







实验五 语义分析器
一. 学习经典的语义分析器(2小时)
一、实验目的
学习已有编译器的经典语义分析源程序。
二、实验任务
阅读已有编译器的经典语义分析源程序,并测试语义分析器的输出。
三、实验内容
(1)选择一个编译器:
选择一个编译器,如:TINY或其它编译器也可(需自备源代码)。
我所选用的是TINY源码进行分析,目录结构如下,其中语义分析器在loucomp文件夹下的analyze.c和symtab.c中
analyse:用于语义分析本身
symtab:用于生成其对应的符号表。
(2)阅读语义分析源程序
阅读语义分析源程序,加上你自己的理解。尤其要求对相关函数与重要变量的作用与功能进行稍微详细的描述。若能加上学习心得则更好。TINY语言请参考《编译原理及实践》第6.5节
-
T I N Y语言在其静态语义要求方面特别简单
语义分析程序也将反映这种简单性。在 T I N Y中没有明确的说明,也没有命名的常量、数据类型或过程;名字只引用变量。变量在使用时隐含地说明,所有的变量都是整数数据类型。也没有嵌套作用域,因此变量名在整个程序有相同
的含义,符号表也不需要保存任何作用域信息。 -
在T I N Y中类型检查也特别简单
只有两种简单类型:整型和布尔型。仅有的布尔型值是两个整数值的比较的结果。因为没有布尔型操作符或变量,布尔值只出现在 i f或r e p e a t语句的测
试表达式中,不能作为操作符的操作数或赋值的值。最后,布尔值不能使用 write语句输出。
1.语法树结构
analyze.c
语义分析程序所基于的TINY的语法和语法树结构在我们在前面的实验中已经描述过了,因此在本实验中我只是简单的阐述一下。
T I N Y有两种基本的结构类型:
语句和表达式。语句共有 5类( i f语句、 r e p e a t语句、 a s s i g n语句、 r e a d语句和w r i t e语句) ,表达式共有 3类(算符表达式、常量表达式和标识符表达式)
因此,语法树节点首先按照它是语句还是表达式来分类,接着根据语句或表达式的种类进行再次分类。树节点最大可有 3个孩子的结构(仅在带有 e l s e部分的i f语句中才需要它们) 语句通过同属域而不是使用子域来排序。
①节点类型:
/*用于分析的语法树*/
typedef enum {StmtK,ExpK} NodeKind; //节点类型
②表达式类型:
typedef enum {IfK,WhileK,ForEach,AssignK,InputK,PrintK} StmtKind; //语句类(statment)
③表达式种类:
typedef enum {OpK,ConstK,IdK} ExpKind; //表达式类(expression)算符表达式、常量表达式和标识符表达式
④语法树的节点定义:
树的结点种类NodeKind分为StmtK和ExpK两类,两类又有各自的子类。在语法树中标明种类有利于代码生成,当遍历语法树检测到特定类型时就可以进行特定的处理。treeNode结构为指向孩子和兄弟的节点。
语句通过同属域而不是子域来排序,即由父亲到他的孩子的唯一物理连接是到最左孩子的。孩子则在一个标准连接表中自左向右连接到一起,这种连接称作同属连接,用于区别父子连接。
/*ExpType用于类型检查*/
typedef enum {Void,Integer,Boolean} ExpType; //表达式种类
#define MAXCHILDREN 3
//语法树的节点
typedef struct treeNode //语法树的节点
{
struct treeNode * child[MAXCHILDREN]; //子节点, 三元
struct treeNode * sibling; //兄弟节点
int lineno; //当前读取到的行号
NodeKind nodekind; //节点类型
//类型
union {
StmtKind stmt; //语句类型
ExpKind exp; //表达式类型
} kind;
//属性
union {
TokenType op; //操作符
int val; //值
char * name; //字段名
} attr;
//表达式类型
ExpType type; //表达式类型
} TreeNode;
2.语义分析结构
-
符号表建立思路:
TINY的静态语义共享标准编程语言的特性,符号表的继承属性,而表达式的数据类型是合成属性。因此,符号表可以通过对语法树的前序遍历建立,类型检查通过后序遍历完成。
//函数buildSymtab按语法树的前序遍历构造符号表 void buildSymtab(TreeNode * syntaxTree) { traverse(syntaxTree,insertNode,nullProc); if (TraceAnalyze) { fprintf(listing,"\nSymbol table:\n\n"); printSymTab(listing); } }// typeCheck通过后序语法树遍历进行类型检查 void typeCheck(TreeNode * syntaxTree) { traverse(syntaxTree,nullProc,checkNode); } -
