







哪里学不会了?文章“点点”一直都在发,有时候找找自己的原因。 “数据救星RAID:保护、备份、恢复,一步到位!”
客户:关于RAID我要详解、详解!

1.概述

1.1 为什么需要RAID
一个技术的出现肯定会解决一个现实的问题,所以为什么需要RAID呢?
- 数据冗余和容错:RAID提供了冗余备份,将数据分布在多个磁盘上。当一个磁盘发生故障时,RAID可以通过冗余数据从其他磁盘恢复数据,保护数据免受硬件故障的影响
- 提高性能:RAID使用数据分散和并行读写的方式,提供更高的读写性能。它能够同时从多个磁盘读取或写入数据,提高数据访问速度,尤其是在涉及大型文件或高负载环境中。
- 扩展容量:通过将多个磁盘组合在一起,RAID可以将它们视为单个逻辑驱动器,提供更大的存储容量。这对于需要处理大量数据或需要长期存储的应用程序和系统非常有用。
- 灵活性和可管理性:RAID允许管理员根据需要选择不同的RAID级别,以平衡性能、容错和存储需求。不同的RAID级别提供了不同的特性,如数据冗余、性能提升、容量扩展等,以适应不同的应用场景和需求。
1.2 RAID简介
RAID(冗余磁盘阵列)是一种将多个物理磁盘组合成逻辑单元的技术,旨在提高数据存储的性能、容量和冗余度。通过RAID技术,多个磁盘可以合并为一个逻辑存储单元,从而提供更高的性能和数据可靠性。
RAID是一种技术,RAID控制器是硬件或软件,用于实现和管理RAID,他是连接磁盘和计算机系统的关键组件,负责控制和操作磁盘阵列。如下图。

1.3 常见的RAID级别及其特点
-
RAID 0:条带化(Striping)级别。数据被分散存储在多个磁盘上,以提高读写性能。RAID 0没有冗余,因此如果任何一个磁盘损坏,所有数据都会丢失。
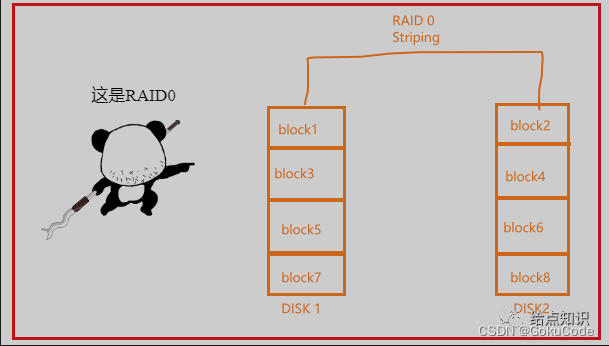
-
RAID 1:镜像(Mirroring)级别。数据同时写入两个磁盘,实现数据冗余。如果一个磁盘出现故障,数据仍然可从另一个磁盘中恢复。由于可以同时读取任一磁盘,因此读取性能得到提高。写入性能与单磁盘存储相同。
文件分为:文件1=文件2=文件
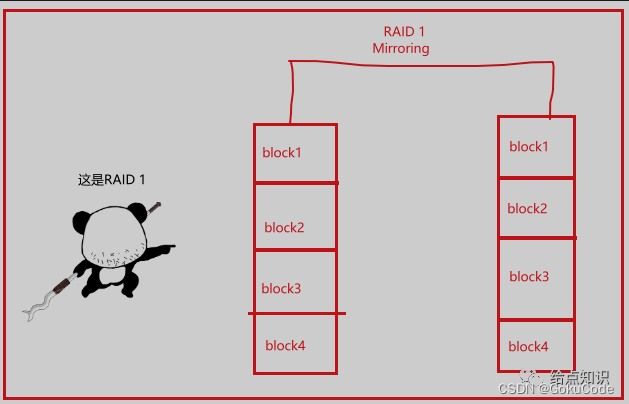
-
RAID 5:条带化带奇偶校验(Striping with Parity)级别。数据和校验信息交错存储在多个磁盘上。校验信息用于恢复任一磁盘发生故障时的数据。RAID 5至少需要三个磁盘。两个存文件,一个存校验块,它的好处就是,如果有一个磁盘坏了,可以利用其他磁盘的数据校验关系进行还原。
比如:有个文件分为了两块 00 和01 然后计算异或 00 ^ 01 = 10 那么就存储00 到磁盘1 01 到磁盘2 10 到磁盘3 如果磁盘1坏了,那么通过异或 10 ^ 01 = 00 就可以找回丢失的数据。
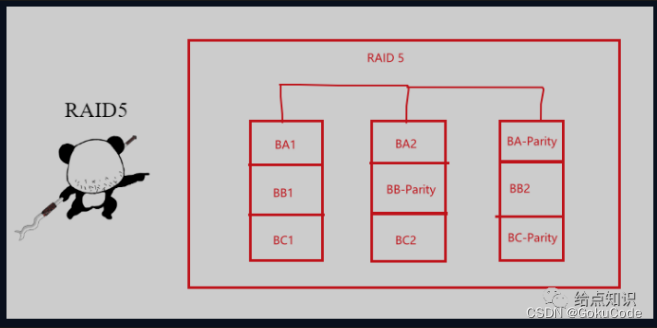
-
RAID 10:RAID 1+0,将RAID 1和RAID 0结合。数据被镜像存储在多组磁盘上,然后进行条带化。RAID 10提供较高的性能和冗余,但需要至少四个磁盘。
这个级别一般是银行使用:两两做镜像-> 然后再做条带方式
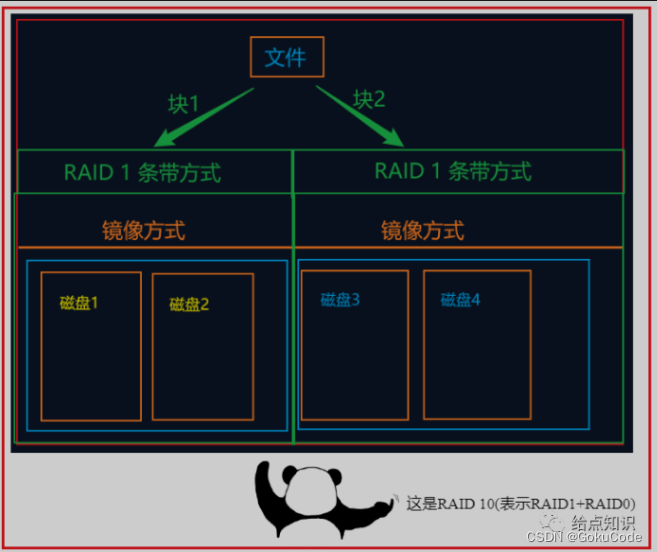
RAID技术的主要优点是提高磁盘性能、提供数据冗余和提高系统可靠性。通过使用多个磁盘并结合不同的RAID级别,可以根据需求平衡性能、容量和冗余的要求。
需要注意的是,RAID并不是备份解决方案。尽管RAID可以提供冗余和容错能力,但它无法保护数据免受其他类型的数据损失,如误删除、病毒感染或灾难性故障。定期备份数据仍然是确保数据安全的重要措施。
2.实现方法
一般使用硬件实现RAID 进行实现,在软件中也可以实现,但要注意软件RAID会比较消耗CPU,这里只做一个演示。
2.1 软件实现RAID 1
-
首先,安装mdadm 软件
yum -y install mdadm -
