










大批量插入数据
-
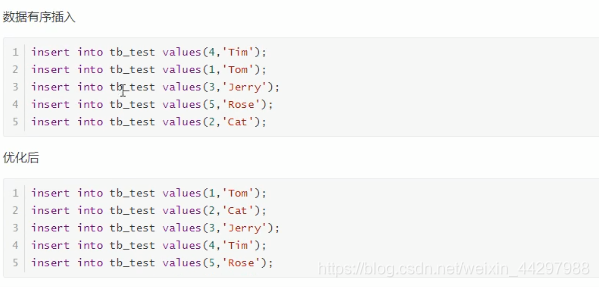
1.建议主键顺序插入,因为主键无序排列文件插入的时候需要花费大量的时间,下面举有列子
-
准备两个存放数据内容的sql语句文件(head 为查询文件前面几行数据的命令)
- 有序数据
-
无序数据
-
加载数据到数据库
load data local infile ’/xxx/xxx/xxx.log' into tb_name fields terminated by ',' lines terminated by '\n';意思为从本地文件系统xxx路径加载数据到tb_name,每一个域之间靠’,'分隔,每一行之间靠\n分隔 -
插入之后可以发现有序加载数据到表只需要20s左右,而无需插入到表却花费一分多钟。
-
2.关闭唯一索引检测,即
SET UNIQUE_CHECKS=0;,在加载数据之后SET UNIQUE_CHECKS=1;,恢复唯一性校验,可以提升导入的效率 -
3.手动提交事物,导入前执行
SET AUTOCOMMIT=0;,在导入后执行SET AUTOCOMMIT=1;打开自动提交,也可以提高导入的速率


优化insert语句

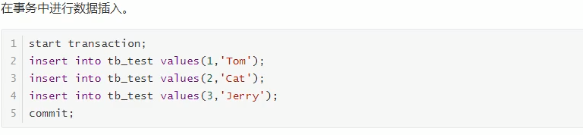
- 为什么插入数据时手动提交事务会比自动提交事务快,刚刚去搜了下:因为自动提交事务没插入一次都要提交一次,而手动提交可以在事务中插入多条数据,然后一次性提交,这样就提升了速度
order by 优化
- MySQL中有俩种排序:filesort,using index
- extra里显示的数据根据是filesort,还是 using index一般是根据select后面要查询的字段有关
- 查询全部即*使用的filesort。
- select后面跟的是覆盖索引,那么extra里出现的是using index
- select后面跟的是覆盖索引,而排序
order by age desc,salary asc;那么会用到useing index 还会用到filesort。即俩者都用到。所以在排序的时候尽量都用降序,或者都用升序 - 还有一个是order by 后面的索引顺序要跟复合索引出现的顺序一样。即
order by age,salary,而不应该出现order by salary,age,否则同样会即用到using index 也会用到 filesort
group by 语句的优化
- group by 时间上也会使用排序操作,与order by 相比,只是多了排序后的分组操作而已
- 如果用到group by 但同时想要避免排序的消耗,可以在后面添加order by null
- group by 也是可以通过索引来提升查询效率的

子查询优化
- 推荐使用多表联查,来替换子查询
or 优化
-
在实际情况中,or前面使用了索引,而后面查询的字段没有使用索引,那么会导致整个索引失效
-
优化:我们可以使用union代替or
-
select * from tb_name where id=1 union select * from tb_name where age=3;

-
union语句type值为ref,or语句type值为range。这是一个很明显的差距
-
union语句的ref值为const,or语句的ref值为null,const表示常量值引用,非常快
-
这俩项说明了union要优于or
优化分页操作
-
一般分页查询时,一个常见又头疼的问题是limit 200000,10,此时会查询表前200010条数据,但仅会返回10条数据即(200001到200010)。那么查询排序的代价较高
-
优化思路一:效率会提升一大半
select * from tb_name a (select id from tb_name order by id limit 200000,10) b where a.id=b.id; -
优化思路二:该方案适用于主键自增的表,且不能出现主键断层,效率极高
select * from tb_name where id>100000 limit 10;














 42万+
42万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









