty的Server组件(NettyRemotingServer) 这里会监听2个端口(10911 ,10909)
- initializeResources 初始化各种线程池
- registerProcessor 注册处理器(Netty的Server的业务处理器)
- this.remotingServer.registerProcessor 注册各种code对应的处理器
- 发送消息的处理器 , 拉取消息的处理器(客户端推模式底层实现也是基于拉模式)
-
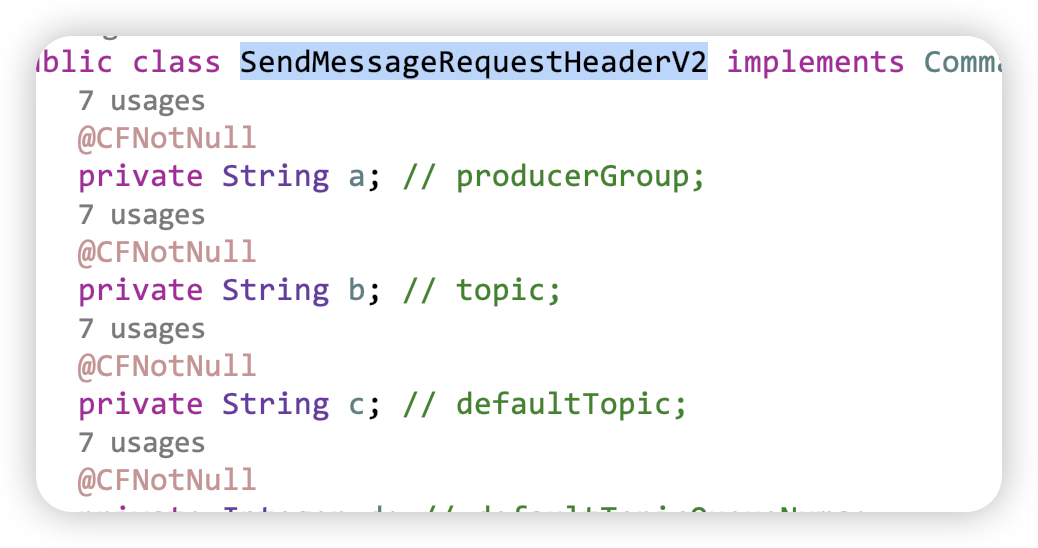
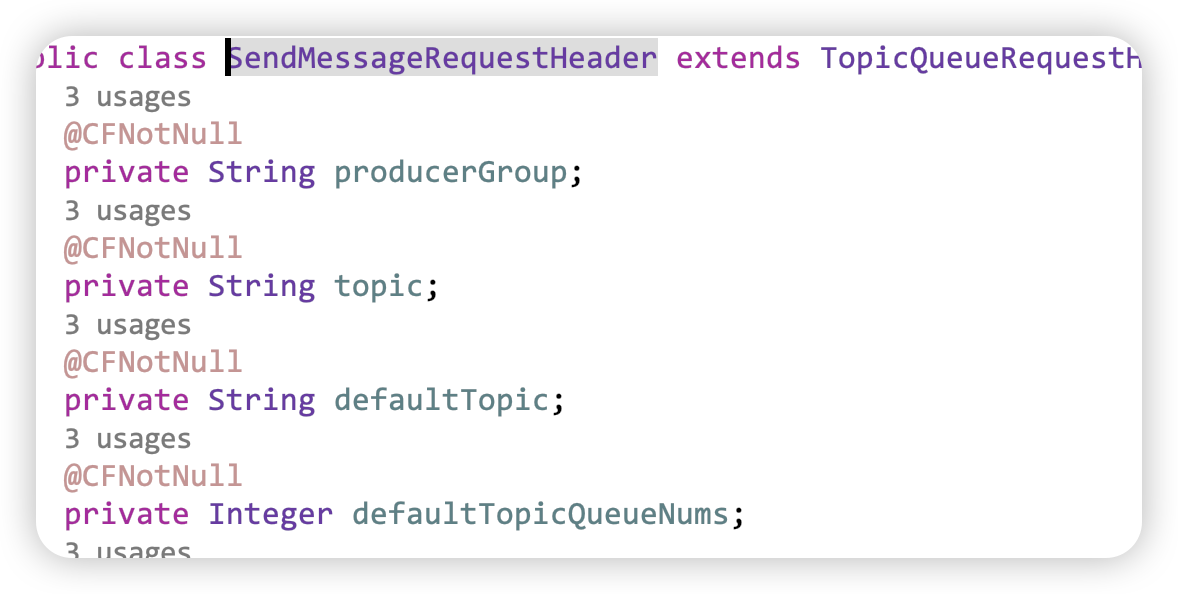
- SEND_MESSAGE_V2 默认都是使用SEND_MESSAGE_V2 这个就是Message的头更加精简 (a =? b=? ,c=? d=?)
- 将字段属性简化为 a,b,c,d
- SendMessageRequestHeader # parseRequestHeader # RequestCode.SEND_MESSAGE_V2
- decodeCommandCustomHeader # SendMessageRequestHeaderV2 序列化精简内存
- this.remotingServer.registerProcessor 注册各种code对应的处理器
- initializeScheduledTasks 初始化定时任务
- initialTransaction 初始化分布式事物处理
- start(BrokerController controller) 启动controller
- controller.start 非常重要的启动方法
- startBasicService() 启动基础组件
- this.messageStore.start() 消息的存储 组件
- Kafka消息的存储是一个主题一个分区一个文件 (意味着有很多文件), RocketMQ只有一个文件(不管多少个主题\队列),创建一个文件顺序追加,确保海量主题下的生产者的高效和稳定
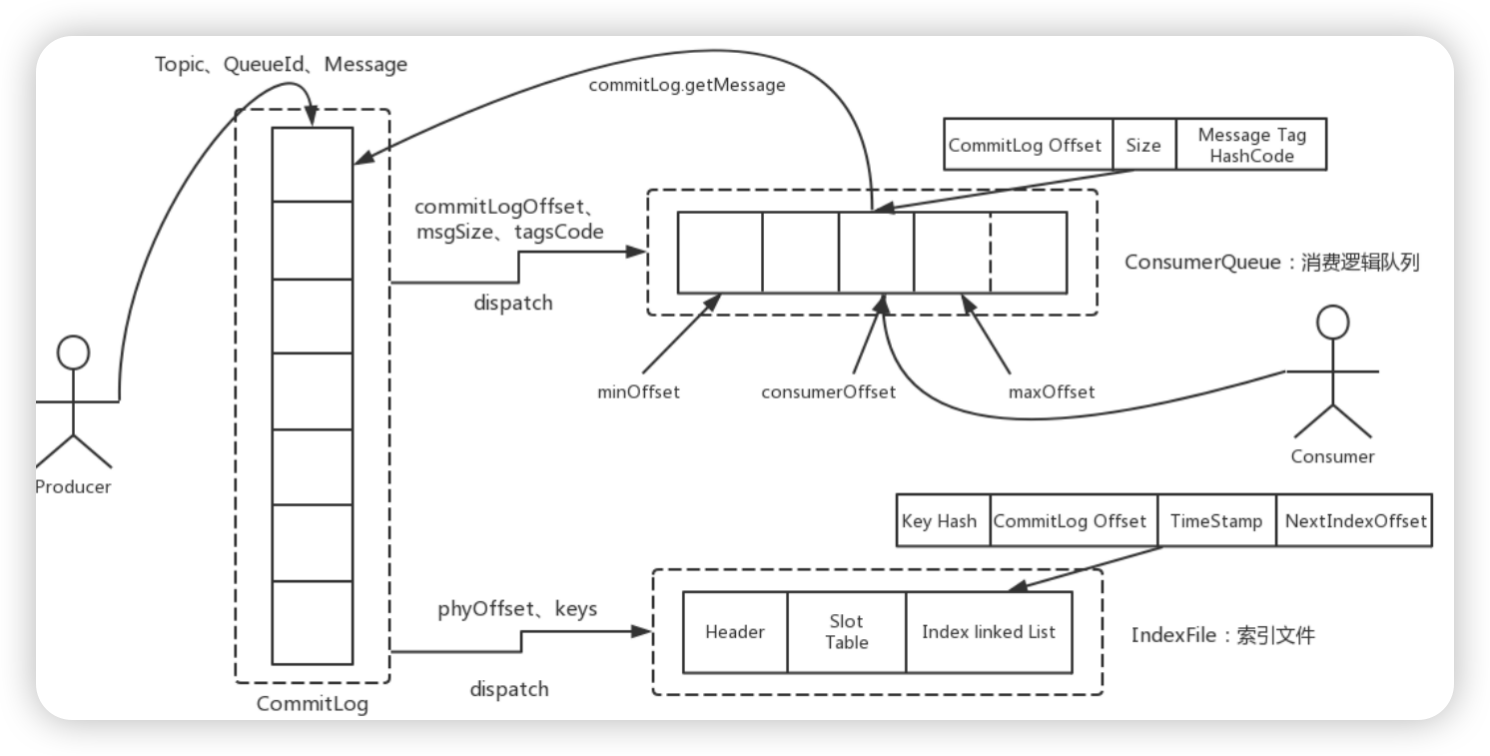
- 所有的消息进入commitlog文件,同时生成consumequeue的索引文件(利用定时任务生成)
- 消费时,先找consumequeue,然后根据偏移量和消息的大小区commitlog中把整体的消息找出来,再发送给消费者
- this.messageStore.start() 消息的存储 组件
存储服务启动
-
DefaultMessageStore # 构造
- new CommitLog(this) 创建CommitLog存储对象
- CommitLog # 构造
- String storePath = messageStore.getMessageStoreConfig().getStorePathCommitLog() 找到存储文件的全路径
- this.mappedFileQueue = new MappedFileQueue(storePath, 创建mappedFileQueue
- MappedFileQueue # CopyOnWriteArrayList mappedFiles 写时复制容器(存放具体的文件的 内存对应类)
- new ConsumeQueueStore(…) 创建consumequeue存储对象
-
BrokerController # initialize ==> this.messageStore.load() ==> DefaultMessageStore# load ==> this.commitLog.load() ==> this.consumeQueueStore.load()
-
CommitLog # load
- this.mappedFileQueue.load()
- MappedFileQueue # load
- doLoad(Arrays.asList(ls))
- new DefaultMappedFile(file.getPath(), mappedFileSize) MappedFile的处理
-
DefaultMappedFile # 构造 ==> init(fileName, fileSize) 零拷贝技术(运用MMAP零拷贝技术 (提高效率,减少IO拷贝次数))
- this.fileChannel = new RandomAccessFile(this.file, “rw”).getChannel()
- this.mappedByteBuffer = this.fileChannel.map(MapMode.READ_WRITE, 0, fileSize) 这里就是MMAP 的内存映射 (mappedByteBuffer 对应文件的映射)
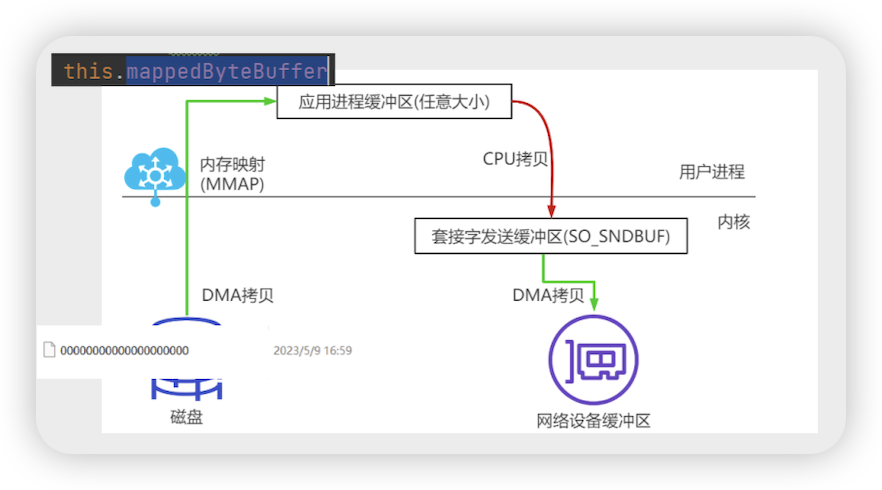
- 将文件的缓冲区映射到应用进程缓冲区(保存commitlog的文件)
-
零拷贝
- 传统的代码传输举服务端案例:
- new serversocket() 客户端发起连接->socket()
- read -> byte数组中(服务端收到了数据)
- File file =new File() ==> byte数组-> File。write()
- 正常从socket数据到磁盘发生4次拷贝
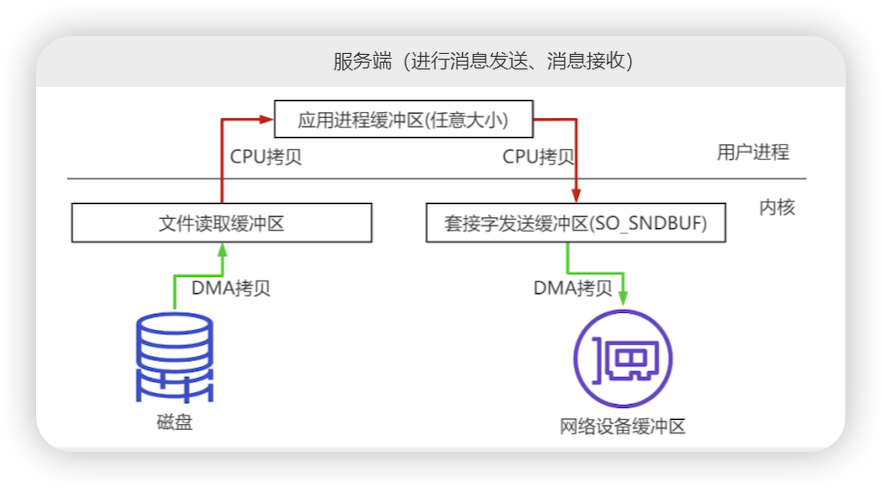
- socket 到内核套接字缓冲区(DMA拷贝) 内核到用户缓冲区(CPU拷贝)
- 用户缓冲区到 内核文件缓冲区(CPU拷贝) 内核文件缓冲区到磁盘(DMA拷贝)
- 2次CPU拷贝 ,2次DMA拷贝
- 在RocketMQ启动的时候把对应的文件做内存映射, 可以减少一次Cpu拷贝
- 将应用进程中文件的指针直接指向保存磁盘文件的文件读取缓冲区
- 将应用进程中文件的指针直接指向保存磁盘文件的文件读取缓冲区
- 传统的代码传输举服务端案例:
消息的流转
- 从生产者 --> broker --> 存储 --> 消费者 整个流程
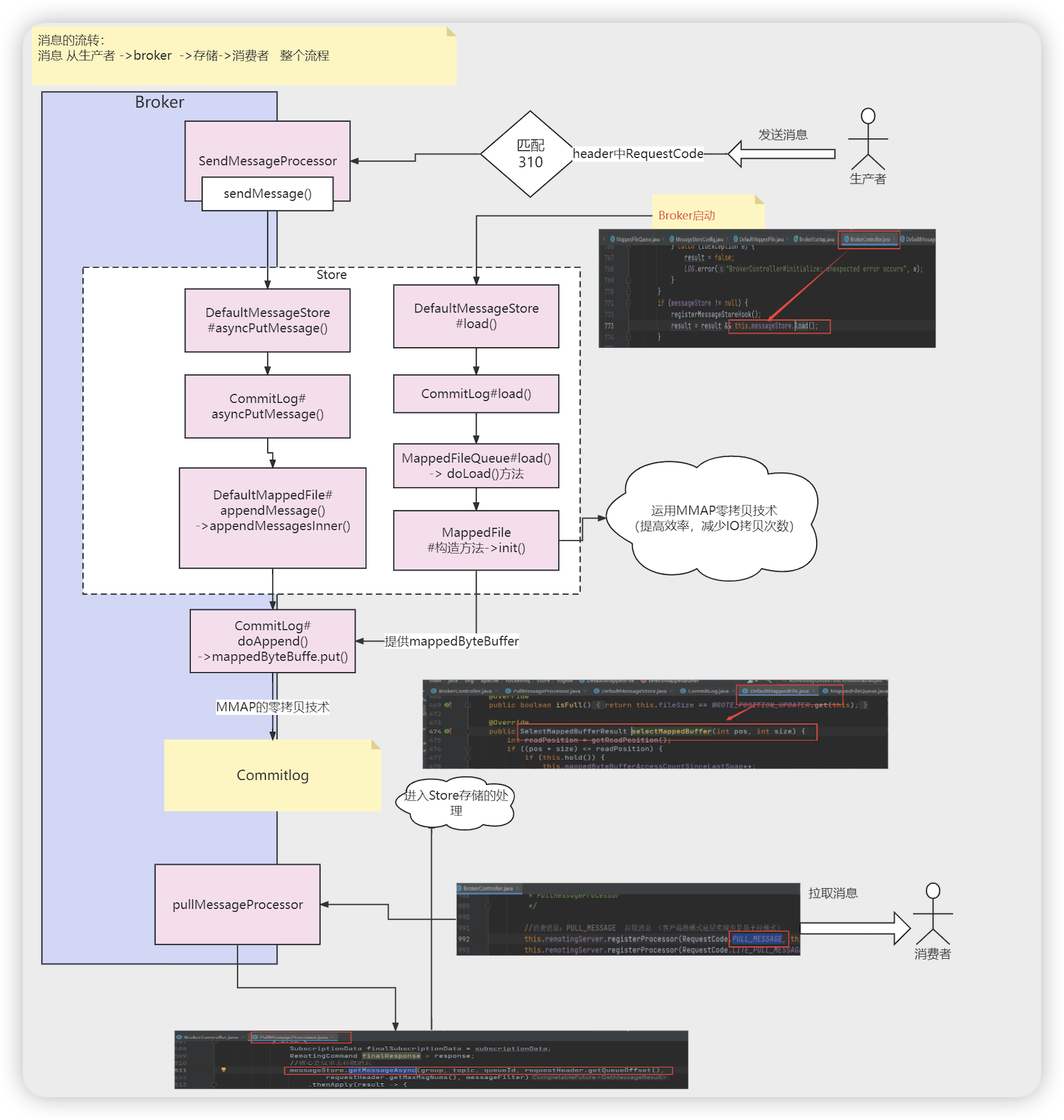
发送消息流程
- DefaultMQProducer # send
- this.defaultMQProducerImpl.send(msg)
- DefaultMQProducerImpl # send
- this.tryToFindTopicPublishInfo 这里从nameserver中获取主题发布信息
- for (; times < timesTotal; times++) { 这里是发送的重试
- this.selectOneMessageQueue(topicPublishInfo, lastBrokerName) 选择队列
- sendResult = this.sendKernelImpl 这里是生产者发送的核心入口
- new SendMessageRequestHeader() 构建消息的头
- SendResult sendResult = null 消息的发送结果
- this.mQClientFactory.getMQClientAPIImpl().sendMessage 发送消息
- MỌClientAPIImpl # sendMessage
- SendMessageRequestHeaderV2.createSendMessageRequestHeaderV2(requestHeader) 简化消息的头部, 转换为 a,b,c,d…
- RemotingCommand request = RemotingCommand.createRequestCommand(RequestCode.SEND_MESSAGE, requestHeader) 构建 请求, 请求的code和请求的头 发送消息请求的code是RequestCode.SEND_MESSAGE_V2
- request.setBody(msg.getBody()) 设置请求体
- case. communicationMode. 根据消息的发送模式,不同模式的发送消息 (invokeOneway, sendMessageAsync, sendMessageSync)
- this.sendMessageSync 同步发送消息
- this.remotingClient.invokeSync
- NettyRemotingClient # invokeSync Netty的发送请求的方法
Broker处理消息
- SendMessageProcessor # processRequest (code为) 这里是Broker接收消息的入口
- parseRequestHeader(request) 解析消息头
- RemotingCommand response = this.sendMessage
- response.readCustomHeader() 读到消息头
- final byte[] body = request.getBody() 读到消息体
- int queueIdInt = requestHeader.getQueueId() 包括队列ID(客户端生产者是可以在方式的时候 指定 这个消息的队列ID)
- new MessageExtBrokerInner() MessageExtBrokerInner 是在Broker中消息进一步封装
- CompletableFuture asyncPutMessageFuture 构建处理消息的结果(处理消息的核心)
- this.brokerController.getTransactionalMessageService().asyncPrepareMessage 事务消息
- asyncPutMessageFuture = this.brokerController.getMessageStore().asyncPutMessage(msgInner) 处理普通消息
- DefaultMessageStore # asyncPutMessage. 存储组件存储消息
储存组件处理消息
- DefaultMessageStore # asyncPutMessage
- this.commitLog.asyncPutMessage(msg) commitlog类存储消息
- CommitLog # asyncPutMessage
- mappedFile = this.mappedFileQueue.getLastMappedFile() 获取到appedFile文件
- topicQueueLock.lock(topicQueueKey) 消息主题的锁
- putMessageLock.lock() 写消息到commitlog的锁 (这里是为了确保写入 commitlog不会发生并发安全问题) new AtomicBoolean(true) 使用的是自旋锁(PutMessageSpinLock)
- mappedFile = this.mappedFileQueue.getLastMappedFile 再拿一次文件
- result = mappedFile.appendMessage(msg, this.appendMessageCallback, putMessageContext) 这里就是进行消息的追加(按照顺序的方式写入mappedFile 中)
- DefaultMappedFile # appendMessage
- appendMessagesInner(msg, cb, putMessageContext)
- ByteBuffer byteBuffer = appendMessageBuffer().slice() 获取到mappedFile 对应的buffer
- writeBuffer != null ? writeBuffer : this.mappedByteBuffer
- int currentPos = WROTE_POSITION_UPDATER.get(this) 获取到修改的位置
- cb.doAppend(this.getFileFromOffset(), byteBuffer,…) 追加文件
- CommitLog # doAppend
- long wroteOffset = fileFromOffset + byteBuffer.position() 文件的偏移量
- ByteBuffer preEncodeBuffer = msgInner.getEncodedBuff()
- this.msgStoreItemMemory.putInt … 往preEncodeBuffer 写入消息内容
- byteBuffer.put(preEncodeBuffer) 这里是进行消息的写入(仅仅是对MMAP的内存映射进行put 没有到磁盘)
Broker处理消费者拉取消息
- BrokerController # registerProcessor
- this.remotingServer.registerProcessor(RequestCode.PULL_MESSAGE, ) 注册处理拉取消息请求处理器
- PullMessageProcessor # processRequest
- MessageStore messageStore = brokerController.getMessageStore() 数据存储
- messageStore.getMessageAsync(group, topic, queueId, requestHeader.getQueueOffset()…) 去拉取消息
- DefaultMessageStore # getMessageAsync
- getMessage(…)
- consumeQueue = findConsumeQueue(topic, queueId) 获取consumeQueue
- minOffset = consumeQueue.getMinOffsetInQueue() 最小偏移量
- maxOffset = consumeQueue.getMaxOffsetInQueue() 最大偏移量
- this.commitLog.getMessage(offsetPy, sizePy) 从commitLog中获取消息
- CommitLog # getMessage
- MappedFile mappedFile = this.mappedFileQueue.findMappedFileByOffset 拿到 MappedFile文件
- mappedFile.selectMappedBuffer(pos, size)
- ByteBuffer byteBuffer = this.mappedByteBuffer.slice() 获取到对应的byteBuffer
存储核心分析
核心概念
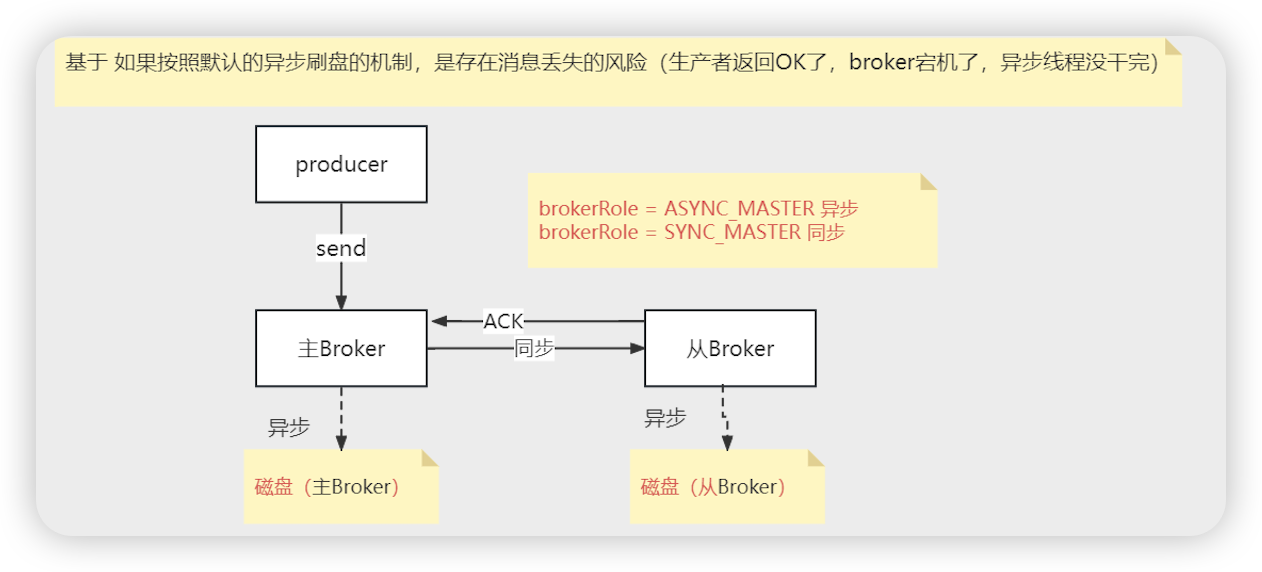
- 存储: 同步刷盘, 异步刷盘 flushDiskType = ASYNC_FLUSH (异步刷盘) | SYNC_FLUSH (同步刷盘)
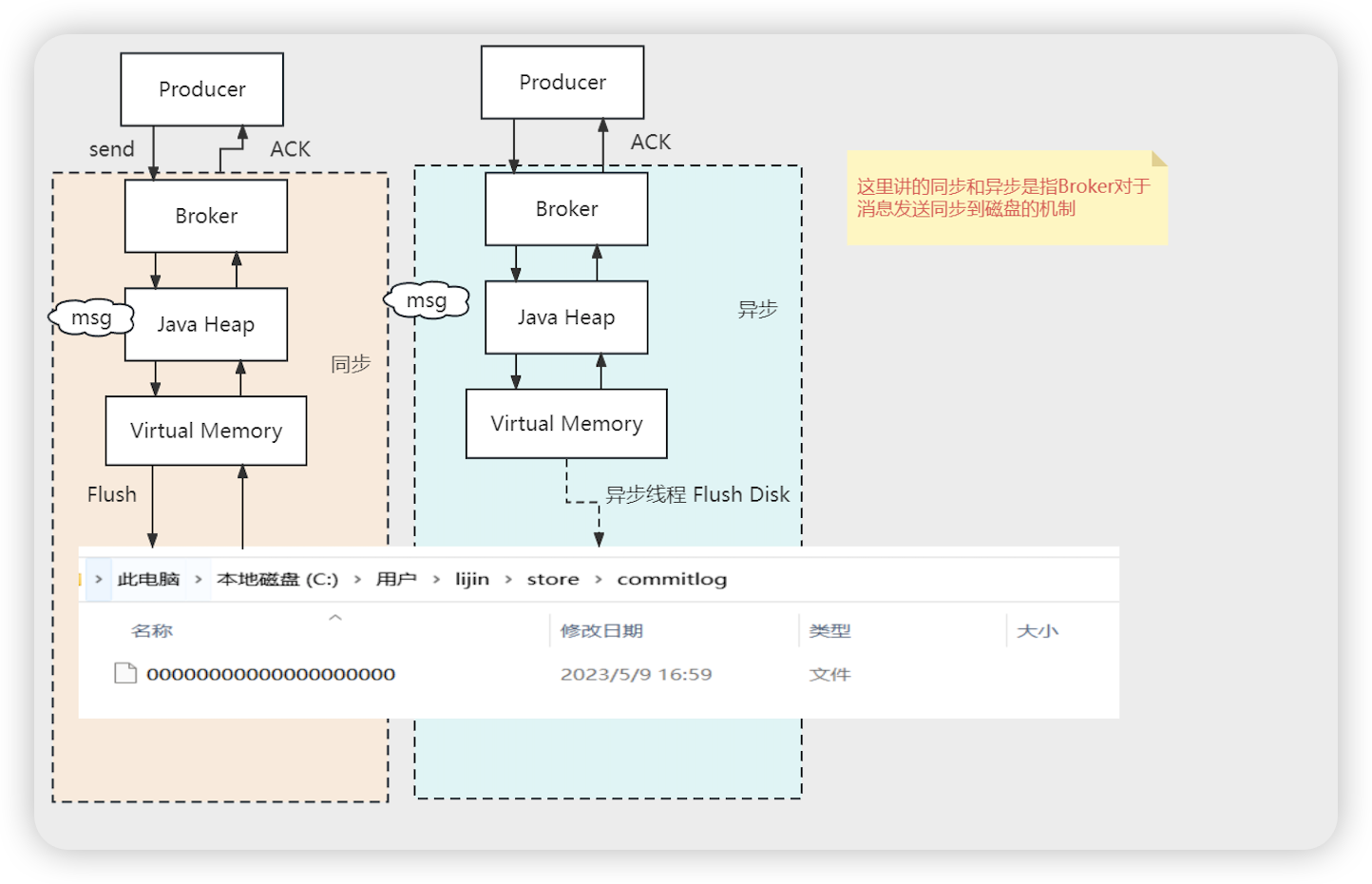
- Java Heap 构建的Inner对象
- 同步异步只是刷盘的时机不同,但是消息内容都会到达虚拟内存(文件内核缓冲区)
源码
commitlog文件刷盘
- CommitLog # 构造
- this.flushManager = new DefaultFlushManager() 刷盘的管理类
- DefaultFlushManager # 构造
- if (FlushDiskType.SYNC_FLUSH == CommitLog.this.defaultMessageStore 如果是同步刷盘
- this.flushCommitLogService = new CommitLog.GroupCommitService()
- else ==> this.flushCommitLogService = new CommitLog.FlushRealTimeService() 异步刷盘
- FlushCommitLogService flushCommitLogService 继承 ServiceThread ==> 实现 Runnable
- if (FlushDiskType.SYNC_FLUSH == CommitLog.this.defaultMessageStore 如果是同步刷盘
- this.flushManager.start() 刷盘管理类的启动方法
- this.flushCommitLogService.start() 让刷盘的任务运行
- this.thread = new Thread(this, getServiceName()) 创建线程
- this.thread.start() 运行对应的runable
- this.flushCommitLogService.start() 让刷盘的任务运行
- SendMessageProcessor # sendBatchMessage
- 同步异步都是异步线程去刷盘,但是同步刷盘,会有CompletableFuture .get () 阻塞等待刷盘结果
- if (this.brokerController.getBrokerConfig().isAsyncSendEnable()) { 判断配置的是否是异步刷盘
- this.brokerController.getMessageStore().asyncPutMessage 异步刷盘
- else 下边是同步刷盘
- this.brokerController.getMessageStore().putMessage 同步刷盘
- waitForPutResult(asyncPutMessage(msg)) 等待异步刷盘的结果
