







文章目录
一、转义字符和原字符
1、转义字符
\t 制表符
\n 换行
\b 退格
\r 替换之前的
2、原字符(使转义字符失效)
在输出内容的引号前加上r或R
例
print(“hello\nworld”)
输出结果:
hello
world
print(r"hello\nworld")
输出结果:
hello\nworld
注意事项:输出内容的最后一个字符不可以是反斜线\ (可以是\\)
引号之前加上" f ",格式化输出
age = 20
name = "张三"
print(f"姓名:{name},年龄:{age}")
补充:input() 输入的是 字符串 类型
二、保留字(keyword)
查看保留字
import keyword
print(keyword.kwlist)
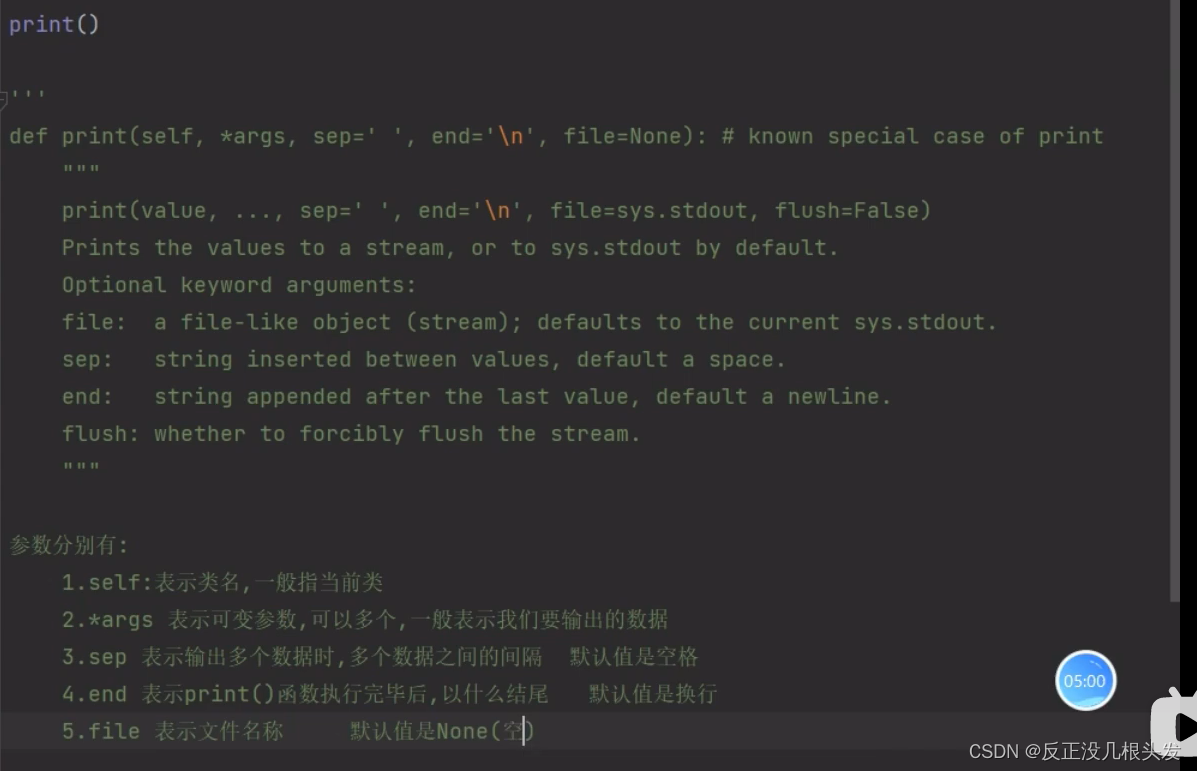
print的用法
三、数据类型
int 整型
十进制(默认的进制)
二进制(0b开头)
八进制(0o开头)
十六进制(0x开头)
float浮点型
可能出现不精确的现象(因为以二进制存储,不是所有的小数都有对应的二进制表达)
解决方案:导入模块decimal
bool布尔类型
True = 1
False = 0
str字符串类型
“ …”
‘… ’
“ ” “ … ” “ ”
‘ … ’
强制类型转换
name = '张三'
age = 22
错误写法:
print('我叫'+name+',今年'+age+'岁。')
正确写法(需要强制转换):
print('我叫'+name+',今年'+str(age)+'岁。')
四、运算符
算数运算符
/ 除法运算
// 整除运算 结果取整(向下取整)
一正一负向下取整 eg: 9//-4=-3 -9//4=-3
** 幂运算 2**3表示2的3次方
% 取余运算 一正一负要咨询公式(余数=被除数-除数*商)
比较运算符
== 对象value的比较
is、is not 对象id的比较(内存空间的比较)
逻辑运算符
and 两者全True才得到True
or 两者之一为True即为True
not 取反 相当于!
成员运算符
in
not in

str1 = "hello"
print('e' in str1) #True
print('k' not in str1) #True
注意:python中没有++或- -
五、程序执行顺序
分支结构
if 条件表达式:
执行语句...
else:
...
if...elif...(elif)...else...

