







Redis 缓冲区的用法
个人复习笔记
前言
缓冲区的功能是用一块内存空间来暂时存放命令数据,以免出现因为数据和命令的处理速度慢于发送速度而导致的数据丢失和性能问题。但因为缓冲区的内存空间有限,如果往里面写入数据的速度持续地大于从里面读取数据的速度,会导致缓冲区需要越来越多的内存来暂存数据。缓冲区占用的内存超出了设定的上限阈值时,会出现缓冲区溢出。
如果发生了溢出,会丢数据了。随着累积的数据越来越多,缓冲区占用内存空间越来越大,一旦耗尽了 Redis 实 例所在机器的可用内存,就会导致 Redis 实例崩溃。
缓冲区是用来避免请求或数据丢失,只有用对了,才能真正起到“避免”的作用。
Redis 是典型的 client-server 架构,所有的操作命令都需要通过客户端发送给服务器端。缓冲区在 Redis 中主要应用场景:
- 1、是在客户端和服务器端之间进行通信时,用来暂存客户端发送的命令数据,或者是服务器端返回给客户端的数据结果。
- 2、是在主从节点间进行数据同步时,用来暂存主 节点接收的写命令和数据。
一、客户端输入和输出缓冲区
1、结构组成
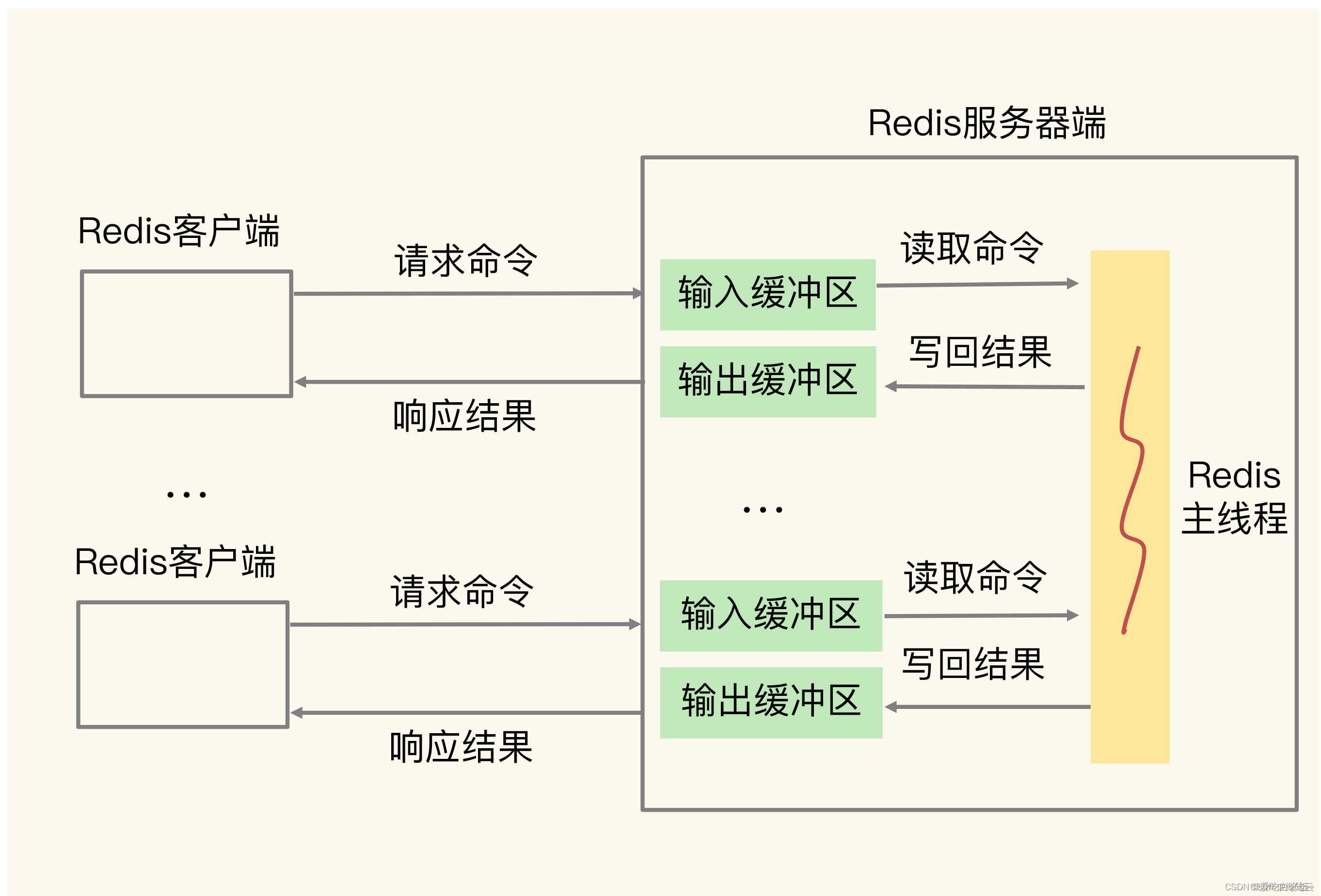
为了避免客户端和服务器端的请求发送和处理速度不匹配,服务器端给每个连接的客户端都设置了一个输入缓冲区和输出缓冲区,称之为客户端输入缓冲区和输出缓冲区。
输入缓冲区会先把客户端发送过来的命令暂存起来,Redis 主线程再从输入缓冲区中读取命令进行处理。当 Redis 主线程处理完数据后,会把结果写入到输出缓冲区,再通过输出缓冲区返回给客户端,如下图:
2、相关命令
要查看和服务器端相连的每个客户端对输入缓冲区的使用情况,使用 CLIENT LIST 命令:
127.0.0.1:6379> client list
d=254487 addr=10.2.xx.234:60240 fd=1311 name= age=8888581 idle=8888581 flags=N
