






关键字:
KFS, Tungsten Replicator
Tungsten Replicator概述
Tungsten Replicator™ is a replication engine supporting a variety of different extractor and applier modules. Data can be extracted from MySQL, Amazon RDS MySQL, Amazon Aurora and Google Cloud SQL, and applied to a variety of transactional stores, NoSQL stores and datawarehouse stores.
During replication, Tungsten Replicator assigns data a unique global transaction ID, and enables flexible statement and/or row-based replication of data. This enables data to be exchanged between different databases and different database versions. During replication, information can be filtered and modified, and deployment can be between on-premise or cloud-based databases. For performance, Tungsten Replicator™ provides support for parallel replication, and advanced topologies such as fan-in, star and multi-master, and can be used efficiently in cross-site deployments.
THL概述
THL全称Transaction History Log,是replicator之间数据交换的核心部件。所有的解析数据都被写入到了THL日志中,再从THL转换到目标端支持的格式。
THL被设计的尽可能灵活和适应性强的存储信息,同时尽可能的保持结构中立性。THL的目的就是从源端尽可能完美的提取数据,并且经肯能完美在目标端复现数据,并保持和源端的一致性。THL还需要在不知道数据库类型和环境的情况下尽可能完好的保存数据。
THL解析
THL的主要特性
- 通过唯一的Seqno来分别Transaction
- 关联唯一的ID和数据库的提取点
- 可以存存元数据信息和数据的变动
- 中立的数据格式,在不同的架构中免于丢失和污染的复制
- 数据已transaction为单位,数据事物不会丢失。
- 数据可以被划分到多个fragment中
THL Header
THL的核心是事物的结构、额外的元数据以及环境信息。所有的事物都将包含Header中的信息,不管事物中的信息是什么。
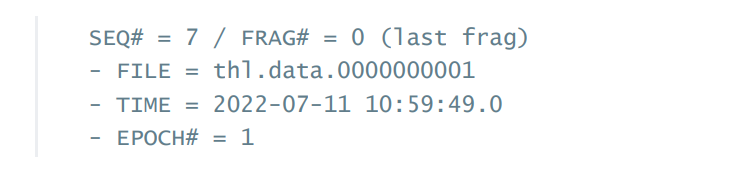
Header中包含了sequence number、fragment、fragment是否为最后一个的信息。File标明了THL文件的入口。Time是事物的提交时间。EPOCH是用于验证THL是从同一个source发出来的。

Event ID是信息加载位置的引用。上述图片是mysql的事物的起始的binary log和byte位置。Source ID 通常是hostname。
Metadata
Metadata包含了提取数据的数据库环境信息。信息由一组KV对的形式表达。用MySql举例子,包括服务器的信息,ID,数据库类型。