第1个过程完成语法树的前序遍历
当它遇到树中的变量标识符时,调用符号表
st_insert过程。遍历完成后,它调用printSymTab打印列表文件中存储的信息。第 2个过程完成语法
树的后序遍历,在计算数据类型时把它们插入到树节点,并把任意的类型检查错误记录到列表文件中。这些过程及其辅助过程的代码包含在analyze.c文件中。 -
第 2个过程完成语法树的后序遍历
在计算数据类型时把它们插入到树节点,并把任意的类型检查错误记录到列表文件中
-
为强调标准的树遍历技术,实现
buildSymtab和typeCheck使用了相同的通用遍历函数traverse,它接受两个作为参数的过程 (和语法树),一个完成每个节点的前序处理,一个进行后序处理
/*
*过程遍历是一种通用的递归方法
*语法树遍历例程:它使用在前序中的preProc和后序中的postProc进行遍历
*/
static void traverse( TreeNode * t,void (* preProc) (TreeNode *),void (* postProc) (TreeNode *) )
{ if (t != NULL)
{
preProc(t);
{ int i;
for (i=0; i < MAXCHILDREN; i++)
traverse(t->child[i],preProc,postProc); //先序遍历
}
postProc(t);
traverse(t->sibling,preProc,postProc); //后续遍历
}
}
-
insertNode函数
基于它通过参数 (指向语法树节点的指针)接受的语法树节点的种类,确定何时把一个标识符 (与行号和地址一起 )插入到符号表中。对于语句节点的情况,包含变量引用的节点是赋值节点和读节点,被赋值或读出的变量名包含在节点的a t t r . n a m e字段中。对表达式节点的情况,感兴趣的是标识符节点,名字也存储在a t t r . n a m e中。因此,在那 3个位置,如果还没有看见变量i n s e r t N o d e过程包含一个
st_insert (t->attr.name, t->lineno, location++);调用(与行号一起存储和增加地址计数器 )如果变量已经在符号表中,则st_insert (t->attr.name,t->lineno,0);(存储行号但没有地址)。
最后,在符号表建立之后, b u i l d S y m t a b完成对p r i n t S y mTa b的调用,在标志T r a c e A n a l y z e的控制下(在m a i n . c中设置),在列表文件中写入行号信息。// 程序将存储在t中的标识符节点插入符号表 static void insertNode( TreeNode * t) { switch (t->nodekind) { case StmtK: switch (t->kind.stmt) { case AssignK: case ReadK: if (st_lookup(t->attr.name) == -1) /* not yet in table, so treat as new definition */ /*还不在表中,因此视为新定义*/ st_insert(t->attr.name,t->lineno,location++); else /* already in table, so ignore location, add line number of use only */ /*已经在表中,所以忽略位置,仅添加使用的行号*/ st_insert(t->attr.name,t->lineno,0); break; default: break; } break; case ExpK: switch (t->kind.exp) { case IdK: if (st_lookup(t->attr.name) == -1) /* not yet in table, so treat as new definition */ /*还不在表中,因此视为新定义*/ st_insert(t->attr.name,t->lineno,location++); else /* already in table, so ignore location, add line number of use only */ /*已经在表中,所以忽略位置,仅添加使用的行号*/ st_insert(t->attr.name,t->lineno,0); break; default: break; } break; default: break; } }