其次,要准备两个磁盘或者两个分区,这里使用sdc,要多/dev/sdc进行分区操作,得到/dev/sdc1 /dev/sdc2
fdisk /dev/sdc
-
然后,制作RAID,在磁盘分区
#两个磁盘分区 /dev/sdc1 /dev/sdc2 mdadm -C /dev/md0 -a yes -l1 -n2 /dev/sdc1 /dev/sdc2 #------S参数详解------------------- -C :表示创建一个RAID的设备框架 /dev/md0 就是RAID1(镜像)设备 -a yes:表示接受同意创建,因为创建的时候会给你一些提示信息,这里我们自动表示同意 -l :表示RAID的级别,1 表示RAID 1 #------E参数详解------------------- [root@model proc]# mdadm -C /dev/md0 -a yes -l1 -n2 /dev/sdc1 /dev/sdc2 mdadm: /dev/sdc1 appears to contain an ext2fs file system size=2097152K mtime=Thu Jan 1 08:00:00 1970 mdadm: Note: this array has metadata at the start and may not be suitable as a boot device. If you plan to store '/boot' on this device please ensure that your boot-loader understands md/v1.x metadata, or use --metadata=0.90 mdadm: /dev/sdc2 appears to contain an ext2fs file system size=2097152K mtime=Thu Jan 1 08:00:00 1970 Continue creating array? y mdadm: Defaulting to version 1.2 metadata mdadm: array /dev/md0 started. -
然后,查看RAID后磁盘的信息
[root@model ~]# mdadm -D /dev/md0 /dev/md0: Version : 1.2 # RAID设备的版本号 Creation Time : Sat Aug 26 17:14:27 2023 # 创建时间 Raid Level : raid1 # RAID级别 Array Size : 2094080 (2045.00 MiB 2144.34 MB) # RAID设备的总大小,单位为扇区(sector) Used Dev Size : 2094080 (2045.00 MiB 2144.34 MB) # 每个设备(磁盘)在RAID设备中使用的大小。 Raid Devices : 2 # RAID设备中的磁盘数目 Total Devices : 2 # 总共参与RAID的设备数目 Persistence : Superblock is persistent #超级块是否持久化的标志 Update Time : Sat Aug 26 17:15:17 2023 # 最后一次更新RAID设备的时间。 State : clean #RAID设备的状态,这里是 clean,表示设备正常运行。 Active Devices : 2 # 活动(正常运行)的设备数目 Working Devices : 2 # 参与RAID操作的设备数目 Failed Devices : 0 # 失效的设备数目 Spare Devices : 0 # 备用设备的数目 Consistency Policy : resync # 一致性策略,这里是 resync,表示设备正在进行数据同步。 Name : model:0 (local to host model) #RAID设备的名称 UUID : ae3fb0c7:046f0fe0:a37c569d:7964559c # RAID设备的唯一标识符 Events : 17 #发生的事件数目 # 每个磁盘在RAID设备中的编号、主设备号、次设备号、RAID设备中的序号和状态。 Number Major Minor RaidDevice State 0 8 33 0 active sync /dev/sdc1 1 8 34 1 active sync /dev/sdc2 -
