







 超级会员免费看
超级会员免费看
1 项目概要
公司购买了ODA一体机,计划将原有的Oracle数据库迁移至ODA一体机,数据库迁移方案使用Oracle DataGuard方案进行,业务最小化停机时间。本文以下内容包含本次搭建的操作内容。
2 Data Guard 容灾数据库实施方案
2.1 Data Guard 系统架构图
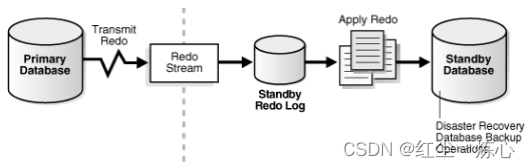
2.2 准备工作
2.2.1数据库版本检查
Data Guard环境需要保证主库与备库数据库版本与补丁一致。
检查结果:容灾环境为12.1.0.2,生产环境为12.1.0.2
调整配置:将容灾环境数据库部署为与生产环境一致版本。
2.2.2数据库备份检查
在部署容灾环境前对生产环境进行一次全量备份,用于数据初始化。
[oracle@rac01 ~]$ rman target /
Recovery Manager: Release 12.1.0.2.0 - Production on Thu Oct 22 18:24:07 2020
Copyright (c) 1982, 2014, Oracle and/or its affiliates. All rights reserved.
connected to target database: PROD (DBID=3884231)
RMAN>backup current controlfile for standby format '/home/oracle/rmanbk/for_standby_ctl.ctl';
RMAN> backup as compressed backupset full database format='/home/oracle/rmanbk/bk_%s_%p_%t';
主库备份数据文件传递到备库:
[oracle@erprac01 rmanbk]$ scp * oracle@172.16.60.224:/u03/app/oracle/rmanbk
2.2.5添加tnsnames.ora文件信息
两个节点检查配置tnsnames.ora
1) 配置主备端所有节点的tnsnames.ora,添加如下信息:
2.2.6 目标端创建静态监听
[oracle@odadb1 admin]$ cat listener.ora
PRODDG=
(DESCRIPTION=
(ADDRESS_LIST=
(ADDRESS=(PROTOCOL=tcp)(HOST=172.16.60.224)(PORT=1531))))
SID_LIST_PRODDG=
(SID_LIST=
(SID_DESC=
(ORACLE_HOME=/u01/app/oracle/product/12.1.0.2/dbhome_15)
(SID_NAME= PROD1)))
#启动监听
lsnrctl start
2.2.7拷贝密码文件
1) 在备库端将主库传输过来的口令文件拷贝到$ORACLE_HOME/dbs下并重命名orapw$ORACLE_SID:

[oracle@odadb1 dbs]$ cat initPROD1.ora
spfile='+DATA/PROD/PARAMETERFILE/spfilePROD.ora'
2.3 主库检查
备注:主库端操作
2.3.1 是否安装相关组件
SQL> SELECT * FROM V$OPTION WHERE PARAMETER in ('Oracle Data Guard', 'Advanced Compression');
PARAMETER VALUE
------------------------------- ----------
Oracle Data Guard TRUE
Advanced Compression TRUE
2.3.2 开启FORCE_LOGGING模式
select force_logging from v$database;
开启:
alter database force logging;
2.3.3 归档模式
2.3.4 remote_login_passwordfile配置
show parameter remote_login_passwordfile
(remote_login_passwordfile应为EXCLUSIVE)
2.4 修改参数文件
2.4.1 修改主库参数
备注:主库端操作
--01. 修改主库参数文件
alter system set db_unique_name='PROD' scope=spfile sid='*';
alter system set LOG_ARCHIVE_CONFIG='DG_CONFIG=(PROD,PRODDG)' scope=both sid='*';
alter system set LOG_ARCHIVE_DEST_1='LOCATION=USE_DB_RECOVERY_FILE_DEST
VALID_FOR=(ALL_LOGFILES,ALL_ROLES) DB_UNIQUE_NAME=PROD' scope=both sid='*';
alter system set LOG_ARCHIVE_DEST_2='SERVICE=PRODDG LGWR ASYNC
VALID_FOR=(ONLINE_LOGFILES,PRIMARY_ROLE) DB_UNIQUE_NAME=PRODDG' scope=both sid='*';
alter system set FAL_SERVER='PRODDG' scope=both sid='*';
alter system set fal_client='PROD' scope=both sid='*';
alter system set
DB_FILE_NAME_CONVERT='/oradata/PRODDG','+DGSYSTEM/PROD','/oradata/PRODDG','+DGDATA01/PROD' scope=spfile sid='*';
alter system set LOG_FILE_NAME_CONVERT='/oradata/PRODDG','+DGSYSTEM/PROD' scope=spfile sid='*';
alter system set standby_file_management=AUTO scope=both sid='*';
2) 将主库参数文件备份
su - oracle
sqlplus / as sysdba
create pfile='/home/oracle/prod.ora' from spfile;
2.4.2 参数文件传输至备库
1)主库将pfile并传送至备库
scp prod.ora oracle@172.16.60.224:/home/oracle
2) 备库修改参数文件
vi /home/oracle/prod.ora
(标红参数需要更改或者检查)
[oracle@odadb1 dbs]$ cat /home/oracle/prod.ora
*.aq_tm_processes=5
*.AUDIT_SYS_OPERATIONS=TRUE
*.cluster_database=true
*.cluster_database_instances=2
*.compatible='12.1.0.2.0'
*.control_file_record_keep_time=14
*.control_files='+DATA/PROD/CONTROLFILE/cntrl01.dbf','+DATA/PROD/CONTROLFILE/cntrl02.dbf','+DATA/PROD/CONTROLFILE/cntrl03.dbf'
*.cursor_sharing='EXACT'# Required 11i settting
*.db_block_checking='FALSE'
*.db_block_checksum='TRUE'
*.db_block_size=8192
*.db_file_name_convert='+DATA/PROD/DATAFILE','+DATA/PROD/DATAFILE','+DATA/PROD/TEMPFILE','+DATA/PROD/TEMPFILE'
*.db_files=512# Max. no. of database files
*.db_name='PROD'
*.db_unique_name='PRODDG'
*.db_recovery_file_dest_size=536870912000
*.db_recovery_file_dest='+RECO'
*.diagnostic_dest='/u01/app/oracle'
*.distributed_lock_timeout=3
*.dml_locks=10000
*.event='10995 trace name context forever, level 16'
*.fal_client='PRODDG'
*.fal_server='PROD'
PROD1.instance_name='PROD1'
PROD2.instance_name='PROD2'
PROD1.instance_number=1
PROD2.instance_number=2
*.job_queue_processes=10
#PROD1.local_listener='PROD1_LOCAL'
#PROD2.local_listener='PROD2_LOCAL'
*.log_archive_config='DG_CONFIG=(PRODDG,PROD)'
*.log_archive_dest_1='LOCATION=USE_DB_RECOVERY_FILE_DEST VALID_FOR=(ALL_LOGFILES,ALL_ROLES) DB_UNIQUE_NAME=PRODDG'
*.log_archive_dest_2='SERVICE=PROD LGWR ASYNC VALID_FOR=(ONLINE_LOGFILES,PRIMARY_ROLE) DB_UNIQUE_NAME=PROD'
*.log_archive_dest_state_1='ENABLE'
*.log_archive_dest_state_2='ENABLE'
*.log_archive_format='%t_%s_%r.dbf'
*.log_buffer=10485760
*.log_checkpoint_interval=100000
*.log_checkpoint_timeout=1200# Checkpoint at least every 20 mins.
*.log_checkpoints_to_alert=TRUE
*.max_dump_file_size='UNLIMITED'
*.log_file_name_convert='+FRA/PROD/ARCHIVELOG','+RECO/PROD/ARCHIVELOG','+DATA/PROD/ONLINELOG','+DATA/PROD/ONLINELOG'
*.nls_comp='binary'# Required 11i setting
*.nls_date_format='DD-MON-RR'
*.nls_length_semantics='BYTE'# Required 11i setting
*.nls_numeric_characters='.,'
*.nls_sort='binary'# Required 11i setting
*.nls_territory='america'
*.o7_dictionary_accessibility=FALSE#MP
*.olap_page_pool_size=4194304
*.open_cursors=2000# Consumes process memory, unless using MTS.