(3)理解符号表的定义
理解符号表的定义(栏目设置)与基于抽象语法树的类型检查/推论的实现方法(树遍历)。
0.符号表的结构
-
在编译器中符号表是一个典型的目录数据结构。主要实现插入、查找和删除这 3种基本操作。目录结构的典型实现包括线性表、各种搜索树结构 (二叉搜索树、 AV L树、 B树)以及杂凑表( h a s h表)等。
-
杂凑表是一个入口数组,称作“桶 ( b u c k e t )”,使用一个整数范围的索引,通常从 0到表的尺寸减1。杂凑函数(hash fuction)把索引键(在这种情况下是标识符名,组成一个字符串 )转换成索引范围内的一个整数的杂凑值,对应于索引键的项存储在这个索引的“桶”中
-
如下图结构:
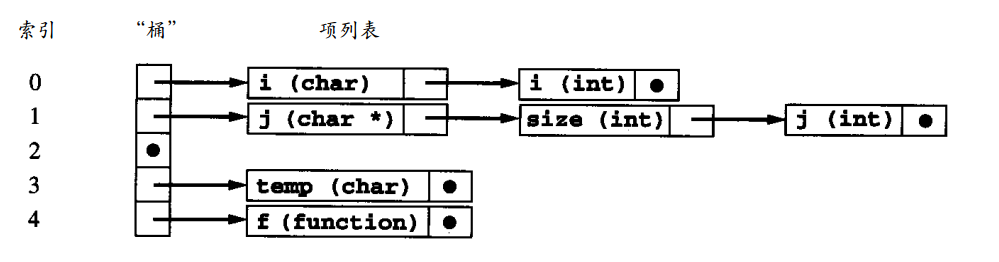
// 存储行序列的结构体
typedef struct LineListRec
{ int lineno;
struct LineListRec * next;
} * LineList;
/*
存储桶列表中的记录每个变量,包括名称,分配的内存位置
以及它出现在源代码中的行号列表
*/
typedef struct BucketListRec
{ char * name; //变量名
LineList lines; //行号
int memloc ; //变量的内存位置
struct BucketListRec * next; //下一个节点
} * BucketList;
1.理解符号表的定义(栏目设置)
-
一般情况数据类型和作用域信息需要保存在符号表中。
-
因为 T I N Y没有作用域信息,并且所有的变量都是整型, T I N Y符号表不需要保存这些信息。
-
在代码产生期间,变量需要分配存储器地址,并且因为在语法树中没有说明,因此符号表是存储这些地址的逻辑位置。
-
地址可以仅仅看成是整数索引,每次遇到一个新的变量时增加。为使符号表更加有趣和有用,还使用符号产生一个交叉参考列表,显示被访问变量的行
下面是对于以下程序的TINY符号表,包括符号名,位置,行号([]) read x; { input an integer } if 0 < x then { don't compute if x <= 0 } fact := 1; repeat fact := fact * x; x := x - 1 until x = 0; write fact { output factorial of x } end

- 在
symtab.c中定义了BucketListRec,用来表示符号表
/*
存储桶列表中的记录每个变量,包括名称,分配的内存位置
以及它出现在源代码中的行号列表
*/
typedef struct BucketListRec
{ char * name; //变量名
LineList lines; //行号
int memloc ; //变量的内存位置
struct BucketListRec * next; //下一个节点
} * BucketList;
2.类型检查和推论的实现方法
讨论每种语言构造的类型推断和类型检查规则。

(1) 说明
引起标识符的类型进入符号表。因此,文法规则
var-decl -> id : type -> exp
有相应的语义动作:
insert(id.name,type-exp.type)
把标识符插入到符号表并关联一个类型。在这个插入中相关的类型根据 type-exp 的文法规则构造
- 假定类型保持某种树形结构,因此在文法的一种结构类型array对应于语义动作makeTypeNode (array.size.type)构成一个类型节点
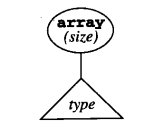
这里数组节点的子孙是 t y p e参数给定的类型树。在树的表示中假定简单类型 integer和boolean构成了标准叶子节点
(2) 语句
语句本身没有类型,但对类型正确性而言需要检查子结构。一般的情形是在示例文法中两个语句规则, i f语句和赋值语句。在 i f语句的情况中,条件表达式必须是布尔类型。这通过规则
if not typeEqual (exp.type,boolean) thentype-error(stmt)
表示,这里type-error指示一个错误报告机制,其属性将简要地描述。
(3) 表达式
常量表达式,像数字及布尔值true和false,隐含地说明了integer和boolean类型。变量名在符号表中通过 lookup操作确定它们的类型。其他表达式通过操作符构成,如算术操作符+、布尔操作符or、以及下标操作符[ ]。对每种情况子表达式都必须是指定操作的正确类型。对于下标的情况,这由规则:
if isArrayType(exp2.type) and typeEqual(exp3.type, integer)
