







一道亚马逊面试题
给出题目:给定一家公司在四十日内的股票走势信息,这些信息包括了它每天交易的最高价,最低价,以及开盘价。假定你做为交易员,必须在股票开盘时做出买入或卖出的决定,你负责设计一个算法用来决定买入和卖出的策略,使得交易获得最高的利润。
拿到题目后不必忙着动手写代码,要不然面试官会认为你缺乏深思熟虑。我们首先需要做的就是搞懂题意,可以从两方面入手:1.确定题目提供了哪些数据;2.确定数据的存储格式。通过读题,可知题目给了三种数据:股票最高价,最低价,以及开盘价。数据的格式和特征在很大程度上影响着我们在算法设计上的思路。接着要确定数据以何种方式存储,数据是存储在数组中还是队列中题目并没有提及,这就需要主动与面试者交流沟通。假设问过面试官后,确定股票价格的数据格式是整型数组。分别用变量H、L、S来代表股价在交易日的最高价,最低价,以及开盘价。根据要求,只能在开盘时做出交易决定,因此在这三种数据中,我们只需考虑和处理数组S。我们可以列举出一些具体的实例,这样有利于思考和推导,比如我们可以假定一些具体的股票开盘价数值假设S数组含有八个数值即[10,5,6,9,2,4,7,8],通过该数组可知开盘价最高为10,最低为2,我们一开始没思路时会贸然以为结果就是最高值减去最低值。但这么想就会违反题目要求,因为你必须买入后才能卖出,由于10在2前,若按之前的想法10元买入2元卖出,那我们相当于亏损8块钱。所以咱们就要想着换一种思路了。
1.暴力枚举
枚举,枚举,顾名思义,就是将所有情况都举出,并判断其是否符合题目条件。所以枚举的基本方法便是分析题意后,找到一个合适的维度列举每一个元素,以完成题目。例如本题,我们可以设,第i天买入,第j天卖出,其中j>i,计算两者间的差价P(i,j)= S(j) - S(i),并返回计算得到的最大值。由此可得如下编码:
s = [10,5,6,9,2,4,7,8]
buyDay = 0
sellDay = 0
maxProfit = 0
for i in range(len(s)-1):
for j in range(i+1,len(s)):
if s[j]-s[i]>maxProfit:
maxProfit =s[j] - s[i]
buyDay = i
sellDay = j
print(('买入日是第{0}天,第{1}天卖出,最大交易利润是{2}').format(buyDay+1,sellDay+1,maxProfit))
运行上述代码结果:

问题已经算解决了,下面咱们再分析一下算法的复杂度,假定数组S的长度为n,上面代码有两个循环,外层循环走n次,内层循环走n-i-1次,因此算法的时间复杂度为:
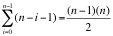
即用暴力枚举法的算法复杂度为:
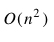
一般而言,当S的长度足够大时,平方级的时间复杂度是无法接受的。好算法的特征是:“多、快、好、省”即以最快的速度、最省的内存、最好的方式处理最多的数据。那么我们能否找到更快速的算法呢?你可能想到,一种算法设计模式叫分而治之。
2 . 分而治之
分治,分治,顾名思义,分治法的设计思想就是,将一个难以直接解决的大问题,分割成一些规模较小的相同问题,以便各个击破,分而治之。也就是,把S 先分成两部分, 第一部分是S 的前半部分:
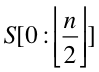
另一部分是S的后半部:
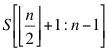
分别计算前半部分和后半部分交易的最大利润,接着选出两个结果中的利润最大值。例如:
S:1 , 2, 3, 4, 5, 6, 7, 9
那么前半部是:1, 2, 3, 4 最佳交易方案是第一天买入,第4天卖出,得到的利润是: 3=4 – 1。后半部是: 5, 6, 7 ,9. 最佳交易是第五天买入,第八天卖出,利润是:4=9-5。因此采用后半部的交易方案能得到最大利润,是当前选择。我们还需要注意,如果交易时间只有两天,那么就只能选择第一天买入第二天卖出。
然而,最后我们还需要考虑一种跨界情况,最大利润可能实现的方案是:在前半部的某一天买入,在后半部的某一天卖出,如果是这种情况,那么只可能是在前半部的最小值处买入,在后半部的最大值处卖出。也就是,第一天买入,最后一天卖出,利润是 8=9-1。因此,我们只需要在前半部找到最小值,在后半部找到最大值,一个循环就可以实现,而一个循环的时间复杂度是 O(n)。依据该算法编码如下:
def findMaxProfit(S):
#返回值格式(买入日期,卖出日期,最大利润)
if len(S) < 2:
return [0, 0, 0]
if len(S) == 2:
# 如果交易天数只有两天,则只能在第一天买入第二天卖出
if (S[1] > S[0]):
return [0, 1, S[1] - S[0]]
else:
return [0, 0, 0]
# 把交易数据分成两部分,分别找出各自的最大利润,然后选取两种结果的最大值
firstHalf = findMaxProfit(S[0:int(len(S) / 2)])
secondHalf = findMaxProfit(S[int(len(S) / 2):len(S)])
finalResult = firstHalf
if (secondHalf[2] > firstHalf[2]):
# 后半部分的交易日期要加上前半部分的天数
secondHalf[0] += int(len(S) / 2)
secondHalf[1] += int(len(S) / 2)
finalResult = secondHalf
# 看最大利润方案是否是在前半部分买入, 后半部分卖出
lowestPrice = S[0]
highestPrice = S[int(len(S) / 2)]
buyDay = 0
sellDay = int(len(S) / 2)
for i in range(0, int(len(S) / 2)):
if (S[i] < lowestPrice):
buyDay = i
lowestPrice = S[i]
for i in range(int(len(S) / 2), len(S)):
if (S[i] > highestPrice):
sellDay = i
highestPrice = S[i]
if (highestPrice - lowestPrice > finalResult[2]):
finalResult[0] = buyDay
finalResult[1] = sellDay
finalResult[2] = highestPrice - lowestPrice
return finalResult
S = [1,2,3,4,5,6,7,9]
maxProfit = findMaxProfit(S)
print("应该在第{0}天买入, 第{1}天卖出, 最大交易利润为: {2}".format(maxProfit[0]+1, maxProfit[1]+1, maxProfit[2]))
程序运行结果:

算法把一个大问题先分解成两个小问题加以解决,最后再进行一次大循环,因此算法的时间复杂度公式为:
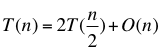
计算出来的T(n)为O(nlg(n)),算法的时间复杂度比前一种提高了一个数量级别。通过分而治之的算法,我们将效率提高了很多。只是它的实现还需要考虑不少边界条件,例如数组是空数组,数组只有一个元素,数组中的元素以降序排列等等。
3.最优解法
我们通过分而治之的算法实现了算法优化,但再想想,还有没有可能再改进一下呢?上面提到的跨界情况或许能给你提示:假定最佳交易方案是第 N 天卖出,那么很显然,最佳买入时机是在前N-1天价格最低的时候,也就是在S[0, N-1] 最小值那时买入,把S[0, N-1]最小值记为:Min(S[0, N-1]),那么,最大利润的值就是 profit = S[N] - Min(S[0, N-1]), 将N从1 到 n 走一遍,使得profit最大化的那个值就是利润最大值。这个遍历将数组循环一次就够了, 于是我们得到一个更好的算法,算法实现:
# 最优解法
S = [10,5,6,9,2,4,7,8]
minPrice = S[0]
N = 0
maxProfit = 0
buyDay = 0
sellDay = 0
for N in range(len(S)):
if (S[N] < minPrice):
minPrice = S[N]
buyDay = N
if (S[N] - minPrice > maxProfit):
maxProfit = S[N] - minPrice
sellDay = N
print("应该在第{0}天买入, 第{1}天卖出, 最大交易利润为: {2}".format(buyDay+1,sellDay+1, maxProfit))
程序运行结果:

这种方法只需把数组遍历一次,因此其时间复杂度是O(n),它的效率最高,而且代码更简单。
以上三种算法,只需要空间存储开盘价数组,都不需要额外分配存储空间,因此空间复杂度都是O(n)。
大家或许可以体会到,在编码技能熟练的情况下,把算法写出来一般也需要20到30分钟。在不到一个小时的面试时间内,根据给定问题,分析问题,设计算法,然后编码实现,接着测试代码,分析复杂度。而在较大的压力情况下,保持头脑清醒,并进行快速的思考分析,对大多数人来说,并不容易做到。因此,要想提高面试成功率,我们必须在平时就注意培养积累算法功底,注意分析能力的培养和提高。正如有的大佬所说,在解决面试算法题时为了提高效率,我们要开启的是搜索模式,而不是思考模式,这就需要我们注重平时积累,在大脑中建立起解决方案数据库。学习在路上,后期会继续更新数据结构和算法内容,敬请期待。
















 537
537











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