db=0 sub=0 psub=0 multi=-1 qbuf=0 qbuf-free=0 obl=0 oll=0 omem=0 events=r cmd=get
id=300210 addr=10.2.xx.215:61972 fd=3342 name= age=8054103 idle=8054103 flags=N
db=0 sub=0 psub=0 multi=-1 qbuf=0 qbuf-free=0 obl=0 oll=0 omem=0 events=r cmd=get
id=5448879 addr=10.16.xx.105:51157 fd=233 name= age=411281 idle=331077 flags=N
db=0 sub=0 psub=0 multi=-1 qbuf=0 qbuf-free=0 obl=0 oll=0 omem=0 events=r cmd=ttl
id=2232080 addr=10.16.xx.55:32886 fd=946 name= age=603382 idle=331060 flags=N
db=0 sub=0 psub=0 multi=-1 qbuf=0 qbuf-free=0 obl=0 oll=0 omem=0 events=r cmd=get
id=7125108 addr=10.10.xx.103:33403 fd=139 name= age=241 idle=1 flags=N db=0
sub=0 psub=0 multi=-1 qbuf=0 qbuf-free=0 obl=0 oll=0 omem=0 events=r cmd=del
id=7125109 addr=10.10.xx.101:58658 fd=140 name= age=241 idle=1 flags=N db=0
sub=0 psub=0 multi=-1 qbuf=0 qbuf-free=0 obl=0 oll=0 omem=0 events=r cmd=del
...
