







上一篇文章介绍了3道常见的SQL笔试题,反响还算是不错。于是乎,接下来的几天,菌哥将每天为大家分享一些关于大数据面试的杀招,祝小伙伴们都能早日找到合适的工作~

一、什么是Hive,为什么要用Hive,你是如何理解Hive?
面试官往往一上来就一个“灵魂三连问”,很多没有提前准备好的小伙伴基本回答得都磕磕绊绊,效果不是很好。下面贴出菌哥的回答:
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能(HQL)。Hive本质是将SQL转换为MapReduce的任务进行运算。
个人理解:hive存的是和hdfs的映射关系,hive是逻辑上的数据仓库,实际操作的都是hdfs上的文件,HQL就是用sql语法来写的mr程序。
二、介绍一下Hive的架构
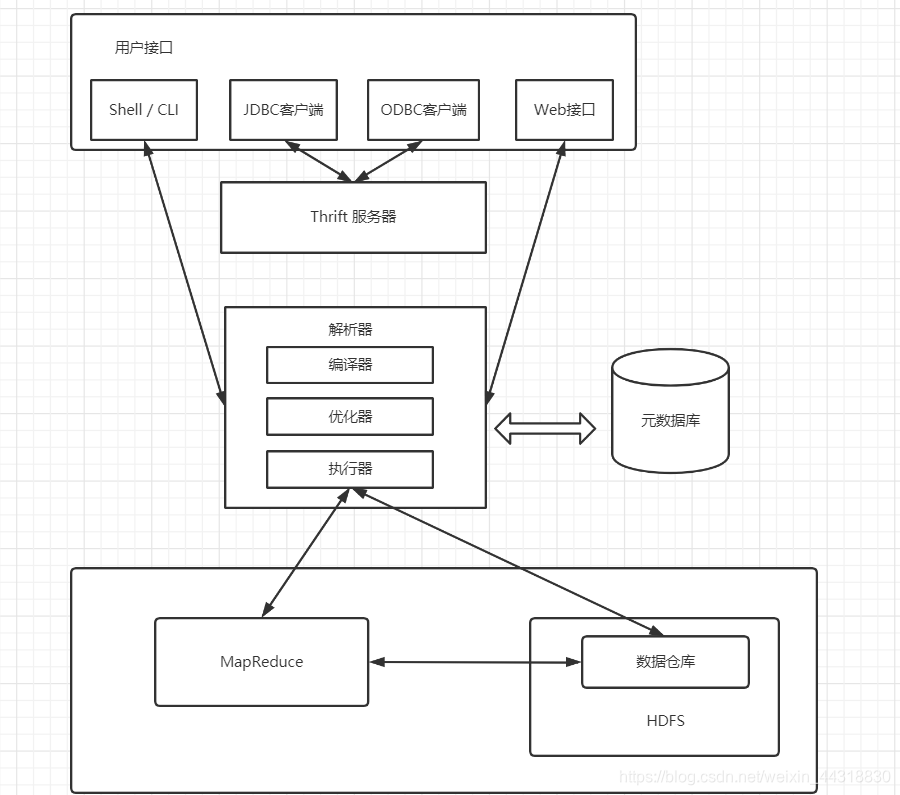
- Hive可以通过CLI,JDBC和 ODBC 等客户端进行访问。除此之外,Hive还支持 WUI 访问
- Hive内部执行流程:解析器(解析SQL语句)、编译器(把SQL语句编译成MapReduce程序)、优化器(优化MapReduce程序)、执行器(将MapReduce程序运行的结果提交到HDFS)
- Hive的元数据保存在数据库中,如保存在MySQL,SQLServer,PostgreSQL,Oracle及Derby等数据库中。Hive中的元数据信息包含表名,列名,分区及其属性,表的属性(包括是否为外部表),表数据所在目录等。
- Hive将大部分 HiveSQL语句转化为MapReduce作业提交到Hadoop上执行;少数HiveSQL语句不会转化为MapReduce作业,直接从DataNode上获取数据后按照顺序输出。
三、Hive和数据库比较
Hive 和 数据库 实际上并没有可比性,除了拥有类似的查询语言,再无类似之处。
- 数据存储位置
Hive 存储在HDFS,数据库将数据保存在块设备或者本地文件系统中。
- 数据更新
Hive中不建议对数据的改写,而数据库中的数据通常是需要经常进行修改的。
- 执行延迟
Hive 执行延迟较高。数据库的执行延迟较低。当然,这个是有条件的,即数据规模较小,当数据规模大到超过数据库的处理能力的时候,Hive的并行计算显然能体现出优势。
- 数据规模
Hive支持很大规模的数据计算;数据库可以支持的数据规模较小。
四、了解和使用过哪些Hive函数
这个可以回答的内容就非常多了
例如常见的关系函数 =,<>,<,LIKE,
日期函数to_date,year,second,weekofyear,datediff,
条件函数IF,CASE,NVL
字符串函数length,reverse,concat…
更多的基本函数不一一列举了,感觉面试官更想听的是开窗函数,例如:rank,row_number,dense_rank…
而开窗函数的使用可以说是大数据笔试的热门考点,所以说嘛,你们都懂得~
五、内部表和外部表的区别,以及各自的使用场景
这个感觉出现的频率也很高,基本在面试中都会被问到。
- 内部表
如果Hive中没有特别指定,则默认创建的表都是管理表,也称内部表。由Hive负责管理表中的数据,管理表不共享数据。删除管理表时,会删除管理表中的数据和元数据信息。
- 外部表
当一份数据需要被共享时,可以创建一个外部表指向这份数据。
删除该表并不会删除掉原始数据,删除的是表的元数据。当表结构或者分区数发生变化时,需要进行一步修复的操作。
六、Sort By,Order By,Distrbute By,Cluster By 的区别
这是一道很容易混淆的题目,就算不被问到,也是必须要掌握清楚的。
- Sort By:分区内有序
- Order By:全局排序,只有一个Reducer
- Distrbute By:类似MR中Partition,进行分区,结合sort by使用