条件表达式(三元运算符)
(类似于Java中的三段式)
x if 条件表达式 else y
条件表达式为True,返回值为x
条件表达式为False,返回值为y

pass语句
什么都不做,只是一个占位符,例如,还没想好函数体的内容/if的条件执行体/保证程序的完整性…
循环
for-in循环
in表示遍历
for 自定义的变量 in 可迭代对象(字符串/元组/列表/集合)
循环体


输出:12 换行 34 换行 5 … 换行 … 42

输出:
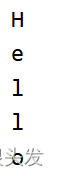
for i in "我爱学习":
print(i)
输出:

(注意:如果不需要用到自定义变量,可用下划线_代替)
while循环
注意:python中没有do...while循环
六、列表
列表的特点
列表相当于其他语言中的数组,不同的是,列表中的元素数据类型可以不全相同
可使用list()函数定义列表对象
列表的索引:正向从0开始,逆向从-1开始
列表可存储重复数据
任意数据类型可以混存
根据需要动态分配和回收空间,一般不用担心内存不够用
获取列表的多个元素(切片)
列表名[start,stop,step]
默认步长为1
(注意:step可正可负 为正数时,start默认为第一个,stop默认为最后一个
为负数时,start默认为最后一个,stop默认为第一个)
list1 = ["张三","李四","王五",123,"hello"]
print(list1[1:]) # ['李四', '王五', 123, 'hello']
print(list1[-4:-1]) # ['李四', '王五', 123]
有关列表的一些操作
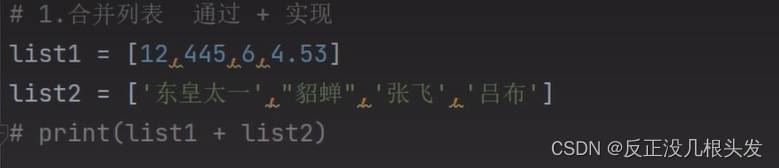
两个列表合并
index():返回元素的索引
列表的查询操作
根据索引 lst[index] 即可
列表的添加操作
append():在列表末尾添加一个元素(常用)
extend():在列表末尾至少添加一个元素
insert():在任意位置添加一个元素
insert(1,'xyz') 在索引为1的位置上添加元素'xyz'
切片
列表的删除操作
remove(): 注意:传入的参数为要删除的元素值
一次删除一个元素
重复元素只能删除第一个
元素不存在跑出ValueError
list1 = ["张三","李四","王五",123,"hello"]
list1.remove("王五")
print(list1) # ['张三', '李四', 123, 'hello']
pop(): 传入的参数为索引
删除一个指定索引位置上的元素
指定索引不存在,抛出IndexError
不指定索引,删除列表中最后一个元素
list1 = ["张三","李四","王五",123,"hello"]
list1.pop() # 默认删除最后一个
print(list1) # ['张三', '李四', '王五', 123]
删除指定索引的元素
list1 = ["张三","李四","王五",123,"hello"]
list1.pop(2)
print(list1) # ['张三', '李四', 123, 'hello']
切片:一次至少删除一个元素 lst[start : stop] = []
clear():清空列表
del():删除列表
列表的修改操作
lst[index] = 新元素
列表的排序操作
sort():原列表变了
从小到大排序(升序排序)
lst.sort()
指定 reverse=True 降序排序
lst.sort(reverse=True)

sorted():原列表没变
lst=[20,40,10,90,8]
new_list = sorted(lst)
print("原列表",lst) #原列表 [20, 40, 10, 90, 8]
print("新列表",new_list) #新列表 [8, 10, 20, 40, 90]