then exp1.type:= exp2.type.child1
else type-error(exp1)
-
类型检查遍的
checkNode函数这个函数完成两个任务,首先,基于子节点的类型,它必须确定是否出现了类型错误。
其次,它必须为当前节点推断一个类型(如果它有一个类型)并且在树节点中为这个类型分配一个新的字段
//在单个树节点上进行类型检查
//完成两个任务,首先,基于子节点的类型,它必须确定是否出现了类型错误。
//其次,它必须为当前节点推断一个类型(如果它有一个类型)并且在树节点中为这个类型分配一个新的字段
static void checkNode(TreeNode * t)
{ switch (t->nodekind)
{ case ExpK: //表达式节点
switch (t->kind.exp)
{ case OpK:
if ((t->child[0]->type != Integer) ||
(t->child[1]->type != Integer))
typeError(t,"Op applied to non-integer"); //确定是否出现了类型错误
if ((t->attr.op == EQ) || (t->attr.op == LT)) //分配一个新的字段,确定类型
t->type = Boolean; //boolean
else
t->type = Integer; //Integer
break;
case ConstK:
case IdK:
t->type = Integer; //ConstK和IdK类型默认是Integer
break;
default:
break;
}
break;
case StmtK: //语句节点
switch (t->kind.stmt)
{ case IfK: //确定是否出现了类型错误
if (t->child[0]->type == Integer)
typeError(t->child[0],"if test is not Boolean");
break;
case AssignK:
if (t->child[0]->type != Integer)
typeError(t->child[0],"assignment of non-integer value");
break;
case WriteK:
if (t->child[0]->type != Integer)
typeError(t->child[0],"write of non-integer value");
break;
case RepeatK:
if (t->child[1]->type == Integer)
typeError(t->child[1],"repeat test is not Boolean");
break;
default:
break;
}
break;
default:
break;
}
}
类型检查的其他主题
- 重载
- 类型转换和强制
- 多态性类型
(4)测试语义分析器。
测试语义分析器,对TINY语言要求输出测试程序的符号表与测试结果。
TINY语言:
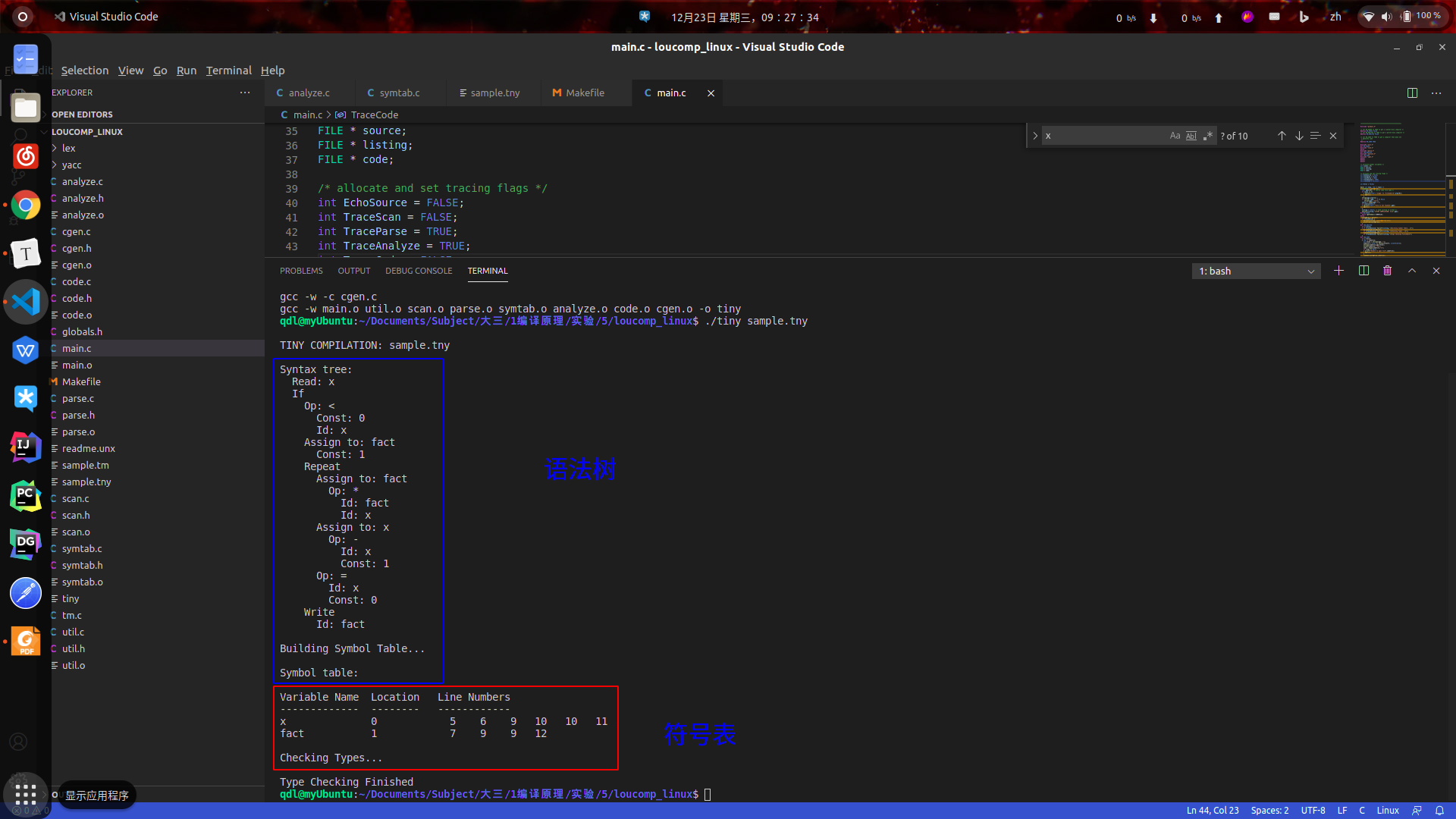
- 测试用例一:
sample.tny
$ make
$ ./tiny sample.tny
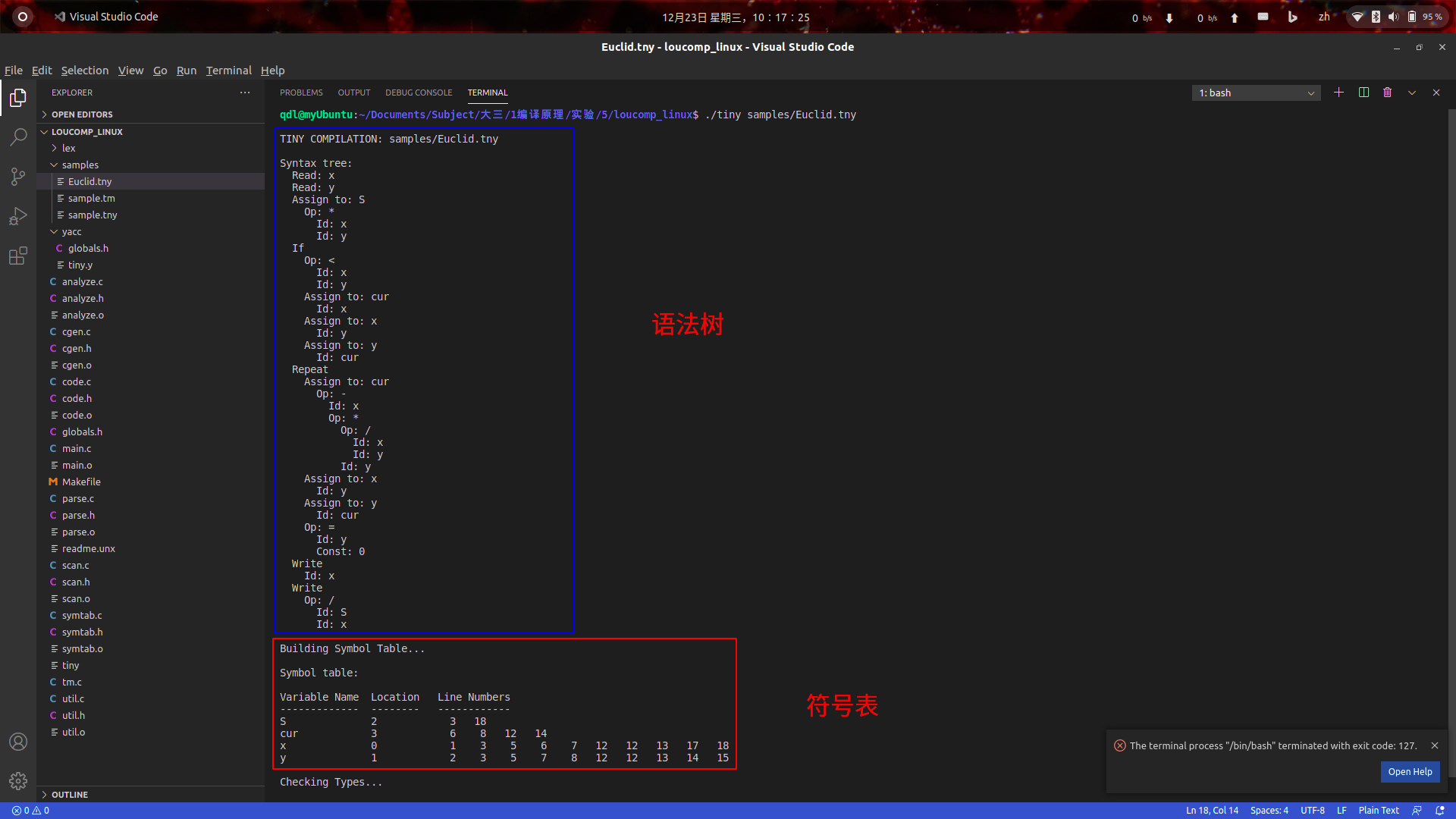
- 测试用例二:用TINY语言自编一个程序计算任意两个正整数的最大公约数与最大公倍数。
read x;
read y;
S:=x*y;
if x < y then
cur := x;
x := y;
y := cur
end;
repeat
cur := x - (x / y)*y;
x := y;
y := cur
until y = 0;
write x;
write (S / x)
二. 实现一门语言的语义分析器(3小时)
一、实验目的
通过本次实验,加深对语义分析的理解,学会编制语义分析器。
二、实验任务
用C或JAVA语言编写一门语言的语义分析器。
三、实验内容
(1)语言确定
C-语言,其定义在《编译原理及实践》附录A中。也可选择其它语言,不过要有该语言的详细定义(可仿照C-语言)。一旦选定,不能更改,因为要在以后继续实现编译器的其它部分。鼓励自己定义一门语言。
我选用的是CMinus语言
(2)C-符号表的定义设计和类型检查/推论的实现
1.完成C-语言的符号表的定义设计
为了应对上面的需求,我们可通过哈希表来实现符号表的设计。
- 符号表的定义设计,包括包括名称、分配的内存位置以及它在源代码中出现的行号列表, 非全局变量global
Scope Variable Name Location Type isArr ArrSize isFunc isParam Line Numbers