以下是域的含义:
addr : 客户端的地址和端口
fd : 套接字所使用的文件描述符
age : 以秒计算的已连接时长
idle : 以秒计算的空闲时长
flags : 客户端 flag (见下文)
db : 该客户端正在使用的数据库 ID
sub : 已订阅频道的数量
psub : 已订阅模式的数量
multi : 在事务中被执行的命令数量
qbuf : 查询缓冲区的长度(字节为单位, 0 表示没有分配查询缓冲区)
qbuf-free : 查询缓冲区剩余空间的长度(字节为单位, 0 表示没有剩余空间)
obl : 输出缓冲区的长度(字节为单位, 0 表示没有分配输出缓冲区)
oll : 输出列表包含的对象数量(当输出缓冲区没有剩余空间时,命令回复会以字符串对象
的形式被入队到这个队列里)
omem : 输出缓冲区和输出列表占用的内存总量
events : 文件描述符事件(见下文)
cmd : 最近一次执行的命令
客户端 flag 可以由以下部分组成:
O : 客户端是 MONITOR 模式下的附属节点(slave)
S : 客户端是一般模式下(normal)的附属节点
M : 客户端是主节点(master)
x : 客户端正在执行事务
b : 客户端正在等待阻塞事件
i : 客户端正在等待 VM I/O 操作(已废弃)
d : 一个受监视(watched)的键已被修改, EXEC 命令将失败
c : 在将回复完整地写出之后,关闭链接
u : 客户端未被阻塞(unblocked)
A : 尽可能快地关闭连接
N : 未设置任何 flag
文件描述符事件可以是:
r : 客户端套接字(在事件 loop 中)是可读的(readable)
w : 客户端套接字(在事件 loop 中)是可写的(writeable)
3、注意事项
- CLIENT LIST 命令可以通过输出结果来判断客户端输入缓冲区的内存占用情况。如果 qbuf 很大,而同时 qbuf-free 很小,就要引起注意了,因为这时候输入缓冲区已经占用了很多内存,而且没有什么空闲空间了。此时客户端再写入大量命令的话, 会引起客户端输入缓冲区溢出,Redis 的处理办法就是把客户端连接关闭,结果就是业 务程序无法进行数据存取了。
- 通常情况下 Redis 服务器端不止服务一个客户端,当多个客户端连接占用的内存总量, 超过了 Redis 的 maxmemory 配置项时(例如 4GB),会触发 Redis 进行数据淘汰,可能会产生数据丢失、 键值淘汰,一旦数据被淘汰出 Redis,再要访问这部分数据,就需要去后端数据库读取,降低了业务应用的访问性能。更糟糕的是使用多个客户端,导致 Redis 内存占用过大,也会导致内存溢出OOM(out-of-memory)问题,进而会引起 Redis 崩溃,给业务应用造成严重影响。
- Redis 的客户端输入缓冲区大小的上限阈值,在代码中就设定为了 1GB。Redis 服务器端允许为每个客户端最多暂存 1GB 的命令和数据。1GB 的大小,对于一般的生产环 境已经是比较合适的了。一方面,这个大小对于处理绝大部分客户端的请求已经够用了; 另一方面,如果再大的话 Redis 就有可能因为客户端占用了过多的内存资源而崩溃。
- 所以,Redis 并没有提供参数调节客户端输入缓冲区的大小。如果要避免输入缓冲区溢出,就只能从数据命令的发送和处理速度入手,也就是前面提到的避免客户端写入 bigkey,以及避免 Redis 主线程阻塞。
二、输出缓冲区溢出的应对方法
1、配置防范
Redis 的输出缓冲区暂存的是 Redis 主线程要返回给客户端的数据。主线程返回给客户端的数据,既有简单且大小固定的 OK 响应(例如,执行 SET 命令)或报错信息,也有大小不固定的、包含具体数据的执行结果(例如,执行 HGET 命令)。
Redis 为每个客户端设置的输出缓冲区也包括两部分:
- 1、一个大小为 16KB 的固定缓冲空间,用来暂存 OK 响应和出错信息;
- 2、一个可以动态增加的缓冲空间,用来暂存大小可变的响应结果。
发生输出缓冲区溢出的三种情况:
1、服务器端返回 bigkey 的大量结果;
2、执行了 MONITOR 命令;
3、缓冲区大小设置得不合理。