降序排列
new_list = sorted(lst,reverse=True)补充:一些函数
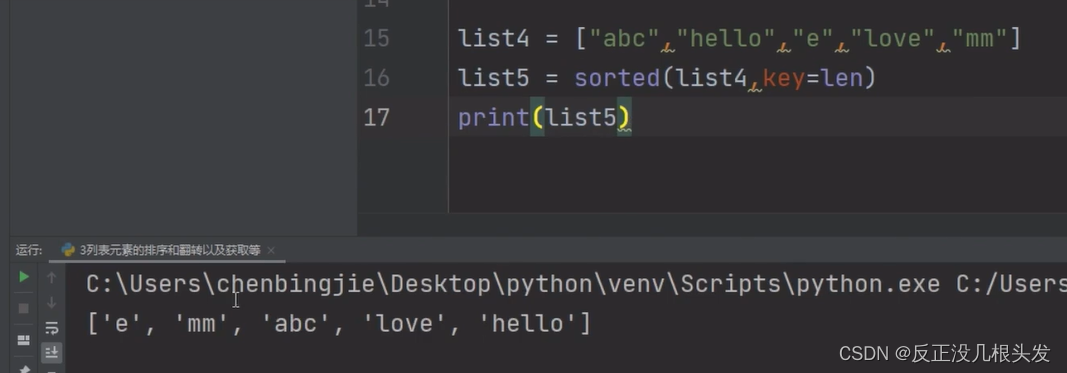
根据字符串长度排序
添加 key = len
翻转列表元素
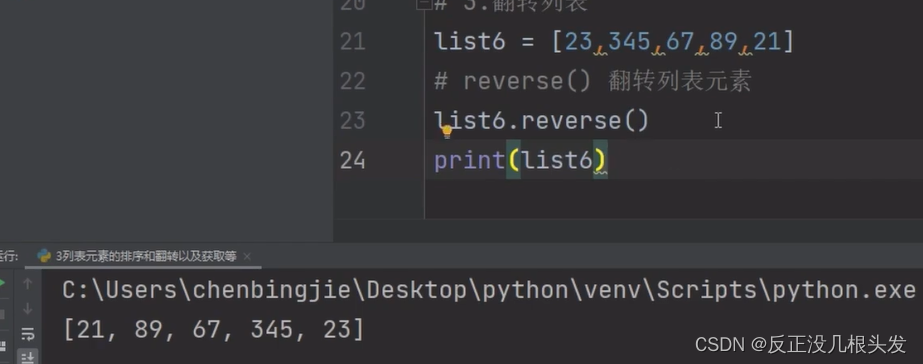
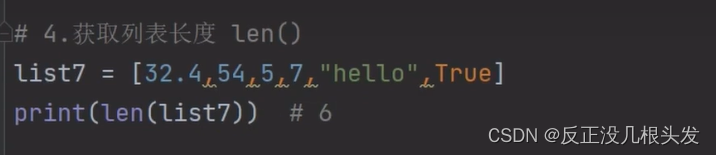
获取列表长度 len()
获取列表中最大值 / 最小值
max(列表名称)
min(列表名称)

获取指定元素的索引 index()
list1 = ["张三","李四","王五",123,"hello"]
print(list1.index("李四")) # 1
列表的嵌套
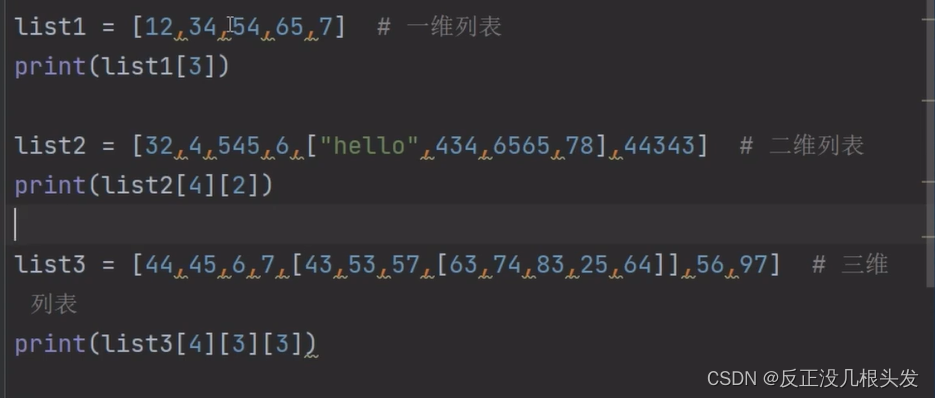
列表生成式:
lst = [i for i in range(1,10)]
print(lst)
第一个i为产生的元素
list1 = [i ** 2 for i in range(1,6)]
print(list1) # [1, 4, 9, 16, 25]
# 生成一个列表--元素为1-10以内的奇数
# 方法一
list2 = [i for i in range(1,11,2)]
print(list2) # [1, 3, 5, 7, 9]
# 方法二
list3 = [i for i in range(1,11) if i % 2 != 0]
print(list3) # [1, 3, 5, 7, 9]
遍历列表
list1 = ["张三","李四","王五",123,"hello"]
for idx,value in enumerate(list1):
print(idx,value)