----- ------------- -------- ---- ----- ------- ------ ------- ------------
1 u 3 int no 0 no yes 4 5 6 6
1 v 4 int no 0 no yes 4 5 6 6 6
Type error at line 13: unknown function name
1 x 0 int no 0 no no 11 13
1 y 1 int no 0 no no 11 13
0 main 0 void no 0 yes no 10
0 i 0 int no 0 no no 1
0 j 1 int no 0 no no 2
0 gcd 2 int no 0 yes no 4
- 数据结构:
散列,存储桶BucketListRec
// 存储桶中的记录列出了每个变量,包括名称、分配的内存位置以及它在源代码中出现的行号列表
typedef struct BucketListRec
{ char * name; //变量名
LineList lines; //行号
int scope; //作用域,越小作用域越高
TreeNode *tnode_p; //语法树节点保存变量的信息
int memloc ; //分配的内存位置
struct BucketListRec * next;
} * BucketList;
- 行号列表
LineListRec
// 引用变量的源代码的行号列表
typedef struct LineListRec
{ int lineno;
struct LineListRec * next;
} * LineList;
2.规划类型检查/推论的实现方法
讨论每种语言构造的类型推断和类型检查规则。
(1) 说明
引起标识符的类型进入符号表。因此,文法规则
var-decl -> id : type -> exp
有相应的语义动作:
insert(id.name,type-exp.type)
把标识符插入到符号表并关联一个类型。在这个插入中相关的类型根据 type-exp 的文法规则构造
扩增一些其他的文法规则…
- 假定类型保持某种树形结构,因此在文法的一种结构类型array对应于语义动作makeTypeNode (array.size.type)构成一个类型节点
这里数组节点的子孙是 type参数给定的类型树。在树的表示中假定简单类型 integer和boolean构成了标准叶子节点
(2) 语句
语句本身没有类型,但对类型正确性而言需要检查子结构。一般的情形是在示例文法中两个语句规则, i f语句和赋值语句。在 i f语句的情况中,条件表达式必须是布尔类型。这通过规则
if not typeEqual (exp.type,boolean) thentype-error(stmt)
表示,这里type-error指示一个错误报告机制,其属性将简要地描述。
(3) 表达式
常量表达式,像数字及布尔值true和false,隐含地说明了integer和boolean类型。变量名在符号表中通过 lookup操作确定它们的类型。其他表达式通过操作符构成,如算术操作符+、布尔操作符or、以及下标操作符[ ]。对每种情况子表达式都必须是指定操作的正确类型。对于下标的情况,这由规则:
if isArrayType(exp2.type) and typeEqual(exp3.type, integer)
then exp1.type:= exp2.type.child1
else type-error(exp1)
-
类型检查遍的
checkNode函数这个函数完成两个任务,首先,基于子节点的类型,它必须确定是否出现了类型错误。
其次,它必须为当前节点推断一个类型(如果它有一个类型)并且在树节点中为这个类型分配一个新的字段
// 过程checkNode在单个树节点上执行类型检查
//完成两个任务,首先,基于子节点的类型,它必须确定是否出现了类型错误。
//其次,它必须为当前节点推断一个类型(如果它有一个类型)并且在树节点中为这个类型分配一个新的字段
static void checkNode(TreeNode * t)
{
BucketList l,r;
int i,j;
TreeNode * s;
TreeNode * p;
switch (t->nodekind)
{
case DeclK: //数据类型
switch (t->kind.decl){
case varK: //变量节点
if(t->child[0] != NULL){
if(t->child[0]->type == Integer){ //Integer
t->type = t->child[0]->type; //分配一个新的字段,确定类型
}
else{ //检查错误
typeError(t,"Variable should not be void type");
}
}
break;
case funK: //同上,函数类型