元信息覆盖了整个事物,经常用于存储源端信息和任何发生的进程的信息。Replicator还用这部分来记录信息是否被过滤或修改,例如:主键信息、列信息等。
Transaction Data
真正的事物信息存储在最后的块里面,并且确切的格式由信息是由row-based statement还是statement的方式解析,或者由两者混合解析。单一的THL事件可能包含多个sql语句和Row事件。对于statement和row事件,模式是一直被记录在真正事物信息的外部。对于tow based statement 信息中将同时包含模式和表信息。
Statement based events
事物数据包含了从源端到目标端执行的相同statement所需要的信息,只有Mysql到Mysql支持此模式的的复制。信息包含在一个statement块里面,包括:statement环境,创建改变的DML statement。
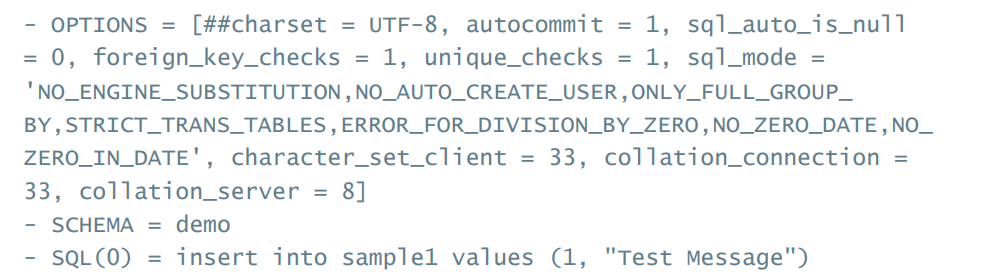
Statement based的好处是replication会小很多,因此需要更少的时间、磁盘容量和带宽。Statement based不能复制数据到非Mysql的平台,因为statement不能被在不同的不标段重写或者在非sql事物系统中重写。
Row based event
Rbe中的信息描述性和实质性更强,因为它保存真正的数据,而不是产生变化的statement。所有的变化都被保存,包括操作类型(insert,update等)和数据本身。除此之外,因为一个事物可能包含很多不同表格、不同模式的变化。每个单体的变化都要被记录在单独的快中,一个表更新对应一个块。
每个记录条目可以存储以下信息:
- Index,在原始行的对应位置
- 列名
- 列数据类型
- 数据类型长度
- 对于数字类型,是unsigned还是signed
- BLOB类型
- 介绍
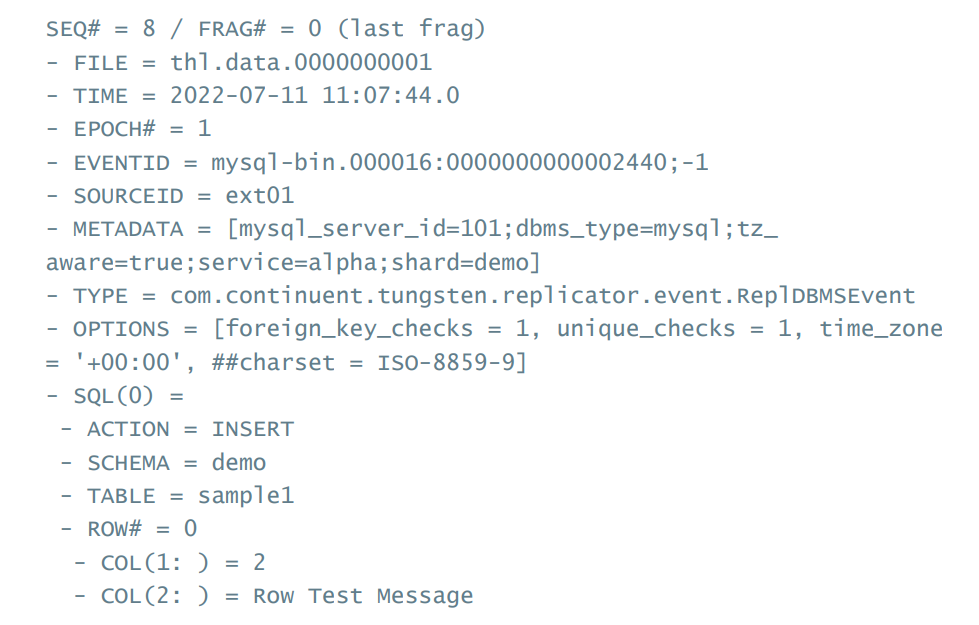
Row based信息实际上存储在两个不同的块中间,叫做row-values和row-keys。这在取名上存在歧义,因为value中存放的行的新信息,而key中存储的是老信息。所以对于一个update事件,kv中包含了更新前的信息和更新后的信息。老信息需要看一眼信息来保证我们根据主键更新了正确的行。
Insert 事件中只包含了value(新信息),update中包含了两者。

Row based event赋予了replication异质的能力,因为信息被表达为了原始数据,使得在不管目标端环境和数据结构的情况下进行提取信息并且再制造信息成为了可能:
- 目标端数据库不需要有相同的结构
- 数据类型可以是不同的
- 字符集可以是不同的
- 字段的大小和定义可以不必完全一样
- 索引可以不是完全一样的
- 字段的顺序可以是不同的,或者目标端的字段可以比源端更大
上述的所有区别都是在不需要使用过滤器下可能实现的。
当应用于doc based数据可是,数据也可可以被组装成目标数据库的数据格式,例如json或者bson文件。这样的灵活性让数据可以被高效的格式化并且被应用于目标数据库并无视数据结构和环境。相比于此,row based event在异构情况下需要对信息结构做出改变。
Row based Insert
Rb insert包含了需要被插入到记录中的信息,在绝大多数案例中,它包含了目标表的字段列表,以及被插入的数据。如果信息是NULL或者未定义,也将会被表达。

