






写在前面:个人学习记录用,细节一窍不通 。
课程网址:Proxy Lab
参考文章,感谢大佬:
· 基于C语言的简易代理服务器实现(proxylab)
· CSAPP之详解ProxyLab
首先点击Self-Study Handout,下载得到proxylab-handout.tar文件,在Linux环境下解压。
Proxy代理,处理Client的Request请求,然后再Response转发给Server。
使用telnetdebug工具,使用命令yum install telnet来安装:

cd到解压好的proxylab-handout目录下,使用tar -xvf proxylab-handout.tar解压。

查看解压好的根目录:

实验部分
下面是原文。
Part I: Implementing a sequential web proxy The first step is implementing a basic sequential proxy that handles HTTP/1.0 GET requests. Other requests type, such as POST, are strictly optional.
When started, your proxy should listen for incoming connections on a port whose number will be specified on the command line. Once a connection is established, your proxy should read the entirety of the request from the client and parse the request. It should determine whether the client has sent a valid HTTP request; if so, it can then establish its own connection to the appropriate web server then request the object the client specified. Finally, your proxy should read the server’s response and forward it to the client.
… …
主要需要完成的三项任务:
1、实现顺序代理;
2、实现并发;
3、实现Cache缓存。
假如收到一条这样的request请求:GET http://www.cmu.edu/hub/index.html HTTP/1.1,应该将其转变为这样的类似数据格式:
GET /hub/index.html HTTP/1.1
Host: www.cmu.edu
Connection: close
Proxy-Connection: close
然后再将其转发给Proxy。
4.3中提到了选择没有被占用的端口号的脚本文件:
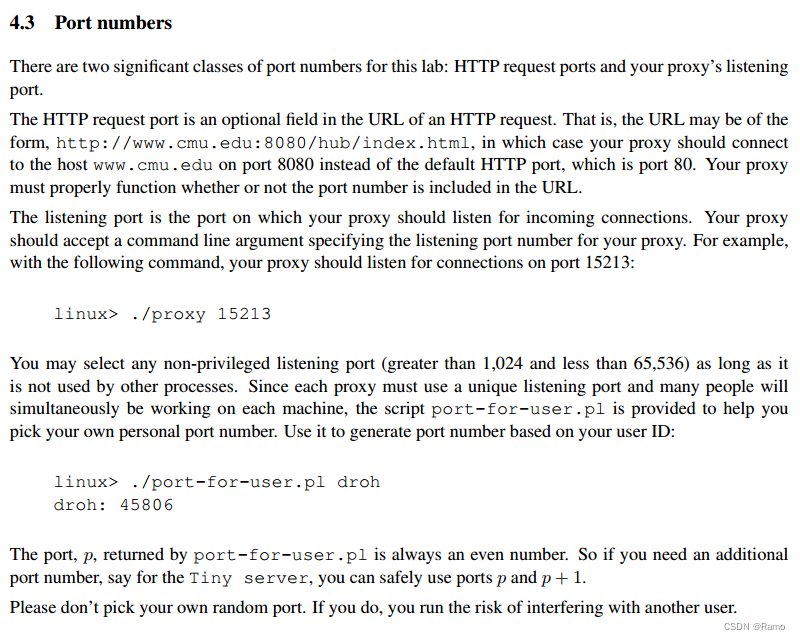
选择一个没有被占用的端口进行实验。使用ps aux查看所有正在被使用的端口。
在目录下的driver.sh脚本中,有一个free_port{}的function,找到当前正在使用的端口,是否使用了端口,没有被用到就会kill该进程(说明没有运行在该服务器)。
部分代码注释
#
# free_port - returns an available unused TCP port
#
function free_port {
# Generate a random port in the range [PORT_START,
# PORT_START+MAX_RAND]. This is needed to avoid collisions when many
# students are running the driver on the same machine.
port=$((( RANDOM % ${MAX_RAND}) + ${PORT_START}))
while [ TRUE ]
do
portsinuse=`netstat --numeric-ports --numeric-hosts -a --protocol=tcpip \
| grep tcp | cut -c21- | cut -d':' -f2 | cut -d' ' -f1 \
| grep -E "[0-9]+" | uniq | tr "\n" " "`
echo "${portsinuse}" | grep -wq "${port}"
if [ "$?" == "0" ]; then
if [ $port -eq ${PORT_MAX} ]
then
echo "-1"
return
fi
port=`expr ${port} + 1`
else
echo "${port}"
return
fi
done
}
nop-server.py:搭建一个无限循环的Server,当请求过来后就会被trap,相当于模拟多线程去解决其中一个请求。
driver.sh的定义部分与Main函数:
# 前面是一些定义常量
# Point values
MAX_BASIC=40 # 基础40分
MAX_CONCURRENCY=15 # 并发15分
MAX_CACHE=15 # CACHE 15分
# ... ...
#######
# Main 主函数
#######
######
# Verify that we have all of the expected files with the right
# permissions
#
# Kill any stray proxies or tiny servers owned by this user
killall -q proxy tiny nop-server.py 2> /dev/null
# Make sure we have a Tiny directory
# 确保你有./tiny文件,否则终止
if [ ! -d ./tiny ]
then
echo "Error: ./tiny directory not found."