if(strcmp(t->attr.name, "main")==0){
if(t->sibling != NULL){ //没有兄弟节点,对于函数类型节点,错误
typeError(t,"main is not the last function");
}
else{
if(t->child[1]->type != Void){ //void
typeError(t,"main has parameter");
}
if(t->child[0]->type != Void){ //void
typeError(t,"main is not void type");
}
}
}
i=0;
if(t->child[1]->type != Void){ //如果字节点不为void,扫描参数列表
s = t->child[1];
while(s != NULL){
if(i > 0 && s->type == Void){
typeError(s,"Void parameter is allowed when it is the first parameter");
}
i++; //记录列表长度
s = s->sibling; //迭代
}
}
break;
case paramK: //检查参数
if(t->array_size != -1){
t->type = t->child[0]->type;
}
break;
}
break;
case ExpK: //表达式节点
switch (t->kind.exp)
{
case IdK: //Id类型,查表
l = st_type_lookup (t->attr.name);
if (l == NULL) break;
if ( l->tnode_p->array_size > 0 ) { // should be array
// 注意这个地方不能直接比较array_size == 0, 因为t有可能是一个数组指针,NULL == 0
if (t->array_size > 0) {
//满足数组定义,arr[const]
if(t->child[0]->nodekind == ExpK && t->child[0]->kind.exp == ConstK){
if(t->child[0]->attr.val < 0){ //如果val < 0说明出现了错误
typeError(t,"Negative Subscript Error");
}
}
else if(t->child[0]->type != Integer){ //如果index部位Integer类型,说明出现错误
typeError(t,"Array Index Type Error");
}
}
}
else if (l->tnode_p->array_size == 0) //数组大小被定义为0
{ // should be var
if (t->array_size > 0) {
typeError(t,"Wrong type!");
}
}
break;
case CalcK: //计算类型,要求0,2两个子节点为Integer
if ((t->child[0]->type != Integer) ||
(t->child[2]->type != Integer)){
typeError(t,"Op applied to non-integer");
}
else{
t->type = Integer; //分配一个新的字段,确定类型
}
break;
}
break;
case StmtK: //语句类型
switch (t->kind.stmt)
{
case IfK: //If语句,要求child0的属性为0,并且数值为1
if(t->child[0]->attr.val != 0 && t->child[0]->attr.val != 1){
typeError(t->child[0],"if test is not Boolean");
}
break;
case AssignK: //赋值语句X = Y
l = r = NULL;
l = st_type_lookup(t->child[0]->attr.name); //检查字节点是否在符号表中
if(t->child[1]->kind.exp == IdK){
r = st_type_lookup(t->child[1]->attr.name); //检查字节点是否在符号表中
}
if(l == NULL){ //如果l为NULL那么左操作数缺失
typeError(t->child[0], "invalid assignment : left operand error");
} else {
if (l->tnode_p->type != Integer) { //如果不是整型,类型异常
typeError(t->child[0],"not integer");