- putMessageResultFuture.get(putMessageTimeout, TimeUnit.MILLISECONDS) 阻塞等待返回结果 ==> commitLog的写入结果
- putResultFuture = this.commitLog.asyncPutMessage(msg) commitLog写入文件,返回异步的结果(CompletableFuture)
- commitLog # asyncPutMessage
- result = mappedFile.appendMessage(msg, this.appendMessageCallback…) 这里就是进行消息的追加,将消息写入到操作系统内存映射中
- handleDiskFlushAndHA(putMessageResult, msg, needAckNums, needHandleHA) 进行刷盘
- flushResultFuture = handleDiskFlush(putMessageResult.getAppendMessageResult(), messageExt) 进行刷盘
- this.flushManager.handleDiskFlush(result, messageExt) flushManager 处理磁盘刷盘新 CommitLog extend FlushManager
- CommitLog # handleDiskFlush
- if (FlushDiskType.SYNC_FLUSH == CommitLog.this.defaultMessageStore 判断是否同步
- 流程
- GroupCommitService 的run方法初始在CountDownLatch2 的阻塞上
- 进来一个异步刷盘请求,将请求进行封装, 然后添加到requestsWrite 队列上,然后将CountDownLatch2唤醒
- run 方法 CountDownLatch2唤醒后,将requestsWrite 替换到requestsRead链表
- run方法处理doCommit,遍历requestsRead 链表,进行CommitLog.this.mappedFileQueue.flush(0) 刷盘
- GroupCommitService service = (GroupCommitService) this.flushCommitLogService 转化为上边 DefaultFlushManager 构造方法创建的GroupCommitService, service 本质是runnable
- =同步刷盘=============
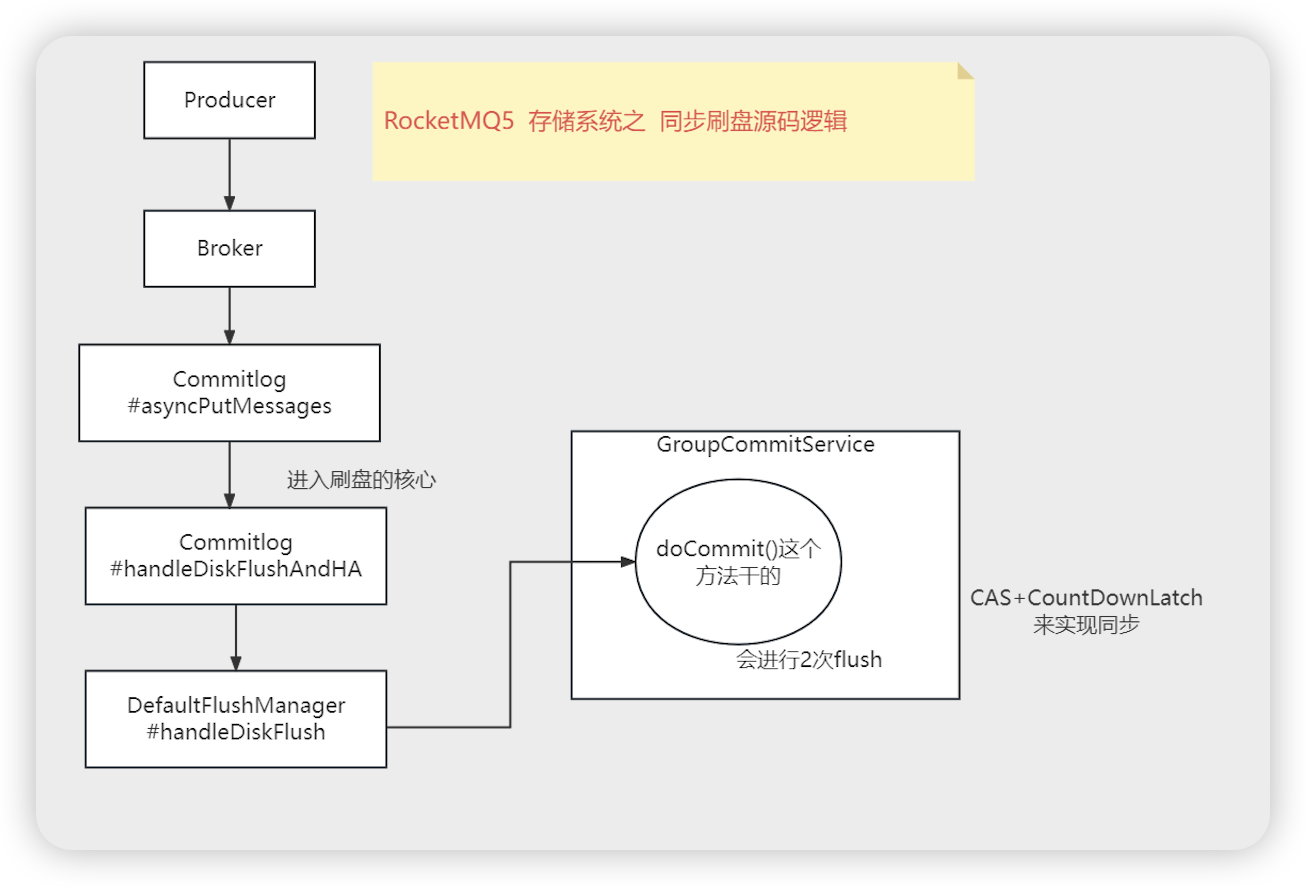
- GroupCommitService # run (同步刷盘)
- this.waitForRunning(10)
- if (hasNotified.compareAndSet(true, false)) { CAS 将是否通知由true变为false
- waitPoint.await(interval, TimeUnit.MILLISECONDS); 进行阻塞 ,将写请求放到链表中会被唤醒
- waitPoint ==> CountDownLatch2
- this.onWaitEnd() 被唤醒后执行的方法
- GroupCommitService # onWaitEnd
- LinkedList tmp = this.requestsWrite; 将写请求放到临时链表
- this.requestsWrite = this.requestsRead 重置写请求链表
- this.requestsRead = tmp 将临时链表放到读请求的链表
- this.doCommit() 处理commit
- if (!this.requestsRead.isEmpty()) { 如果questRead链表不为空
- for (GroupCommitRequest req : this.requestsRead) { 遍历链表
- CommitLog.this.mappedFileQueue.getFlushedWhere() 获取上次刷盘的位置
- for (int i = 0; i < 2 && !flushOK; i++) { 这里会刷盘两次,如果第一次刷盘事变,会重试一次
- CommitLog.this.mappedFileQueue.flush(0) 进行刷盘
- MappedFileQueue # flush fileQueue进行刷盘
- MappedFile mappedFile = this.findMappedFileByOffset(this.flushedWhere 根据偏移量获取到具体的MappedFile文件,commitlog文件名是偏移量
- int offset = mappedFile.flush(flushLeastPages); 这里就是刷盘,返回刷盘后的偏移量
- if (!this.requestsRead.isEmpty()) { 如果questRead链表不为空
- this.waitForRunning(10)
- new GroupCommitRequest 创建commit 请求
- service.putRequest(request) 将请求放到链表
- this.requestsWrite.add(request) 将请求放到请求写的链表中
- LinkedList requestsWrite 写请求的链表
- this.wakeup() 唤醒上边的CountDownLatch2
- waitPoint.countDown();
- this.requestsWrite.add(request) 将请求放到请求写的链表中
- 流程
- =异步刷盘=============
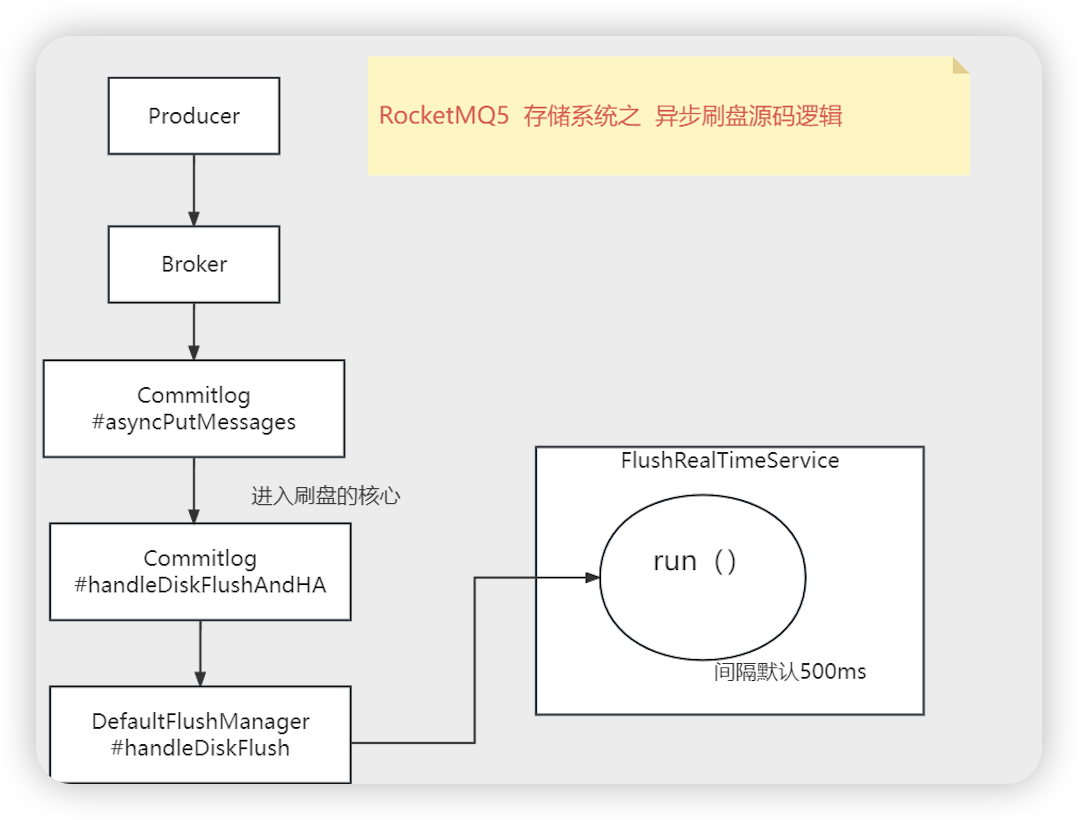
- 和同步刷盘的区别,同步刷盘需要先放到队列中,异步刷盘不需要放到队列
- flushCommitLogService.wakeup() ==> waitPoint.countDown(); 直接唤醒CountDownLatch2 ,不需要构建刷盘请求放到链表中
- FlushRealTimeService # run 异步刷盘的实现类
- while (!this.isStopped()) { 循环操作
- int interval = CommitLog.this.defaultMessageStore.getMessageStoreConfig().getFlushIntervalCommitLog() 获取循环间隔,线程sleep的时间
- Thread.sleep(interval) | this.waitForRunning(interval) 睡眠后者CountDownLatch2阻塞间隔时间
- CountDownLatch2 会被上边异步刷盘唤醒
- CommitLog.this.mappedFileQueue.flush(flushPhysicQueueLeastPages) 进行刷盘操作
- int offset = mappedFile.flush(flushLeastPages);
- while (!this.isStopped()) { 循环操作
- rocketMq同步刷盘为什么要将刷盘请求放到requestsWrite 队列中,而异步刷盘不需要
- RocketMQ 的消息存储机制中,刷盘操作是一个重要的环节,它确保了消息的持久化。RocketMQ 支持同步刷盘和异步刷盘两种模式,这两种模式在处理刷盘请求时有所不同。
- 同步刷盘
- 在同步刷盘模式下,消息在被确认写入磁盘之前,生产者的发送操作会被阻塞。为了保证消息的可靠性和一致性,RocketMQ 将刷盘请求放入一个名为
requestsWrite的队列中。这个队列的作用是序列化和管理这些刷盘请求,确保它们能够按照顺序被处理,并且每个请求都能够在确认写入磁盘之前,阻塞生产者的进一步操作。这样做可以防止在发生系统崩溃等异常情况时,消息的丢失或损坏。
- 在同步刷盘模式下,消息在被确认写入磁盘之前,生产者的发送操作会被阻塞。为了保证消息的可靠性和一致性,RocketMQ 将刷盘请求放入一个名为
- 异步刷盘
- 相比之下,异步刷盘模式不会阻塞生产者的发送操作。在异步刷盘模式下,消息被写入内存后即认为发送成功,然后由后台线程异步地将消息刷写到磁盘上。因此,异步刷盘不需要将刷盘请求放入一个队列中进行管理,因为它不需要等待刷盘操作的完成来确认消息的发送。
- 总结
- 总的来说,同步刷盘需要将刷盘请求放入
requestsWrite队列中,是为了确保消息的可靠性和一致性,通过阻塞发送操作直到消息被确认写入磁盘。而异步刷盘则不需要这样的机制,因为它不依赖于磁盘写入操作的完成来确认消息的发送。这两种模式各有优缺点,可以根据实际应用场景的需求来选择合适的刷盘模式
- 总的来说,同步刷盘需要将刷盘请求放入
从节点的刷盘
- brokerRole = ASYNC_MASTER | YNC_MASTER 是否需要等待从节点将消息同步成功(具体的刷盘策略看从节点的配置),配置到master上的
- 一般配置同步复制到从节点内存,但是主节点和从节点都是异步刷盘
consumequeue的生成机制
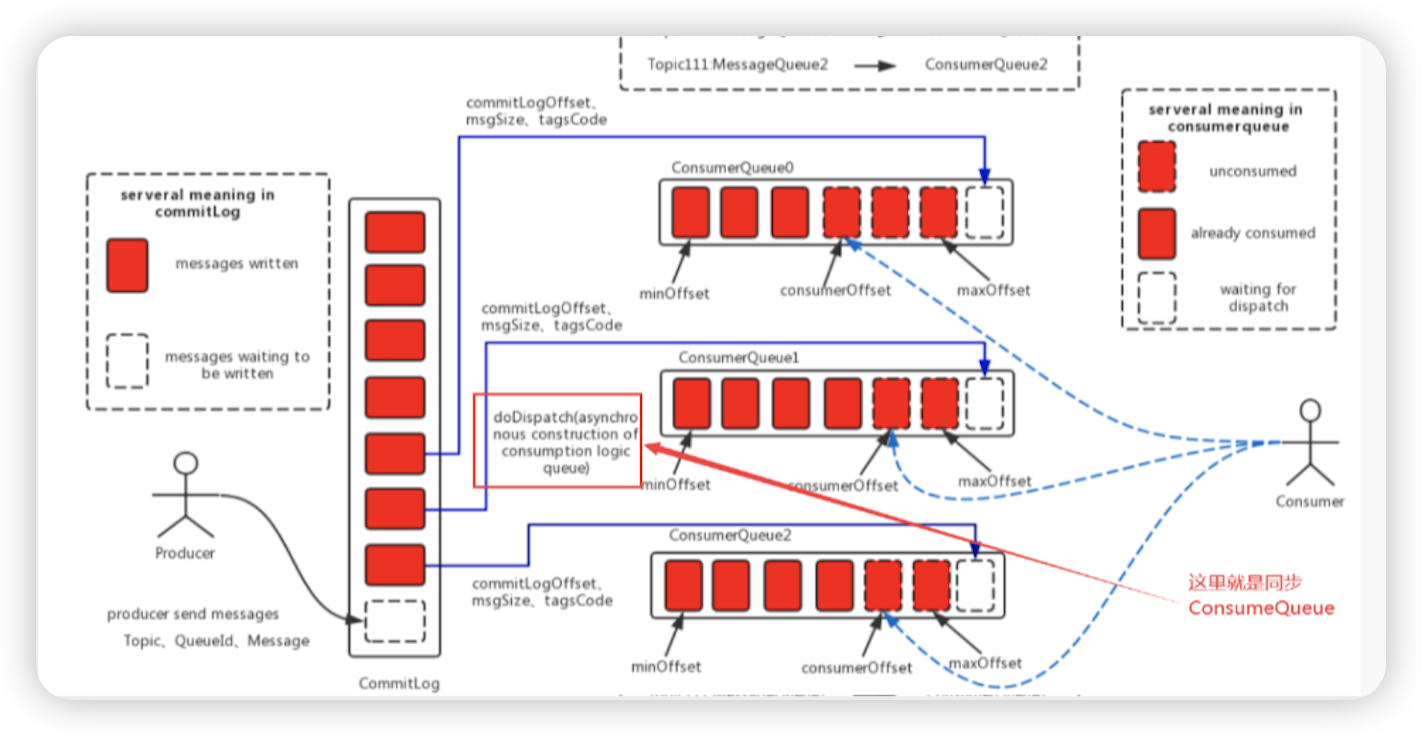
- ReputMessageService 或者 ConcurrentReputMessageService启动异步线程for循环,监控this.isCommitLogAvailable() commitLog文件是否可用, 利用多线程或者单线程的方式生成consumequeue文件
- DefaultMessageStore # 构造
- 老版本就是一个线程,新版本可以通过配置参数 变成多线程 (ReputMessageService | ConcurrentReputMessageService)
- this.reputMessageService = new ReputMessageService(); 单线程的处理生成consumequeue
- ReputMessageService # run 单线程写入consumequeue文件
- this.doReput()
- for (boolean doNext = true; this.isCommitLogAvailable() && doNext; ) { commitLog是否可用
- DefaultMessageStore.this.commitLog.getData(reputFromOffset) 从commitLog中获取到数据
- MappedFile mappedFile = this.mappedFileQueue.findMappedFileByOffset(offset, returnFirstOnNotFound); 获取到具体的文件
- mappedFile.selectMappedBuffer(pos) 获取到可读的ByteBuffer封装为result
- ByteBuffer byteBuffer = this.mappedByteBuffer.slice();
- byteBuffer.position(pos)
- ByteBuffer byteBufferNew = byteBuffer.slice()
- DefaultMessageStore.this.doDispatch(dispatchRequest)
- dispatcher.dispatch(req);
- CommitLogDispatcherBuildConsumeQueue # dispatch
- DefaultMessageStore.this.putMessagePositionInfo(request)
- ConsumeQueueInterface cq = this.findOrCreateConsumeQueue 发现或者创建consumequeue文件, ConsumeQueueInterface 是consumequeue文件的内存映射
- consumeQueue.putMessagePositionInfoWrapper(request)
- ConsumeQueue # putMessagePositionInfoWrapper
- this.putMessagePositionInfo(request.getCommitLogOffset()…) 写消息到ByteBuffer
- this.byteBufferIndex.flip();
- this.byteBufferIndex.limit(CQ_STORE_UNIT_SIZE); 每条消息20byte
- this.byteBufferIndex.putLong(offset); 前8个byte 保存offset
- this.byteBufferIndex.putInt(size); 中间4个byte 保存size
- this.byteBufferIndex.putLong(tagsCode); 后8个byte 保存tagsCode
- MappedFile mappedFile = this.mappedFileQueue.getLastMappedFile(expectLogicOffset) 获取到MappedFile文件
- mappedFile.appendMessage(this.byteBufferIndex.array()) 将byteBufferIndex 文件写到mappedFile文件
- this.putMessagePositionInfo(request.getCommitLogOffset()…) 写消息到ByteBuffer
- this.doReput()
- ConcurrentReputMessageService(利用线程池和队列处理任务)
- 总结
- ConcurrentReputMessageService 的run方法将task添加到batchDispatchRequestQueue 中
- mainBatchDispatchRequestService 利用线程池,将batchDispatchRequestQueue 的任务分发dispatchRequestOrderlyQueue队列中
- DispatchService # run方法处理dispatchRequestOrderlyQueue 队列中的任务
- start()
- this.mainBatchDispatchRequestService.start() 从batchDispatchRequestQueue队列中获取任务,利用线程池执行
- this.dispatchService.start()
- ReputMessageService # run ==> doReput
- ConcurrentReputMessageService # doReput
- this.createBatchDispatchRequest 创建批量分发请求
- BatchDispatchRequest task = new BatchDispatchRequest
- batchDispatchRequestQueue.offer(task) 批处理队列中添加task
- MainBatchDispatchRequestService # pollBatchDispatchRequest
- BatchDispatchRequest task = batchDispatchRequestQueue.peek() 从队列中拿出任务
- batchDispatchRequestExecutor.execute(…)异步线程池执行task
- dispatchRequestOrderlyQueue.put 将task任务放到dispatchRequestOrderlyQueue
- DispatchService # run() --> dispatch 方法会处理dispatchRequestOrderlyQueue 队列中的内容
- batchDispatchRequestQueue.poll() 将任务从队列中移除
- 总结
indexFile 生成
- DefaultMessageStore # 构造
- this.dispatcherList.addLast(new CommitLogDispatcherBuildIndex()) 床架IndexFile的分发器
- DefaultMessageStore.this.doDispatch(dispatchRequest)
- dispatcher.dispatch(req)
- CommitLogDispatcherBuildIndex # dispatch
- DefaultMessageStore.this.indexService.buildIndex(request) 构建索引文件
- IndexService # buildIndex
- indexFile = putKey(indexFile, msg, buildKey(topic, req.getUniqKey()))
- indexFile.putKey
- IndexFile # putKey 往indexFile中写入数据
内存区分:
- 直接内存(堆外内存):
- 定义:直接内存是指JVM堆外内存,即不由JVM直接管理的内存区域。这部分内存通过Java的NIO(New Input/Output)库进行分配和访问,主要用于提高I/O操作的性能。
- 特点:
- 不受JVM垃圾回收器管理,需要程序员手动释放。
- 读写性能通常优于堆内存,因为减少了数据在不同内存区域之间的复制。
- 分配和释放成本可能高于堆内存
- 直接内存和堆外内存不由JVM直接管理,而堆内存由JVM管理。
- 由于减少了数据在不同内存区域之间的复制次数,直接内存通常具有较高的I/O性能。然而,其分配和回收成本可能较高。
- 磁盘空间(Disk Space)
