







网络爬虫可以大大减轻我们在网络访问的工作量,爬虫入门我选择了python的第三方库requests库、bs4库、re库,下面我就对我所学的知识进行简单总结。
目录
一、requests库的介绍
requests库只能爬取需要的内容在其HTML页面中的网站,对于jsp等动态获取的数据还需要通过其他方式。
使用cmd打开命令行输入pip install requests -i https://pypi.tuna.tsinghua.edu.cn/simple/
后面的链接时清华的下载镜像
1.requests库的属性及方法的介绍
requests中的方法和http协议基本一致,有get、post、head、put、patch、delete。
requests.get(url)------获取url位置的资源
requests.post(url)------向url处追加资源
requests.head(url)------获取url位置的头部资源
requests.put(url)------更新url位置的全部资源(覆盖更新)
requests.patch(url)------更新url位置的部分资源(局部更新)
requests.delete(url)------删除url位置的资源
同时requests.get方法返回的是一个response对象,而response对象(下面用r代替response对象)有以下属性:
r.status_code------返回状态码,200表示成功
r.text------返回响应内容
r.encoding----返回从网页头部获取的编码方式
r.apparent_encoding-----返回从网页内容获取的编码方式
r.content----返回二进制的响应内容
除此之外,在使用requests库中的方法时还可以添加额外的参数,参数如下:
params-----可以将字典或者字节序列作为参数添加到url中
data-----可以将字典或者字节序列作为response的内容向服务器提交
jason-----可以将Jason文件作为response的内容提交给服务器
headers-----可以定制访问头信息
files------传输文件
timeout-----设置超时时间
proxies----设置代理服务器
以及其他高级设置参数
2.requests库爬虫的通用框架
requests中的r.raise_for_status()可以处理异常,当返回的状态码不是200时返回HTTPerror异常。
因此request库爬虫的通用框架是
import requests
url = "http://www.baidu.com" #所要爬取的网址
try:
r = requests.get(url) #获取网页内容
r.raise_for_status() #检测异常
r.encoding = r.apparent_encoding #头部编码和内容编码一致
print(r.text) #输出获取的内容或者返回
except:
print("产生异常!")
3.requests爬虫实例
1.爬取我爱竞赛网的某一个比赛
import requests
url = "http://www.52jingsai.com/article-10558-1.html"
try:
r = requests.get(url)
r.raise_for_status()
r.encoding = r.apparent_encoding
print(r.text[:1000])
except:
print("产生异常!")

2.爬取电话归属地查询


import requests
info = {'mobile':'13700000000','action':'mobile'}
url = "https://www.ip138.com/mobile.asp"
kv = {'user-agent':'Chrome/10.0'} #设置爬虫头部防止被拦截
try:
r = requests.get(url,headers=kv,params=info)
r.raise_for_status()
r.encoding = r.apparent_encoding
print(r.text[:1000])
except:
print("产生异常!")

3.爬取图片
首先查看网页中的图片地址
import requests
def getimg(url):
try:
r = requests.get(url)
r.raise_for_status()
return r
except:
print("error!")
def main():
i = 22600
url = "http://img.netbian.com/file/2020/0324/\
small90bc2075285bf9c8fe8fc4a03f0425be1585063342.jpg"
path = "D:/壁纸/image%s"%(i) +".jpg"
fileImage = getimg(url)
with open(path,'wb')as f:
f.write(fileImage.content)
f.close()
return ""
main()