七、字典
[ ]定义列表
{ }定义字典
键值对 无序(第一个放入字典的元素不一定在第一个,根据hash()计算位置)
字典的创建
方法一:
scores = {'张三':85,'李四':95}
方法二:
student = dict(name='xyz',age=20)
字典中元素的获取
方式一:key不存在时报错
print(scores['张三'])
方式二:get() key不存在是返回None
print(scores.get('李四'))
print(scores.get('王五',99)) #可以定义key不存在时value的默认值,这里是99
字典
dict1 = {"name":"张三","age":20,"job":"算法工程师"}
print(dict1["name"]) # 张三
print(dict1["job"]) # 算法工程师
字典常用的操作
key的判断
in
‘张三’ in scores
not in
‘王五’ not in scores
字典元素的删除
del scores['张三']
scores.clear() #清空字典元素

字典元素的新增
scores['陈六'] = 84
字典元素的修改同上
获取字典视图
keys():获取字典中所有的key
values():获取字典中所有的value
dict1 = {"name":"张三","age":20,"job":"算法工程师"}
print(dict1.keys()) # dict_keys(['name', 'age', 'job'])
print(dict1.values()) # dict_values(['张三', 20, '算法工程师'])
items():获取字典中所有的key,value对 元组类型
print(dict1.items()) # dict_items([('name', '张三'), ('age', 20), ('job', '算法工程师')])
字典的遍历
for item in dict1.items():
print(item,type(item))
输出:
('name', '张三') <class 'tuple'>
('age', 20) <class 'tuple'>
('job', '算法工程师') <class 'tuple'>
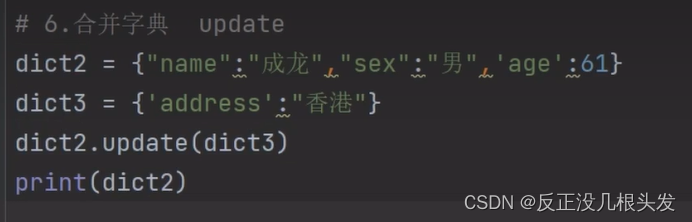
合并字典 update()
字典的特点:
key不可以重复,value可重复
字典生成式
内置函数zip()
items=['fruit','books','computers']
prices = [12,50,6000]
d={item.upper():price for item,price in zip(items,prices)}
print(d)
当key和value的个数不一致时,以短的个数进行打包
八、元组
不可变序列:没有增删改操作(但是可以对元组的可变序列元素进行增删改)
(列表、字典为可变序列:可执行增删改操作,对象地址不发生改变)
元组的创建与表示
tup = (32,45,"hello","张三",125)
print(tup) # (32, 45, 'hello', '张三', 125)
print(tup[1]) # 45
print(tup[-1]) # 125
不能修改元组中的元素!!!
合并元组 通过 +

使用内置函数tuple()创建元组
t = tuple(('python','java',90))
只包含一个元组的元素需使用逗号和小括号
t = ('python',)
print(t,type(t)) #<class 'tuple'>

判断元素是否在元组内

元组的切片

获取元组的长度 len()

