







MySQL事务一直是很头疼的问题,很多小伙伴搞不清楚,今天我们从实操层面,对事务一探究竟。
首先,我们都知道事务的四大特性:原子性、隔离性、一致性、持久性。不知道的,自行学习下去。
我们直接来看事务的隔离级别。
其实,数据库是有默认的隔离级别的,使用下面的语句可查询:
select @@transaction_isolation;运行后:
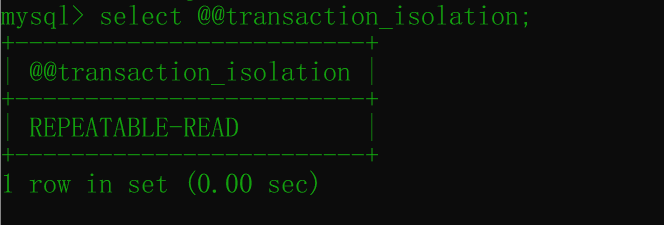
可见,数据库默认的隔离级别是:REPEATABLE-READ,也就是可重复读。在同一个事务内的查询都是事务开始时刻一致的,该隔离级别消除了不可重复读,但是还存在幻象读。
现在,我们从第一个事务隔离级别看起。
1、读未提交(Read Uncommitted)
设置隔离级别:
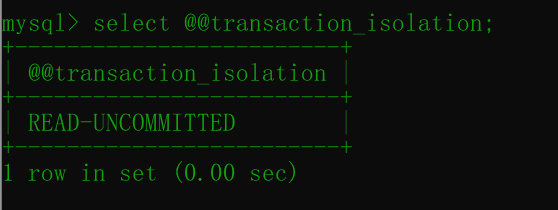
set session transaction isolation level read uncommitted;查看这个事务的隔离级别:
select @@transcaction_isolation;结果如下:
开启第一个事务:
begin;然后再另外一个事务中(我们叫他第二个事务,为了方便演示)对数据进行修改score为101;
begin;update emp set score=101 where eid=1;然后在第一个事务中查询:
select * from emp where eid = 1;结果如下:
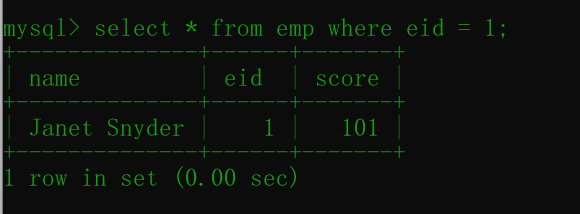
可见,读未提交(Read Uncommitted)这个级别,即使另外一个事务没有提交也会被另外一个事务查询到修改后的数据。
这就隔离级别最低的,造成的后果就是会读到脏数据,也就是一个事物读到了另外一个事务还未提交的数据。
2、读提交(Read Committed)
设置隔离级别:
set session transaction isolation level read committed;可以查看一下是否设置成功:
select @@transcaction_isolation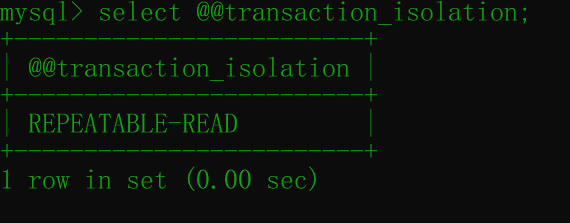
此时,已经是RR的隔离级别了,也就是只能读到提交的事务的数据了。
我们测试一下。
开启事务:
begin;然后查看一下当前的数据:
select * from emp where eid = 1;运行后:
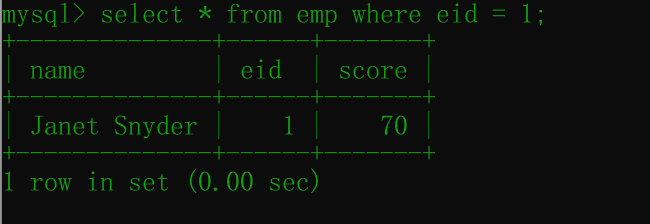
可见,当前的数score是70;
然后我么开另外一个窗口,开启一个新的事务,然后对score修改为85。
bgein;update emp set score = 85 where eid = 1;运行后,我们再从第一个事务哪里查看是这个数据:
select * from emp where eid = 1;结果如下:
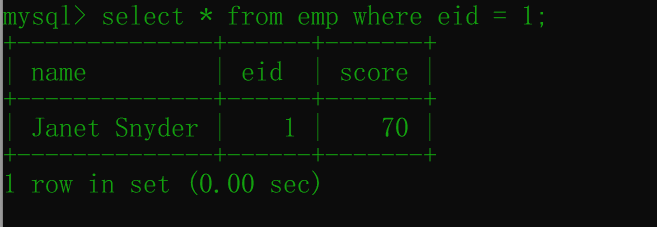
数据score仍然是70,没有改变,这就是RR隔离级别起的作用,另外一个事务修改数据后,在没有commit之前,查看到的依然是原来的数据。
现在,我们对数据进行commit。
然后再次查询后,结果如下:
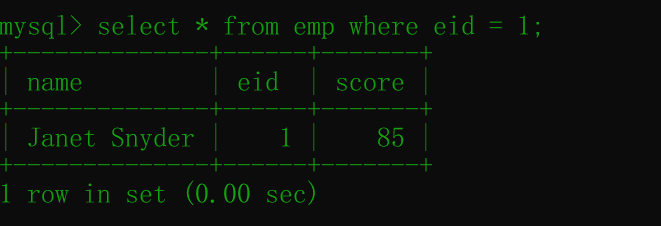
此时,score就是85,是我们修改过后的数据。
3、可重复读(Repeated Read)
设置隔离级别:
set session transaction isolation level repeatable read;运行后:

查看事务隔离级别:
select @@transaction_isolation;运行后如下:
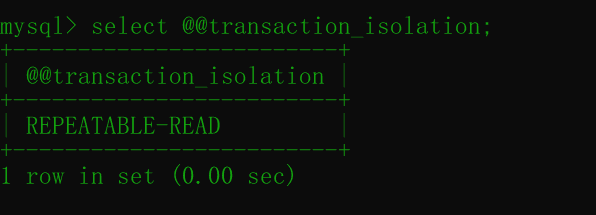
在第一个事务中开启事务:
begin;接下来,在另外一个事务中修改这个数据score为90:
begin;update emp set score=90 where eid = 1;commit;
然后在第一个事务查询,结果如下:
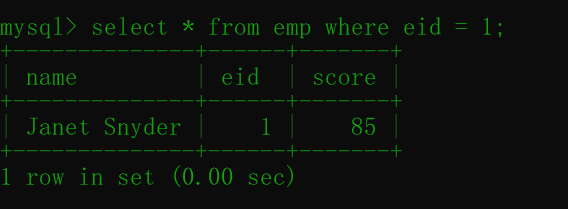
数据还是85,没有变化。
可见,RR这个隔离级别下,只要还在这个事务中,另外一个事务修改了数据后,查询到的还是原来的数据。
也就是,我们在第一个事务查询这个数据时,另外一个书事务对这个数据进行了修改,但是我们在第一个事务中查询的到的热然是85,而不是90。
4、串行读(Serializable)
设置隔离级别:
set session transaction isolation level serializable;运行后:

查询当前的隔离级别:
select @@transaction_isolation;结果如下:
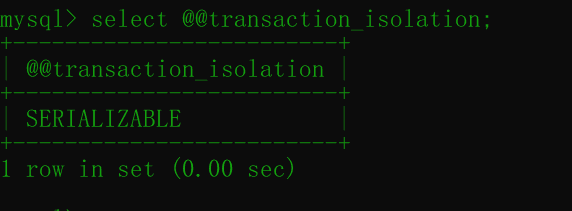
设置成功。
然后开启第二个事务,并对数据进行修改:
begin;update emp set score=100 where eid=1;执行后如下:
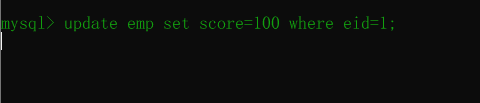
第二事务个一直处于等待中,等待另外一个事务进行提交或者回滚,然后才能执行。
如果超过一定的时间,就会报错:

我们对第一个事务进行回滚,然后第二个事务就立马执行了:

左边是第一个事务,对其进行回滚,然后右边是第二个事务,它立马执行了修改操作。
这就是Serializable隔离及级别。















 1031
1031











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