需要注意的是,信息中不包含列名信息。JDBC对于数据顺序一样的源端和目标端不要求提供列名信息。然而对于异构目标,列名是非常有用的,例如对于doc based数据库,名字是肯定需要的。
除此之外,insert event中还没有主键和索引信息,这对JDBC来说也是经常不被需要的,但对于doc based数据库或者message based数据例如kufka来说,使用主键来定位文件和消息是需要的。
在mysql中列名和主键信息必须被分别使用filters在THL中更新。

Immutability
已经提取出来的THL是不可以被任何形式修改的,一旦数据被提取并被写入磁盘,THL就是不可改变的。
改变数据的的唯一方式是在replication管线的stream中。这表示信息可以不被任何修改的从源端库中提取并写入到THL中,在被应用到各种类型的目标端,通过在目标端进行过滤和变更来适应目标端的情况。
THL可以扮演一个规范的引用源对于提取的信息来说。但不可更改性对于额外的信息和被需要的一些数据来说,必须在replicator在THL被写入磁盘之前进行变更。
存储
THL在磁盘上的存储被被分隔到一个或多个文件中。每个文件都包含了一个或多个事物信。分隔的过程取决于事物的大小和THL文件大小的设置。
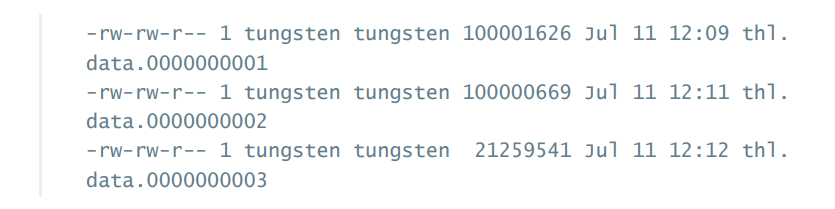

THL文件可以被设置来适配不同的存储环境和事物大小或者潜在的恢复长款。事物不会被分隔到多个THL文件中,这增加文件毁坏的概率。
THL文件同时还是由replicator使用简单的到期机制自我管理的。如果到期被设置为5天,那么THL就会在五天到期后被删除。到期机制在源端和目标端表现不同:在extractor,到期有下游applier是否已经运输内容。在appllier端,删除操作则由到期时间设定决定。
THL可以被手动删除,但是无法单独删除中间的单个文件,只能从开头或者结尾。
THL位置
Replicator可以从它开始的位置启动或者停止。Replicator的位置有THL的Event ID记录,并且和THL的sequence number联系在一起。Replicator永远在事物的边界出停止,例如一个THL sequence number。在Mysql中,提取位置是Binary log和byte position。信息一旦在THL中被存储,replicator可以暂停或者下线,记录对应表的sequence number。在重新上线时,可以从同一位置启动。
在Extractor:
- 寻找在源端数据库提取的位置,并且使用存储的Event ID
- 寻找磁盘中的THL寻找最后事物中的Event ID
- 开始在源端数据库中提取,(binlog或者scn)
这确保了及时,远端数据库轨迹数据被抹除了,提取信息依旧可以在引用点被获取。
在applier中,计算有些许不同:
- 在目标端中数据库中获取Event ID并获取相联系的sequence number
- 检查在THL文件中的sequence number,并且从上游Extractor中请求下一个THL位置
- 从源端请求存储的第一个sequence number
从源端请求sequence number,epoch主要是为了验证THL日志的匹配。Extractor和Applier的位置都可以在上线前被明确的。
参考资料
Tungsten Replicator 7.0 Manual















 198
198











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