exit
fi
# If there is no Tiny executable, then try to build it
if [ ! -x ./tiny/tiny ]
then
echo "Building the tiny executable."
(cd ./tiny; make)
echo ""
fi
# Make sure we have all the Tiny files we need
if [ ! -x ./tiny/tiny ]
then
echo "Error: ./tiny/tiny not found or not an executable file."
exit
fi
for file in ${BASIC_LIST}
do
if [ ! -e ./tiny/${file} ]
then
echo "Error: ./tiny/${file} not found."
exit
fi
done
# Make sure we have an existing executable proxy
if [ ! -x ./proxy ]
then
echo "Error: ./proxy not found or not an executable file. Please rebuild your proxy and try again."
exit
fi
# Make sure we have an existing executable nop-server.py file
# 确保你有nop-server.py文件,否则终止
if [ ! -x ./nop-server.py ]
then
echo "Error: ./nop-server.py not found or not an executable file."
exit
fi
# Create the test directories if needed
# 没有PROXY_DIR和NOPROXY_DIR文件夹的话,终止运行
if [ ! -d ${PROXY_DIR} ]
then
mkdir ${PROXY_DIR}
fi
if [ ! -d ${NOPROXY_DIR} ]
then
mkdir ${NOPROXY_DIR}
fi
脚本的运行部分:
# Add a handler to generate a meaningful timeout message
trap 'echo "Timeout waiting for the server to grab the port reserved for it"; kill $$' ALRM
#####
# Basic
#
echo "*** Basic ***"
# Run the Tiny Web server
# 启动Web server
tiny_port=$(free_port)
echo "Starting tiny on ${tiny_port}"
cd ./tiny
./tiny ${tiny_port} &> /dev/null &
tiny_pid=$!
cd ${HOME_DIR}
# Wait for tiny to start in earnest
# 检查是否真正的运行起来
wait_for_port_use "${tiny_port}"
# Run the proxy
# 运行proxy
proxy_port=$(free_port)
echo "Starting proxy on ${proxy_port}"
./proxy ${proxy_port} &> /dev/null &
proxy_pid=$!
# Wait for the proxy to start in earnest
# 检查proxy是否运行成功,和server没有先后顺序。
wait_for_port_use "${proxy_port}"
# Now do the test by fetching some text and binary files directly from
# Tiny and via the proxy, and then comparing the results.
numRun=0
numSucceeded=0
for file in ${BASIC_LIST}
do
numRun=`expr $numRun + 1`
echo "${numRun}: ${file}"
clear_dirs
# Fetch using the proxy
# 通过proxy进行fetch
echo " Fetching ./tiny/${file} into ${PROXY_DIR} using the proxy"
download_proxy $PROXY_DIR ${file} "http://localhost:${tiny_port}/${file}" "http://localhost:${proxy_port}"
# Fetch directly from Tiny
# 通过tiny进行fetch
echo " Fetching ./tiny/${file} into ${NOPROXY_DIR} directly from Tiny"
download_noproxy $NOPROXY_DIR ${file} "http://localhost:${tiny_port}/${file}"
# Compare the two files
echo " Comparing the two files"
diff -q ${PROXY_DIR}/${file} ${NOPROXY_DIR}/${file} &> /dev/null
if [ $? -eq 0 ]; then # 没有输出
numSucceeded=`expr ${numSucceeded} + 1`
echo " Success: Files are identical."
else
echo " Failure: Files differ."