- 定义:磁盘空间是指网络托管公司分配给网站及其在网络服务器上的所有文件和内容的存储空间量,也指计算机硬盘上可用于存储数据的空间
- 特点:
- 以字节(B)、千字节(KB)、兆字节(MB)或千兆字节(GB)为单位。
- 访问速度相对较慢,但存储容量大,适合长期存储数据。
- 应用程序缓冲区(Application Buffer)
- 定义:应用程序缓冲区是应用程序在内存中开辟的一块区域,用于临时存储数据,以便在应用程序和驱动程序或外部设备之间传递数据
- 特点:
- 根据应用程序的需求设计,大小和用途各异。
- 可以提高数据处理的效率,减少I/O操作的次数。
- IO缓冲区(IO Buffer)
- 定义:IO缓冲区是在内存里开辟的一块区域,用于存放接收用户输入和用于计算机输出的数据,以减小系统开销和提高外设效率。
- 特点:
- 分为输入缓冲区和输出缓冲区,分别用于数据的接收和发送。
- 可以平滑I/O需求峰值,提高系统性能。
- 堆内存(Heap Memory)
- 定义:堆内存是JVM管理的一块内存区域,用于存放Java对象实例。
- 特点:
- 分配和回收由JVM的垃圾回收器自动管理。
- 大小可以通过JVM启动参数进行配置。
- 当堆内存不足时,JVM会进行垃圾回收以释放无用对象所占用的内存空间。如果垃圾回收后仍然无法满足内存需求,则可能会抛出OutOfMemoryError异常。
- 操作系统缓存区(Operating System Cache)
- 定义:操作系统缓存区是操作系统为了优化磁盘I/O等操作而设置的一块内存区域。
- 特点:
- 自动管理,用于缓存磁盘数据,减少磁盘访问次数,提高系统性能。
- 对应用程序透明,应用程序通常不需要直接操作操作系统缓存区。
- 操作系统缓存区由操作系统自动管理,磁盘空间由文件系统管理。
- 内核缓冲区:
- 内核缓冲区是操作系统内核为了优化磁盘I/O、网络I/O等操作而设置的一块内存区域。
- 它用于缓存磁盘数据、网络数据包等,以减少对硬件的直接访问次数,提高系统性能。
- 内核缓冲区对应用程序是透明的,应用程序通常不需要直接操作内核缓冲区。
- 直接IO
- 定义:直接IO是指应用程序直接访问磁盘数据,而不经过操作系统的内核缓冲区。这意味着IO请求直接从用户空间发送到磁盘设备,绕过了内核的缓存机制。
- 目的:直接IO的主要目的是减少数据在用户空间和内核空间之间的拷贝次数,降低系统缓存的开销,并提高IO操作的确定性。它适用于对数据访问延迟敏感或需要确保数据直接写入磁盘的场景。
- 实现方式:在Linux系统中,可以通过在打开文件时设置
O_DIRECT标志来启用直接IO。然而,使用直接IO时需要注意数据的对齐和大小要求,因为磁盘IO操作通常以扇区为单位进行。 - 优缺点:
- 优点:减少数据拷贝次数,降低缓存开销,提高IO操作的确定性。
- 缺点:可能增加CPU的开销,因为每次IO操作都需要直接与磁盘交互;同时,由于绕过了内核缓存,可能会降低缓存的利用率和整体性能。
- 零拷贝
- 零拷贝(Zero-Copy)技术是一种减少数据在用户空间和内核空间之间复制次数的技术,旨在提高数据传输效率,减少CPU负担。在传统的文件读写操作中,数据通常需要从磁盘复制到内核缓冲区,然后再从内核缓冲区复制到用户空间缓冲区,最后还可能被复制到网络缓冲区等,这个过程中涉及多次数据拷贝和上下文切换。而零拷贝技术通过减少这些不必要的拷贝和切换,来优化性能。
- 总结
- 直接内存和堆外内存主要用于提高I/O性能,操作系统缓存区用于优化磁盘I/O,磁盘空间用于长期数据存储,应用程序缓冲区和IO缓冲区用于临时存储和传递数据。
- 直接内存、堆外内存、堆内存和缓存区的访问速度通常快于磁盘空间。
- 直接内存对应用程序是可见的,需要程序员进行分配和释放;而操作系统缓冲区对应用程序是透明的,应用程序不需要直接操作
- 直接内存更侧重于Java应用程序的I/O性能提升,而内核缓冲区则更广泛地用于优化整个操作系统的I/O性能。
- IO缓冲区和内核缓冲区在功能和用途上有相似之处,但它们的定义和管理机制并不完全相同。IO缓冲区是一个更广泛的概念,可以包含内核缓冲区和用户空间的缓冲区;而内核缓冲区则是特指操作系统内核用于优化IO操作而设置的内存区域
- 内核缓冲区是操作系统缓冲区在内核空间中的一种具体实现,专门用于处理内核级别的I/O操作, 两者之间的关系可以理解为包含与被包含的关系,即内核缓冲区是操作系统缓冲区的一个子集
- 即使使用直接内存,数据写入磁盘时也可能需要经过内核缓冲区,除非应用程序明确使用了直接I/O模式
- 直接IO绕过了操作系统的内核缓冲区,直接与用户空间和磁盘设备进行交互;而内存映射则是将文件数据映射到进程的地址空间中,使得进程可以像访问内存一样访问文件数据
- 直接内存主要关注于减少数据在JVM堆内存和系统缓冲区之间的复制开销,直接内存由操作系统进行管理, 而直接IO则关注于减少数据在用户空间和内核空间之间的拷贝次数
- 直接内存是操作系统内存的一部分,但它不由内核直接管理,而是由操作系统提供的API(如Java NIO中的
ByteBuffer.allocateDirect())来分配和释放。内核内存则是操作系统内核所使用的内存区域,用于支持系统的核心功能。 - 直接内存位于用户空间,用于提高IO操作的性能;而内核内存位于内核空间,用于支持操作系统的核心功能。
- 用户空间可以有操作系统内存吗
1. 用户空间本身并不直接拥有操作系统内存,但可以通过操作系统提供的机制来访问和使用内存。操作系统内存主要指的是由操作系统管理的内存资源,这包括了内核空间和用户空间所使用的内存。
2. 在用户空间中运行的程序(如应用程序)可以通过操作系统提供的API来请求和释放内存。这些API允许程序在用户空间内分配和访问内存,但这部分内存仍然是由操作系统来管理和维护的。操作系统负责确保内存的分配和访问是安全的,防止不同程序之间的内存干扰,以及处理内存不足的情况。
3. 因此,虽然用户空间中的程序可以使用操作系统内存,但这部分内存的使用是受到操作系统管理和控制的。用户空间程序无法直接访问或管理内核空间的内存,这是由操作系统的内存保护机制所确保的。这种机制有助于保护系统的稳定性和安全性,防止用户空间程序对内核空间进行非法访问或操作 - 内存映射实现了零拷贝吗
1. MappedFile通过内存映射的方式减少了数据拷贝的次数,但在某些情况下,仍然可能涉及数据拷贝。例如,当进程首次访问映射区域的某个页面时,如果该页面尚未被加载到物理内存中(即发生缺页异常),那么内核需要将页面从磁盘加载到物理内存中,这个过程中仍然涉及数据拷贝。但相对于传统的文件读写操作来说,这种拷贝是异步进行的,并且由DMA(Direct Memory Access)完成,减少了CPU的负担。
堆外内存
- 内存映射:
- 内存映射是一种将磁盘文件或其他设备的数据映射到进程地址空间的技术。在内存映射中,操作系统会将磁盘文件或设备的数据缓存在内存中,并将这些数据在进程的地址空间中分配一段连续的虚拟地址,使得进程可以像访问内存一样高效地访问这些数据。
- 过程
- 文件加载:首先,操作系统会将磁盘上的文件内容加载到内存中。这一步是隐式的,由操作系统在进程访问映射区域时自动完成。如果数据不在物理内存中,操作系统会触发页面置换机制,将数据从磁盘加载到内存中。
- 地址映射:操作系统在进程的地址空间中分配一段连续的虚拟地址空间,并将加载到内存中的文件数据与这段虚拟地址空间建立映射关系。这样,进程就可以通过访问这段虚拟地址来间接访问文件数据。
- 优势
- 内存映射避免了频繁的磁盘操作和数据拷贝,提高了文件访问速度,特别是对于大文件和随机访问的文件。
- 支持并发访问:多个进程可以同时访问同一份映射的数据,提高了系统的并发性能。但需要注意数据一致性问题,可能需要通过锁机制、信号量等方式进行同步控制。
- 实现进程间通信:内存映射可以使得多个进程共享同一份数据,从而实现更高效的进程间通信。这种方式比传统的管道或消息队列更加高效。
- 各种空间
- (直接内存,堆外内存) 不受jvm管理 应用程序缓冲区(堆内存)
- 操作系统缓存区 包含 内核缓冲区(内核级别的I/O操作)
- 磁盘空间 IO缓冲区(用户空间,内核空间)
- DefaultMessageStore # start
- this.isTransientStorePoolEnable() 是否开启堆外内存 ==>messageStoreConfig.isTransientStorePoolEnable() transientStorePoolEnable为true(开启直接内存)并且不是从节点
- this.transientStorePool.init(). 初始化
- for (int i = 0; i < poolSize; i++) { poolSize默认为5,默认有5块直接内存
- byteBuffer = ByteBuffer.allocateDirect(fileSize) 分配一个直接堆外内存
- LibC.INSTANCE.mlock(pointer, new NativeLong(fileSize)) 内存进行锁定(避免交换),fileSize默认为1个G,是commitlog的文件大小
- availableBuffers.offer(byteBuffer) 将内存放到队列中
- AllocateMappedFileService # mmapOperation 使用本地内存的构造
- messageStore.isTransientStorePoolEnable() 是否开启直接内存
- mappedFile.init(req.getFilePath(), req.getFileSize(), messageStore.getTransientStorePool())
- 和上边的DefaultMessageStore # start ==> this.transientStorePool.init(). 初始化 关联
- 和下边的DefaultMappedFile # init关联
- mappedFile.init(req.getFilePath(), req.getFileSize(), messageStore.getTransientStorePool())
- messageStore.isTransientStorePoolEnable() 是否开启直接内存
- DefaultMappedFile # init
- this.writeBuffer = transientStorePool.borrowBuffer()
- ByteBuffer buffer = availableBuffers.pollFirst(); 从队列中获取到直接内存
- this.writeBuffer = transientStorePool.borrowBuffer()
- DefaultMappedFile # appendMessage
- appendMessageBuffer()
- writeBuffer != null ? writeBuffer : this.mappedByteBuffer 如果writeBuffer 不为null,则取直接内存,否则取内存映射
- 使用直接内存和内存映射可以实现读写分离,写的时候用直接内存,读取的时候用内存映射
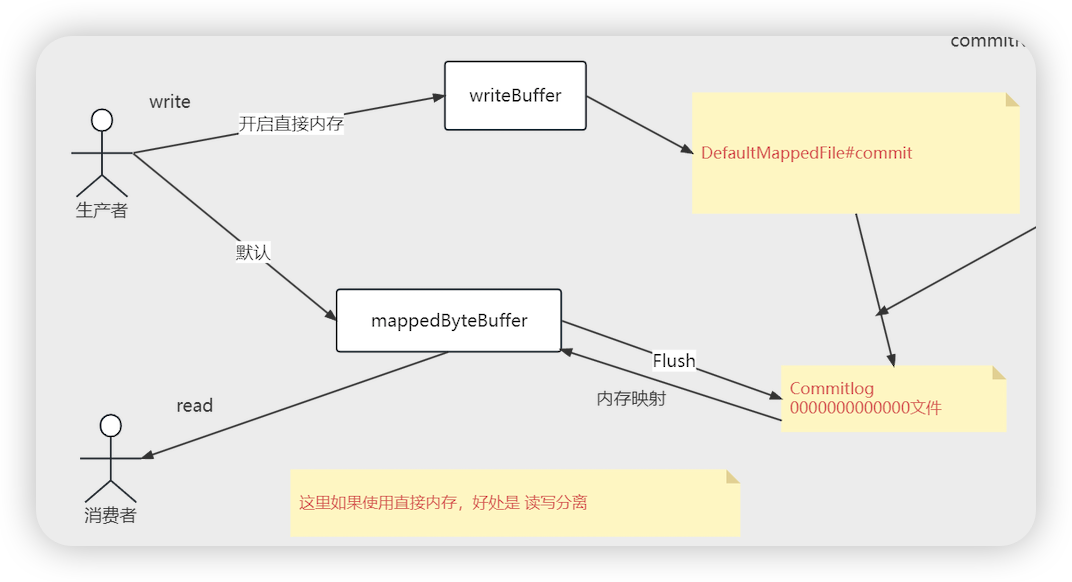
- appendMessageBuffer()
- CommitLog # flush
- this.mappedFileQueue.commit(0)
- int offset = mappedFile.commit(commitLeastPages)
- DefaultMappedFile # commit
- commit0();
- ByteBuffer byteBuffer = writeBuffer.slice(); writeBuffer 直接内存写之前的slice
- this.fileChannel.write(byteBuffer); 将直接内存写到fileChannel,写磁盘
- writeBuffer != null … 直接内存不为空
- this.transientStorePool.returnBuffer(writeBuffer) 将直接内存返回
- byteBuffer.position(0) | byteBuffer.limit(fileSize) 重置byteBuffer
- this.availableBuffers.offerFirst(byteBuffer) 将byteBuffer放到队列
- commit0();
- DefaultFlushManager # 构造
- FlushDiskType.SYNC_FLUSH != getFlushDiskType 异步刷盘
- new CommitLog.FlushRealTimeService() 异步刷盘
- FlushCommitLogService # run
- CommitLog.this.mappedFileQueue.commit(commitDataLeastPages) 异步线程刷盘commitlog
- mappedFile.commit(commitLeastPages)
- FlushCommitLogService # run
- 直接内存和内存映射
- 直接内存(Direct Memory)和内存映射(Memory Mapping 虚拟内存,需要进行刷盘)是两种不同的内存访问机制
- 区别
- 定义与用途
- 直接内存:通常指的是操作系统内核空间之外的内存,即用户空间可以直接访问的内存区域,但在Java等高级语言中,直接内存更多指的是堆外内存,即不是由Java虚拟机(JVM)直接管理的内存。直接内存不受JVM垃圾回收机制的控制,但可以通过JNI(Java Native Interface)等方式由Java代码访问。它主要用于提高性能,特别是在需要频繁进行内存与I/O设备之间数据交换的场景中,如网络传输、文件操作等。
- 内存映射:是一种内存访问技术,它将文件或设备的内容映射到进程的地址空间中,使得程序可以直接通过指针访问这些数据,而不需要通过传统的文件I/O操作。内存映射主要用于提高文件I/O操作的性能,因为它允许操作系统利用虚拟内存管理来进行优化,减少数据拷贝次数
- 实现方式
- 直接内存:在Java中,可以通过NIO(New Input/Output)包中的DirectByteBuffer类来分配直接内存。这种内存分配方式绕过了JVM堆,直接在操作系统的内存空间中分配,因此不受JVM垃圾回收机制的控制。
- 内存映射:在操作系统中,内存映射通常通过系统调用实现,如Unix/Linux系统中的mmap()函数或Windows系统中的CreateFileMapping()和MapViewOfFile()函数。这些调用将文件或设备的内容映射到进程的地址空间中,并建立虚拟地址与物理地址之间的映射关系。
- 性能影响
- 直接内存:由于绕过了JVM堆和垃圾回收机制,直接内存访问通常比堆内存访问更快。但是,直接内存管理较为复杂,需要程序员手动管理内存的生命周期,以避免内存泄漏等问题。
- 内存映射:内存映射通过减少数据拷贝次数来提高文件I/O操作的性能。当文件被映射到内存后,程序可以直接通过指针访问文件内容,而不需要通过系统调用来读取或写入文件。这大大减少了系统调用的开销和数据拷贝的次数。
- 与文件的对应
- 直接内存(Direct Memory)并不是直接对应磁盘上的一个文件。直接内存是指操作系统内核空间之外的内存,它绕过了Java虚拟机(JVM)堆内存,直接在操作系统的内存空间中分配。这种内存分配方式通常用于提高性能,特别是在需要频繁进行内存与I/O设备(如网络套接字、文件系统等)之间数据交换的场景中。直接内存的使用不受JVM垃圾回收机制的控制,需要程序员手动管理其生命周期,以避免内存泄漏等问题。
- 内存映射(Memory Mapping)则是一种将磁盘上的文件或设备的内容映射到进程的地址空间中的技术。通过这种方式,文件或设备的内容可以被视为进程地址空间中的一部分,程序可以直接通过指针访问这些数据,而不需要通过传统的文件I/O操作。内存映射通常用于提高文件I/O操作的性能,因为它允许操作系统利用虚拟内存管理来进行优化,减少数据拷贝次数。在内存映射中,磁盘上的文件与进程地址空间中的一段虚拟地址之间建立了一一对应的关系。这种映射关系是通过操作系统提供的系统调用来实现的,如Unix/Linux系统中的mmap()函数或Windows系统中的CreateFileMapping()和MapViewOfFile()函数。当文件被映射到内存后,程序可以直接通过指针访问文件内容,而操作系统会在适当的时候处理内存与磁盘之间的数据交换。
- 直接内存:不直接对应磁盘上的文件,而是在操作系统的内存空间中分配,用于提高内存与I/O设备之间数据交换的性能
- 内存映射:将磁盘上的文件或设备的内容映射到进程的地址空间中,使得程序可以直接通过指针访问这些数据,从而提高文件I/O操作的性能。
- 定义与用途
- 联系
- 尽管直接内存和内存映射在定义、实现方式和性能影响上存在差异,但它们都是为了提高内存访问和文件I/O操作的性能而设计的。在某些场景下,这两种技术可以相互结合使用,以达到更好的性能效果。例如,在Java网络编程中,可以使用直接内存来分配Socket缓冲区,以减少数据在用户空间和内核空间之间的拷贝次数;同时,可以利用内存映射技术将网络文件映射到内存中,以便程序可以直接访问文件内容
- 尽管直接内存和内存映射在定义、实现方式和性能影响上存在差异,但它们都是为了提高内存访问和文件I/O操作的性能而设计的。在某些场景下,这两种技术可以相互结合使用,以达到更好的性能效果。例如,在Java网络编程中,可以使用直接内存来分配Socket缓冲区,以减少数据在用户空间和内核空间之间的拷贝次数;同时,可以利用内存映射技术将网络文件映射到内存中,以便程序可以直接访问文件内容
消息发送总览
producer启动流程
- DefaultMQProducer # 构造
- new DefaultMQProducerImpl