- Cluster By:当Distribute by和Sorts by字段相同时,可以使用Cluster by方式。Cluster by除了具有Distribute by的功能外还兼具Sort by的功能。但是排序只能是升序排序,不能指定排序规则为ASC或者DESC。
七、Hive窗口函数的区别
- RANK() 排序相同时会重复,总数不会变,例如
1224 - DENSE_RANK() 排序相同时会重复,总数会减少,例如
1223 - ROW_NUMBER() 会根据顺序去计算,例如
1234
八、是否自定义过UDF,UDTF,简述步骤
这个时候,面试官可能看你面试得挺顺利的,打算问你点“难题”:
在项目中是否自定义过UDF、UDTF函数,以及用他们处理了什么问题,及自定义步骤?
你可以这么回答:
<1> 自定义过
<2> 我一般用UDF函数解析公共字段;用UDTF函数解析事件字段
具体的步骤对应如下:
自定义UDF:继承UDF,重写evaluate方法
自定义UDTF:继承自GenericUDTF,重写3个方法:initialize(自定义输出的列名和类型),process(将结果返回forward(result)),close
为什么要自定义UDF/UDTF?
因为自定义函数,可以自己埋点Log打印日志,出错或者数据异常,方便调试
九、请介绍下你熟知的Hive优化
当被问到优化,你应该庆幸自己这趟面试来得值了。为啥?就冲着菌哥给你分析下面的这九大步,面试官还不得当场呆住,这波稳了的节奏~
- MapJoin
如果不指定MapJoin或者不符合MapJoin的条件,那么Hive解析器会将Join操作转换成Common Join,即:在Reduce阶段完成join。容易发生数据倾斜。可以用MapJoin把小表全部加载到内存在map端进行join,避免reducer处理。
- 行列过滤
列处理:在SELECT中,只拿需要的列,如果有,尽量使用分区过滤,少用SELECT *。
行处理:在分区剪裁中,当使用外关联时,如果将副表的过滤条件写在Where后面,那么就会先全表关联,之后再过滤。
- 合理设置Map数
是不是map数越多越好?
答案是否定的。如果一个任务有很多小文件(远远小于块大小128m),则每个小文件也会被当做一个块,用一个map任务来完成,而一个map任务启动和初始化的时间远远大于逻辑处理的时间,就会造成很大的资源浪费 。而且,同时可执行的map数是受限的。此时我们就应该减少map数量。
- 合理设置Reduce数
Reduce个数并不是越多越好
(1)过多的启动和初始化Reduce也会消耗时间和资源;
(2)另外,有多少个Reduce,就会有多少个输出文件,如果生成了很多个小文件,那么如果这些小文件作为下一个任务的输入,则也会出现小文件过多的问题;
在设置Reduce个数的时候也需要考虑这两个原则:处理大数据量利用合适的Reduce数;使单个Reduce任务处理数据量大小要合适;
- 严格模式
严格模式下,会有以下特点:
①对于分区表,用户不允许扫描所有分区
②使用了order by语句的查询,要求必须使用limit语句
③限制笛卡尔积的查询
- 开启map端combiner(不影响最终业务逻辑)
这个就属于配置层面上的优化了,需要我们手动开启 set hive.map.aggr=true;
- 压缩(选择快的)
设置map端输出中间结、果压缩。(不完全是解决数据倾斜的问题,但是减少了IO读写和网络传输,能提高很多效率)
- 小文件进行合并
在Map执行前合并小文件,减少Map数:CombineHiveInputFormat具有对小文件进行合并的功能(系统默认的格式)。HiveInputFormat没有对小文件合并功能。
- 其他
列式存储,采用分区技术,开启JVM重用…类似的技术非常多,大家选择一些方便记忆的就OK。
十、了解过数据倾斜吗,是如何产生的,你又是怎么解决的?