*.optimizer_adaptive_features=FALSE#MP
*.optimizer_secure_view_merging=false
*.OS_AUTHENT_PREFIX=''
*.parallel_force_local=TRUE
*.parallel_max_servers=8
*.parallel_min_servers=0
*.pga_aggregate_limit=0
*.pga_aggregate_target=12884901888
*.plsql_code_type='INTERPRETED'# Default 11i setting
*.processes=2500# Max. no. of users x 2
*.recyclebin='off'
*.sec_case_sensitive_logon=FALSE
*.service_names='PROD, PROD_ebs_patch,PROD_ebs_patch'
*.session_cached_cursors=500
*.sessions=3000# 2 X processes
*.sga_max_size=55834574848
*.sga_target=55834574848
*.shared_pool_reserved_size=100M
*.shared_pool_size=4500M
PROD1.shared_pool_size=10737418240
PROD2.shared_pool_size=10737418240
*.SQL92_SECURITY=TRUE
*.standby_file_management='AUTO'
*.temp_undo_enabled=true
PROD1.thread=1
PROD2.thread=2
*.undo_management='AUTO'# Required 11i setting
*.undo_retention=3600
PROD1.undo_tablespace='APPS_UNDOTS1'
PROD2.undo_tablespace='APPS_UNDOTS2'
*.undo_tablespace='APPS_UNDOTS1'
*.utl_file_dir='/u01/app/oracle/product/12.1.0.2/dbhome_15/temp'
*.workarea_size_policy='AUTO'# Required 11i setting
3) 创建文件夹(所有节点都要创建)
mkdir -p /u01/app/oracle/product/12.1.0.2/dbhome_15/temp
2.5 恢复备库实例
2.5.1 恢复参数文件
[oracle@odadb1 dbs]$ sqlplus / as sysdba
SQL> create spfile='+DATA/PROD/PARAMETERFILE/spfilePROD.ora' from pfile='/home/oracle/prod.ora';
SQL>startup nomount;
3.5.2 查看主库日志文件大小
col thread# for 99
col member for 99
col bytes for 99999999
col status for a10
col type for a20
set linesize 200
set pagesize 100
SELECT L.GROUP#, L.THREAD#, LF.MEMBER, L.BYTES/1024/1024, L.STATUS, LF.TYPE FROM V$LOG L, V$LOGFILE LF WHERE L.GROUP# = LF.GROUP#;
2.5.3 创建standby日志组
备注:若数据库已经有standby log的信息,主备库可不用重新删除添加。即忽略该步骤。以下为主备库均无standby log情况下操作。
添加主备库端两节点的standby日志组
添加规则:
standby redo log组数公式 >= (每个instance日志组个数+1)*instance个数
alter database add standby logfile thread 1 group 20 (‘…','…') size 1024M;
alter database add standby logfile thread 1 group 21 ('…','…') size 1024M;
1)主库添加standby日志
SQL> col MEMBER for a50
SQL> select group#,member from v$logfile;
GROUP# STATUS TYPE MEMBER
1 ONLINE +RECO/CX/ONLINELOG/group_1.338.1036554323
2 ONLINE +RECO/CX/ONLINELOG/group_2.339.1036554323
3 ONLINE +RECO/CX/ONLINELOG/group_3.340.1036554565
4 ONLINE +RECO/CX/ONLINELOG/group_4.341.1036554567
可以看到主库有4组redo日志,我们添加6组standby日志
alter database add standby logfile thread 1 group 5 '+RECO' size 4096M;
alter database add standby logfile thread 1 group 6 '+RECO' size 4096M;
alter database add standby logfile thread 1 group 7 '+RECO' size 4096M;
alter database add standby logfile thread 2 group 8 '+RECO' size 4096M;
alter database add standby logfile thread 2 group 9 '+RECO' size 4096M;
alter database add standby logfile thread 2 group 10 '+RECO' size 4096M;
3.5.4 备库恢复数据库
1) duplicate恢复
[oracle@traracdb1 20190607]$ rman target /
RMAN> restore standby controlfile from '/home/oracle/backup/for_standby_ctl.ctl';
RMAN> alter database mount;
恢复数据库
RMAN> catalog start with '/home/oracle/backup/';
RMAN> crosscheck backupset;
RMAN> delete noprompt expired backup;
RMAN> restore database;
2) 启动数据库到mount状态
SQL> startup mount;
2.5.6 备库介质恢复
备注:使用节点1开启mrp
alter database recover managed standby database using current logfile disconnect from session nodelay;
2.5.7 开启日志投递
备注:主库端操作
alter system set log_archive_dest_state_2='enable' scope=both sid='*';
alter system switch logfile;
2.6 同步状态检查
2.6.1 查看备库警告日志 (若出现问题,采取这样的操作)
tail -100f alert_实例名.log
如果出现日志投递错误的情况,比如:提示某个standby日志不存在,则备库需要重建standby日志
操作步骤:
1)备库取消日志投递
SQL> recover managed standby database cancel;
Media recovery complete.
2)修改standby日志管理为MANUAL
SQL> alter system set standby_file_management=MANUAL sid='*' scope=both;
3)备库重建standby日志
SQL> select group# , member from v$logfile ; 查看所有日志路径
删除无效的日志组
alter database drop logfile group 11;
alter database drop logfile group 12;