- this.asyncSenderThreadPoolQueue = new LinkedBlockingQueue<>(50000) 异步发送队列
- this.defaultAsyncSenderExecutor = new ThreadPoolExecutor 异步发送线程池
- new DefaultMQProducerImpl
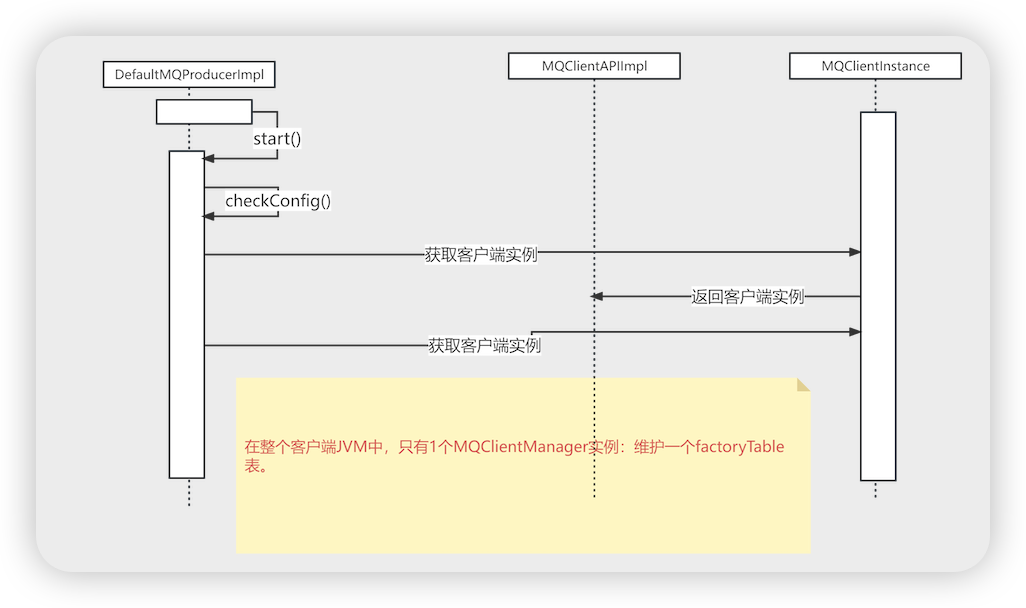
- DefaultMQProducer # start
- this.defaultMQProducerImpl.start()
- case CREATE_JUS 第1步CREATE_JUST
- this.checkConfig() 检查配置信息
- MQClientManager.getInstance().getOrCreateMQClientInstance 通过MQClientManager 创建 MQClientInstance 实例
- MQClientManager # 属性
- ConcurrentMap<String/* clientId */, MQClientInstance> factoryTable 客户端唯一标识和MQClientInstance 的缓存map
- MQClientManager # getOrCreateMQClientInstance
- String clientId = clientConfig.buildMQClientId(); 客户端的ID 唯一性标识 IP@instanceName@unitName
- new MQClientInstance(clientConfig.cloneClientConfig() 创建MQClientInstance
- MQClientInstance # 构造
- nettyClientConfig = new NettyClientConfig() nettyclient
- pullMessageService = new PullMessageService(this) 拉取消息的服务
- rebalanceService = new RebalanceService(this) 负载均衡的服务
- defaultMQProducer = new DefaultMQProducer(MixAll.CLIENT_INNER_PRODUCER_GROUP) 默认的mq发送者
- mQClientFactory.registerProducer 往 MQClientInstance 注册defaultMQProducerImpl
- ConcurrentMap<String, MQProducerInner> producerTable 发送者组名和发送者实现类的map
- this.producerTable.putIfAbsent(group, producer)
- mQClientFactory.start() MQClientInstance 的启动
- MQClientInstance # start
- mQClientAPIImpl.start() netty服务的启动
- startScheduledTask() 定时从nameserver中获取路由信息
- pullMessageService.start() 拉取消息开启
- rebalanceService.start() 负载均衡开启
producer 发送消息流程
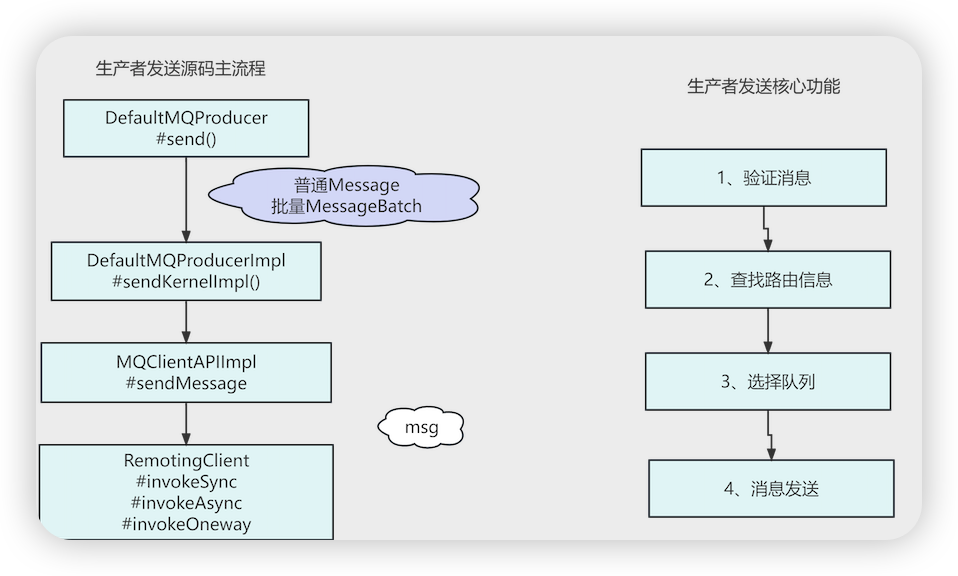
- DefaultMQProducer # send
- this.defaultMQProducerImpl.send(msg)
- this.mQClientFactory.getMQClientAPIImpl().sendMessage 从 MỌClientInstance 获取到MQClientAPIImpl netty组件发送消息
- this.remotingClient.invokeOneway 发送单向消息
- this.sendMessageAsync 发送异步消息
- this.sendMessageSync 发送同步消息
消息发送核心功能
- DefaultMQProducerImpl # sendDefaultImpl
从nameserver获取主题发送信息
- this.tryToFindTopicPublishInfo(msg.getTopic()) 从nameserver中获取主题发布信息(入参主题)
- topicPublishInfo = this.topicPublishInfoTable.get(topic) 从缓冲中根据topic获取到topic的Info信息,利用topicPublishInfoTable 缓存topic对应的信息
- if(null == topicPublishInfo) ===> this.mQClientFactory.updateTopicRouteInfoFromNameServer(topic) 如果是空的,从nameserver中获取topic对应信息
- MQClientInstance # updateTopicRouteInfoFromNameServer
- this.mQClientAPIImpl.getTopicRouteInfoFromNameServer 利用netty从nameserver获取topic信息
- MQClientAPIImpl # getTopicRouteInfoFromNameServer
- request = RemotingCommand.createRequestCommand(RequestCode.GET_ROUTEINFO_BY_TOPIC, requestHeader) 创建请求信息 code为GET_ROUTEINFO_BY_TOPIC
- this.remotingClient.invokeSync netty发送请求, 向NAmeServer获取路由信息
- if (topicPublishInfo != null && topicPublishInfo.ok()) { 如果主题信息不为空
- int timesTotal = 1 + this.defaultMQProducer.getRetryTimesWhenSendFailed() 获取发送次数 = 1 + 发送重试次数
从topic主题信息中选择队列
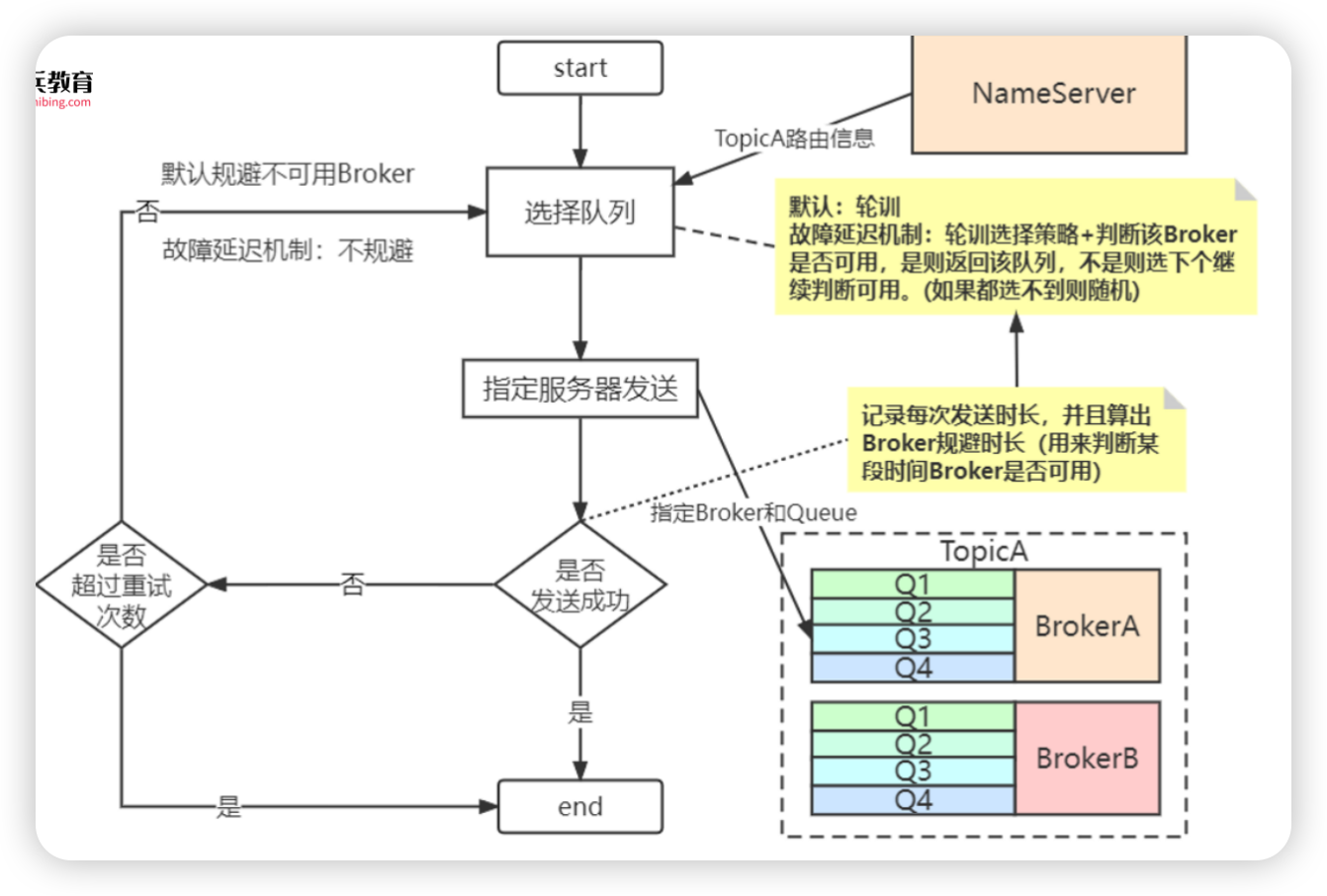
- String lastBrokerName = null == mq ? null : mq.getBrokerName(); lastBrokerName 第一次发送的时候为空,重试的时候会有值
- this.updateFaultItem(mq.getBrokerName(), endTimestamp - beginTimestampPrev, true) 每次发送消息结束(不管成功失败),会将对应brokerName和这次发送消息的时长放入缓存

- brokerName的数量大于等于2,规避选择才有意义,即master的数量要大于等于2,如果只有一个broker,是没意义的,规避重试规避的是broker,轮询策略选择的是queue(队列)
- isolation 发送消息成功为false,发送消息失败为true
- long duration = computeNotAvailableDuration(isolation ? 30000 : currentLatency); 这里用计算规避时长 ,如果发送消息失败,计算规避的时间参数为30s,如果消息发送成功,计算规避的时间参数为这次发送消息用的时间
- private long[] latencyMax = {50L, 100L, 550L, 1000L, 2000L, 3000L, 15000L} 发送延时
- private long[] notAvailableDuration = {0L, 0L, 30000L, 60000L, 120000L, 180000L, 600000L} 故障规避的时长
- 利用计算规避时间参数从发送延时找到对应的下标,利用该下标从故障规避时长的数组中找到对应的下标元素即为这个brokerName需要规避的时间, 如果发送时间小于100,规避时间为0,不需要规避
- this.latencyFaultTolerance.updateFaultItem 更新规避时长缓存
- faultItem.setStartTimestamp(System.currentTimeMillis() + notAvailableDuration) 设置规避结束的时间 = 当前时间 + 需要规避的时间(不可用的时间)
- ConcurrentHashMap<String, FaultItem> faultItemTable 更新map缓存
- MessageQueue mqSelected = this.selectOneMessageQueue(topicPublishInfo, lastBrokerName) 选择队列
- if (this.sendLatencyFaultEnable) { 队列选择发送策略 ==> 故障延迟机制(非默认)
- 记录每次发送时长,并且计算出broker规避时长(用来判断某段时间broker是否可用)
- for (int i = 0; i < tpInfo.getMessageQueueList().size(); i++) { 遍历topic的队列集合
- latencyFaultTolerance.isAvailable(mq.getBrokerName()) ==> return mq; 如果这个broker可用,返回队列
- final FaultItem faultItem = this.faultItemTable.get(name) 从faultItemTable 获取到brokerName对应的不可用时间
- faultItem.isAvailable() ==> (System.currentTimeMillis() - startTimestamp) >= 0; 判断是否可用 当前时间 - 不可用时间是否大于0
- tpInfo.selectOneMessageQueue(lastBrokerName) 轮询机制
- if (lastBrokerName == null) { lastBrokerName == null 说明是第一次发送消息
- selectOneMessageQueue() 标准的轮询
- int index = this.sendWhichQueue.incrementAndGet(); index +1
- int pos = index % this.messageQueueList.size(); index % queue的size
- this.messageQueueList.get(pos) 从队列集合获取队列
- else 消息发送重试的轮询, 规避发送失败的broker
- for (int i = 0; i < this.messageQueueList.size(); i++) { 遍历messageQueueList 队列集合
- if (!mq.getBrokerName().equals(lastBrokerName)) { ==> return mq; 如果选择出来的brokerName != 传进来的brokerName,返回, 规避上次不可用的broker
- selectOneMessageQueue() 如果没有选择出来,进行重新轮询选择
- if (lastBrokerName == null) { lastBrokerName == null 说明是第一次发送消息
利用netty发送消息
- if (mqSelected != null) { 如果选择的queue不为空
- sendResult = this.sendKernelImpl 生产者发送消息的核心
- brokerName = this.mQClientFactory.getBrokerNameFromMessageQueue(mq) 获取brokerName
- brokerAddr = this.mQClientFactory.findBrokerAddressInPublish(brokerName) 获取broker的地址
- if (null == brokerAddr) { 如果broker地址为null
- tryToFindTopicPublishInfo(mq.getTopic()); 再次从nameserver获取broker地址
- new SendMessageRequestHeader(); 消息头
- this.mQClientFactory.getMQClientAPIImpl().sendMessage 发送消息
连接建立
- producer.start与nameserver建立连接
- producer.send与broker建立连接
- NettyRemotingClient # invokeSync
- final Channel channel = this.getAndCreateChannel(addr) 这个地方与broker建立连接
- ConcurrentMap<String /* addr */, ChannelWrapper> channelTables 缓存
- ChannelWrapper cw = this.channelTables.get(addr) 将地址对应的channel信息进行缓存
- this.createChannel(addr) 如果缓存中没有创建channel
- ChannelFuture channelFuture = fetchBootstrap(addr).connect(hostAndPort[0], Integer.parseInt(hostAndPort[1])) 建立连接
- fetchBootstrap ==> Bootstrap bootstrap = new Bootstrap() 获取到Bootstrap
- connect ==> bootstrap.connect 利用netty连接broker
- 利用的是RemotingCommand协议
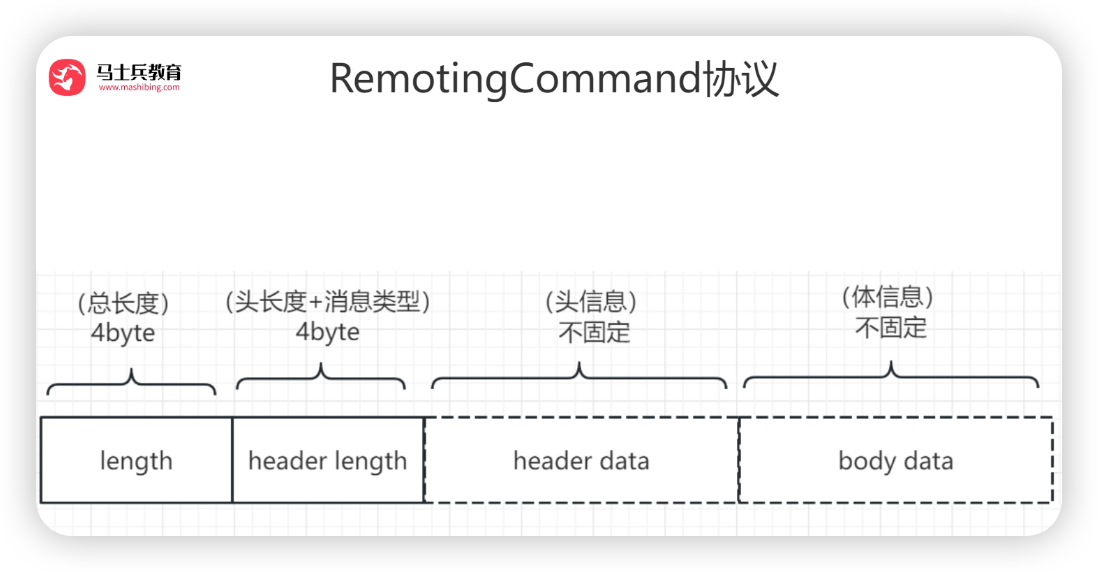
- cw = new ChannelWrapper(channelFuture) 将channelFuture包装为ChannelWrapper
- this.channelTables.put(addr, cw) 放入缓存
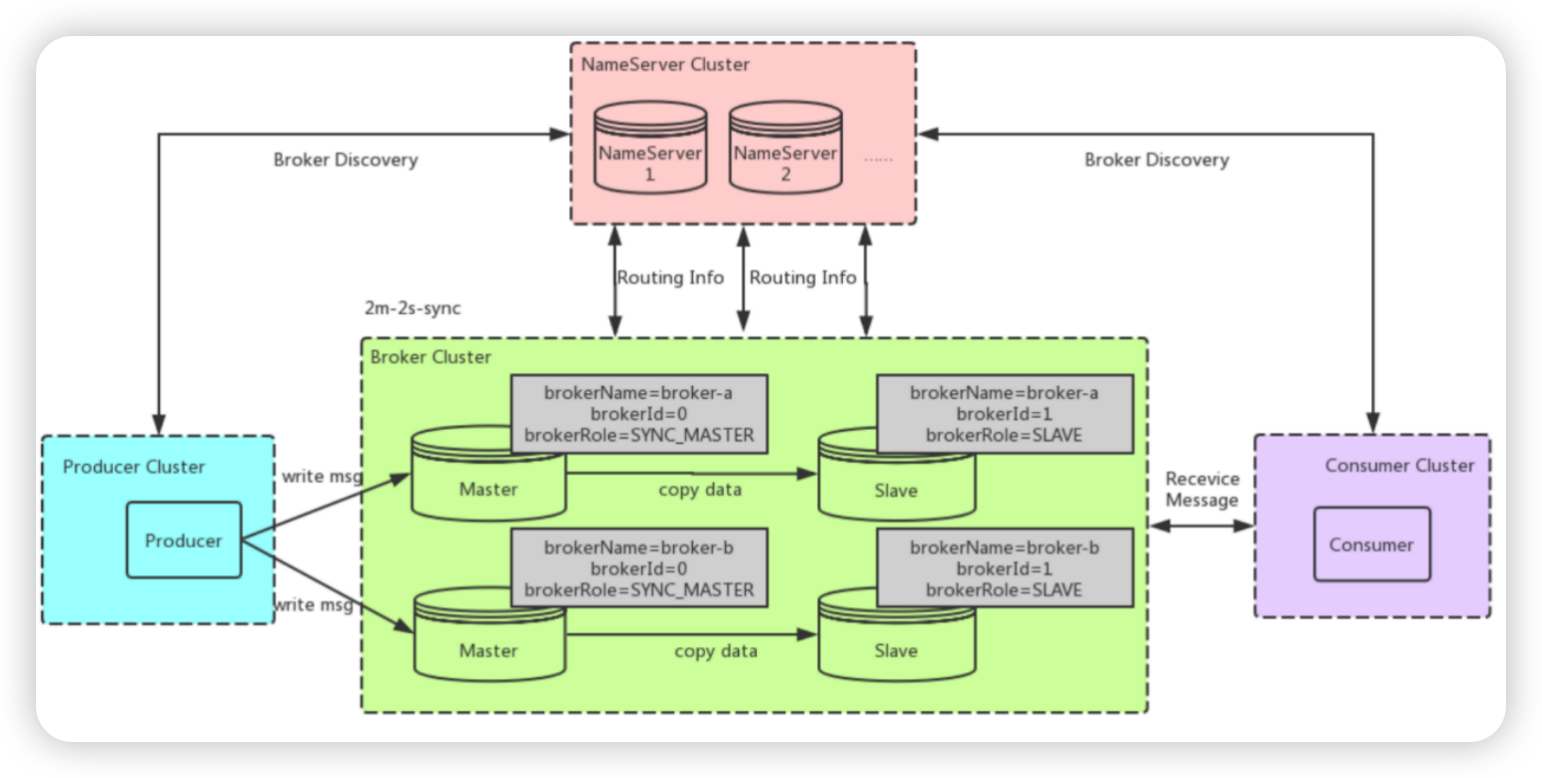
主从同步与多副本机制
主从复制配置
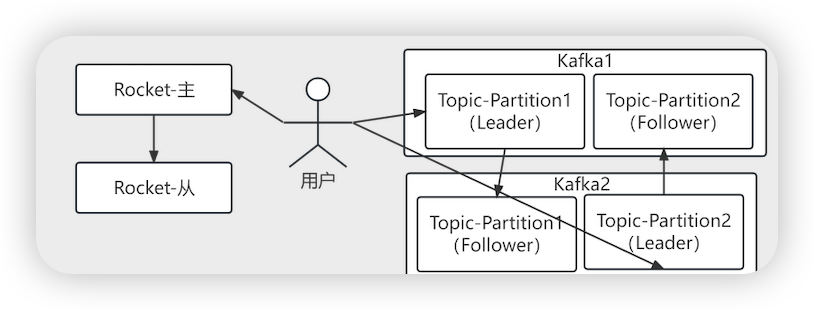
- kfaka与rocketMq集群最主要的区别
- RocketMq的主从建立在broker上,Kakfa的集群建立在Topic中的Partition中
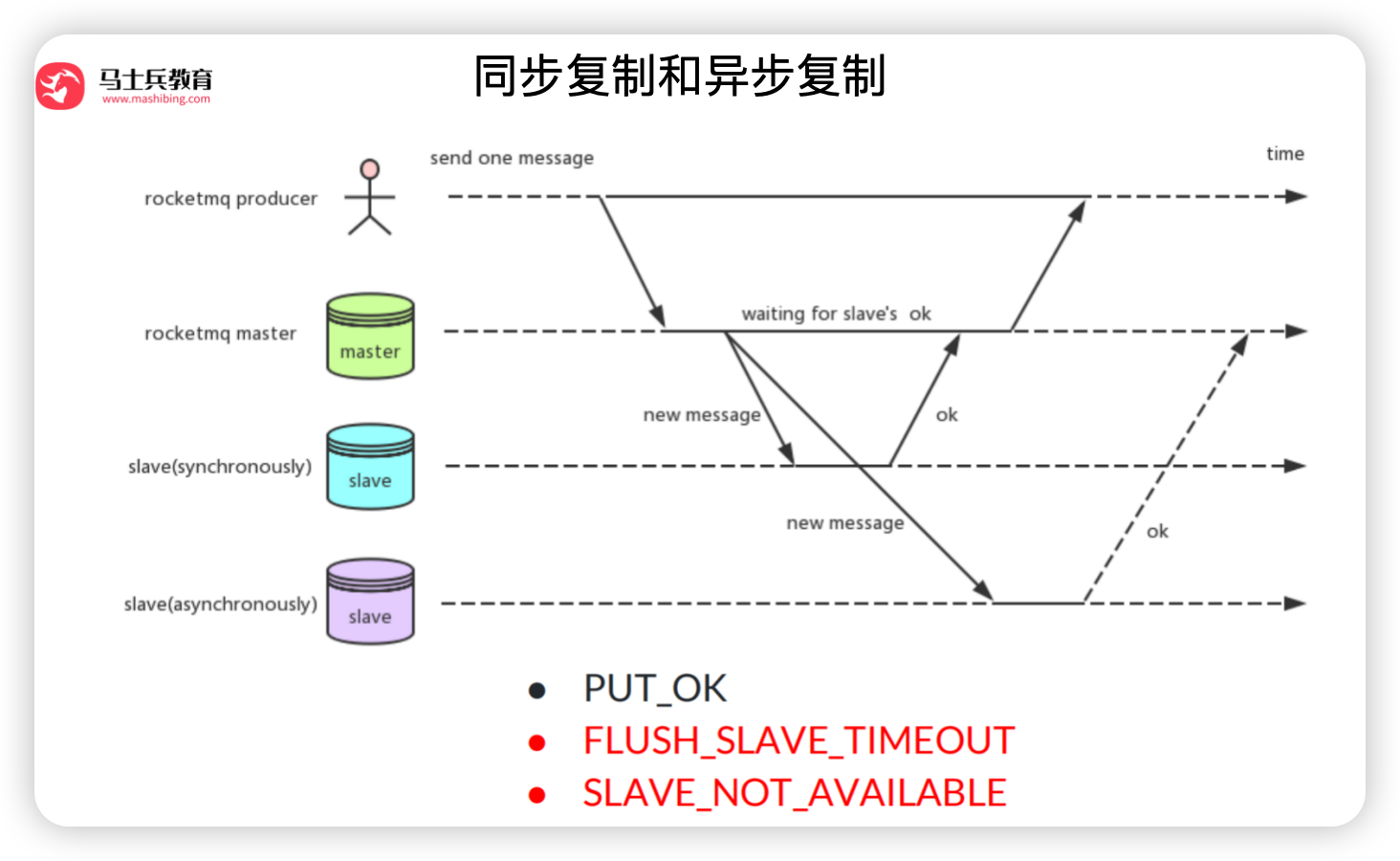
- 同步复制得等消息发送到slave节点才返回发送成功,异步不用把消息发送到slave就可以返回
- 主节点宕机后,可以从 从节点 消费数据 (确保发送的消息不丢)
- 提高性能
- 主要表现为slave可分担Master读的压力,当从Master拉取消息,拉取消息的最大物理偏移与本地存储的最大物理偏移的差值超过一定值,会转向Slave(默认brokerld=1)进行读取,减轻了Master压力,提高性能
- 主要表现为slave可分担Master读的压力,当从Master拉取消息,拉取消息的最大物理偏移与本地存储的最大物理偏移的差值超过一定值,会转向Slave(默认brokerld=1)进行读取,减轻了Master压力,提高性能
元数据复制
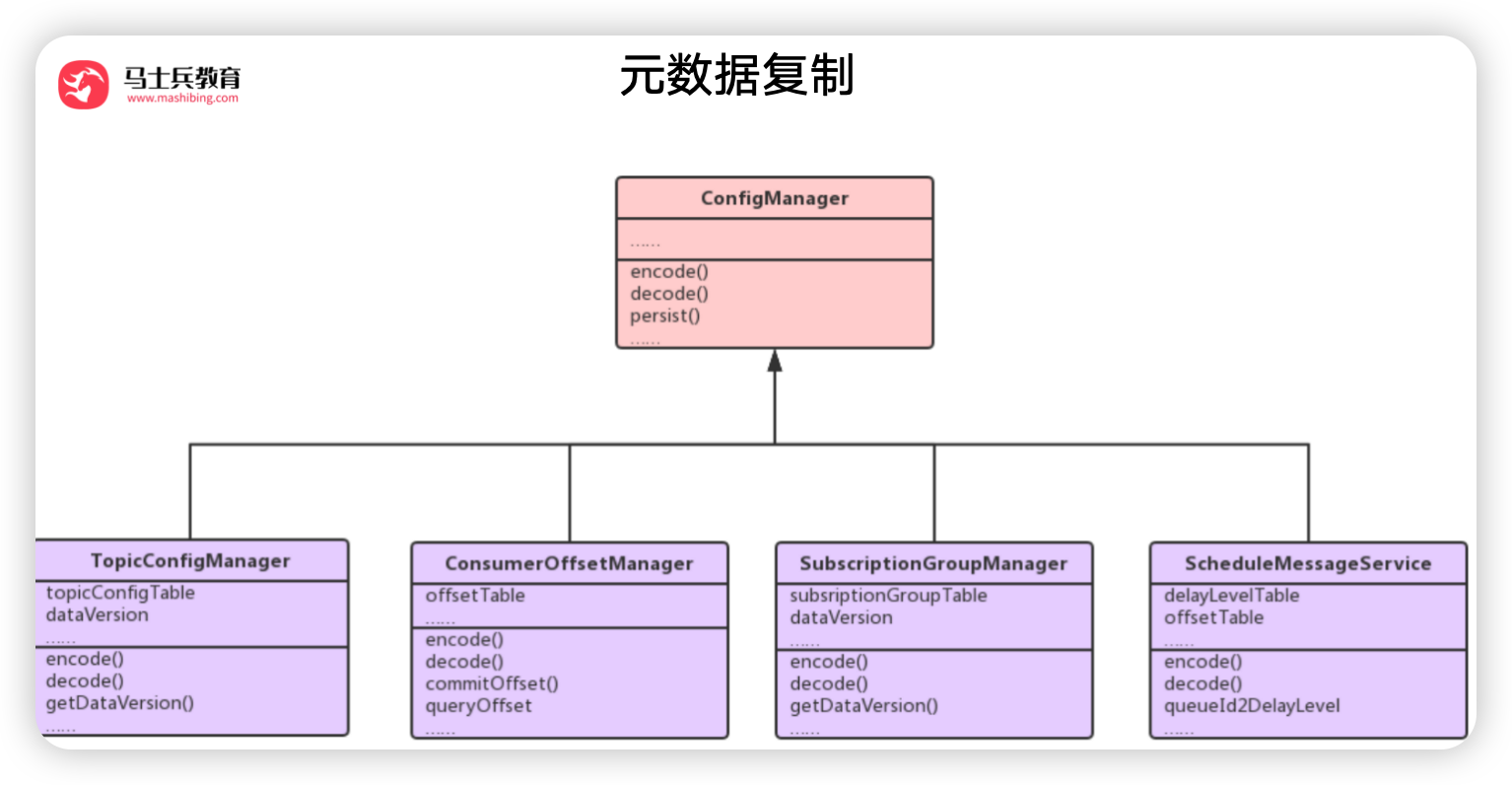
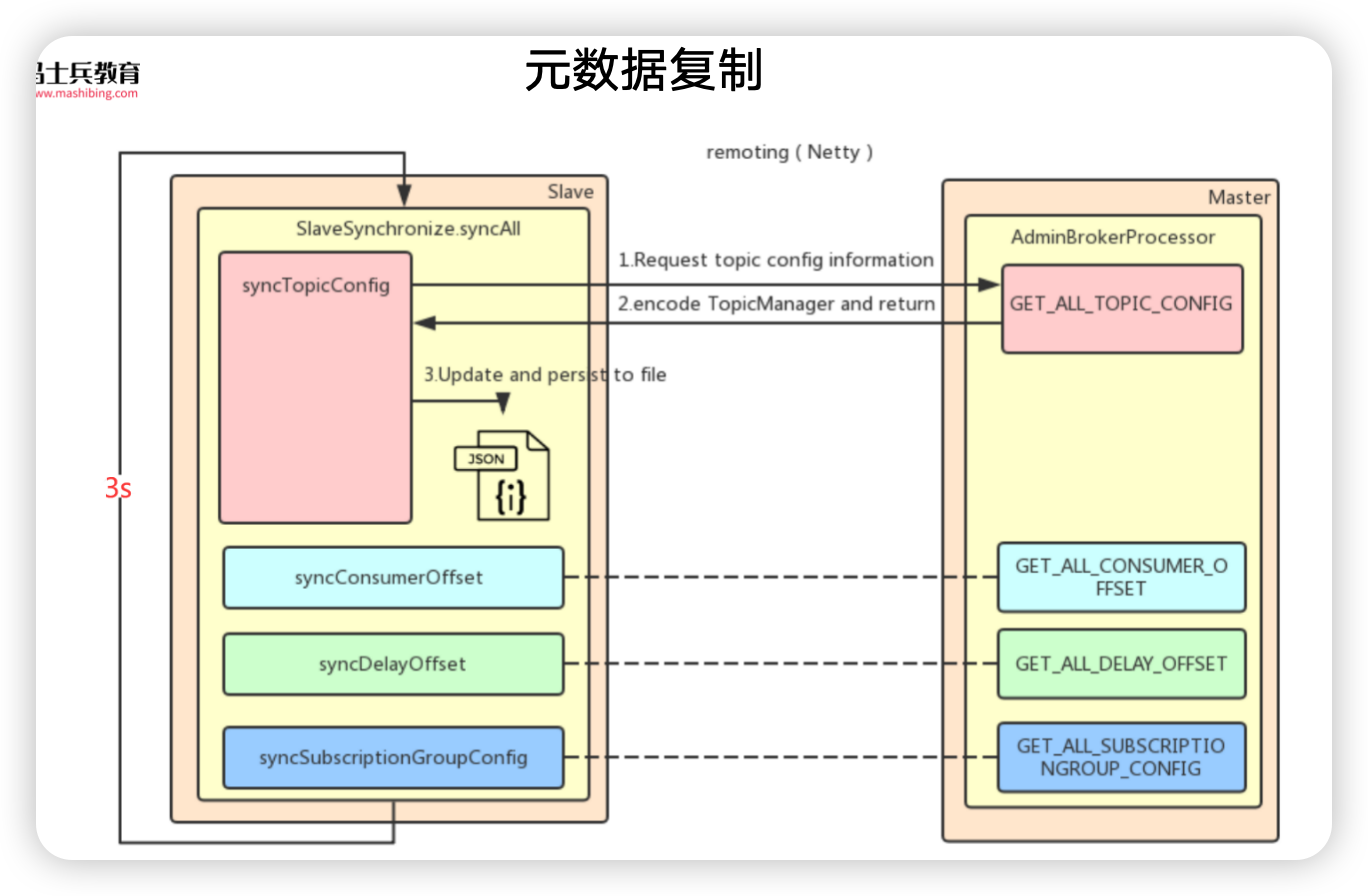
- BrokerController # 构造
- new TopicConfigManager …各种Manager
- BrokerController # initialize 初始化
- initializeScheduledTasks() 初始化定时任务
- initializeBrokerScheduledTasks() 初始化Broker定时任务
- if (BrokerRole.SLAVE == this.messageStoreConfig.getBrokerRole()) { 如果是从节点(从节点向主节点主动同步 topic 的路由信息、消费进度、延迟队列处理队列、消费组订阅配置等信息)
- this.scheduledExecutorService.scheduleAtFixedRate 定时任务线程池(开启定时同步任务,每 3s 从主节点同步一次元数据)
- BrokerController.this.getSlaveSynchronize().syncAll()
- SlaveSynchronize # syncAll
- this.syncTopicConfig(); 同步主题配置,从主节点获取所有主题配置信息,并在从节点更新主题配置。
- this.syncConsumerOffset(); 同步消费者偏移量,从主节点获取所有消费者的偏移量信息,并在从节点更新消费者偏移量。
- this.syncDelayOffset(); 同步延迟偏移量,从主节点获取所有延迟消息的偏移量信息,并在从节点更新延迟偏移量。
- this.syncSubscriptionGroupConfig(); 同步订阅组配置,从主节点获取所有订阅组配置信息,并在从节点更新订阅组配置。
- this.syncMessageRequestMode(); 同步消息请求模式