获取元组内最大值max() 最小值min()
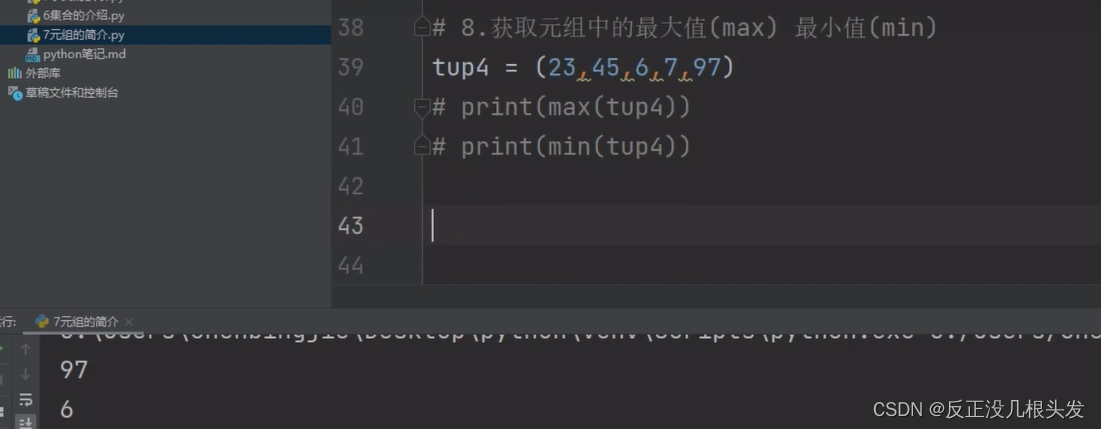
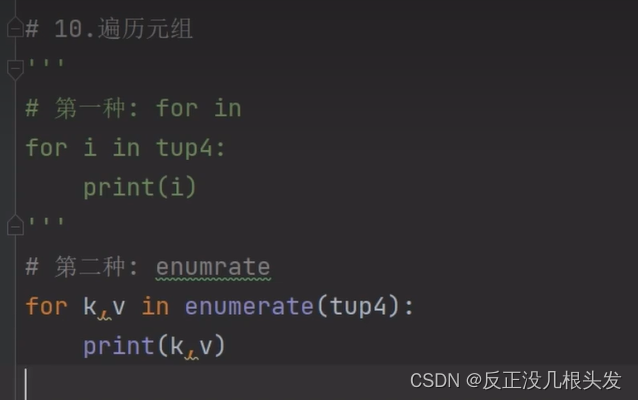
遍历元组
九、集合
可变序列(还有列表、字典)
{ } 和字典的区别:没有key
集合的特点
集合中的元素不能通过下标来访问或者修改
集合中的元素不允许重复,集合中的元素无序
s = {1,4,5,7,5,7}
print(s) #{1, 4, 5, 7}
另一种创建方式,使用内置函数set()
s2 = set(range(6))
print(s2) #{0, 1, 2, 3, 4, 5}
集合的新增操作
add():一次添加一个元素
update():一次至少添加一个元素 多个元素以列表的形式追加
set1 = {1,4,9,16,25}
print(len(set1)) # 5
set1.add(36)
print(set1) # {1, 4, 36, 9, 16, 25}
set1.update([45,23,20])
print(set1) # {1, 4, 36, 9, 45, 16, 20, 23, 25}
集合的删除元素
remove():移除一个指定元素,若元素不存在,报keyError错
discard():移除一个指定元素,若元素不存在,不报错
pop():一次删除一个任意元素(删谁,运行前不知道)不可以指定元素
set1 = {30,28,9,16,25}
print(set1) # {9, 16, 25, 28, 30}
set1.pop()
print(set1) # {16, 25, 28, 30} 随机删除一个元素
clear():清空集合中的元素
集合之间的关系
集合是否相等? 集合中元素相等则相等,顺序无所谓
一个集合是否为另一个集合的子集? 调用issubset()方法
s1 = {10,20,30,40}
s2 = {20,30}
print(s2.issubset(s1)) #True
一个集合是否为另一个集合的超集? 调用issuperset()方法
print(s1.issuperset(s2)) #True
两个集合是否没有交集? 调用isdisjoint()方法
s1 = {10,20,30,40}
s2 = {20,30,50}
s3 = {100,200}
print(s1.isdisjoint(s2)) #False
print(s1.isdisjoint(s3)) #True
集合的数学操作
# 交集 intersection()
print(s1.intersection(s2)) #方法一
print(s1 & s2) #方法二
#并集 union()
print(s1.union(s2)) #方法一
print(s1 | s2) #方法二
#差集 difference
print(s1.difference(s2)) #方法一
print(s1 - s2) #方法二
#对称差集 symmetric_difference
print(s1.symmetric_difference(s2)) #方法一
print(s1 ^ s2) #方法二
集合生成式
s = {i*i for i in range(6)}
print(s) #{0, 1, 4, 9, 16, 25}
列表、字典、元组、集合总结
list dict tuple set
除了元组(tuple),都可变
字典key、集合 不可重复
列表和元组有序,字典和集合无序(哈希)
列表:[ ] 字典:{key:value } 元组:( ) 集合:{}
十、字符串
不可变的字符序列
字符串驻留机制
对相同的字符串仅保留一份拷贝,创建相同的字符串时不会开辟新空间,而是把该字符串的地址赋给新创建的变量。
驻留机制几种情况
1、字符串的长度为0或1
2、符合标识符的字符串
3、字符串指针编译时驻留,而非运行时
4、[-5,256]之间的整数数字
强制驻留 import sys
import sys
a = 'abc%'
b = 'abc%'
a = sys.intern(b)
注意:进行字符串拼接时,建议使用str类型的**join()**方法,而非+
获取字符串的长度len
统计子串出现的次数count

字符串查询操作
index():查找子串第一次出现的位置,找不到时抛异常
rindex():查找子串最后一次出现的位置,找不到时抛异常
find():查找子串第一次出现的位置,找不到时返回-1
rfind():查找子串最后一次出现的位置,找不到时返回-1
还可以在指定范围内查找