alter database drop logfile group 13;
alter database drop logfile group 14;
alter database drop logfile group 15;
alter database drop logfile group 16;
alter database drop logfile group 17;
alter database drop logfile group 18;
alter database drop logfile group 19;
alter database drop logfile group 20;
重建standby日志
alter database add standby logfile thread 1 group 11 ('+DATA/PROD/ONLINELOG/stby_redo11.log') size 1000M;
alter database add standby logfile thread 1 group 12 ('+DATA/PROD/ONLINELOG/stby_redo12.log') size 1000M;
alter database add standby logfile thread 1 group 13 ('+DATA/PROD/ONLINELOG/stby_redo13.log') size 1000M;
alter database add standby logfile thread 1 group 14 ('+DATA/PROD/ONLINELOG/stby_redo14.log') size 1000M;
alter database add standby logfile thread 1 group 15 ('+DATA/PROD/ONLINELOG/stby_redo15.log') size 1000M;
alter database add standby logfile thread 2 group 16 ('+DATA/PROD/ONLINELOG/stby_redo16.log') size 1000M;
alter database add standby logfile thread 2 group 17 ('+DATA/PROD/ONLINELOG/stby_redo17.log') size 1000M;
alter database add standby logfile thread 2 group 18 ('+DATA/PROD/ONLINELOG/stby_redo18.log') size 1000M;
alter database add standby logfile thread 2 group 19 ('+DATA/PROD/ONLINELOG/stby_redo19.log') size 1000M;
alter database add standby logfile thread 2 group 20 ('+DATA/PROD/ONLINELOG/stby_redo20.log') size 1000M;
4)修改standby管理模式为auto
SQL> alter system set standby_file_management=auto scope=both;
5)备库开启日志投递
SQL> recover managed standby database using current logfile disconnect from session nodelay;
6)检查主库、备库的日志信息是否一致
SQL> select thread#,max(sequence#) "Last Primary Seq Generated" from v$archived_log val,v$database vdb where val.resetlogs_change#=vdb.resetlogs_change# group by thread# order by 1;
THREAD# Last Primary Seq Generated
---------- --------------------------
1 210
2 203
2.6.2 mrp进程状态检查
select inst_id,process,status,thread#,sequence#,block# from gv$managed_standby where PROCESS like 'MRP%';
2.6.3 日志接收与同步检查
主库:
select thread#,max(sequence#) "Last Primary Seq Generated" from v$archived_log val,v$database vdb where val.resetlogs_change#=vdb.resetlogs_change# group by thread# order by 1;
备库:
-- 检查备库已经接收到的 sequence# 号
select thread#,max(sequence#) "Last Standby Seq Received" from v$archived_log val,v$database vdb where val.resetlogs_change#=vdb.resetlogs_change# group by thread# order by 1;
-- 检查备库已经应用到的 sequence# 号
select thread#,max(sequence#) "Last Standby Seq Applied" from v$archived_log val,v$database vdb where val.resetlogs_change#=vdb.resetlogs_change# and val.applied in ('YES','IN-MEMORY') group by thread# order by 1;
2.6.4 延迟查询
select name,value from v$dataguard_stats;
3.6.5 开启数据库为open
当主备库完全同步后,重启备库
select name,open_mode,protection_mode,database_role,swithover_status from v$database;
alter database recover managed standby database cancel;
recover managed standby database using current logfile disconnect from session nodelay;
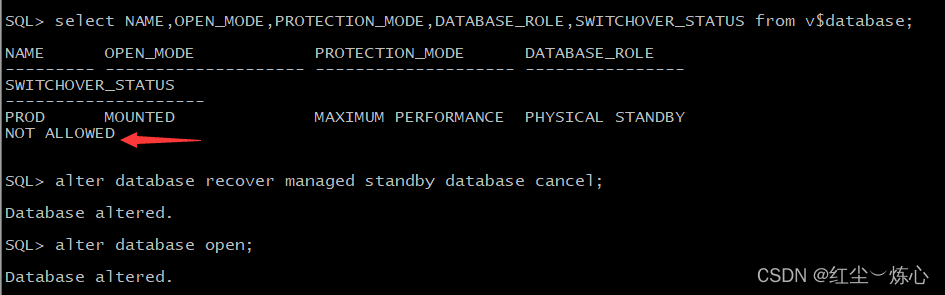
select open_mode,database_role from gv$database;
注意:如果主库日志无法传输到备库
备库的 alert*.log日志一直停留在
recover managed standby database using current logfile disconnect from session nodelay;
主库的 alert*.log日志提示这个问题
Error1033 received logging on to the standby,主库日志未传输到备库解决办法
检查备库的监听、TNS配置,备库的密码文件一定要和主库一直。最好从主库拷贝过来
检查主备库的密码文件是否一致
[oracle@mestszb dbs]$ md5sum orapwmesasrac
d32aa9a0c8a593d8d4ae71f557d50a56 orapwmesasrac
把主库的rfs重启一下
mrp也重启一些
SQL> alter system set log_archive_dest_state_2=defer sid='*' scope=both;
System altered.
SQL> alter system set log_archive_dest_state_2=enable sid='*' scope=both;
System altered.
3 Dataguard 切换
---主库
select DATABASE_ROLE,SWITCHOVER_STATUS from v$database;
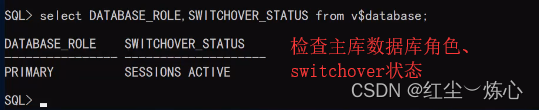
如果switchover状态为active,说明还有活动的会话
select DATABASE_ROLE,SWITCHOVER_STATUS,PROTECTION_MODE from v$database;