接下来,就可以把/dev/md0 当作一个磁盘进行使用,首先可以格式化RAID这块磁盘
mkfs.ext4 /dev/md0 -
然后挂载磁盘,就可以使用了
mkdir /mnt/md0 mount /dev/md0 /mnt/md0 -
演练故障
1. 首先确认下磁盘是否正常 cat /proc/mdstat [root@model ~]# cat /proc/mdstat Personalities : [raid1] md0 : active raid1 sdc2[1] sdc1[0] 2094080 blocks super 1.2 [2/2] [UU] unused devices: <none> 2. 创建一个文件放在挂载的目录中 touch /mnt/md0/a.txt 3. 模拟故障,让/dev/sdc1 故障 mdadm --fail /dev/md0 /dev/sdc1 如下结果:查看状态可以看到sdc1[0](F) F表示故障 [root@model md0]# cat /proc/mdstat Personalities : [raid1] md0 : active raid1 sdc2[1] sdc1[0](F) 2094080 blocks super 1.2 [2/1] [_U] 4. 查看文件,可以看到依然可以访问文件 [root@model mnt]# cat /mnt/md0/a.txt [root@model mnt]# ls -alh /mnt/md0//a.txt -rw-r--r--. 1 root root 0 8月 26 17:34 /mnt/md0//a.txt -
恢复故障的设备
1. cat /proc/mdstat 确保 `/dev/md0` RAID1 阵列处于降级状态(\[2/1\])并且 `/dev/sdc1` 被标记为故障(F)。 2. 移除故障的设备 mdadm --manage /dev/md0 --remove /dev/sdc1 3. 修复或者替换 (1)修复 mdadm --manage /dev/md0 --re-add /dev/sdc1 (2)替换 mdadm --manage /dev/md0 --add /dev/sdc1 4. 查询信息可以看到正在恢复 [root@model mnt]# cat /proc/mdstat Personalities : [raid1] md0 : active raid1 sdc1[2] sdc2[1] 2094080 blocks super 1.2 [2/1] [_U] [==>..................] recovery = 13.2% (278272/2094080) finish=0.6min speed=46378K/sec unused devices: <none> -
其他操作