字符串大小写转换
upper():所有字符–>大写
lower():所有字符–>小写
swapcase():所有大写–>小写,所有小写–>大写
capitalize():第一个字符–>大写,其余字符–>小写
title():每个单词第一个字符–>大写,每个单词剩余字符–>小写
字符串对齐操作
指定宽度小于字符串原宽度,则返回原字符串
center(宽度,填充符(可选)):居中对齐,填充符默认是空格
ljust():左对齐,其他同上
rjust():右对齐,其他同上
zfill():右对齐,左边用0填充
字符串的劈分操作
split():
从左开始,默认遇到空格就劈分,返回一个列表
s = 'hello world python'
print(s.split())
通过参数sep指定劈分符
s1 = 'hello|world'
print(s1.split(sep='|'))
通过maxsplit指定最大劈分次数,之后的剩余部分单独做一部分
s1 = 'hello|world|python|hello'
print(s1.split(sep='|',maxsplit=2)) #['hello', 'world', 'python|hello']
rsplit()
从右边开始劈分,其他同split()
print(s1.rsplit(sep='|',maxsplit=2)) #['hello|world', 'python', 'hello']
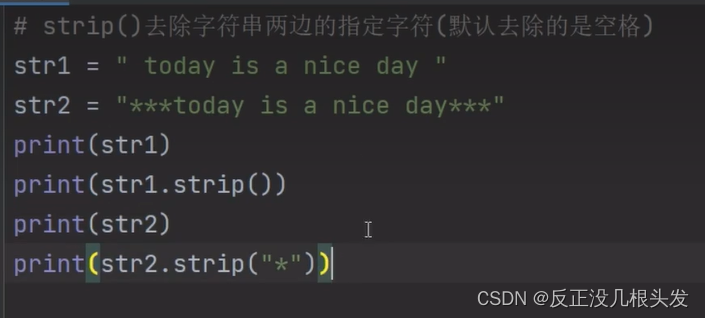
strip() 去除字符串两边的指定字符
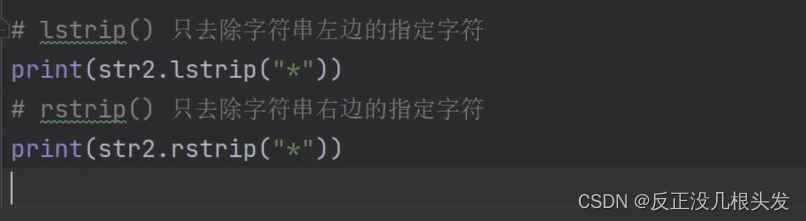
lstrip()和rstrip() 只切除左边/右边的指定字符(默认为空格)
字符串判断
isidentifier():判断指定字符串是否合法
isspace():判断指定字符是否全由空白字符组成(回车、换行、水平制表)
isupper():检测字符串中字母是否全部为大写
islower():检测字符串中字母是否全部为小写
istitle():检测字符串中单词首字母是否全部为大写
print("HELLO".isupper()) # True
print("HELLO123".isupper()) # True
print("Hello".isupper()) # False
print("hello123".islower()) # True
print("Hello world".istitle()) # False
print("Hello World".istitle()) # True
isalpha():是否全部由字母或文字组成
print("Hello World".isalpha()) # False
print("HelloWorld".isalpha()) # True
print("Hello World123".isalpha()) # False
print("Hello张三".isalpha()) # True
isdecimal():是否全部由十进制数字组成
isnumeric():是否全部由数字组成(包括汉字(一二三)、罗马数字等)
isalnum():是否全部由字母和数字组成
isdigit():是否全部由数字组成
字符串替换:
replace(被替子串,用来替换的子串,最大替换次数)
s = 'hello python python python'
print(s.replace('python','Java')) #hello Java Java Java
s = 'hello python python python'
print(s.replace('python','Java',2)) #hello Java Java python
字符串的合并
join():将列表或元组之中的字符串合并为一个字符串
lst = ['hello','python','python','hello','hi']
print('|'.join(lst)) #hello|python|python|hello|hi
print('*'.join('python')) #p*y*t*h*o*n
字符串的切片:
不可变,切片将产生新的对象
s = 'hello,world'
print(s,id(s))
s1 = s[:5]
s2 = s[6:]