如果检查都没有问题的话,这种状态就可以强制性处理了
select DATABASE_ROLE,SWITCHOVER_STATUS,PROTECTION_MODE from v$database;

将主库切换为备库并强制关闭当前的会话
alter database commit to switchover to physical standby with session shutdown;
![]()
这条命令会强制性将主库转为备库,并断掉所有会话,需要启动数据库
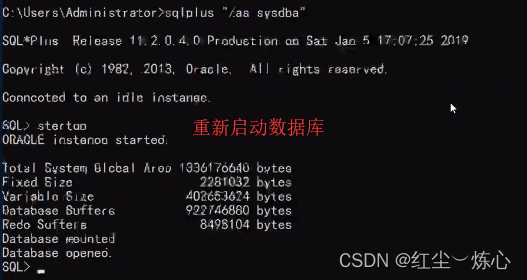
再检查数据库角色,主库现在变成了物理备库了

--备库

如果switchover状态为not allowed,说明需要结束之前的会话连接

把应该断掉的会话都断掉之后,这个状态就不影响了

检查日志是否都同步完成,有没有缺失的日志

现在将备库切换为主库
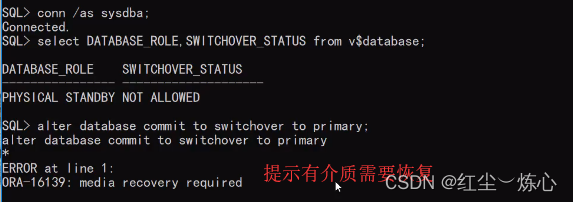


再将备库切换为主库,现在切换成功了

现在可以看到数据库的角色变成主库了



















 1073
1073

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