fi
done
# ... ...
proxy.c
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include "csapp.h"
/* Recommended max cache and object sizes */
#define MAX_CACHE_SIZE 1049000
#define MAX_OBJECT_SIZE 102400
#define MAX_CACHE 10
/* You won't lose style points for including this long line in your code */
static const char *user_agent_hdr = "User-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:10.0.3) Gecko/20120305 Firefox/10.0.3\r\n";
// read & write Lock
struct rwlock_t{
sem_t lock; //basic lock
sem_t writelock; //write lock
int readers; //Reader
};
// Cache
struct Cache{
int used; //最近被使用过为1,否则为0
char key[MAXLINE]; //URL索引
char value[MAX_OBJECT_SIZE]; //URL所对应的缓存
};
// Url数据格式
struct UrlData{
char host[MAXLINE]; //hostname
char port[MAXLINE]; //端口
char path[MAXLINE]; //路径
};
struct Cache cache[MAX_CACHE]; //定义缓存对象,最多允许存在MAX_CACHE个
struct rwlock_t* rw; //定义读写者锁指针
int nowpointer; //LRU当前指针
void doit(int fd);
void parse_url(char* url, struct UrlData* u); //解析URL
void change_httpdata(rio_t* rio, struct UrlData* u, char* new_httpdata); //修改http数据
void thread(void* v); //线程函数
void rwlock_init(); //初始化读写者锁指针
int readcache(int fd, char* key); //读缓存
void writecache(char* buf, char* key); //写缓存
/*main函数大体与书上一致*/
int main(int argc, char** argv){
rw = Malloc(sizeof(struct rwlock_t));
printf("%s", user_agent_hdr);
pthread_t tid;
int listenfd, connfd;
char hostname[MAXLINE], port[MAXLINE];
socklen_t clientlen;
struct sockaddr_storage clientaddr;
rwlock_init();
if (argc != 2){
fprintf(stderr, "usage: %s <port>\n", argv[0]);
exit(0);
}
listenfd = Open_listenfd(argv[1]);
while (1){
clientlen = sizeof(clientaddr);
connfd = Accept(listenfd, (SA*)&clientaddr, &clientlen);
Getnameinfo((SA*)&clientaddr, clientlen, hostname, MAXLINE, port, MAXLINE, 0);
printf("Accepted connection from (%s %s)\n", hostname, port);
Pthread_create(&tid, NULL, thread, (void*)&connfd);
}
return 0;
}
void rwlock_init(){
rw->readers = 0; //no reader
sem_init(&rw->lock, 0, 1);
sem_init(&rw->writelock, 0, 1);
}
void thread(void* v){
int fd = *(int*)v; //这一步是必要的,v是main中connfd的地址,后续可能被改变,所以必须要得到一个副本
//还要注意不能锁住,因为允许多个一起读
Pthread_detach(pthread_self()); //设置线程,结束后自动释放资源
doit(fd);
close(fd);
}
void doit(int fd){
char buf[MAXLINE], method[MAXLINE], url[MAXLINE], version[MAXLINE];
char new_httpdata[MAXLINE], urltemp[MAXLINE];
struct UrlData u;
rio_t rio, server_rio;
Rio_readinitb(&rio, fd);
Rio_readlineb(&rio, buf, MAXLINE);
sscanf(buf, "%s %s %s", method, url, version);
strcpy(urltemp, url); //赋值url副本以供读者写者使用,因为在解析url中,url可能改变
/*只接受GEI请求*/
if (strcmp(method, "GET") != 0){
printf ("The proxy can not handle this method: %s\n", method);
return;
}
if (readcache(fd, urltemp) != 0) //如果读者读取缓存成功的话,直接返回
return;
parse_url(url, &u); //解析url
change_httpdata(&rio, &u, new_httpdata); //修改http数据,存入 new_httpdata中
int server_fd = Open_clientfd(u.host, u.port);
size_t n;
Rio_readinitb(&server_rio, server_fd);
Rio_writen(server_fd, new_httpdata, strlen(new_httpdata));
char cache[MAX_OBJECT_SIZE];
int sum = 0;
while((n = Rio_readlineb(&server_rio, buf, MAXLINE)) != 0){
Rio_writen(fd, buf, n);
sum += n;
strcat(cache, buf);
}
printf("proxy send %ld bytes to client\n", sum);
if (sum < MAX_OBJECT_SIZE)
writecache(cache, urltemp); //如果可以的话,读入缓存
close(server_fd);
return;
}
void writecache(char* buf, char* key){
sem_wait(&rw->writelock); //需要等待获得写者锁
int index;
/*利用时钟算法,当前指针依次增加,寻找used字段为0的对象*/
/*如果当前used为1,则设置为0,最坏情况下需要O(N)时间复杂度*/
while (cache[nowpointer].used != 0){
cache[nowpointer].used = 0;