以下是对你提供的操作的解释: 1. `mdadm -Evs > /etc/mdadm.conf`:这个命令的作用是生成 `/etc/mdadm.conf` 文件,并将输出重定向到该文件。`mdadm -Evs` 命令用于显示当前系统中的所有软件RAID设备的信息,包括设备级别、元数据版本、设备数量、UUID等。 3. `cat /etc/mdadm.conf`:这个命令再次用于查看 `/etc/mdadm.conf` 文件的内容。在你的示例中,输出显示了重新生成的内容,包括一个名为 `/dev/md/0` 的RAID设备,使用了 `/dev/sdc2` 和 `/dev/sdc1` 作为其组成设备。 综上所述,通过这些操作,你将设备路径添加到 `/etc/mdadm.conf` 文件中,并重新生成了该文件以包含当前系统中的所有软件RAID设备的信息。这样,在系统启动时,软件RAID设备将会自动加载。请确保在执行任何更改之前备份重要数据,并小心谨慎操作。 3 永久挂载 [root@model ~]# cat /etc/fstab /dev/sdb5 swap swap defaults 0 0 /dev/md0 /mnt/md0 ext4 defaults 0 0
5. 小知识
5.1 奇偶校验如何恢复数据
奇偶校验可以恢复数据是因为它利用了异或(XOR)运算的特性。异或运算是一种逻辑运算,它的结果取决于输入的位的状态。下面解释为什么奇偶校验可以用于恢复数据:
在RAID 5中,奇偶校验块存储在不同的磁盘上,并且通过对其他磁盘上相同位置的数据块进行异或运算得出。假设有多个数据块和一个奇偶校验块,它们的位表示如下:
数据块1:A1 A2 A3 A4 …
数据块2:B1 B2 B3 B4 …
数据块3:C1 C2 C3 C4 …
奇偶校验块:P1 P2 P3 P4 …
对于每一位,奇偶校验块的值等于相同位置上数据块的值进行异或运算的结果。例如,P1 = A1 XOR B1 XOR C1,P2 = A2 XOR B2 XOR C2,以此类推。
当一个磁盘发生故障导致数据丢失时,可以使用奇偶校验块和其他正常磁盘上的数据块来恢复丢失的数据。由于异或运算的特性,如果已知任意两个数据块和奇偶校验块中的值,就可以通过异或运算计算出缺失的数据块的值。
例如,如果数据块1和数据块2的值已知,而数据块3丢失,可以使用奇偶校验块和已知数据块的值进行计算:
P3 = A3 XOR B3 XOR C3
根据异或运算的特性,可以将等式变形为:
C3 = A3 XOR B3 XOR P3
通过执行异或运算,可以恢复数据块3的值。
同样的原理适用于其他丢失的数据块。只要已知足够的数据块和奇偶校验块的值,就可以使用异或运算恢复丢失的数据块。
需要注意的是,奇偶校验只能恢复一个数据块的值。如果同时丢失多个数据块,或者在恢复一个数据块时另一个数据块发生故障,就无法完全恢复所有数据。因此,及时替换故障磁盘是重要的,以确保RAID系统的数据完整性和可靠性。
5.2 故障输出
在你提供的输出中,RAID 1 阵列的状态显示了故障。让我们解析输出的含义:
[root@model md0]# cat /proc/mdstat
Personalities : [raid1]
md0 : active raid1 sdc2[1] sdc1[0](F)
2094080 blocks super 1.2 [2/1] [_U]
在这个输出中:
-
Personalities : [raid1]表示系统支持 RAID 1 阵列。 -
md0是 RAID 1 阵列的名称。 -
active表示 RAID 1 阵列处于活动状态,正在工作。 -
sdc2[1]和sdc1[0](F)是 RAID 1 阵列中的两个设备。方括号中的数字表示设备的编号。 -
(F)标记了sdc1设备为故障状态。在这个例子中,设备sdc1处于故障状态。 -
2094080 blocks表示 RAID 1 阵列的容量。 -
super 1.2表示 RAID 元数据的版本。 -
[2/1]表示 RAID 1 阵列中的设备数量。在这个例子中,阵列应该有两个设备,但只有一个设备正常工作。 -
[_U]表示设备状态。在这个例子中,下划线_表示设备状态未知,大写字母U表示设备正常工作。
因此,通过 [0](F) 标记,你可以确定 sdc1 设备处于故障状态。
















 320
320











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