- SlaveSynchronize # syncTopicConfig
- String masterAddrBak = this.masterAddr 主节点的地址
- topicWrapper = this.brokerController.getBrokerOuterAPI().getAllTopicConfig(masterAddrBak) 远程调用,从master获取topic的信息
- request =RemotingCommand.createRequestCommand(RequestCode.GET_ALL_TOPIC_CONFIG 构建获取所有主题配置信息的请求
- this.remotingClient.invokeSync 调用netty获取数据
- brokerController.getTopicConfigManager().persist() 保存到本地
- MixAll.string2File(jsonString, fileName) 将数据写到本地文件
commitLog复制
- 流程总结:
- slave上报自己的偏移量
- master获取到slave上报的偏移量,更新自己维护的已经同步给slave的最大偏移量, 检测是否可以唤醒同步复制slave阻塞的发送线程
- master将commitLog从slave上报的偏移量开始拿到数据发送给slave
- slave接收到master发送的数据写到自己的磁盘CommitLog文件中
- slave将文件写入到CommitLog后会上报本地的偏移量
- 步骤
- Master写入CommitLog:
- 当Producer(生产者)发送消息到Master时,Master会先将消息写入到CommitLog文件中。
- 每条消息在CommitLog中都有一个唯一的偏移量(offset),这个偏移量标识了消息在CommitLog中的位置。
- Slave请求同步:
- Slave会定期向Master发送同步请求,请求同步Master上的CommitLog文件。
- 请求中通常会包含Slave当前已经同步到的CommitLog偏移量,这样Master就知道从哪里开始同步。
- Master响应同步请求:
- Master收到Slave的同步请求后,会根据Slave提供的偏移量,从CommitLog中读取相应的数据。
- Master将读取到的数据(包括消息内容和偏移量)发送给Slave。
- Slave接收并写入数据:
- Slave接收到Master发送的数据后,会将这些数据写入到自己的CommitLog文件中。
- Slave在写入数据时,会保持与Master相同的偏移量,以确保数据的一致性。
- 更新Slave的同步偏移量:
- Slave在成功写入数据后,会更新自己当前已经同步到的CommitLog偏移量。
- 这个偏移量会被用于下一次同步请求中,以便Master知道从哪里开始继续同步。
- 循环同步:
- Slave会不断重复上述同步过程,以保持与Master的数据一致。
- 如果Master上有新的消息写入CommitLog,Slave会在下一次同步请求中获取并同步这些新消息。
- Master写入CommitLog:
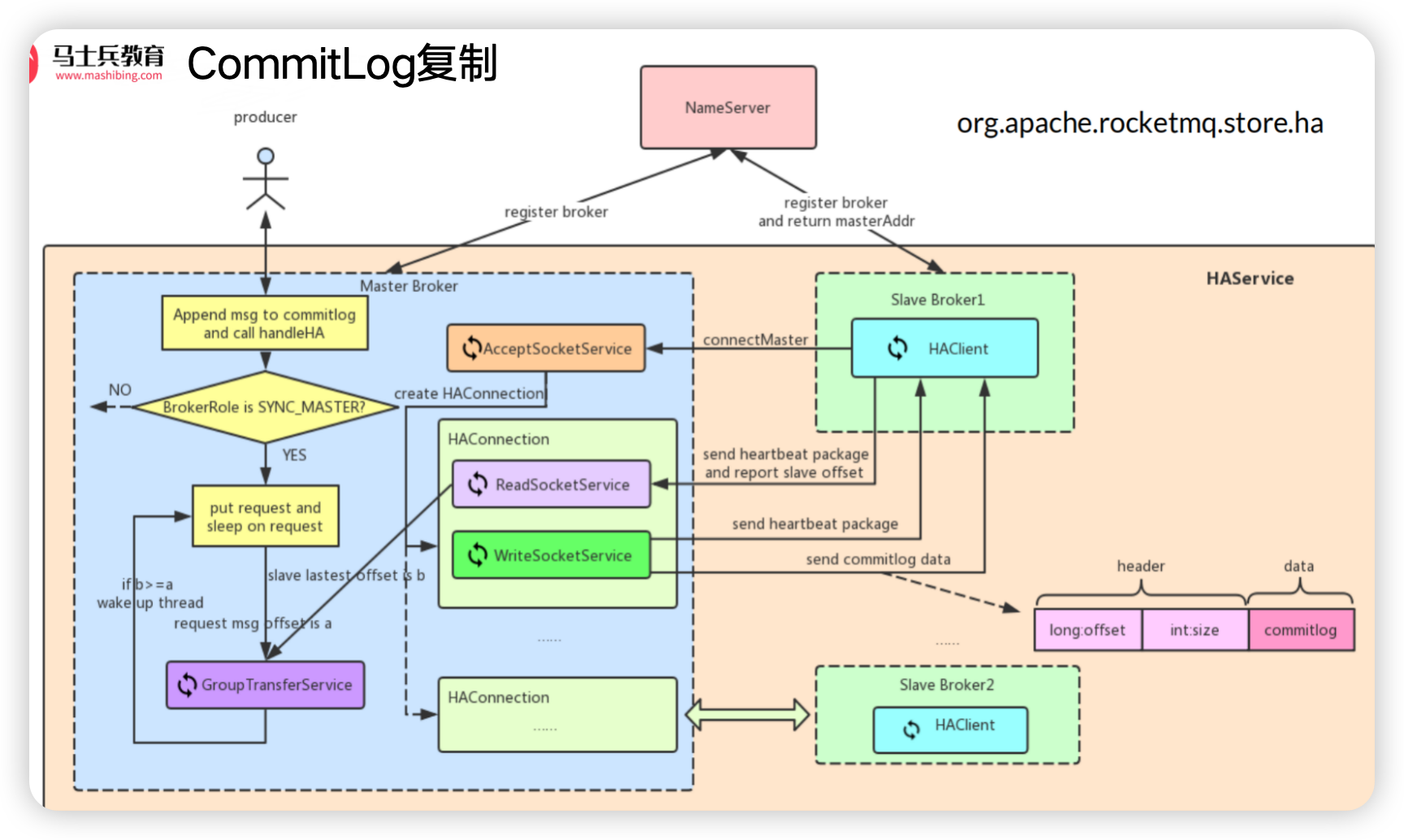
- 只要有CommitLog文件的复制,就可以通过从节点的定时任务生成consumequeue文件和indexFile文件
- 单独启动了自己的NIO框架,没有走Netty
- DefaultHAClient | DefaultHAService
- 同步的内容,消息在commitLog的偏移量,消息的大小,消息的内容
- DefaultMessageStore # start
- this.haService.init(this) 高可用(主从)初始化
- DefaultHAService # init
- this.acceptSocketService = new DefaultAcceptSocketService 接收socket请求的server
- this.groupTransferService = new GroupTransferService 服务端处理commitLog请求service
- this.defaultMessageStore.getMessageStoreConfig().getBrokerRole() == BrokerRole.SLAVE 如果是从节点
- int haListenPort = 10912 从节点高可用的端口
- this.haClient = new DefaultHAClient(this.defaultMessageStore) 创建DefaultHAClient
- 从节点启动后要做的工作:
- slave连接到master,向master上报当前的commitlog的offset
- master收到请求,确认有新的消息,给slave发送同步数据的开始位置
- master查询开始位置的commitlog发送到slave
- slave节点收到数据保存到自己的commitlog
- DefaultHAClient # run (只有从节点的启动才会创建DefaultHAClient)
- while (!this.isStopped()) { 一直循环执行
- case READY ==> this.connectMaster() 第一步, 建立与主的连接, 注册read事件, 连接master
- if (null == socketChannel) { 从节点第一次启动会去连接主节点(NIO selector去做的)
- String addr = this.masterHaAddress.get() 获取master的地址
- this.socketChannel = RemotingHelper.connect(socketAddress) 连接master
- sc = SocketChannel.open()
- sc.socket().connect(remote, timeoutMillis)
- this.changeCurrentState(HAConnectionState.TRANSFER) 修改当前的状态为TRANSFER
- this.socketChannel.register(this.selector, SelectionKey.OP_READ) 注册一个读事件
- this.currentReportedOffset = this.defaultMessageStore.getMaxPhyOffset() 从节点的当前的commitlog的偏移量
- case TRANSFER ==> transferFromMaster() 第二步, 进行数据传输, 响应read事件
- this.selector.select(1000); selector.select 阻塞, 通过后说明有数据了
this.selector.select方法的行为(阻塞还是非阻塞)取决于你调用它的方式。在Java NIO中,Selector类提供了几种选择(或“选择”)方法,这些方法允许你检查一个或多个NIO通道,并确定哪些通道已经准备好进行读取、写入等。- select():这是一个阻塞方法。它会阻塞调用线程,直到至少有一个通道在你注册的事件上就绪了。
- select(long timeout):这是一个带有超时机制的阻塞方法。它会阻塞调用线程,直到至少有一个通道在你注册的事件上就绪了,或者指定的超时时间到达。
- selectNow():这是一个非阻塞方法。它不会阻塞调用线程,而是立即返回。如果没有任何通道就绪,它将返回0。
- result = this.processReadEvent() 处理read事件(将master响应的commitlog中的数据写到磁盘)
- reportSlaveMaxOffsetPlus 上报从节点的最大偏移量到master
- this.selector.select(1000); selector.select 阻塞, 通过后说明有数据了
- DefaultHAClient # processReadEvent (slave端处理读事件)
- ByteBuffer byteBufferRead = ByteBuffer.allocate(READ_MAX_BUFFER_SIZE) read缓冲区
- while (this.byteBufferRead.hasRemaining()) {
- int readSize = this.socketChannel.read(this.byteBufferRead) 从socketChannel读取数据到Buffer
- boolean result = this.dispatchReadRequest()
- byte[] bodyData = byteBufferRead.array() 读取消息体数据
- this.defaultMessageStore.appendToCommitLog(masterPhyOffset, bodyData, dataStart, bodySize) 将消息追加到提交CommitLog日志中
- this.commitLog.appendData
- mappedFile.appendMessage 将CommitLog数据写入到mappedFile
- reportSlaveMaxOffsetPlus() 从节点重新上报自己的本地偏移量
- DefaultHAClient # reportSlaveMaxOffsetPlus 上报从节点的最大偏移量到master
- long currentPhyOffset = this.defaultMessageStore.getMaxPhyOffset() 拿到当前的最大偏移量
- result = this.reportSlaveMaxOffset(this.currentReportedOffset) 上报最大偏移量
- this.socketChannel.write(this.reportOffset) 这里就是建立连接之后 往主节点进行写请求(发送请求)
- DefaultHAService # beginAccept 构建socket服务端 (主节点和从节点启动都会创建DefaultHAService)
- ServerSocketChannel.open()
- this.serverSocketChannel.socket().setReuseAddress(true)
- serverSocketChannel.register(this.selector, SelectionKey.OP_ACCEPT)
- DefaultHAService # run
- this.selector.select(1000)
- Set selected = this.selector.selectedKeys()
- for (SelectionKey k : selected) {
- (k.readyOps() & SelectionKey.OP_ACCEPT) != 0 有连接事件
- HAConnection conn = createConnection(sc) 创建连接
- this.socketChannel = socketChannel
- writeSocketService = new WriteSocketService(this.socketChannel) 对应socket客户端写的service
- readSocketService = new ReadSocketService(this.socketChannel) 对应socket客户端读的service
- conn.start()
- DefaultHAConnection # start
- this.readSocketService.start()
- this.writeSocketService.start()
- DefaultHAConnection # start
- ReadSocketService # run master 接收到slave 的请求, 发送slave的最大偏移
- boolean ok = this.processReadEvent() 作用master同步复制slave时,复制动作是通过异步线程处理的,返回发送者的线程会被阻塞,当生产者接到slave上报最大偏移量的时候,判断当前维护的偏移量是否小于slave已经同步的偏移量,如果是,将master维护的偏移量变更为slave的最大偏移量,通过GroupTransferService 唤醒producer发送消息的线程,只对master同步复制slave有效
- DefaultHAConnection # processReadEvent (master端处理读事件)
- int readSize = this.socketChannel.read(this.byteBufferRead) 获取到slave端的数据
- long readOffset = this.byteBufferRead.getLong(pos - 8); 得到从节点更新过来的偏移量
- DefaultHAConnection.this.haService.notifyTransferSome(DefaultHAConnection.this.slaveAckOffset)
- offset > value slave本地的偏移量大于master维护的已经推送的偏移量
- boolean ok = this.push2SlaveMaxOffset.compareAndSet(value, offset) 将slave本地的偏移量设置到已经推送的最大偏移量,设置成功
- this.groupTransferService.notifyTransferSome() 唤醒同步复制slave阻塞的线程
- this.notifyTransferObject.wakeup()
- hasNotified.compareAndSet(false, true) 更新notifyTransferObject 中的hasNotified 为true
- WriteSocketService # run 这个线程会将master的commitLog文件发送给slave
- this.nextTransferFromWhere = DefaultHAConnection.this.slaveRequestOffset 偏移量为slave发送的偏移量,同步数据从slave发送的偏移量开始同步
- SelectMappedBufferResult selectResult = DefaultHAConnection.this.haService.getDefaultMessageStore().getCommitLogData(this.nextTransferFromWhere) 获取到对应nextTransferFromWhere commitLog的数据,放到SelectMappedBufferResult中
1. this.commitLog.getData(offset)
2. this.mappedFileQueue.findMappedFileByOffset(offset…) - this.lastWriteOver = this.transferData();
- while (this.byteBufferHeader.hasRemaining()) { 如果byteBufferHeader 头还有数据, 将头数据写到channel,响应到slave
- int writeSize = this.socketChannel.write(this.byteBufferHeader); 将头的信息响应给slave
- if (!this.byteBufferHeader.hasRemaining()) { 如果头中没有数据了
- while (this.selectMappedBufferResult.getByteBuffer().hasRemaining()) { selectMappedBufferResult.getByteBuffer() selectMappedBufferResult 获取到commitLog中消息体的buffer有数据
- int writeSize = this.socketChannel.write(this.selectMappedBufferResult.getByteBuffer()) 将消息体的信息发送给slave
- GroupTransferService # run
- 作用: 主从同步通知
- 阻塞与通知:当RocketMQ配置为主从同步模式时,消息发送者将消息刷写到磁盘后,需要等待新数据被传输到从服务器。从服务器数据的复制是在另一个线程中进行的,因此消息发送者需要等待数据传输的结果。
GroupTransferService负责在主从同步复制结束后通知那些由于等待HA(高可用)同步结果而阻塞的消息发送者线程。 - 同步判断与唤醒:判断主从同步是否完成的依据是从服务器(Slave)中已成功复制的最大偏移量是否大于等于消息生产者发送消息后消息服务端返回的下一条消息的起始偏移量。如果是,则表示主从同步复制已经完成,此时
GroupTransferService会唤醒消息发送线程;否则,它会等待一段时间(如1秒)后再次判断,这个过程会在一批任务中循环判断多次(如5次)。
- 阻塞与通知:当RocketMQ配置为主从同步模式时,消息发送者将消息刷写到磁盘后,需要等待新数据被传输到从服务器。从服务器数据的复制是在另一个线程中进行的,因此消息发送者需要等待数据传输的结果。
- this.doWaitTransfer() 等待同步
- for (CommitLog.GroupCommitRequest req : this.requestsRead) { 遍历请求读的请求
- this.notifyTransferObject.waitForRunning(1000) 等待同步完成