nowpointer = (nowpointer + 1) % MAX_CACHE;
}
index = nowpointer;
cache[index].used = 1;
strcpy(cache[index].key, key);
strcpy(cache[index].value, buf);
sem_post(&rw->writelock); //释放锁
return;
}
int readcache(int fd, char* url){
sem_wait(&rw->lock); //读者等待并获取锁(因为要修改全局变量,可能是线程不安全的,所以要锁)
if (rw->readers == 0) //如果没有读者的话,说明可能有写者在写,必须等待并获取写者锁
sem_wait(&rw->writelock); //读者再读时,不允许有写着
rw->readers++;
sem_post(&rw->lock); //全局变量修改完毕,接下来不会进入临界区,释放锁给更多读者使用
int i, flag = 0;
// 依次遍历找到缓存,成功则设置返回值为1
for (i = 0; i < MAX_CACHE; i++){
//printf ("Yes! %d\n",cache[i].usecnt);
if (strcmp(url, cache[i].key) == 0){
Rio_writen(fd, cache[i].value, strlen(cache[i].value));
printf("proxy send %d bytes to client\n", strlen(cache[i].value));
cache[i].used = 1;
flag = 1;
break;
}
}
sem_wait(&rw->lock); // 进入临界区,等待并获得锁
rw->readers--;
if (rw->readers == 0) // 如果没有读者了,释放写者锁
sem_post(&rw->writelock);
sem_post(&rw->lock); // 释放锁
return flag;
}
// 解析url,解析为host, port, path
/*可能的情况:
url: /home.html 这是目前大部分的形式,仅由路径构成,而host在Host首部字段中,端口默认80
url: http://www.xy.com:8080/home.html 这种情况下,Host首部字段为空,我们需要解析域名:www.xy.com,端口:8080,路径:/home.html*/
//该函数没有考虑参数等其他复杂情况
void parse_url(char* url, struct UrlData* u){
char* hostpose = strstr(url, "//");
if (hostpose == NULL){
char* pathpose = strstr(url, "/");
if (pathpose != NULL)
strcpy(u->path, pathpose);
strcpy(u->port, "80");
return;
} else{
char* portpose = strstr(hostpose + 2, ":");
if (portpose != NULL){
int tmp;
sscanf(portpose + 1, "%d%s", &tmp, u->path);
sprintf(u->port, "%d", tmp);
*portpose = '\0';
} else{
char* pathpose = strstr(hostpose + 2, "/");
if (pathpose != NULL){
strcpy(u->path, pathpose);
strcpy(u->port, "80");
*pathpose = '\0';
}
}
strcpy(u->host, hostpose + 2);
}
return;
}
void change_httpdata(rio_t* rio, struct UrlData* u, char* new_httpdata){
static const char* Con_hdr = "Connection: close\r\n";
static const char* Pcon_hdr = "Proxy-Connection: close\r\n";
char buf[MAXLINE];
char Reqline[MAXLINE], Host_hdr[MAXLINE], Cdata[MAXLINE];//分别为请求行,Host首部字段,和其他不东的数据信息
sprintf(Reqline, "GET %s HTTP/1.0\r\n", u->path); //获取请求行
while (Rio_readlineb(rio, buf, MAXLINE) > 0){
/*读到空行就算结束,GET请求没有实体体*/
if (strcmp(buf, "\r\n") == 0){
strcat(Cdata, "\r\n");
break;
}
else if (strncasecmp(buf, "Host:", 5) == 0){
strcpy(Host_hdr, buf);
}
else if (!strncasecmp(buf, "Connection:", 11) && !strncasecmp(buf, "Proxy_Connection:", 17) &&!strncasecmp(buf, "User-agent:", 11)){
strcat(Cdata, buf);
}
}
if (!strlen(Host_hdr)){
/*如果Host_hdr为空,说明该host被加载进请求行的URL中,我们格式读从URL中解析的host*/
sprintf(Host_hdr, "Host: %s\r\n", u->host);
}
sprintf(new_httpdata, "%s%s%s%s%s%s", Reqline, Host_hdr, Con_hdr, Pcon_hdr, user_agent_hdr, Cdata);
return;
}
tiny.c:
int main(int argc, char **argv)
{
int listenfd, connfd;
char hostname[MAXLINE], port[MAXLINE];
socklen_t clientlen;
struct sockaddr_storage clientaddr;
/* Check command line args */
if (argc != 2) {
fprintf(stderr, "usage: %s <port>\n", argv[0]);
exit(1);
}
// 1.Open_listenfd 获取到请求
listenfd = Open_listenfd(argv[1]);
while (1) {
clientlen = sizeof(clientaddr);
// 2.Accept 接受请求
connfd = Accept(listenfd, (SA *)&clientaddr, &clientlen); //line:netp:tiny:accept
Getnameinfo((SA *) &clientaddr, clientlen, hostname, MAXLINE,
port, MAXLINE, 0);
printf("Accepted connection from (%s, %s)\n", hostname, port);
// 3.doit=处理请求
doit(connfd); //line:netp:tiny:doit
Close(connfd); //line:netp:tiny:close
}
}
修改proxy.c代码,执行命令查看结果:
make clean
make
./driver.sh

















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