二、bs4库的介绍
beautifulsoup4库是一个能将request库爬取的内容进行解析从而能够更快更准确的或许需要的内容。
使用cmd命令输入pip install beautifulsoup4 -i https://pypi.tuna.tsinghua.edu.cn/simple/
即可安装beautifulsoup4库
1.bs4库的方法及属性的介绍
-
soup = beautifulsoup(HTML文档,解析方式)
解析方式有:
html解释器-------为beautifulsoup4自带的 使用方法 beautiful("data", "html.paser")
lxml的html的解析器-------需要安装 pip install lxml 使用方法 beautiful("data", "lxml")
lxml的xml的解析器-------需要安装 pip install lxml 使用方法 beautiful("data", "xml")
html5lib的xml的解析器-------需要安装 pip install html5lib 使用方法 beautiful("data", "html5lib") -
bs4基本标签
Tag标签——返回一个标签的信息,例如soup.a 为返回一个a标签的信息。
Attributes——返回标签的属性信息(字典类型),例如Soup.a.attrs[href]为返回a标签中的链接属性。
NavigableString——返回标签中非属性字符串,例如soup.a.String表示返回a标签中的提示性字符串。
Comment——返回一个注释 -
bs4标签树的遍历
下行遍历:
.contents——返回所有儿子节点的列表
.children——返回所有儿子节点的迭代类型,用于循环
.descendants——返回孙子节点的迭代类型
上行遍历:
.parent——返回父标签
.parents——返回先辈标签的迭代类型
平行遍历:
.next_sinling——返回按照HTML文本顺序的下一个平行节点
.previous_sibling——返回按照HTML文本顺序的上一个平行节点
.next_siblings——返回按照HTML文本顺序的后续平行节点的迭代类型
.previous_siblings——返回按照HTML文本顺序的前续平行节点的迭代类型 -
bs4常用函数
find_all(Tag,attrs,recursive,string)——返回一个列表类型的查询结果
Tag:表示所要查询的标签。
attrs:表示查询的属性条件。
recursive:表示是否对子孙元素进行全部检索,默认为true。
string:表示对于标签中的非属性字符串的检索。
使用find_all()函数时可以使用简略方式例如:
1.<tag>() 等价于<tag>.find_all()
2.soup() 等价于 soup.find_all()。
同时在使用find_all() 进行查找时还可以结合正则表达式,这样能更高效快捷的查找到需要的信息。
同时find_all()还有以下几种扩展方法(其中参数和find_all()类似):
.find()——搜索且只返回一个字符串类型结果
find_parent()——在先辈节点中返回一个字符串类型结果
find_parents()——在先辈节点中搜索返回一个列表结果
.find_next_sibling()——在后续平行节点中返回一个字符串类型的结果
.find_next_siblings()——在后续平行节点中返回一个列表结果
.find_previous_sibling()——在前序节点中返回一个字符串类型结果
.find_previous_siblings()——在前序节点中返回一个列表结果
2.bs4库的使用
3.requests+bs4库的爬虫实例
import requests
from bs4 import BeautifulSoup
import bs4
def getHtmlText(url):
try:
head = {'user-agen':'Chrome/10.0'} #user-agen为访问头,服务器从这里知道是谁在访问,该例子说明是谷歌浏览器的10.0版本访问
r = requests.get(url, headers=head)
r.encoding = r.apparent_encoding
r.raise_for_status()
return r.text
except:
return ""
def fillUnivList(unlist, html):
soup = BeautifulSoup(html,'html.parser')
for i in soup.find('tbody').children:
if isinstance(i,bs4.element.Tag):
tds = i('td')
unlist.append([tds[0].string, tds[1].string, tds[4].string])
def printUnivList(unlist, num):
print("{0:^10}\t{1:{3}^15}\t{2:^10}".format("排名","学校名称","总分", chr(12288)))
for i in range(num):
u = unlist[i]
print("{0:^10}\t{1:{3}^15}\t{2:^10}".format(u[0],u[1],u[2],chr(12288)))
def main():
unlist = []
url = "http://www.zuihaodaxue.com/subject-ranking/computer-science-engineering.html"
html = getHtmlText(url)
fillUnivList(unlist, html)
printUnivList(unlist,10)
return ""
main()

三、re库
1…re库+requests库的综合实例
re库为正则表达式库,对于re库的介绍我在前一篇文章中介绍过如有需要请移步查看。

import requests
import bs4
from bs4 import BeautifulSoup
import re
def getHtml(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
print("getHtmlError!")
return ""
def parseHtml(htmlText):
try:
godsList = []
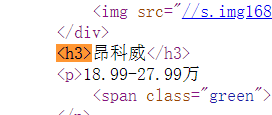
name = re.findall(r"<h3>.+",htmlText)
price = re.findall(r"<p>[\d]+.+万",htmlText)
for i in range(len(name)):
nameG = re.split(r"[>|<]",name[i])[2]
priceG = re.split(r"[>]",price[i])[1]
godsList.append([nameG, priceG])
print(re.split(r"[<p>|<]",price[1])[1])
return godsList
except:
return ""
def printHtml(godsList):
print("{:10}\t{:10}\t".format("名称","价格"))
for listGods in godsList:
print("{:10}\t{:10}\t".format(listGods[0],listGods[1]))
def main():
url = "http://price.16888.com/cn/"
htmlText = getHtml(url)
godsList = parseHtml(htmlText)
printHtml(godsList)
main()

四、Xpath+request爬取网页内容的介绍
使用Xpaht需要导入LXML库,它是效率非常高且简单易学的网页解析库,由于不是标准库,所以需要安装。
pip install lxml
pip install lxml -i https://pypi.tuna.tsinghua.edu.cn/simple/
#第二条,为使用清华大学的镜像,这样就避免访问外网存在的问题
xpath为xml路径语言,它是一种用来确定xml文档中某部分位置的语言。lxml基于xml的树状结构,因此可以快速定位到结构树的某个节点找到自己想要的数据。通过结合request库,以及浏览器的开发者工具,爬虫相比变得十分简单了。下面我通过一个实例来讲解xpath的基本用法,当然xpath也有许多高级用法,感兴趣的可以深入了解。
xpath基础用法
- 通过属性查找元素:xpat路径我们可以通过浏览器的开发者工具(F12)找到对应元素后右击得到,如图可知其xpath路径为//*[@id=“nav-left-menu”]/li[1]/a/img。其中" * " 表示任意标签,利用属性来定位元素类似于上述的[@class=“abcd”]这种语法格式。

-
通过路径查找元素:复制下来该元素的完整路径 :/html/body/div[1]/div/ul/li[1]/a/img。它表示从最外层向最里查找的路径。

-
提取属性值:例如我需要提取其中alt属性名称,即可写为:
import requests
from lxml import etree
header = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) \
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'}
url = "http://www.chinadaily.com.cn/"
html = requests.get(url,headers=header)
html.encoding = 'utf-8'
selector = etree.HTML(html.text)
altName = selector.xpath('/html/body/div[3]/div[4]/a/img/@alt')
print(altName)

提取文本信息,将@alt换成text()即可。

总结
通过上述介绍,个人觉得使用request+xpath进行小规模静态网页爬取十分方便。但我们知道网页分为静态网页和动态网页。静态网页是相对于动态网页而言,是指没有后台数据库、不含程序和不可交互的网页 ;而动态网页就是与后台数据库有交互的网页,有时根据用户的不同操作会有不同的显示内容。因此目前这种爬取模式还不能进行动态网页的爬取,对于动态网页的爬取后续还会进行介绍。















 617
617











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