- if (this.hasNotified.compareAndSet(true, false)) { 将是否通知由true替换为flase
- this.onWaitEnd(); 执行master同步slave成功后的方法
- req.wakeupCustomer(transferOK ? PutMessageStatus.PUT_O …) 将阻塞的发送者唤醒
- CommitLog # asyncPutMessage
- handleDiskFlushAndHA 返回刷盘结果(如果需要同步复制的话,这个 方法)
- flushResultFuture = handleDiskFlush 这个方法里边判断是否同步刷盘
- if (!needHandleHA) { 是否需要同步复制
- needHandleHA 为false 如果不需要 ==> CompletableFuture.completedFuture(PutMessageStatus.PUT_OK) 直接返回结果
- else ==> 需要同步复制
- replicaResultFuture = handleHA(putMessageResult.getAppendMessageResult(), ) 如果是需要主从同步复制就进入这里
- HAService haService = this.defaultMessageStore.getHaService() 获取到HAService
- haService.putRequest(request) 将请求放到requestsWrite 队列,然后就可以唤醒阻塞的请求线程返回了
- this.groupTransferService.putRequest(request)
- List<CommitLog.GroupCommitRequest> requestsWrite
- this.requestsWrite.add(request) 将写请求的数据放到requestsWrite list中, 上边GroupTransferService 的run方法会遍历这个集合,如果master已经将数据同步到slave中,会执行onWaitEnd 方法
- this.groupTransferService.putRequest(request)
- master同步slave 同步复制
- 在RocketMQ中,即使配置了Master与Slave之间的同步复制方式,Master节点本身并不会直接等待Slave节点的同步完成
- 当生产者发送消息时,可以选择同步发送模式,并且可以设置相应的超时时间。在这种情况下,生产者会等待Master节点的响应,直到Master节点确认消息已经被写入并且(在同步复制的情况下)已经尝试同步到Slave节点(只是将同步的request写到了GroupTransferService 的requestsWrite 队列中)。
- “尝试同步”并不意味着Master节点会等待Slave节点的确认响应。相反,Master节点会将消息发送给Slave节点,并立即向生产者返回响应。如果Slave节点在后续时间内成功同步了消息,那么一切正常。如果Slave节点同步失败,RocketMQ提供了相应的补偿机制,比如通过定时任务来重试同步失败的消息。
消息消费总览
消费者启动源码
- DefaultMQPushConsumer # start
- setConsumerGroup(NamespaceUtil.wrapNamespace 设置消费者分组
- this.defaultMQPushConsumerImpl.start() consumerImpl # 开启
- this.mQClientFactory = MQClientManager.getInstance().getOrCreateMQClientInstance 创建一个MQClientInstance (消费者和生产者用的都是MQClientInstance), 要获取不同的MQClientInstance,要设置unitName不同
- RebalanceImpl rebalanceImpl = new RebalancePushImpl(this) 负载均衡实现
- this.pullAPIWrapper.registerFilterMessageHook(filterMessageHookList) 拉取消息的实现类
- this.consumeMessageService.start() 消费消息服务启动
- mQClientFactory.start() 启动
- this.mQClientAPIImpl.start() netty请求服务启动
- this.startScheduledTask() 这里会定时从nameserver中获取路由信息
- this.pullMessageService.start() 拉取消息服务 (利用线程开启的)
- this.rebalanceService.start() 负载均衡服务开启 (利用线程开启的)
- MessageListenerConcurrently 并发消费监听 | MessageListenerOrderly 顺序消费监听
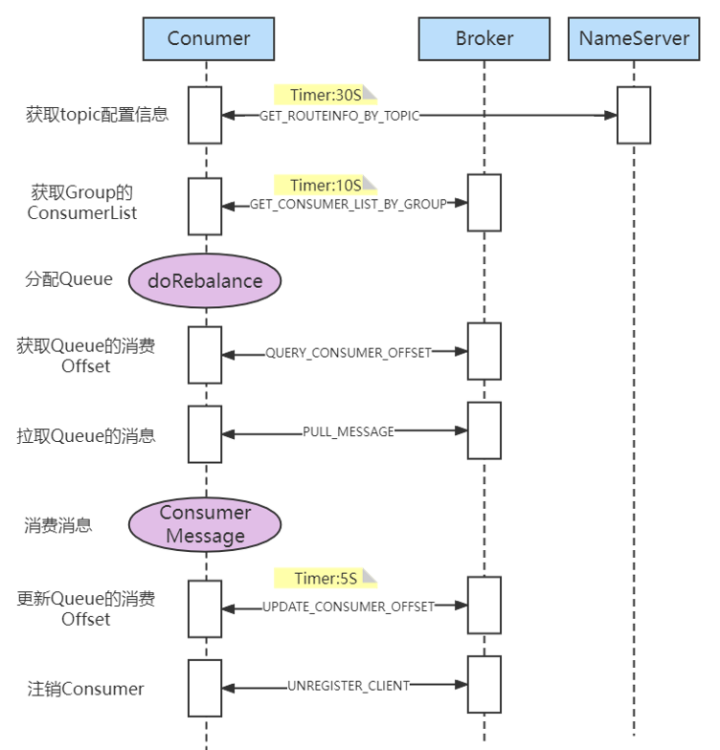
- 总结
- 获取topic配置信息 ===> 获取group的consumerList ===> 分配queue ===> 获取queue的消费offset ===> 拉取queue的消息 ===> 消费消息 ===> 更新queue的offset(持久化broker) ===> 注销consumer
消息消费源码
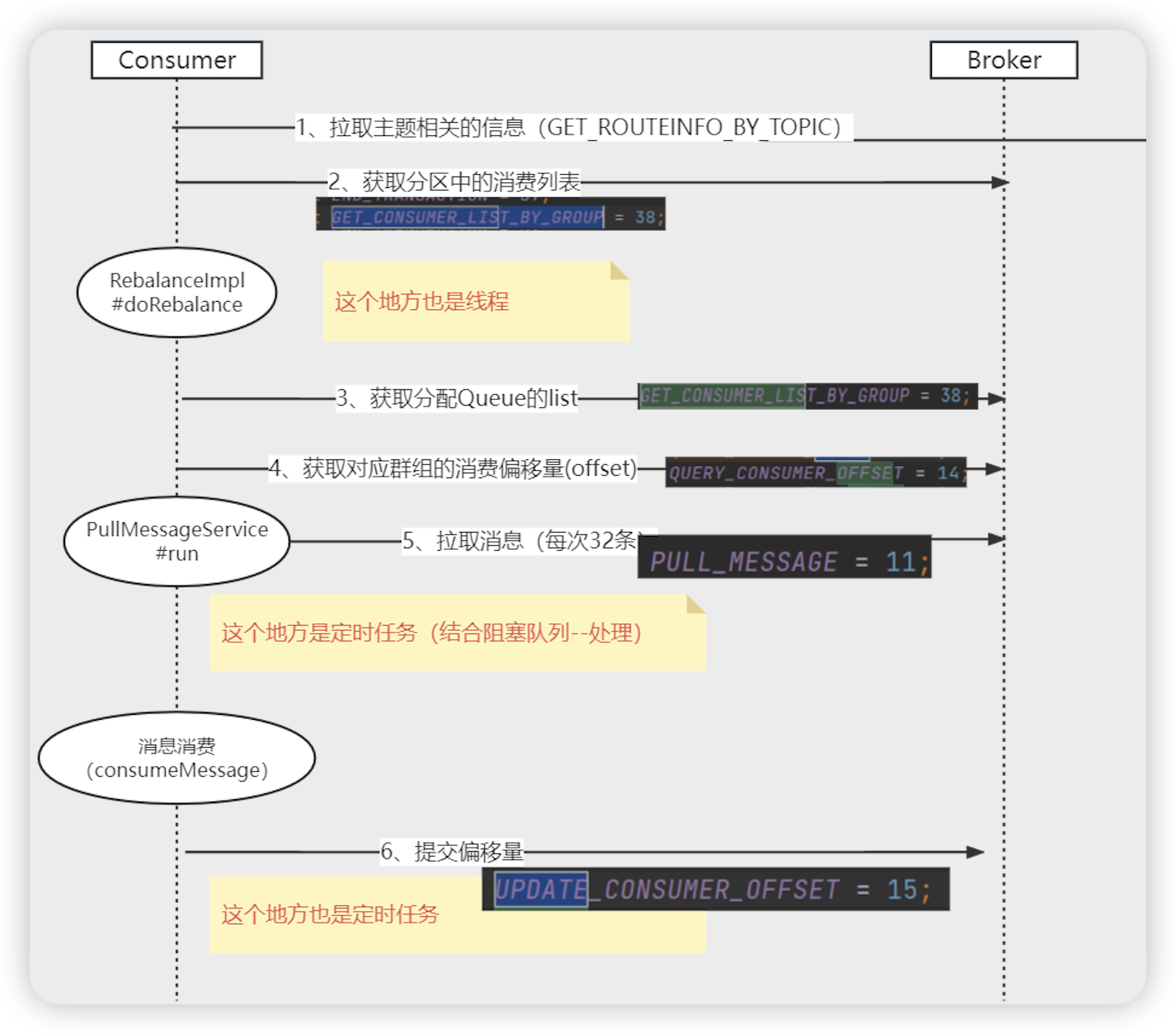
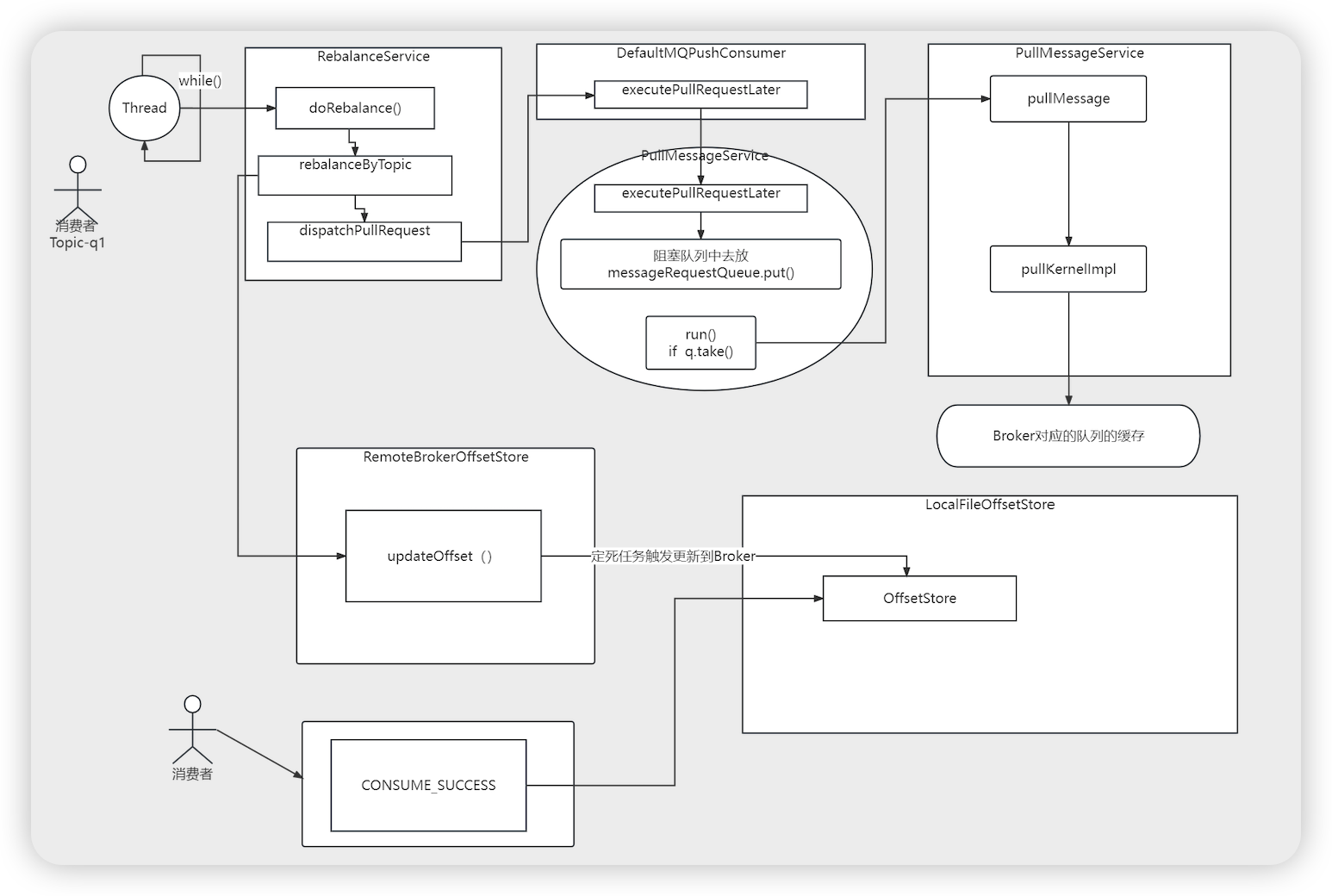
获取路由消息
- MQClientInstance # start
- this.startScheduledTask() 定时从nameserver中获取路由信息
- this.scheduledExecutorService.scheduleAtFixedRate ==> MQClientInstance.this.updateTopicRouteInfoFromNameServer() 定时获取路由信息
- MQClientAPIImpl # getTopicRouteInfoFromNameServer
- this.remotingClient.invokeSync 向NameServer获取路由信息
获取消费者集合(请求broker)
- RebalanceImpl # rebalanceByTopic 根据主题进行负载均衡选择队列
- Set mqSet = this.topicSubscribeInfoTable.get(topic) 拿到主题对应的队列信息
- List cidAll = this.mQClientFactory.findConsumerIdList(topic, consumerGroup) 获取到消费者组的列表
- String brokerAddr = this.findBrokerAddrByTopic(topic) 获取到broker的地址
- this.mQClientAPIImpl.getConsumerIdListByGroup(brokerAddr,group,clientConfig.getMqClientApiTimeout()) 利用netty请求broker获取到对应分组下的所有的消费者集合
- request = RemotingCommand.createRequestCommand(RequestCode.GET_CONSUMER_LIST_BY_GROUP, 构建根据group获取消费者的请求
- RemotingCommand response = this.remotingClient.invokeSync 通过netty调用broker
给消费者分配queue
- RebalanceService # run
- this.mqClientFactory.doRebalance()
- impl.doRebalance()
- DefaultMQPullConsumerImpl # doRebalance
- RebalanceImp # doRebalance
- balanced = this.rebalanceByTopic(topic, isOrder) 根据 topic负载均衡
- AllocateMessageQueueStrategy strategy = this.allocateMessageQueueStrategy 负载均衡的策略类
- allocateResult = strategy.allocate 分配一个queue (消费者分配queue消费)
消费者获取队列的消费偏移量
- DefaultMQPushConsumerImpl # pullMessage
- if (MessageModel.CLUSTERING == this.defaultMQPushConsumer.getMessageModel()) { 如果是集群模式
- commitOffsetValue = this.offsetStore.readOffset(pullRequest.getMessageQueue(), …) 获取消费队列的消费偏移量
- RemoteBrokeroffsetStore # readOffset
- long brokerOffset = this.fetchConsumeOffsetFromBroker(mq)
- this.mQClientFactory.getMQClientAPIImpl().queryConsumerOffset
- request = RemotingCommand.createRequestCommand(RequestCode.QUERY_CONSUMER_OFFSET, 构建查询队列消费偏移量的请求
- request = RemotingCommand.createRequestCommand(RequestCode.QUERY_CONSUMER_OFFSET, 构建查询队列消费偏移量的请求
消费者拉取消息
- ConsumeMessageOrderlyService # run 顺序消息service
- objLock = messageQueueLock.fetchLockObject(this.messageQueue) 进来的时候首先获取本地锁对象
- MessageModel.CLUSTERING.equals(ConsumeMessageOrderlyService 如果是集群消费
- 当消费者处理顺序消息时,RocketMQ会通过加锁来确保在同一时间内,一个队列中的消息只被一个线程处理,从而保持消息的消费顺序。这种加锁机制通常是在消费者端实现的,以确保消息按照进入队列的顺序被处理。
- ConsumeMessageOrderlyService # tryLockLaterAndReconsume 顺序消息每次消费的时候都尝试加锁
- 调用这个方法来尝试锁定这批消息所属的消息队列。如果锁定成功,消费者就可以继续处理这批消息;如果锁定失败,则可能需要等待或尝试处理其他消息。
- 涉及到与 Broker 的通信,以检查消息队列的锁定状态,并尝试获取锁。如果 Broker 允许锁定,那么消费者就可以开始处理消息;否则,消费者可能需要等待或尝试其他操作。
- ConsumeMessageOrderlyService.this.lockOneMQ(mq)
- this.defaultMQPushConsumerImpl.getRebalanceImpl().lock(mq)
- this.mQClientFactory.getMQClientAPIImpl().lockBatchMQ
- RemotingCommand.createRequestCommand(RequestCode.LOCK_BATCH_MQ, 发送加锁请求
- processQueue.setLocked(true); 设置加锁成功
- PullMessageService # run 拉取消息的开始
- LinkedBlockingQueue messageRequestQueue
- MessageRequest messageRequest = this.messageRequestQueue.take() 从阻塞队列中拿取数据,如果拿到数据,消费,如果拿不到数据会阻塞
- this.pullMessage((PullRequest)messageRequest) 拉取消息
- impl = (DefaultMQPushConsumerImpl) consumer
- impl.pullMessage(pullRequest)
- DefaultMQPushConsumerImpl # pullMessage
- processQueue = pullRequest.getProcessQueue()
- if (!this.consumeOrderly) { 如果不是顺序消息
- processQueue.setLocked(true);
- this.scheduledExecutorService.schedule(new Runnable() 执行定时任务
- PullMessageService.this.executePullRequestImmediately(pullRequest) 将拉取消息的任务放到队列中
- this.messageRequestQueue.put(pullRequest) 放到队列拉取消息请求
- processQueue.setLocked(true);
- else 如果是顺序消息
- if (processQueue.isLocked()) { 是否已经加锁了
- else ==> this.executePullRequestLater 过会消费
- this.pullAPIWrapper.pullKernelImpl
- new PullMessageRequestHeader() 创建拉取消息头
- this.mQClientFactory.getMQClientAPIImpl().pullMessage 拉取消息
- MQClientAPIImpl # pullMessage 拉取消息
- RemotingCommand.createRequestCommand(RequestCode.PULL_MESSAGE 拉取消息command

定时任务提交偏移量
- DefaultMQPushConsumerImpl # pullMessage
- new PullCallback() # onSuccess
- DefaultMQPushConsumerImpl.this.executeTaskLater
- mQClientFactory.getPullMessageService().executeTaskLater(r, timeDelay)
- scheduledExecutorService.schedule(r, timeDelay, TimeUnit.MILLISECONDS) 执行一个延迟的任务,延迟10000ms ,10s
- DefaultMQPushConsumerImpl.this.offsetStore.persist 持久化偏移量
- RemoteBrokerOffsetStore # persist
- this.updateConsumeOffsetToBroker(mq, offset.get())
- updateConsumeOffsetToBroker(mq, offset, true); 更新偏移量到broker
- this.mQClientFactory.getMQClientAPIImpl().updateConsumerOffsetOneway(
- request = RemotingCommand.createRequestCommand(RequestCode.UPDATE_CONSUMER_OFFSET 构建更新偏移量请求
- this.remotingClient.invokeOneway 通过netty发送请求到broker
rocketMq的消息推拉模式
- RocketMQ的消息推拉模式主要涉及消息的消费者(Consumer)如何从消息队列(Broker)中获取消息。虽然从命名上看,RocketMQ提供了PushConsumer(推消费者)和PullConsumer(拉消费者)两种接口,但实际上,RocketMQ主要基于拉模式(Pull Mode),而PushConsumer只是一种对拉模式的封装,实现了类似推模式(Push Mode)的效果。下面详细解释这两种模式:
- 拉模式(Pull Mode)
- 基本概念:在拉模式下,消费者主动向消息队列(Broker)发起请求,拉取消息进行消费。
- 工作流程:
- 请求消息:消费者根据自身需求,定时或按需向Broker发送拉取消息的请求。
- 获取消息:Broker根据请求返回消息给消费者。如果当前没有新消息,Broker可能会挂起请求,直到有新消息产生或达到超时时间。 (长轮询模式)
- 消费消息:消费者收到消息后进行业务处理。
- 确认消息:消费者处理完消息后,需要向Broker发送确认消息,告知已消费成功。
- 优点:
- 消费者可以根据自身处理能力控制拉取消息的频率和数量,避免消息积压。
- 消息拉取由消费者主动发起,减少了Broker的推送压力。
- 缺点:
- 如果拉取频率设置不当,可能会导致消息延迟或无效请求过多。
- 消费者需要实现复杂的拉取逻辑和错误处理机制。
- 推模式(Push Mode,实际上是封装的拉模式)
- 基本概念:RocketMQ的PushConsumer虽然名为“推”模式,但实际上是通过长轮询(Long Polling)的方式实现类似推送的效果。
- 工作流程:
- 流程: 消费者注册监听器,内部启动线程基于长轮询去拉取消息,返回结果有消息了,消费者触发监听器去broker真实拿取消息消费
- 注册监听器:消费者启动后,注册一个消息监听器(MessageListener),用于监听新消息的到来。
- 轮询拉取:消费者内部会开启一个线程(如PullMessageService),不断轮询Broker拉取消息。
- 消息推送:一旦拉取到消息,消费者内部会唤醒监听器,调用其consumeMessage方法处理消息,给用户一种消息被推送的错觉。
- 状态反馈:处理完消息后,消费者会向Broker发送消费状态反馈(如消费成功、消费失败等)。
- 优点:
- 对用户来说,实现简单,不需要关心消息拉取的具体逻辑。
- 消息消费可以认为是实时的,因为消费者内部通过长轮询实现了消息的快速响应。
- 缺点:
- 如果消费者处理消息的速度跟不上拉取速度,可能会导致消息积压甚至内存溢出。
- 需要消费者保证系统的稳定性和消费能力,以应对可能的消息洪峰。
- 总结
- RocketMQ的推拉模式各有优缺点,消费者在选择时需要根据自身的业务需求和系统能力进行权衡。一般来说,对于需要高实时性和低延迟的场景,可以考虑使用PushConsumer(实际上是封装的拉模式);而对于需要精确控制消息拉取频率和数量的场景,则可以考虑使用PullConsumer。
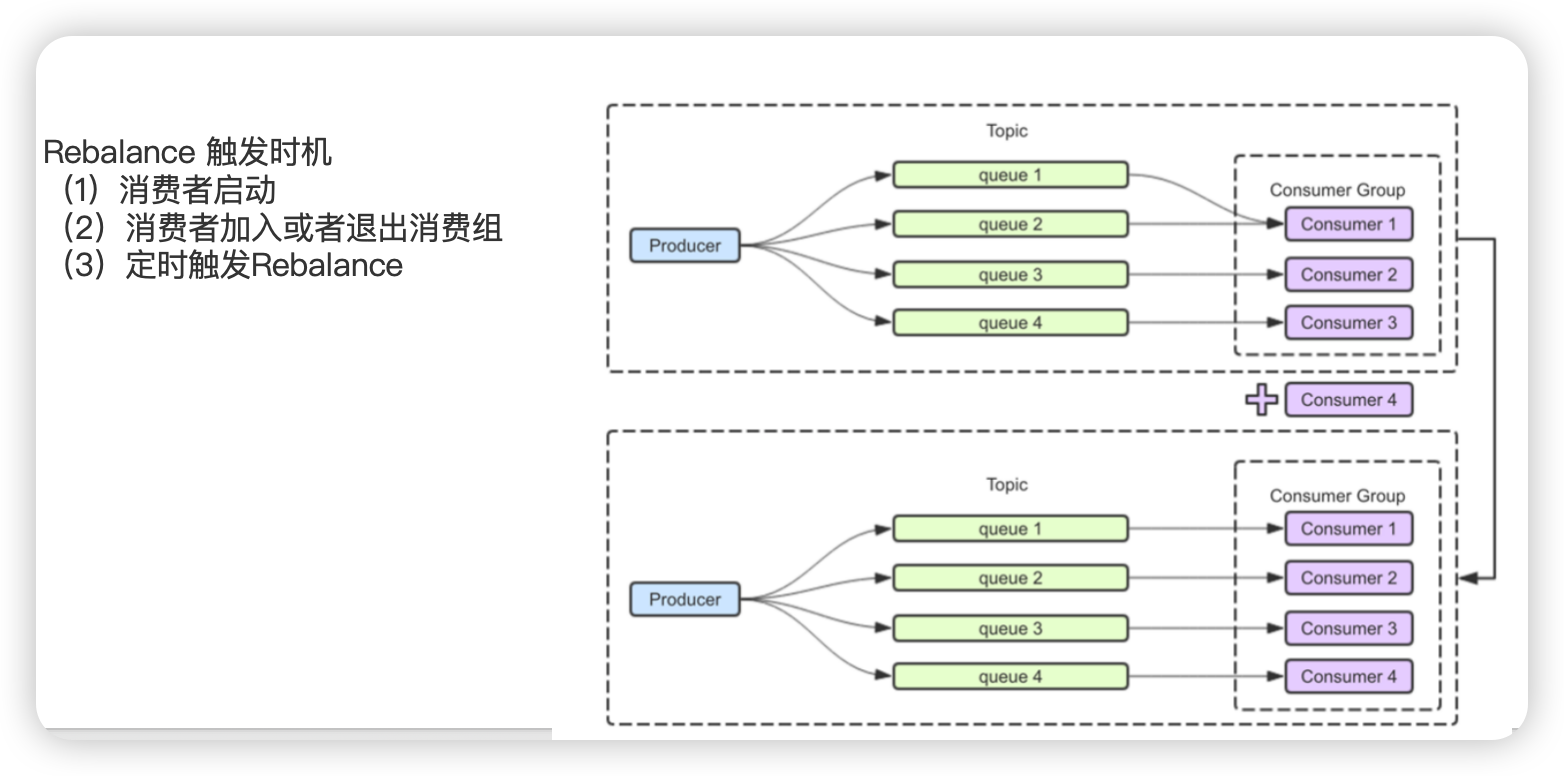
负载均衡(每隔20s执行一次) 消费者分配消费队列
- RebalanceService # run 这个是整个消费的开始
- while (!this.isStopped()) { 循环进行
- this.waitForRunning(waitInterval) waitInterval = 20s
- waitPoint.await(interval, TimeUnit.MILLISECONDS); 阻塞
- this.mqClientFactory.doRebalance()
- MQClientInstance # doRebalance ==> impl.doRebalance()
- DefaultMQPushConsumerImpl # doRebalance
- RebalanceImpl # doRebalance ==> this.rebalanceByTopic(topic, isOrder) topic负载均衡
- case CLUSTERING: { 集群模式
- Set mqSet = this.topicSubscribeInfoTable.get(topic) 队列集合
- AllocateMessageQueueStrategy strategy = this.allocateMessageQueueStrategy 负载均衡策略
- allocateResult = strategy.allocate( 分配一个队列
- allocateResultSet.addAll(allocateResult) 将分配结果放到allocateResultSet 集合中
- boolean changed = this.updateProcessQueueTableInRebalance 更新负载均衡结果
- List pullRequestList = new ArrayList<>() 封装为PullRequest
- this.dispatchPullRequest(pullRequestList, 500) 分配拉取请求
- RebalancePushImpl # dispatchPullRequest
- this.defaultMQPushConsumerImpl.executePullRequestLater 执行拉取消息请求
- this.mQClientFactory.getPullMessageService().executePullRequestLater
- PullMessageService # executePullRequestLater
- this.scheduledExecutorService.schedule 定时任务线程池执行任务
- PullMessageService.this.executePullRequestImmediately(pullRequest)
- this.messageRequestQueue.put(pullRequest) 往请求队列中方请求和上边的take方法对应
- PullMessageService # run
- MessageRequest messageRequest = this.messageRequestQueue.take()
- this.pullMessage((PullRequest)messageRequest)
- DefaultMQPushConsumerImpl # pullMessage
- PullCallback pullCallback = new PullCallback() ==> onSuccess 回调方法
- DefaultMQPushConsumerImpl.this.consumeMessageService.submitConsumeRequest( 处理自定义的消费逻辑
- ConsumeMessageConcurrentlyService # submitConsumeRequest
- final int consumeBatchSize = this.defaultMQPushConsumer.getConsumeMessageBatchMaxSize() 获取拉取到消息的数量
- ConsumeRequest consumeRequest = new ConsumeRequest(msgThis, processQueue, messageQueue) 构建消费请求
- this.consumeExecutor.submit(consumeRequest) 线程池执行消费请求
- ConsumeRequest # run
- MessageListenerConcurrently listener = ConsumeMessageConcurrentlyService.this.messageListener 获取到监听器
- status = listener.consumeMessage(Collections.unmodifiableList(msgs), context) 执行监听器的方法,即自定义的消费方法
- ConsumeMessageConcurrentlyService.this.processConsumeResult(status, context, this) 处理消费返回结果
- this.defaultMQPushConsumerImpl.getOffsetStore().updateOffset(consumeRequest.getMessageQueue() 消费完毕提交偏移量
- RemoteBrokeroffsetStore # updateOffset
- ConcurrentMap<MessageQueue, AtomicLong> offsetTable 队列,偏移量缓存
- this.offsetTable.putIfAbsent(mq, new AtomicLong(offset)) 将偏移量放到缓存中
- MQClientInstance # startScheduledTask 开启定时任务, 将放到缓冲中的偏移量提交到broker
- MQClientInstance.this.persistAllConsumerOffset()
- impl.persistConsumerOffset()
- DefaultMQPushConsumerImpl # persistConsumerOffset
- this.offsetStore.persistAll(mqs) 持久化所有的偏移量
- RemoteBrokerOffsetStore # persistAll
- for (Map.Entry<MessageQueue, AtomicLong> entry : this.offsetTable.entrySet()) { 遍历offsetTable 缓存map
- this.updateConsumeOffsetToBroker(mq, offset.get())
- this.mQClientFactory.getMQClientAPIImpl().updateConsumerOffset( 调用netty同步偏移量
- this.pullAPIWrapper.pullKernelImpl( 拉取消息,每次拉取32条
- PullAPIWrapper # pullKernelImpl
- case ASYNC: 异步消费
- this.pullMessageAsync(addr, request, timeoutMillis, pullCallback)
- this.remotingClient.invokeAsync(addr, request, timeoutMillis, 回调函数) 调用netty拉取消息
- 回调函数 ==> operationComplete
- PullResult pullResult = MQClientAPIImpl.this.processPullResponse(response, addr) 处理 拉取消息
- pullCallback.onSuccess(pullResult) 执行callBack函数的方法
- this.pullMessageAsync(addr, request, timeoutMillis, pullCallback)
- case SYNC: 同步消费
- this.pullMessageSync(addr, request, timeoutMillis)
- RemotingCommand response = this.remotingClient.invokeSync(addr, request, timeoutMillis) 执行拉取消息
- this.processPullResponse(response, addr) 处理响应
- this.pullMessageSync(addr, request, timeoutMillis)
- case ASYNC: 异步消费
消息重试 定时 过滤
重试
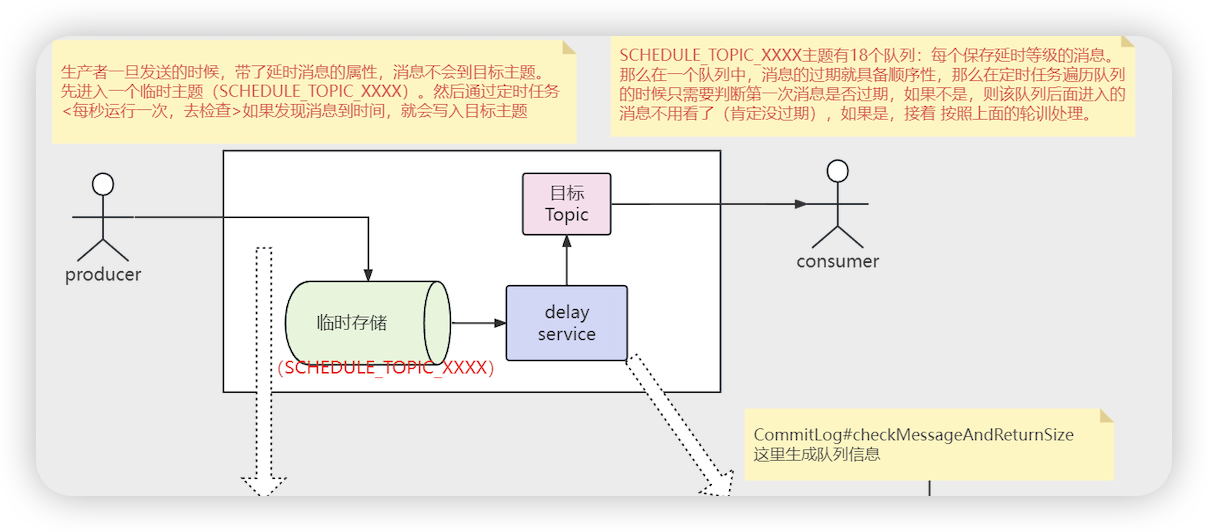
- 消费者消费的主题出了原来的主题,还会消费一个 %RETRY%消费者群组名称 的主题,消费重试后, 原来的消息会被提交, 消息进入 %RETRY%消费者群组名称 主题之前会先进入 SCHEDULE_TOPIC_XXXX的主题中,里边会有定时任务执行
- 超过重试次数,消息会放入 %DLQ%消费者群组名称 的主题中
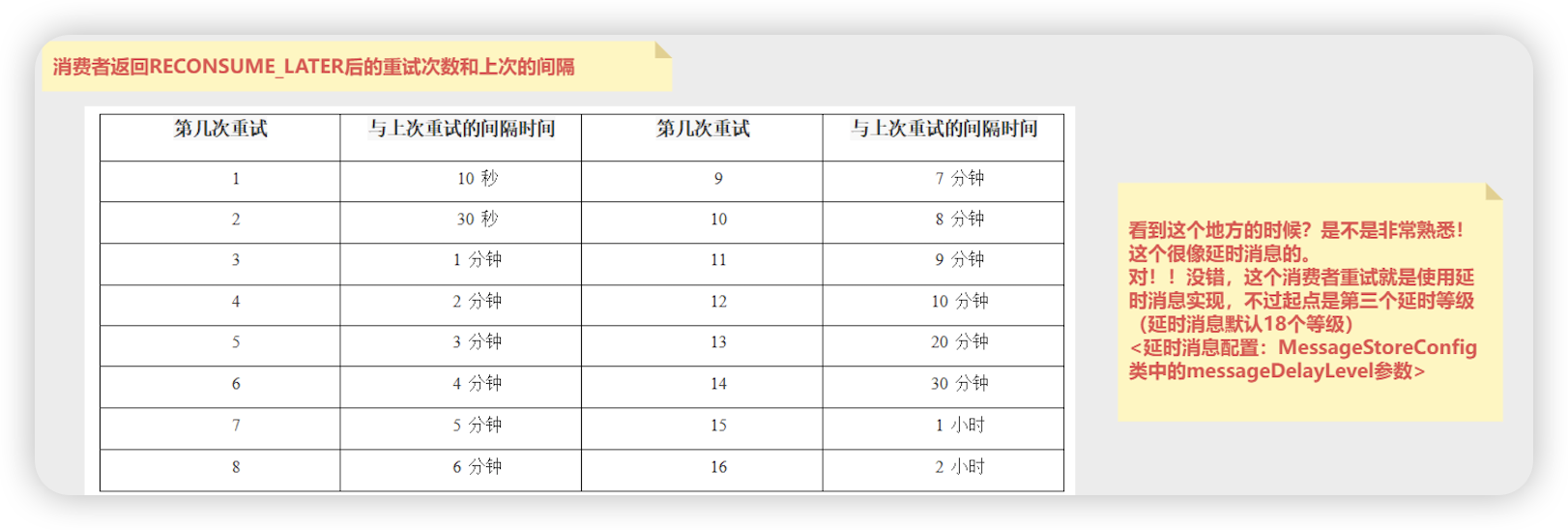
- 重试消息没有延时消息的第一个和第二个等级 (1s 5s)
- 消息重试是消息乱序的主要原因
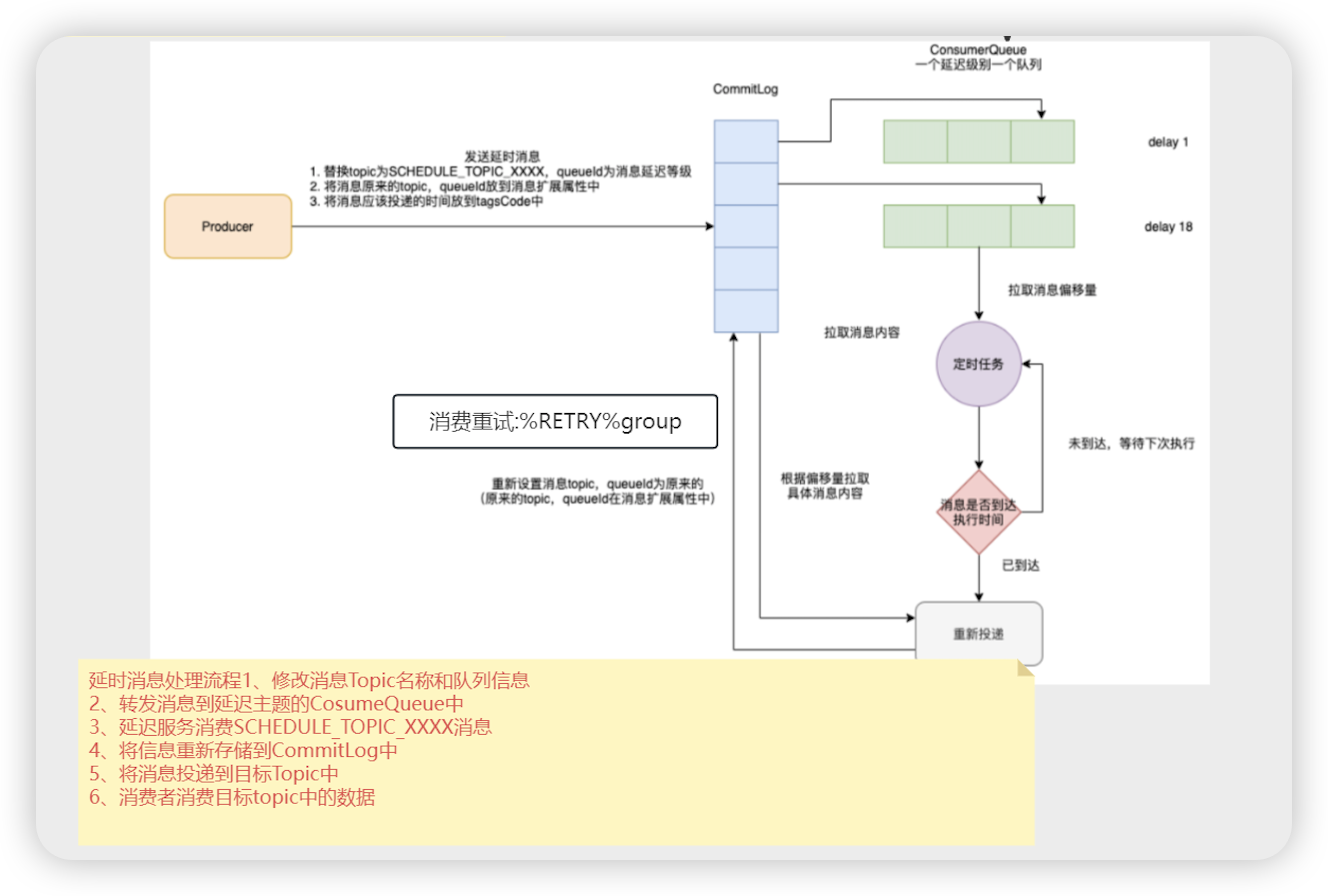
- 消息的重试本质是定时消息
- 定时消息和延时消息最后都会投递到 %RETRY%消费者组名 的主题
源码
- ConsumeMessageConcurrentlyService # submitConsumeRequest
- ConsumeRequest consumeRequest = new ConsumeRequest
- ConsumeRequest # run
- status = listener.consumeMessage(Collections.unmodifiableList(msgs), context)
- ConsumeMessageConcurrentlyService.this.processConsumeResult(status
- ConsumeMessageConcurrentlyService # processConsumeResult
- switch (this.defaultMQPushConsumer.getMessageModel()) { ==> case CLUSTERING 如果消费模式时集群消费
- for (int i = ackIndex + 1; i < consumeRequest.getMsgs().size(); i++) { 消费成功索引
ackIndex之后还有剩余消息未处理时,这些消息会被认为是消费失败的 - boolean result = this.sendMessageBack(msg, context) 消费者向broker重新投递消费失败的消息,为了下次重试
- this.defaultMQPushConsumerImpl.sendMessageBack(msg, delayLevel,
- DefaultMQPushConsumerImpl # sendMessageBack
- this.mQClientFactory.getMQClientAPIImpl().consumerSendMessageBack(brokerAddr
- request = RemotingCommand.createRequestCommand(RequestCode.CONSUMER_SEND_MSG_BACK 构建消息回退请求
- SendMessageProcessor # processRequest Broker接收消息的入口(生产者发送的消息到了Broker就会进入这里) broker处理重试消息的请求
- switch (request.getCode()) { ==> case RequestCode.CONSUMER_SEND_MSG_BACK 如果code时消费者发送消息回退
- this.consumerSendMsgBack(ctx, request)
- MessageAccessor.putProperty(msgExt, MessageConst.PROPERTY_RETRY_TOPIC, msgExt.getTopic()); 将原来的主题内容设置到新主题的property中,记录原来的主题
- String newTopic = MixAll.getRetryTopic(requestHeader.getGroup()) 构建 重试topic名称
- RETRY_GROUP_TOPIC_PREFIX + consumerGroup 重试前缀 + 消费者组名称
- int delayLevel = requestHeader.getDelayLevel() 获取延时等级
- if (msgExt.getReconsumeTimes() >= maxReconsumeTimes 如果消费的次数 >最大重试次数, 死信队列的处理
- newTopic = MixAll.getDLQTopic(requestHeader.getGroup())
- DLQ_GROUP_TOPIC_PREFIX + consumerGroup 死信前缀 + 消费者组名称
- newTopic = MixAll.getDLQTopic(requestHeader.getGroup())
- if (0 == delayLevel) { 如果第一次进来重试
- delayLevel = 3 + msgExt.getReconsumeTimes() 重试队列初始的延时等级为3级别
- msgInner = new MessageExtBrokerInner() 构建msgInner
- msgInner.setTopic(newTopic) 设置新的主题
- masterBroker.getMessageStore().putMessage(msgInner) 将新主题的信息进行保存
- BrokerController # initialize 将延时消息放到 SCHEDULE_TOPIC_XXXX 主题,注册钩子函数,保存消息之前的函数
- registerMessageStoreHook() 注册钩子函数
- handleScheduleMessage ==> HookUtils.handleScheduleMessage(BrokerController.this, (MessageExtBrokerInner) msg) 转为延时消息为定时消息
- if (msg.getDelayTimeLevel() > 0) { 如果消息的延时等级大于0
- transformDelayLevelMessage(brokerController, msg) 转换延时消息
- putProperty(msg, MessageConst.PROPERTY_REAL_TOPIC, msg.getTopic()) 设置属性 REAL_TOPIC 真实的主题
- msg.setTopic(TopicValidator.RMQ_SYS_SCHEDULE_TOPIC) 设置主题 SCHEDULE_TOPIC_XXXX
- SCHEDULE_TOPIC_XXXX 主题
- 这个主题一共有18个队列,一个队列对应一个延时等级,一个队列上对应一个定时任务
- 延时消息和重试消息的区别
- 延时消息先放在SCHEDULE_TOPIC_XXXX 主题中,定时任务捞取到会将消息重新投递到commitlog的主题中
- 重试消息定时任务捞取到,会将消息投递到 %RETRY%消费者组 的主题中
- BrokerController # 构造 处理定时消息服务处理
- new ScheduleMessageService
- BrokerController # start
- changeSpecialServiceStatus ==> changeScheduleServiceStatus(shouldStart) ==>this.scheduleMessageService.start()
