







Unsupervised Audio Source Separation using Generative Priors论文解读
本文以读懂Unsupervised Audio Source Separation using Generative Priors论文(Interspeech2020)为主线,对WaveGAN、Deep Audio Prior(DAP)、Projected Gradient Descent(PGD) optimization等该论文所应用的方法一并做了解读,以帮助读者更好地理解该论文的思路脉络。
1. 相关介绍
1.1 Audio source separation
首先想请大家了解一下什么是音源分离,下面是我粗略整理的思维导图:

音源分离是将各组成源信号从给定的混合音频中恢复分离出来的过程。
一些应用场景和分类包括:语音增强、音频去混响、音频降噪、说话人分离和声源定位(仅针对多声道音源分离)等。
至于当下的音源分离研究现状是怎样的,请见下图总结:

- 关于ill-posed 问题:一个例子是声纹的集外处理,比如测试集出现了训练集中没有的音源。
1.2 Motivation
有这样一些方法常用于音源分离:
-
Matrix Factorization 矩阵分解机
传统的音源分离方法主要是矩阵分解机,通过矩阵分解可以实现在混合音频数量多于要分离出的音源的数量的情况下(over-determined senarios)的音频分离,但是对混合音频数量少于要分离出的音源的数量的场景(under-determined senarios)无能为力。主要的方法包括ICA、PCA、NMF、FastICA、KernelPCA等(这五个方法也是我们后来作为实验比较对象所用到的方法)。 -
Supervised Deep Learning 有监督的深度学习方法
随着深度学习的火热,音源分离也尝试将神经网络引入任务中来,它可以解决传统的矩阵分解机无法分离under-determined 场景的方法。缺点是需要大量的观测标签数据,以及当训练所用的给定音源和混合过程改变时,模型需要重新训练(re-training),这是一件耗时又麻烦的事。目前有基于时域和谱域的有监督的深度学习方法。 -
Unsupervised methods 基于无监督学习的音源分离方法
为了解决有监督的深度学习所需带标签的观测数据集大的问题,引入了无监督学习方法。无监督学习方法,可以利用数据驱动模型的优势,利用有意义的先验知识对带标签数据集的缺乏问题做一定程度的缓解。 -
Priors utilization 对于先验知识的利用
为了解决re-training问题,人们想到利用一些先验知识对其进行改善,包括如下几种:
a. 统计学先验知识
该类方法往往基于一定的统计学假设,比如非高斯性和独立性等,使用起来会受一定限制。
b. 结构上的先验
一些深度神经网络的的设计表明特定的精心选择的网络,有调整或者作为一个先验来解决病态的inverse problems的内在能力。Deep Audio Prior就是一个例子,他通过随机初始化神经网络结构,利用U-Net网络(利用了反卷积神经网络deconvolution neural network的思想)来学习时频掩码,从而达到音源分离的效果。
c. GAN 先验
第三种基于先验的方法是通过使用经过生成式模型(比如生成对抗网络GAN)定义的先验。因为GAN能够从充足的无标签数据中学习参数化的非线性分布 p ( X ; z ) p(X;z) p(X;z),其中z为模型隐变量。利用后验分布 p ( X = x ∣ x ^ ; z ) p(X=x| \hat x;z) p(X=x∣x^;z),我们可以利用隐变量 z z z和被损坏的观测数据 x ^ \hat x x^推测恢复出原有的完整数据。这也是利用GAN先验可以实现音源分离的理论依据之一。因为后验分布不能被可分析地表达,故在实践中,本文使用诸如PGD优化器的迭代方法来评估隐藏特征 z ^ \hat z z^,然后从生成器中采样,就是说 p ( X ; z = z ^ ) p(X;z=\hat z) p(X;z=z^).
在这里,本文主要使用无监督的方法,通过利用特定源的先验,基于精心设计的基于谱域的损失函数的投影梯度下降优化器来完成音源分离。
2. 方法
2.1 Overview
以下是本文提出方法的框架结构和算法:
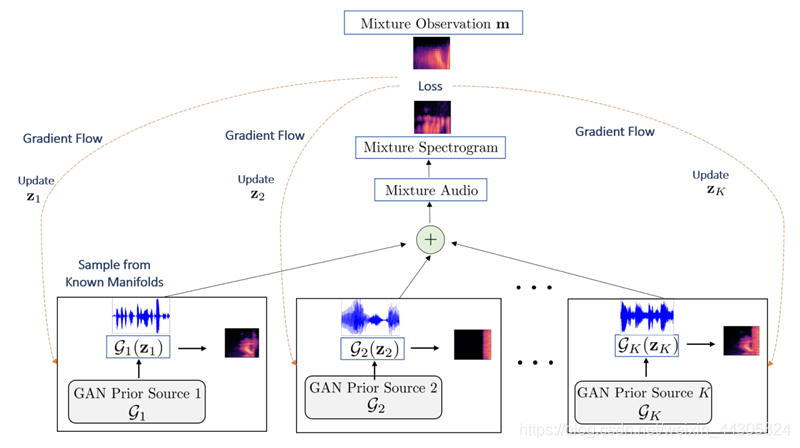

首先输入无标签的混合音频m(反映该方法的无监督性),要分离的源的数量K,和预训练好的GAN先验模型;我们所期望的输出是评估源集合 { s ^ i ∗ } i = 1... K \{\hat s ^*_i\}_{i=1...K} {
s^i∗}i=1...K.
首先将隐向量
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