格式化字符串
%做占位符
%s 字符串
%i或%d 整数
%f 浮点数
%.2f 保留两位小数
name = 'zs'
age = 22
print('我叫%s,今年%d岁' % (name,age))
{}做占位符
花括号内为索引
print('我的名字是{0},今年{1}岁,我真的叫{0}'.format(name,age))
f-string
print(f'我叫{name},今年{age}岁')
字符串编码解码
#编码
str1 = "我爱你中国"
str1_en = str1.encode() # 默认按照utf-8编码
print(str1_en) # b'\xe6\x88\x91\xe7\x88\xb1\xe4\xbd\xa0\xe4\xb8\xad\xe5\x9b\xbd'
str1_en1 = str1.encode('gbk')
print(str1_en1) # b'\xce\xd2\xb0\xae\xc4\xe3\xd6\xd0\xb9\xfa'
str1_en2 = str1.encode('utf-8')
print(str1_en2) # b'\xe6\x88\x91\xe7\x88\xb1\xe4\xbd\xa0\xe4\xb8\xad\xe5\x9b\xbd'
#解码
str2 = b'\xe6\x88\x91\xe7\x88\xb1\xe4\xbd\xa0\xe4\xb8\xad\xe5\x9b\xbd'
print(str2.decode("utf-8")) # 我爱你中国
str3 = b'\xce\xd2\xb0\xae\xc4\xe3\xd6\xd0\xb9\xfa'
print(str3.decode("gbk")) # 我爱你中国
chr() 和 ord()
# ASCII码的转换
# chr() ASCII值--->对应的字符
print(chr(97)) # a
# ord() 字符--->对应的ASCII值
print(ord('a')) # 97
十一、函数
函数定义
def …
def calc(a,b):
c=a/b
return c
注意!!!
1、在一个文件中,出现了定义的函数名相同的情况,后面定义的函数会覆盖前面的
def test():
print("前面的")
def test():
print("后面的")
test() # 后面的
2、若将函数名赋值给了一个变量,还可以通过该变量调用函数
def test():
print("一个函数")
demo = test
demo() # 一个函数
传参
①位置传参
result = calc(2,5)
print(result) #0.4
②关键字传参
result2 = calc(b = 2,a = 5)
print(result2) #2.5
在函数调用过程中,进行参数的传递
①如果是不可变对象,在函数体的修改不会影响实参的值
②如果是可变对象,在函数体的修改会影响到实参的值
函数的返回值
①函数没有返回值可以不写return
②函数返回值为1个,直接返回原类型
③函数返回多个值时,结果为元组
没有return时默认返回None
函数的参数定义
①给形参设定默认值,默认形参一般放在最后
def fun2(a,b = 10): #b为默认值参数,默认值为10
print(a,b)
fun2(100) #100,10 此时b使用默认值10
fun2(20,30) #20,30
注意:函数定义过程中,既有可变关键字形参,又有可变位置形参,位置形参放前面
先* 再**
②个数可变的位置参数(一个函数只能有一个可变位置参数)
使用*定义个数可变的位置形参
结果为一个元组
def fun3(*args1):
print(args1)
fun3(10) #(10,)
fun3(10,20,30) #(10, 20, 30)
③个数可变的关键字形参(一个函数只能有一个可变关键字参数)
使用 ** 定义个数可变的关键字形参,输入形式:key = value
结果为一个字典
def fun4(**args1):
print(args1)
fun4(a = 10) #{'a': 10}
fun4(a = 10,b = 20,c = 30) #{'a': 10, 'b': 20, 'c': 30}
将一个列表转为位置传参的参数
def fun1(a,b,c):
print('a=',a)
print('b=',b)
print('c=',c)
lst = [12,22,32]
fun1(*lst)
下面这种写法:*之后的参数,在函数调用时,只能关键字实参传递,否则报错
def fun2(a,b,*,c,d): #这种写法:c、d只能关键字实参传递
print('a=',a)
print('b=',b)
print('c=',c)
print('d=',d)
fun2(10,20,c=30,d=40)
变量的作用域
局部变量 给局部变量加上global,变成全局变量
全局变量
def fun3():
global age #没有global时,age为局部变量,加上后,age为全局变量
age = 22
print(age)
fun3()
print(age)
匿名函数
使用lambda定义的表达式,该表达式包含了参数,实现体,返回值
num1 = lambda num : num ** 2
print(num1(3)) # 9