- ConcurrentMap<Integer /* level /, Long/ delay timeMillis */> delayLevelTable 延时消息缓存
- for (Map.Entry<Integer, Long> entry : this.delayLevelTable.entrySet()) { 遍历延时消息缓冲map
- this.deliverExecutorService.schedule(new DeliverDelayedMessageTimerTask(level, offset), FIRST_DELAY_TIME, 启动一个延时任务
- DeliverDelayedMessageTimerTask # run
- this.executeOnTimeup()
- ScheduleMessageService.this.brokerController.getMessageStore().getConsumeQueue(TopicValidator.RMQ_SYS_SCHEDULE_TOPIC, delayLevel2QueueId(delayLevel)); 获取定时主题某个队列对应的消息
- TopicValidator.RMQ_SYS_SCHEDULE_TOPIC ==> SCHEDULE_TOPIC_XXXX
- delayLevel2QueueId(delayLevel) ==> 延时等级对应的主题中的队列
- if (cq == null) { 如果没有新的数据
- this.scheduleNextTimerTask(this.offset, DELAY_FOR_A_WHILE)
- ScheduleMessageService.this.deliverExecutorService.schedule(new DeliverDelayedMessageTimerTask(this.delayLevel, offset), delay, TimeUnit.MILLISECONDS) 执行下一次的延时任务
- long countdown = deliverTimestamp - now 投递的时间和当前的时间相减
- if (countdown > 0) { ==> this.scheduleNextTimerTask(currOffset, DELAY_FOR_A_WHILE) 如果大于0,开始下一次的延时任务
- MessageExt msgExt = ScheduleMessageService.this.brokerController.getMessageStore() 得到消息的内容
- msgInner = ScheduleMessageService.this.messageTimeup(msgExt) 构建MsgInner
- msgInner.setTopic(msgInner.getProperty(MessageConst.PROPERTY_REAL_TOPIC)); 恢复消息主题
- msgInner.getProperty(MessageConst.PROPERTY_REAL_TOPIC) 从之前设置的属性中获取REAL_TOPIC
- deliverSuc = this.syncDeliver(msgInner, msgExt.getMsgId()…) 进行消息的投递
- deliverMessage(msgInner, msgId, offset, offsetPy, sizePy, false) 投递消息
- brokerController.getEscapeBridge().asyncPutMessage(msgInner)
- this.brokerController.getBrokerOuterAPI().sendMessageToSpecificBrokerAsync
- buildSendMessageRequest(msg, group)
- request = RemotingCommand.createRequestCommand(RequestCode.SEND_MESSAGE_V2 构建发送消息的请求
- this.remotingClient.invokeAsync 利用netty发送请求
- ScheduleMessageService # load
- this.parseDelayLevel() 解析延时等级
- String levelString = this.brokerController.getMessageStoreConfig().getMessageDelayLevel() 获取延时等级字符串
- String messageDelayLevel = “1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h” 延时消息等级
- this.delayLevelTable.put(level, delayTimeMillis) 将解析出来的等级放到缓存map中
- rocketMq将不同等级的延时消息放到不同队列的好处
- 不同队列方式:
- 高效排序:由于每个队列只包含特定延时等级的消息,这些消息在队列内部自然按照发送时间排序,无需额外排序算法。
- 快速检索:定时任务只需要扫描当前时间点应该被处理的队列,无需遍历整个消息集合,大大提高了检索效率。 只需要扫描前边的消息,如果发现一个消息没有过期,后边的消息不用处理了
- 单队列方式:
- 复杂排序:所有消息混合存储在一个队列中,需要额外的排序算法来确保消息按延时时间排序,增加了处理复杂度和时间开销。
- 低效检索:定时任务需要遍历整个队列来查找可处理的消息,随着消息量的增加,检索效率会显著下降。
- 消费者订阅重试主题
- DefaultMQPushConsumerImpl # start
- this.copySubscription()
- final String retryTopic = MixAll.getRetryTopic(this.defaultMQPushConsumer.getConsumerGroup()) 获取重试主题
- RETRY_GROUP_TOPIC_PREFIX + consumerGroup 前缀+消费者组
- this.rebalanceImpl.getSubscriptionInner().put(retryTopic, subscriptionData) 将订阅关系放到map缓存中
消费过滤
- 消费过滤,会把所有的消费偏移量提交,消费过滤是在消费者端处理
- DefaultMessageStore # getMessage
- ConsumeQueueInterface consumeQueue = findConsumeQueue(topic, queueId) 获取consumequeue
- while (bufferConsumeQueue.hasNext() 遍历消费的消息
- messageFilter.isMatchedByConsumeQueue(cqUnit.getValidTagsCodeAsLong() 过滤消息
- DefaultMessageFilter # isMatchedByConsumeQueue 表达式过滤
- subscriptionData.getSubString().equals(SubscriptionData.SUB_ALL) 判断配置的是否为 *
- subscriptionData.getCodeSet().contains(tagsCode.intValue() 匹配是否包含tag
- ExpressionMessageFilter # isMatchedByConsumeQueue sql 过滤
- status = GetMessageStatus.NO_MATCHED_MESSAGE; ==> continue 消息没有匹配到跳过这次while循环
流处理与性能调优
流处理
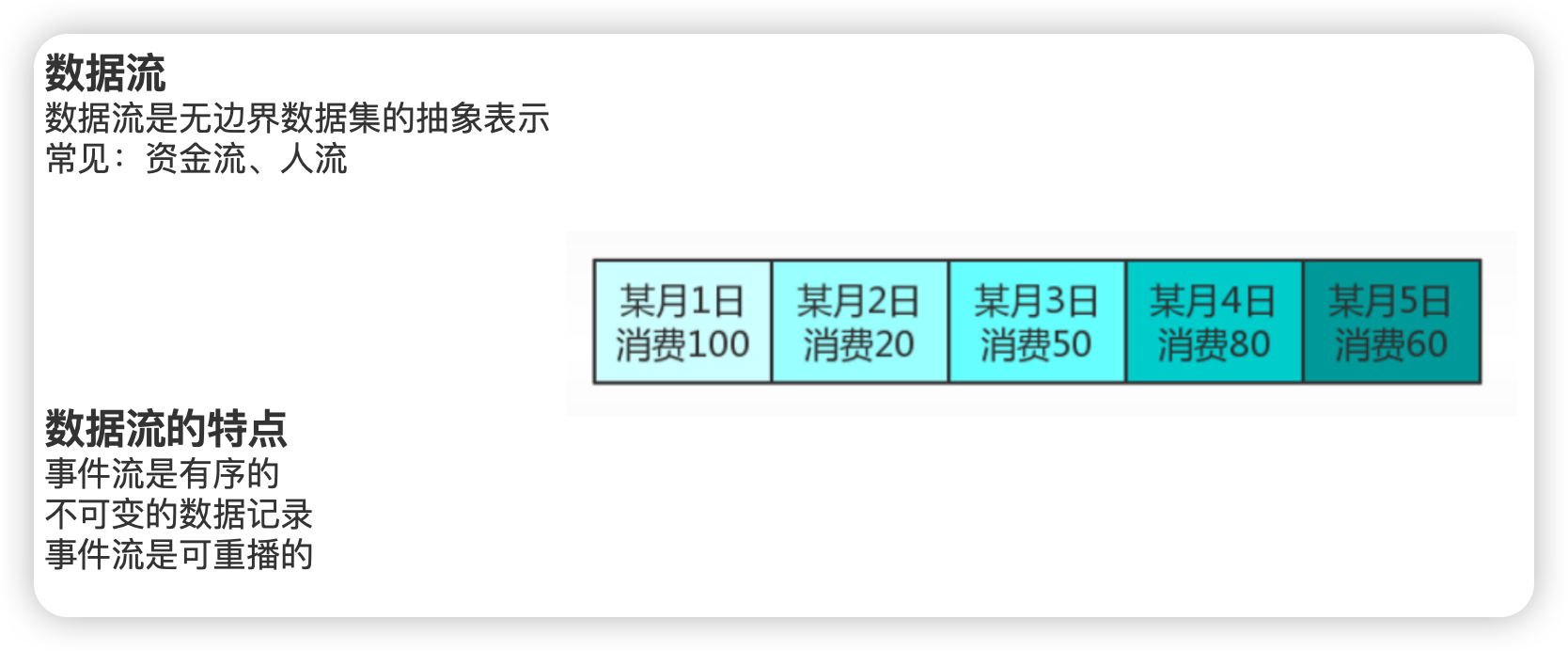
- 流的概念
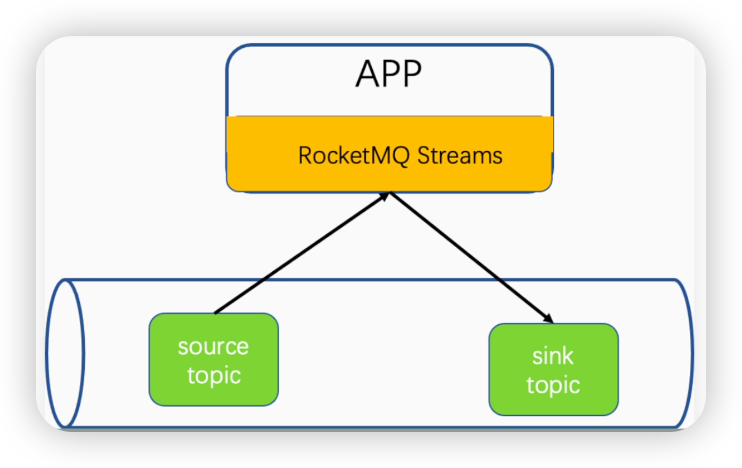
- 流处理事单独的app
- 流的数据来源和输出为mq的主题
- 使用流处理的原因
- 利用流数据进行统计
- 大厂中的应用的数据异构(高并发系统中,数据一般是先落地到MQ<Kafka、RocketMQ>异步方式批量同步到数据库
- 数据库的统计功能比较弱
//运用RocketMQ Stream,将一个消息主题("sell")的消息复制到另一个主题("sell-2")
public class StreamCopy {
public static void main(String[] args) {
//构建流处理实例:一个JobId对应一个StreamBuilder实例
StreamBuilder builder = new StreamBuilder("StreamCopy-2");
//定义source topic 和反序列化方式
builder.source("sell", total -> { //total 参数表示消息的总体内容
String value = new String(total, StandardCharsets.UTF_8);
return new Pair<>(null, value);
})
//sink方法:将结果输出到特定topic
.sink("sell-2", new KeyValueSerializer<Object, String>() {
final ObjectMapper objectMapper = new ObjectMapper();
@Override
public byte[] serialize(Object o, String data) throws Throwable {
return objectMapper.writeValueAsBytes(data);
}
});
//一个StreamBuilder实例,有一个TopologyBuilder,TopologyBuilder可构建出数据处理器processor
TopologyBuilder topologyBuilder = builder.build();
Properties properties = new Properties();
//nameserver的地址
properties.put(MixAll.NAMESRV_ADDR_PROPERTY, "127.0.0.1:9876");
//RocketMQStream实例,有一个拓扑构建器TopologyBuilder
RocketMQStream rocketMQStream = new RocketMQStream(topologyBuilder, properties);
Runtime.getRuntime().addShutdownHook(new Thread("StreamCopy-shutdown-hook") {
@Override
public void run() {
rocketMQStream.stop();
}
});
rocketMQStream.start();
}
}
public class WordCount {
public static void main(String[] args) {
//构建流处理实例:一个JobId对应一个StreamBuilder实例
StreamBuilder builder = new StreamBuilder("wordCount-lijin");
//定义source topic 和反序列化方式
builder.source("sourceTopic", total -> {
String value = new String(total, StandardCharsets.UTF_8);
return new Pair<>(null, value);
})
//flatMap:对数据进行一对多转化
.flatMap((ValueMapperAction<String, List<String>>) value -> {
String[] splits = value.toLowerCase().split("\\W+");
return Arrays.asList(splits);
})
//keyBy:按照特定字段分组
.keyBy(value -> value)
//count:统计含有某个字段数据的个数
.count()
//toRStream:转化为RStream,只是在接口形式上转化,对数据无任何操作
.toRStream()
// sink:按照自定义序列化形式将结果写出到topic
.sink("sell-count", (KeyValueSerializer) (key, value) -> {
//return value.toString().getBytes();
return ( key+":"+ value).toString().getBytes(); // 将词频统计结果转换为字符串
});
TopologyBuilder topologyBuilder = builder.build();
Properties properties = new Properties();
properties.put(MixAll.NAMESRV_ADDR_PROPERTY, "127.0.0.1:9876");
//一个StreamBuilder实例,有一个TopologyBuilder,TopologyBuilder可构建出数据处理器processor
RocketMQStream rocketMQStream = new RocketMQStream(topologyBuilder, properties);
final CountDownLatch latch = new CountDownLatch(1);
Runtime.getRuntime().addShutdownHook(new Thread("wordcount-shutdown-hook") {
@Override
public void run() {
rocketMQStream.stop();
latch.countDown();
}
});
try {
rocketMQStream.start();
latch.await();
} catch (final Throwable e) {
System.exit(1);
}
System.exit(0);
}
}
性能调优
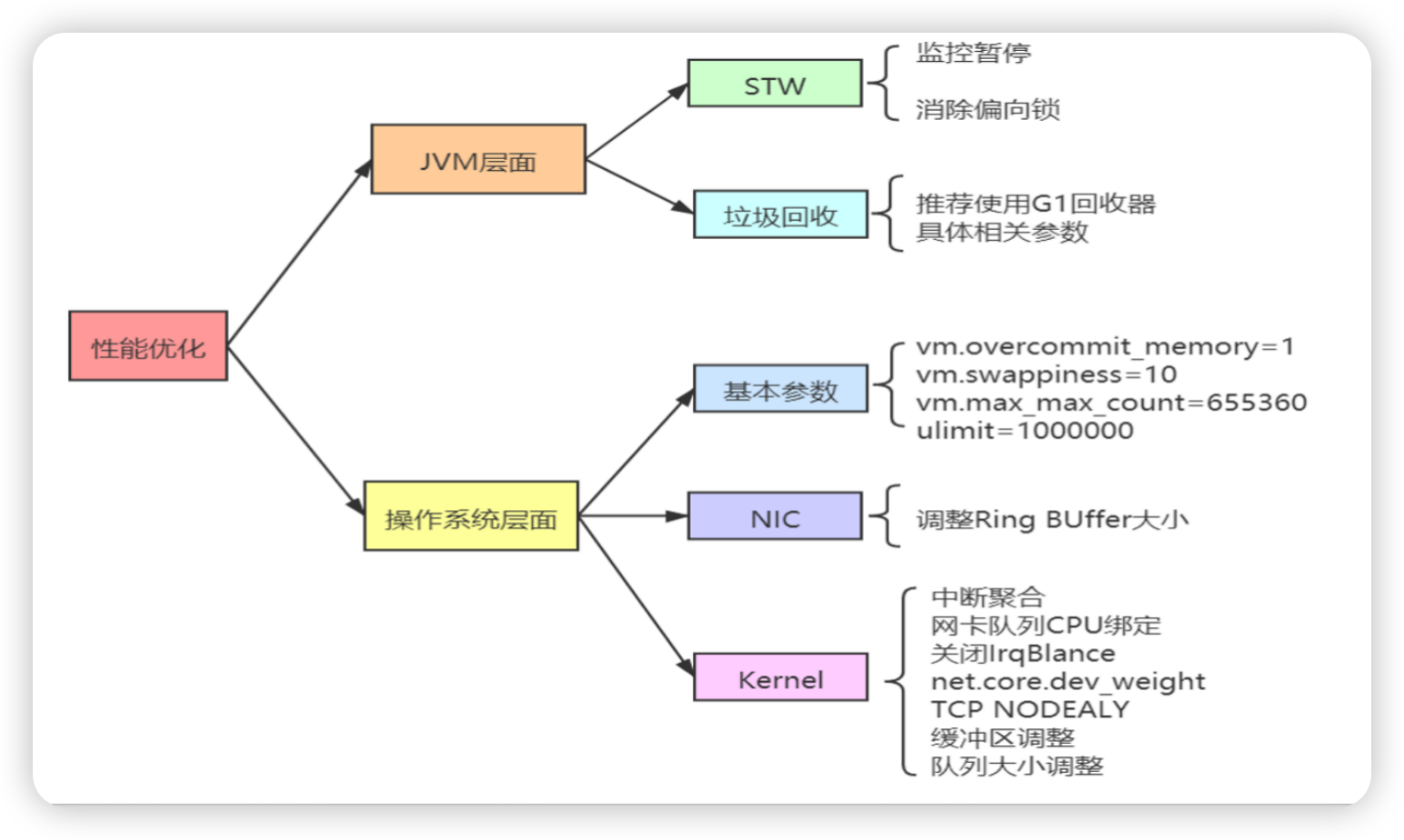
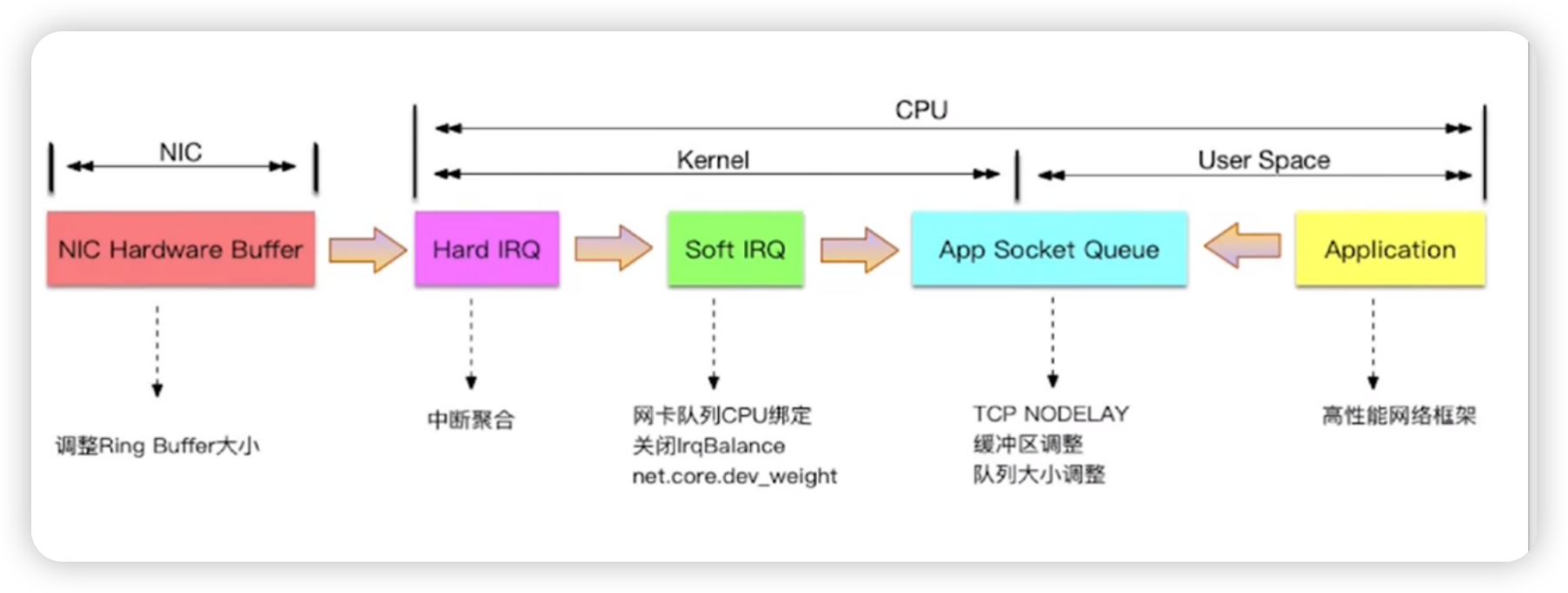
- 取消mq的监控
- 消除偏向锁,rocketmq源码中很多用了多线程的处理,锁竞争比较激烈,直接去除偏向锁
- -XX:-UseBiasedLocking 禁用偏向锁
- 使用G1垃圾会收器: -XX:+UseG1GC, 推荐堆内存至少为8g
- ulimit 打开文件的限制 一个系统一个进程最多打开多少个文件数
- vm.overcommit_memory 是否允许向操作系统申请内存超过内存大小,设置为1,允许,减少每次申请内存时的内存判断
- NIC: 网卡的参数
- 中断聚合

- 不让CPU优化分配核心
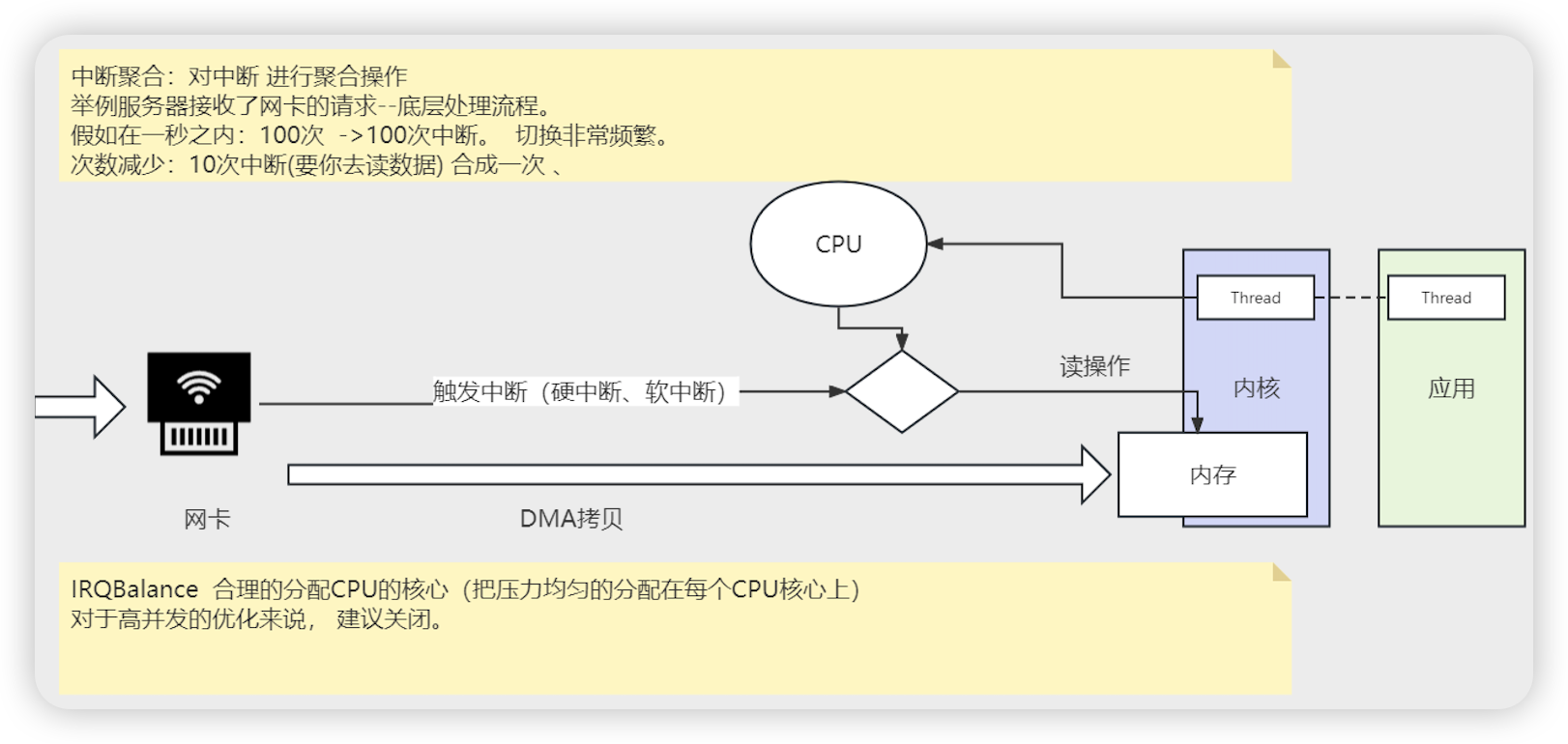
DMA数据拷贝
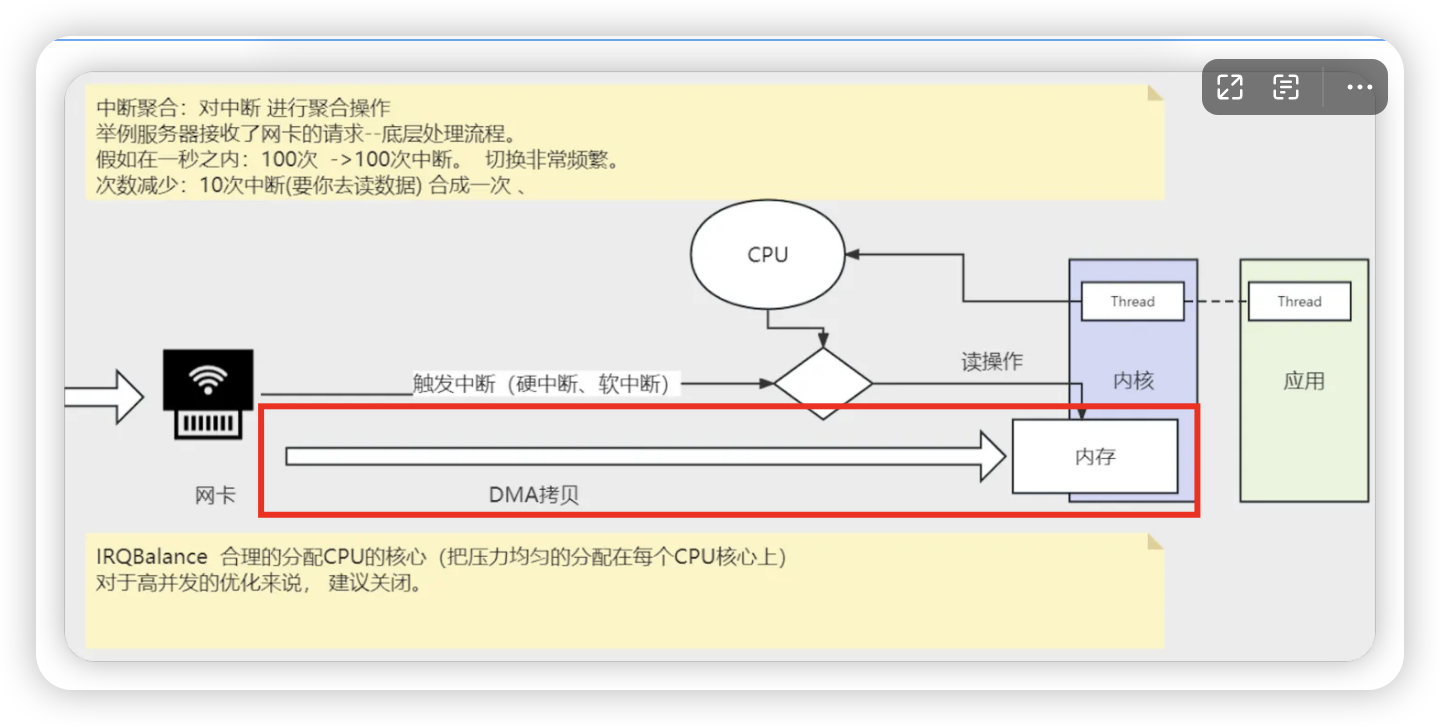
- DMA拷贝通常会将数据拷贝到内核空间,然后CPU可能将(零拷贝)内核空间的数据拷贝到应用空间。这个过程涉及到直接内存访问(DMA)技术和操作系统中的内存管理机制。
- DMA拷贝的基本过程
- DMA请求与传输:
- 当用户进程发起I/O请求(如读取磁盘文件)时,CPU会向DMA控制器发送指令,告诉DMA控制器需要读取的数据位置(源地址)和存放数据的位置(目的地址)。
- DMA控制器接管总线控制权,直接从外设(如磁盘)读取数据到内核空间的缓冲区(如Page Cache),这个过程中CPU不参与数据的实际拷贝,可以继续执行其他任务。
- 数据传输完成后,DMA控制器会向CPU发送中断信号,告知传输完成。
- CPU处理:
- CPU响应DMA中断后,会检查传输的数据是否准备就绪。
- 如果用户进程需要这些数据,CPU可能会将这些数据从内核空间的缓冲区拷贝到用户空间的缓冲区。这一步是可选的,取决于用户进程的具体需求和操作系统的实现。
- DMA请求与传输:
- 为什么可能需要CPU拷贝到应用空间
- 用户空间的权限隔离:操作系统为了保护用户空间的稳定性和安全性,通常不允许用户进程直接访问内核空间的数据。因此,即使DMA已经将数据拷贝到内核空间,用户进程也需要通过系统调用等方式来获取这些数据,这通常涉及到数据的拷贝。
- 数据处理的需要:在某些情况下,用户进程可能需要对数据进行进一步的处理或转换,这就需要将数据从内核空间拷贝到用户空间,以便在用户空间中进行操作。
- 零拷贝技术的优化
- 为了减少不必要的数据拷贝和上下文切换,现代操作系统引入了零拷贝技术。零拷贝技术并不是指不进行任何数据拷贝,而是指通过优化减少CPU参与的数据拷贝次数。例如,使用
mmap系统调用可以实现用户空间和内核空间对同一物理内存区域的映射,从而避免数据在用户空间和内核空间之间的拷贝。另外,sendfile系统调用可以在内核空间内部完成数据的传输,减少了CPU拷贝的次数。
- 为了减少不必要的数据拷贝和上下文切换,现代操作系统引入了零拷贝技术。零拷贝技术并不是指不进行任何数据拷贝,而是指通过优化减少CPU参与的数据拷贝次数。例如,使用
- 综上所述,DMA拷贝通常会将数据拷贝到内核空间,然后CPU可能根据需要将内核空间的数据拷贝到应用空间。但在某些情况下,通过零拷贝技术等优化手段可以减少这种拷贝操作。















 1162
1162

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