} else if (l->tnode_p->array_size > 0 && t->child[0]->array_size == 0) {
// 如果检测到左操作数是一个数组,但是
typeError(t,"L is array but using without []");
}
}
if(r == NULL){//expr //右侧操作数为NULL,说明不是一个简单的操作数,而可能是一个表达式
if(t->child[1]->type != Integer){ //右操作数缺失
typeError(t->child[1],"invalid assignment : right operand error");
}
} else {
if (r->tnode_p->type != Integer) {
typeError(t->child[1],"not integer");
}
if(t->child[1]->nodekind == ExpK && t->child[1]->kind.exp == IdK){//var = var
if(r->tnode_p->array_size > 0 && t->child[1]->array_size == 0){ //如果是简单赋值,但是没有[]
typeError(t,"R is array but using without []"); //抛出异常
}
}
t->type = Integer;
}
break;
case WhileK: //while状态
if (t->child[0]->type != Integer){ //如果字节点不是Integer类型,抛出异常
typeError(t->child[1],"expression should be integer type");
}
else{
t->type = Integer;
}
break;
case ReturnK: //返回类型
/* l = st_type_lookup(t->attr.name); */
if(t->child[0] == NULL){//void return //返回为空,但是类型不是Void
if (return_type != Void)
typeError(t,"Function has no return, but the function is not void type");
}
else{//data return //返回类型为Void,但是返回val
if (return_type == Void)
typeError(t,"Function has return value, but the function is void type");
if(t->child[0]->kind.stmt == CallK) { //如果字节点为CalK类型的,我们要查找符号表
l = st_type_lookup(t->child[0]->attr.name); //查找符号表
if(l != NULL && l->tnode_p->type != Integer){ //如果call函数不存在或者返回类型不是Integer,出现错误
typeError(t,"return type error"); //返回类型错误
}
} else if (t->child[0]->kind.exp == IdK) { //如果为Id类型
l = st_type_lookup(t->child[0]->attr.name); //查找符号表,Id是否存在
if (l->tnode_p->array_size > 0 && t->child[0]->array_size == 0) { //如果前驱节点arrsize 大于0并且数组的大小==0,返回类型异常
typeError(t,"return type error");
} // case : return array
} else{
if(t->child[0]->type == Void){ //子节点为Void,直接返回异常
typeError(t->child[0],"return type error");
}
}
t->type = Integer;
}
break;
case CallK: //函数调用
l = st_type_lookup(t->attr.name); //查找调用函数名
if(l == NULL){
typeError(t,"unknown function name"); //未找到
}
else{
t->type = l->tnode_p->type; // 函数名未查找到
if(l->tnode_p->paramnum == -1){ //is not function name
typeError(t,"is not function name");
}
else{
i=0;
if(t->child[0] == NULL){//no argument //如果child0 ==NULL说明没有参数
