







学了一段时间的SparkSQL,相信大家都已经知道了SparkSQL是一个相当强大的存在,它在一个项目的架构中扮演着离线数据处理的"角色",相较于前面学过的HQL,SparkSQL能明显提高数据的处理效率。正因为如此,SparkSQL就会涉及到与多种的数据源进行一个交互的过程。那到底是如何交互的呢,下文或许能给你带来答案…
码字不易,先赞后看,养成习惯!

Spark SQL可以与多种数据源进行交互,如普通文本、json、parquet、csv、MySQL等
下面将从写数据和读数据两个角度来进行演示。
准备数据
以下面的演示为例,我们在本地的D:\data目录下创建一个person.txt
19 zhhshang 66
20 lisi 66
19 wangwu 77
31 zhaoliu 66
19 maqi 88
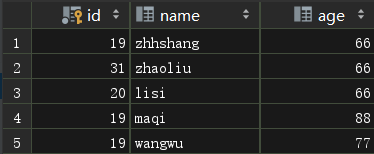
并在本地Mysql创建一个数据库spark_test,并创建一个表名persons,并且表结构如下所示:

写入数据
object WriterDataSourceDemo {
case class Person(id:Int,name:String,age:Int)
def main(args: Array[String]): Unit = {
//1.创建SparkSession
val spark: SparkSession = SparkSession.builder().master("local[*]").appName("SparkSQL")
.getOrCreate()
val sc: SparkContext = spark.sparkContext
sc.setLogLevel("WARN")
//2.读取文件
val fileRDD: RDD[String] = sc.textFile("D:\\data\\person.txt")
val linesRDD: RDD[Array[String]] = fileRDD.map(_.split(" "))
val rowRDD: RDD[Person] = linesRDD.map(line =>Person(line(0).toInt,line(1),line(2).toInt))
//3.将RDD转成DF
//注意:RDD中原本没有toDF方法,新版本中要给它增加一个方法,可以使用隐式转换
import spark.implicits._
//注意:上面的rowRDD的泛型是Person,里面包含了Schema信息
//所以SparkSQL可以通过反射自动获取到并添加给DF
val personDF: DataFrame = rowRDD.toDF
//==================将DF写入到不同数据源===================
//Text data source supports only a single column, and you have 3 columns.;
//personDF.write.text("D:\\data\\output\\text")
personDF.write.json("D:\\data\\output\\json")
personDF.write.csv("D:\\data\\output\\csv")
personDF.write.parquet("D:\\data\\output\\parquet")
val prop = new Properties()
prop.setProperty("user","root")
prop.setProperty("password","root")
// 将数据写入到数据库
personDF.write.mode(SaveMode.Overwrite).jdbc(
"jdbc:mysql://localhost:3306/spark_test?characterEncoding=UTF-8","persons",prop)
println("写入成功")
sc.stop()
spark.stop()
}
}
运行结果:
我们在程序中设置的输出路径下看到了已经生成的三个文件

csv目录

json目录
parquet目录
再让我们打开数据库看看
发现我们新建的数据库中的数据也添加了进来
说明我们的数据写入成功了,感兴趣的朋友们可以自己试一下哟~
下面我们再来尝试把数据从我们写入的数据文件中读取出来。
读数据
object ReadDataSourceDemo {
def main(args: Array[String]): Unit = {
//1.创建SparkSession
val spark: SparkSession = SparkSession.builder().master("local[*]").appName("SparkSQL")
.getOrCreate()
val sc: SparkContext = spark.sparkContext
sc.setLogLevel("WARN")
//2.读取文件
spark.read.json("D:\\data\\output\\json").show()
spark.read.csv("D:\\data\\output\\csv").toDF("id","name","age").show()
spark.read.parquet("D:\\data\\output\\parquet").show()
val prop = new Properties()
prop.setProperty("user","root")
prop.setProperty("password","root")
spark.read.jdbc(
"jdbc:mysql://localhost:3306/spark_test?characterEncoding=UTF-8","persons",prop).show()
sc.stop()
spark.stop()
}
}
运行结果
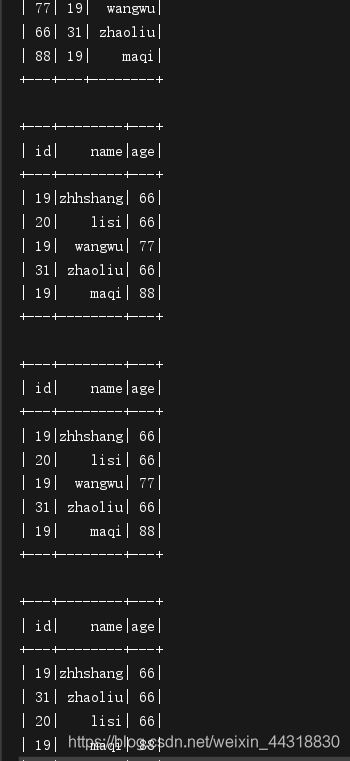
看到上图的结果说明我们成功实现了将数据导出,再读取的过程。
总结
-
SparkSQL 写数据:
DataFrame/DataSet.write.json/csv/jdbc -
SparkSQL读数据
SparkSession.read.json/csv/text/jdbc/format
结语
本次的分享就到这里,受益的朋友或对大数据技术感兴趣的伙伴可以点个赞关注一下博主,后续会持续更新大数据的相关内容,敬请期待(✪ω✪)
















 3052
3052











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