数据倾斜和第九步谈到的的性能调优,但凡有点工作经验的老工程师都会告诉你,这都是面试必问的!那怎么才能回答好呢,慢慢往下看~
- 概念:
数据的分布不平衡,某些地方特别多,某些地方又特别少,导致的在处理数据的时候,有些很快就处理完了,而有些又迟迟未能处理完,导致整体任务最终迟迟无法完成,这种现象就是数据倾斜
- 如何产生
① key的分布不均匀或者说某些key太集中
② 业务数据自身的特性,例如不同数据类型关联产生数据倾斜
③ SQL语句导致的数据倾斜
- 如何解决
① 开启map端combiner(不影响最终业务逻辑)
② 开启数据倾斜时负载均衡
③ 控制空值分布
将为空的key转变为字符串加随机数或纯随机数,将因空值而造成倾斜的数据分配到多个Reducer
④ SQL语句调整
a ) 选用join key 分布最均匀的表作为驱动表。做好列裁剪和filter操作,以达到两表join的时候,数据量相对变小的效果。
b ) 大小表Join:使用map join让小的维度表(1000条以下的记录条数)先进内存。在Map端完成Reduce。
c ) 大表Join大表:把空值的Key变成一个字符串加上一个随机数,把倾斜的数据分到不同的reduce上,由于null值关联不上,处理后并不影响最终的结果。
d ) count distinct大量相同特殊值:count distinct 时,将值为空的情况单独处理,如果是计算count distinct,可以不用处理,直接过滤,在最后结果中加1。如果还有其他计算,需要进行group by,可以先将值为空的记录单独处理,再和其他计算结果进行union。
十一、分区表和分桶表各自的优点能介绍一下吗?
前面刚被问到内部表与外部表的区别,现在终于到了分区表和分桶表~作为Hive常用的几种管理表,被问到也是意料之中!
- 分区表
- 介绍
1、分区使用的是表外字段,需要指定字段类型
2、分区通过关键字partitioned by(partition_name string)声明
3、分区划分粒度较粗
- 优点
将数据按区域划分开,查询时不用扫描无关的数据,加快查询速度
- 分桶表
- 介绍
1、分桶使用的是表内字段,已经知道字段类型,不需要再指定。
2、分桶表通过关键字clustered by(column_name) into … buckets声明
3、分桶是更细粒度的划分、管理数据,可以对表进行先分区再分桶的划分策略
- 优点
用于数据取样;能够起到优化加速的作用
回答到这里已经非常不错,面试官可能又问了:
小伙几,能讲解一下分桶的逻辑吗?
哈哈哈,好吧~谁让我看了菌哥写的杀招,有备而来,丝毫不惧!!!
分桶逻辑:对分桶字段求哈希值,用哈希值与分桶的数量取余,余几,这个数据就放在那个桶内。
十二、了解过动态分区吗,它和静态分区的区别是什么?能简单讲下动态分区的底层原理吗?
都到了这一步,没有撤退可言。
- 静态分区与动态分区的主要区别在于静态分区是手动指定,而动态分区是通过数据来进行判断
- 详细来说,静态分区的列是在编译时期,通过用户传递来决定的;动态分区只有在 SQL 执行时才能决定
- 简单理解就是静态分区是只给固定的值,动态分区是基于查询参数的位置去推断分区的名称,从而建立分区
十三、使用过Hive的视图和索引吗,简单介绍一下
可能有的朋友在学习的过程中没机会使用到视图和索引,这里菌哥就简单介绍一下如何在面试的时候回答,更详细的实操应该等着你们后面去实践哟~
- Hive视图
视图是一种使用查询语句定义的虚拟表,是数据的一种逻辑结构,创建视图时不会把视图存储到磁盘上,定义视图的查询语句只有在执行视图的语句时才会被执行。
通过引入视图机制,可以简化查询逻辑,提高了用户效率与用户满意度。
注意:视图是只读的,不能向视图中插入或是加载数据
- Hive索引
和关系型数据库中的索引一样,Hive也支持在表中建立索引。适当的索引可以优化Hive查询数据的性能。但是索引需要额外的存储空间,因此在创建索引时需要考虑索引的必要性。
注意:Hive不支持直接使用DROP TABLE语句删除索引表。如果创建索引的表被删除了,则其对应的索引和索引表也会被删除;如果表的某个分区被删除了,则该分区对应的分区索引也会被删除。
彩蛋
为了能鼓励大家多学会总结,菌在这里贴上自己平时做的思维导图,需要的朋友,可以关注博主个人微信公众号【大数据梦想家】,后台回复“思维导图”即可获取。
结语
本篇纯当试个水,有任何好的想法或者建议可以在评论区留言,或者直接私信我也ok,后期会考虑出一些大数据面试的场景题,在最美的年华,做最好的自己,我是Alice,我们下一期见~~
一键三连,养成习惯~
文章持续更新,可以微信搜一搜「 大数据梦想家 」第一时间阅读,思维导图,大数据书籍,大数据高频面试题,海量一线大厂面经…期待您的关注!
















 126
126











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