if(l->tnode_p->paramnum != 0){ //如果
typeError(t,"arguments not match");
}
}
else{//some argument // 有参数
s = t->child[0];
while(s != NULL){ // 扫描得到参数个数
i++;
s = s->sibling;
}
if(l->tnode_p->paramnum == i){ // 如果参数数量匹配
s = t->child[0]; // 子节点
p = l->tnode_p->child[1]; // 后续节点
while(s != NULL && p != NULL){
if(s->type != p->type){ // 如果类型不匹配
typeError(s,"argument type is not matched");
}
// 如果是表达式节点,那么我们需要查找符号表
if (s->nodekind == ExpK && s->kind.exp == IdK) {
BucketList tmp = st_type_lookup(s->attr.name);
if (p->array_size == 0) { // 先看arr_size, 如果为0,那么是一个var
if (tmp->tnode_p->array_size > 0 && s->array_size == 0) {
// 但是p是一个arr,不匹配
typeError(s,"argument type is not matched(array to var)");
}
} else if (p->array_size > 0) { // p->arr_size >0 说明是一个数组指针
//should be array pointer
if ( tmp->tnode_p->array_size == 0 ||(tmp->tnode_p->array_size > 0 && s->array_size > 0))
// 但是p是一个var
typeError(s,"argument type is not matched(var to array)");
}
}
s = s->sibling;
p = p->sibling;
}
} else{//number of arguments not match to number of parameters
typeError(t,"arguments not match2");
}
}
}
}
break;
default:
break;
}
break;
default:
break;
}
}
(3)编写选定语言的语义分析器
仿照前面学习的语义分析器,编写选定语言的语义分析器。
见代码
(4)测试
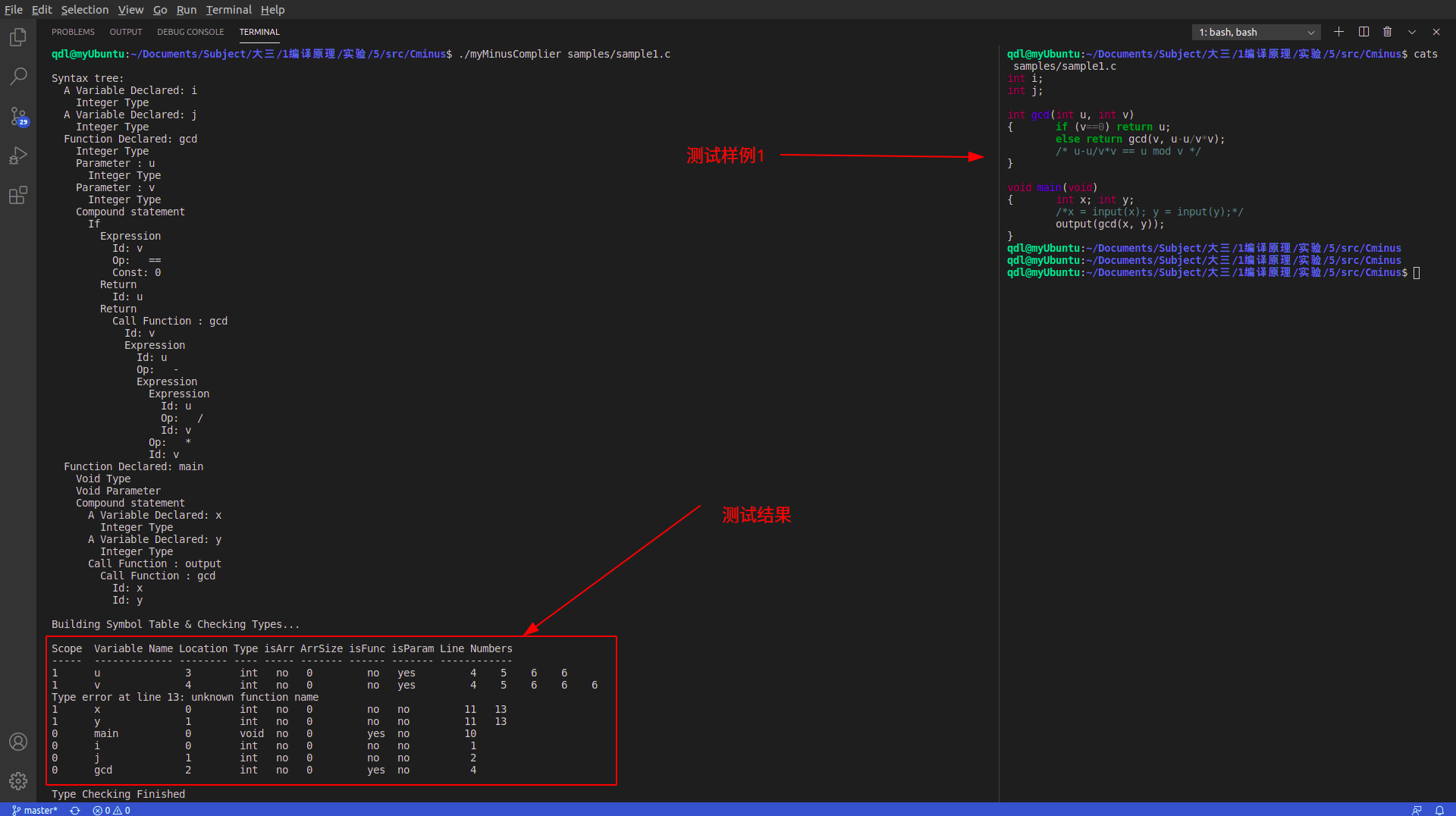
准备2~3个测试用例,测试并解释程序的运行结果
int i;
int j;
int gcd(int u, int v)
{ if (v==0) return u;
else return gcd(v, u-u/v*v);
/* u-u/v*v == u mod v */
}
void main(void)
{ int x; int y;
/*x = input(x); y = input(y);*/
output(gcd(x, y));
}
sample1.c
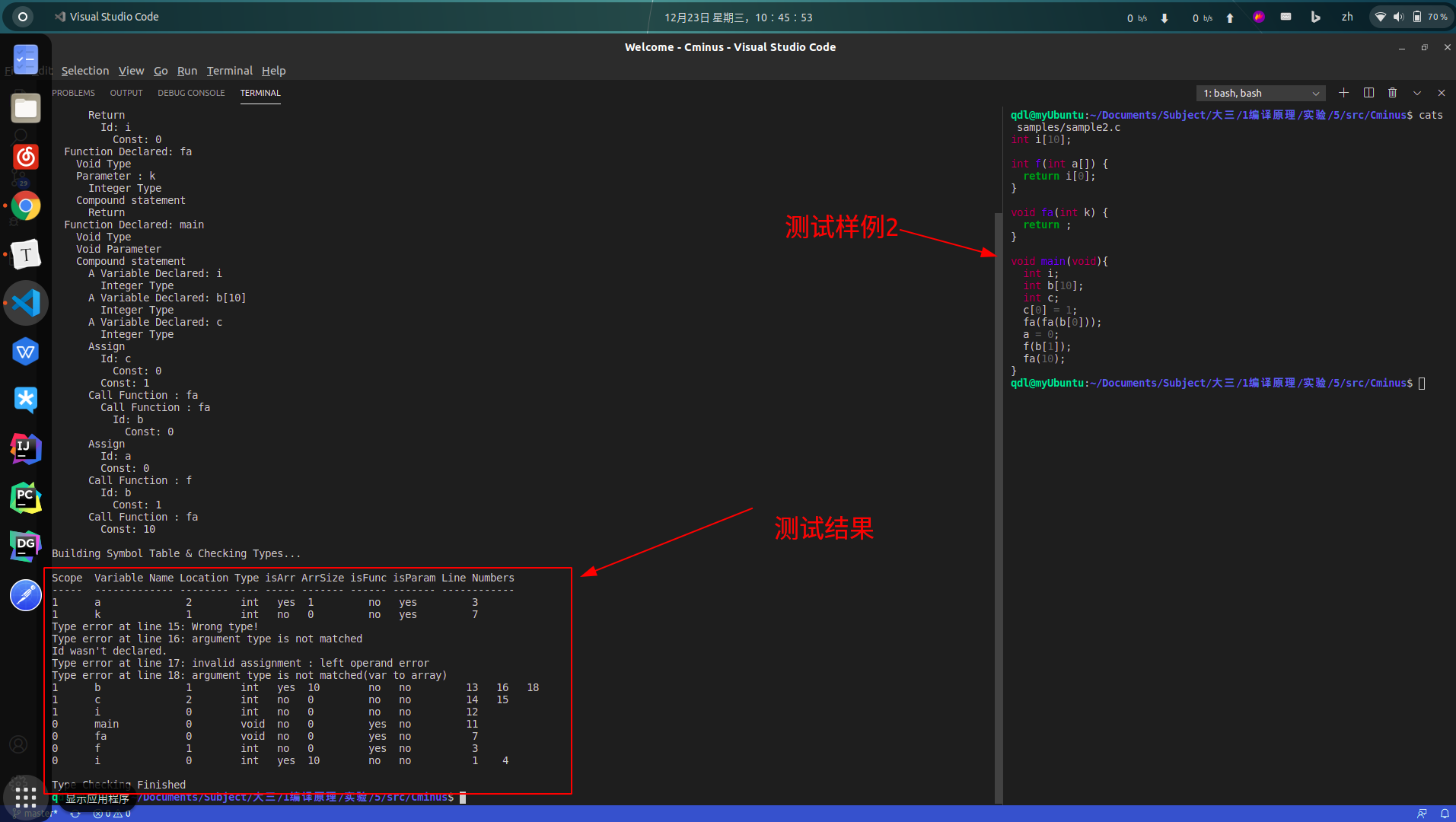
int i[10];
int f(int a[]) {
return i[0];
}
void fa(int k) {
return ;
}
void main(void){
int i;
int b[10];
int c;
c[0] = 1;
fa(fa(b[0]));
a = 0;
f(b[1]);
fa(10);
}
sample2.c
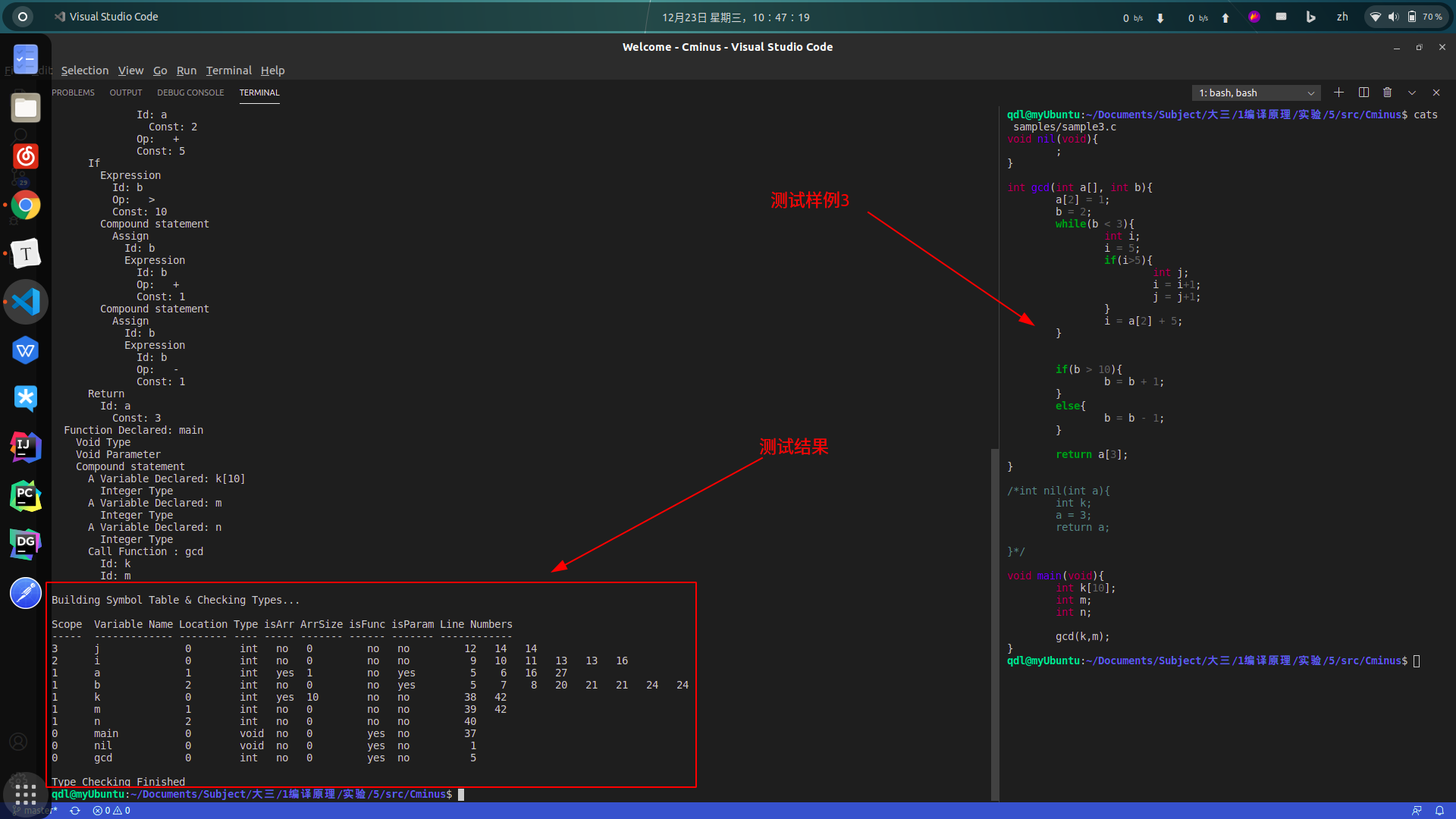
void nil(void){
;
}
int gcd(int a[], int b){
a[2] = 1;
b = 2;
while(b < 3){
int i;
i = 5;
if(i>5){
int j;
i = i+1;
j = j+1;
}
i = a[2] + 5;
}
if(b > 10){
b = b + 1;
}
else{
b = b - 1;
}
return a[3];
}
/*int nil(int a){
int k;
a = 3;
return a;
}*/
void main(void){
int k[10];
int m;
int n;
gcd(k,m);
}
sample3.c


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









