







下次的文章会分享toB端产品经理的内容,数据分析的内容会放到周末发,作为一个产品岗的人老是发数据分析确实有点离谱。
这一章主要说的是数据的清洗步骤,过程比较简单,没有用到插值法,各位凑合欣赏
1.数据初步缺失值处理
a.先进行数据源的检索如图
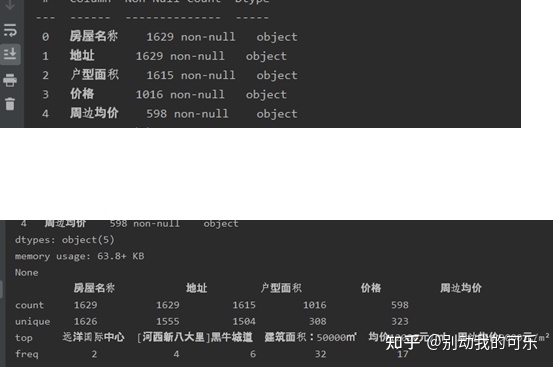
b.统计列缺失值,行缺失值如图
c.检查并删除房屋名称,地址,户型面积三列缺失值所在的行,因为这三列的缺失值无法填补,因为周边均价和均价意义一致,所以将周边均价一列插入到价格一列,再将价格一列的缺失值所在的行删除。
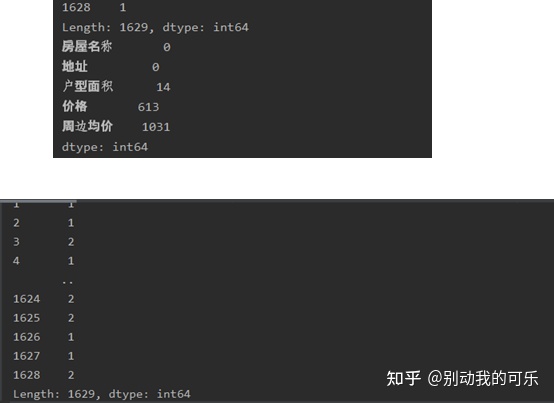
c=df.isnull().sum(axis=1)#查看缺失值
print(c)
d=df.isnull().sum(axis=0)
print(d)
df=df.dropna(subset=['房屋名称','地址','户型面积'])#删除此列缺失值行
df=df.fillna(axis=1,method='backfill')#将周边均价插入到价格中
df=df.dropna(subset=['价格'])#删除价格的缺失值
2.文本去重
检索第一列的重复的名称,进行去重
data = df.drop_duplicates(subset=['房屋名称'], keep='first', inplace=False)
3.删除最后一列
留下必要的数据,现在数据暂时无缺失、无重复,如图

4.数据分类
因为安居客的房价的计量单位不同,所以进行区分周边均价和均价放在一类,最低放在一类,总价放在一类,分类分析,如图
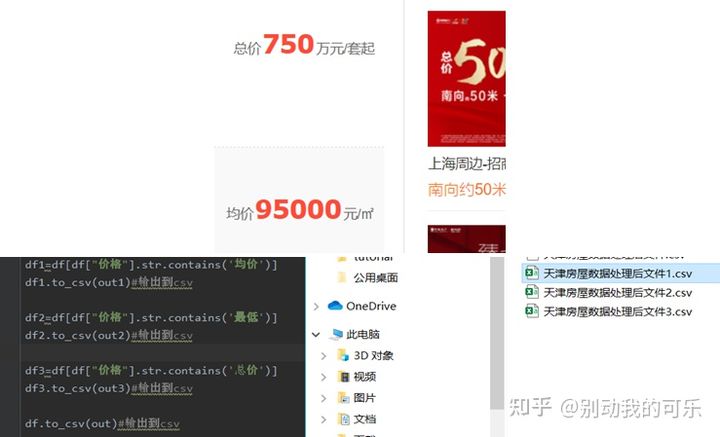
5.数据变换和提取面积上下限
a.先将数据中不重要的字符串删除,将数据冗余清除,例如房价的“周边均价”、“均价”、计量单位等,这里需要注意将“万”替代成“0000”如图,便于以后的分析,清除后得到如图所示的内容,得到最终清理后的文件。因为房子的面积是一个范围,所以要进行分离面积的上下限。

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1665
1665











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