bigkey 原本就会占用大量的内存空间,所以服务器端返回的结果包含 bigkey,必然会影响输出缓冲区。
MONITOR 命令是用来监测 Redis 执行的。执行这个命令之后,会持续输出监测到的各个命令操作,如下所示:
MONITOR
OK
1600617456.437129 [0 127.0.0.1:50487] "COMMAND"
1600617477.289667 [0 127.0.0.1:50487] "info" "memory"
MONITOR 的输出结果会持续占用输出缓冲区,并越占越多,最后的结果就是发生溢出。建议 MONITOR 命令主要用在调试环境中,不要在线上生产环境中持续使用 MONITOR。如果在线上环境中偶尔使用 MONITOR 检查 Redis 的命令执行情况是没问题的。
输出缓冲区大小设置的问题和输入缓冲区不同,通过 client- output-buffer-limit 配置项来设置缓冲区的大小。设置的内容包括两方面:
1、设置缓冲区大小的上限阈值;
2、设置输出缓冲区持续写入数据的数量上限阈值,和持续写入数据的时间的上限阈值。
在具体使用 client-output-buffer-limit 来设置缓冲区大小的时候,需要先区分下客户端的类型。
配置文件配置
两类客户端和 Redis 服务器端交互:
1、常规和 Redis 服务器端进行读写命令交互的普通客户端;
2、订阅了 Redis 频道的订阅客户端。
3、在 Redis 主从集群中,主节点上也有一类客户端(从节点客户端)用来和从节点进行
数据同步。
# 普通用户client buffer限制
client-output-buffer-limit normal 0 0 0
# 集群从服务器slave client buffer限制
client-output-buffer-limit slave 256mb 64mb 60
# 订阅用户pubsub client buffer限制
client-output-buffer-limit pubsub 32mb 8mb 60
普通客户端:设置缓冲区大小时,在 Redis 配置文件中进行这样的设置:
client-output-buffer-limit normal 0 0 0
normal 表示当前设置的是普通客户端,第 1 个 0 设置的是缓冲区大小限制,第 2 个 0 和第 3 个 0 分别表示缓冲区持续写入量限制和持续写入时间限制。
普通客户端每发送完一个请求,会等到请求结果返回后,再发送下一个请求,这种发送方式称为阻塞式发送。如果不是读取体量特别大的 bigkey, 服务器端的输出缓冲区一般不会被阻塞的。 所以通常把普通客户端的缓冲区大小限制,以及持续写入量限制、持续写入时间限 制都设置为 0,也就是不做限制。
订阅客户端:一旦订阅的 Redis 频道有消息了,服务器端都会通过输出缓冲区把消息发给客户端。所以订阅客户端和服务器间的消息发送方式,不属于阻塞式发送。如果频道消息较多的话,也会占用较多的输出缓冲区空间。 因此给订阅客户端设置缓冲区大小限制、缓冲区持续写入量限制,以及持续写入时间限制,在 Redis 配置文件中设置:
client-output-buffer-limit pubsub 8mb 2mb 60
pubsub 参数表示当前是对订阅客户端进行设置;8mb 表示输出缓冲区的大小上限为 8MB,一旦实际占用的缓冲区大小要超过 8MB,服务器端就会直接关闭客户端的连接;2mb 和 60 表示连续 60 秒内对输出缓冲区的写入量超过 2MB 的话,服务器端也会关闭客户端连接。
集群服务器用户:对于slave的client,默认的限制是,如果buffer达到了256MB,或者达到64MB并持续了1分钟,那么master就会强制断开slave的连接。
client-output-buffer-limit slave 256mb 64mb 60
2、操作注意
如何应对输出缓冲区溢出:
1、避免 bigkey 操作返回大量数据结果;
2、避免在线上环境中持续使用 MONITOR 命令。
3、使用 client-output-buffer-limit 设置合理的缓冲区大小上限,或是缓冲区连续
写入时间和写入量上限。
那么如何快速发现和监控呢? 监控输入缓冲区异常的方法有两种:
1、通过定期执行client list命令, 收集qbuf和qbuf-free找到异常的连接记录
并分析, 最终找到可能出问题的客户端。
2、通过info命令的info clients模块, 找到最大的输入缓冲区, 例如下面命令
中的其中client_biggest_input_buf代表最大的输入缓冲区, 例如可以设置
超过 10M 就进行报警:
127.0.0.1:6379> info clients
# Clients
connected_clients:1414
client_longest_output_list:0
client_biggest_input_buf:2097152
blocked_clients:0
这两种方法各有自己的优劣势, 表对两种方法进行了对比。

三、主从集群中的缓冲区
1、结构组成
主从集群间的数据复制包括全量复制和增量复制两种。全量复制是同步所有数据,增量复制只会把主从库网络断连期间主库收到的命令同步给从库。无论在哪种形式的复制中,为了保证主从节点的数据一致,都会用到缓冲区。但是这两种复制场景下的缓冲区,在溢出影响和大小设置方面并不一样。
复制缓冲区的溢出问题
全量复制过程主节点在向从节点传输 RDB 文件的同时,会继续接收客户端发送的写命令请求。这些写命令就会先保存在复制缓冲区中,等 RDB 文件传输完成后,再发送给从节点去执行。主节点上会为每个从节点都维护一个复制缓冲区,来保证主从节点间的数据同步。

2、注意事项
复制积压缓冲区的英文名字 repl_backlog_buffer。从缓冲区溢出的角度再来回顾下两个重点:复制积压缓冲区溢出的影响,以及如何应对复制积压缓冲区的溢出问题。
- 复制积压缓冲区是一个大小有限的环形缓冲区。当主节点把复制积压缓冲区写满后,会覆盖缓冲区中的旧命令数据。如果从节点还没有同步这些旧命令数据,就会造成主从节点间重新开始执行全量复制。
- 为了应对复制积压缓冲区的溢出问题,调整复制积压缓冲区的大小,如果服务器内存够大,设置 repl_backlog_size 这个参数的值较大点
总结
使用缓冲区以后,当命令数据的接收方处理速度跟不上发送方的发送速度时,缓冲区可以避免命令数据的丢失。
按照缓冲区的用途,例如是用于客户端通信还是用于主从节点复制,把缓冲区分成了客户端的输入和输出缓冲区,以及主从集群中主节点上的复制缓冲区和复制积压缓冲区。在排查问题的时候,可以快速找到方向。从客户端和服务器端的通信过程以及主从节点的复制过程中分析原因。
从缓冲区溢出对 Redis 的影响的角度,把这四个缓冲区分成两类做个总结:
- 缓冲区溢出导致网络连接关闭:普通客户端、订阅客户端,以及从节点客户端,它们使用的缓冲区,本质上都是 Redis 客户端和服务器端之间,或是主从节点之间为了传输命令数据而维护的。这些缓冲区一旦发生溢出,处理机制都是直接把客户端和服务器端的连接,或是主从节点间的连接关闭。网络连接关闭造成的直接影响,就是业务程序无法读写 Redis,或者是主从节点全量同步失败,需要重新执行。
- 缓冲区溢出导致命令数据丢失:主节点上的复制积压缓冲区属于环形缓冲区,一旦发生溢出,新写入的命令数据就会覆盖旧的命令数据,导致旧命令数据的丢失,进而导致主从节点重新进行全量复制。
缓冲区溢出的三个原因:
1、命令数据发送过快过大;
2、命令数据处理较慢;
3、缓冲区空间过小。
缓冲区溢出的三个应对策略:
- 1、针对命令数据发送过快过大的问题,对于普通客户端来说可以避免 bigkey,而对于复制缓冲区来说,就是避免过大的 RDB 文件。
- 2、针对命令数据处理较慢的问题,解决方案就是减少 Redis 主线程上的阻塞操作,例如使用异步的删除操作。
- 3、针对缓冲区空间过小的问题,解决方案就是使用 client-output-buffer-limit 配置项设置合理的输出缓冲区、复制缓冲区和复制积压缓冲区大小。输入缓冲区的大小默认是固定的,无法通过配置来修改它,除非直接去修改 Redis 源码。














 3427
3427











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