回调函数
def add(a,b):
print(a + b)
def ji(x,y):
print(x * y)
def func(x,y,fun):
fun(x,y)
func(24,12,add)
闭包函数
一个外部函数内部定义了一个内部函数,且外部函数的返回值是内部函数,就构成了一个闭包,则这个内部函数称为闭包。
一个简单的闭包函数:
def outer():
def inner():
print("这是一个闭包函数")
return inner
fn = outer() # fn相当于inner函数
fn() # fn()相当于inner()
内部函数可以使用外部函数的变量
def outer(x):
y = 17
def inner():
print(x + y)
return inner
fn = outer(7) # fn相当于inner函数
fn() # fn()相当于inner() 24
闭包函数主要用于装饰器函数的实现
十二、浅拷贝与深拷贝
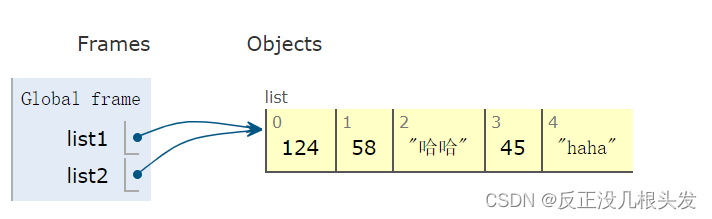
1、赋值,其实就是对象的引用(相当于起别名)
list1 = [124,58,35,45,"haha"]
print(list1) # [124, 58, 35, 45, 'haha']
list2 = list1
print(list2) # [124, 58, 35, 45, 'haha']
list2[2] = "哈哈"
print(list1) # [124, 58, '哈哈', 45, 'haha']
print(list2) # [124, 58, '哈哈', 45, 'haha']
内存图 Pythontutor–>可视化
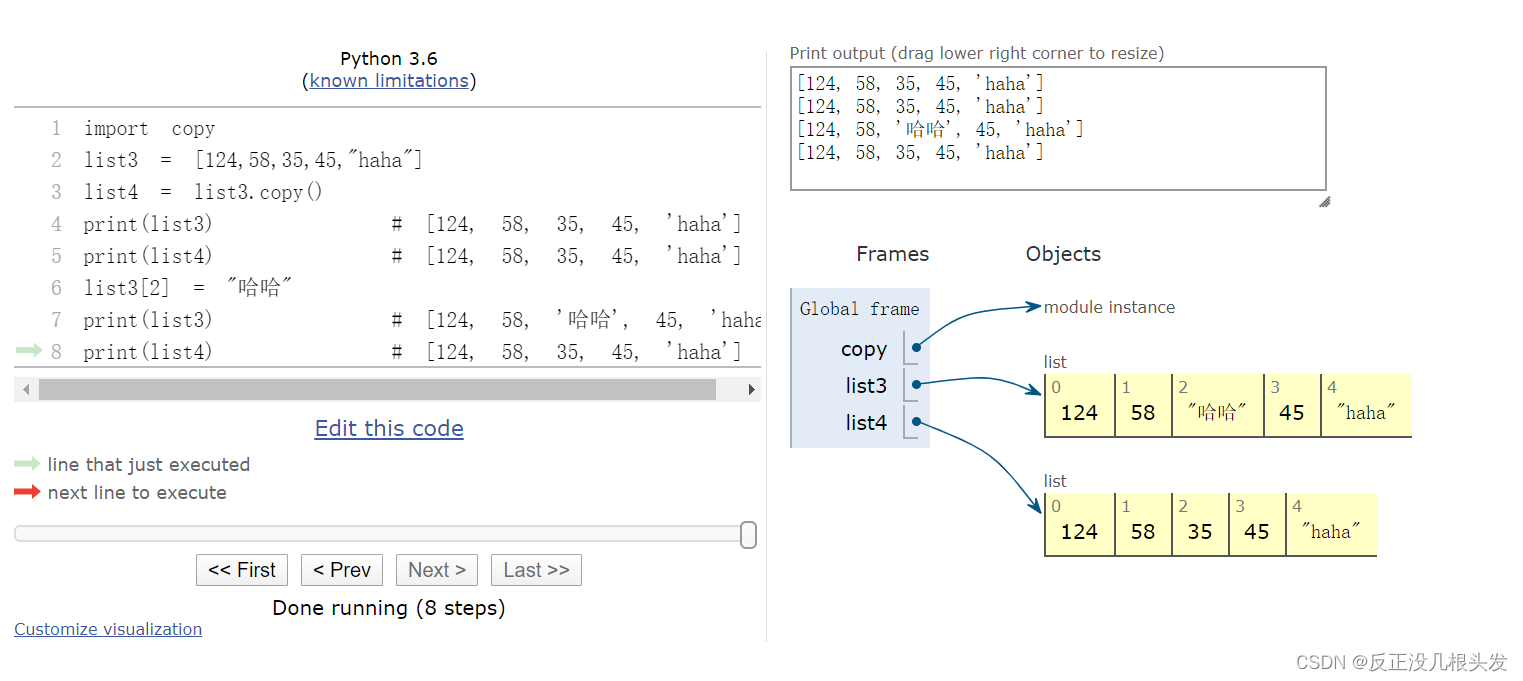
2、浅拷贝 copy()
可以解决一维列表复制的问题
list3 = [124,58,35,45,"haha"]
list4 = list3.copy()
print(list3) # [124, 58, 35, 45, 'haha']
print(list4) # [124, 58, 35, 45, 'haha']
list3[2] = "哈哈"
print(list3) # [124, 58, '哈哈', 45, 'haha']
print(list4) # [124, 58, 35, 45, 'haha']
内存图
但是对于二维列表,简单的copy()不可行
import copy
list5 = [124,58,[15,47,632],35,45,"haha"]
list6 = list5.copy()
list5[2][1] = "张三"
print(list5)
print(list6)

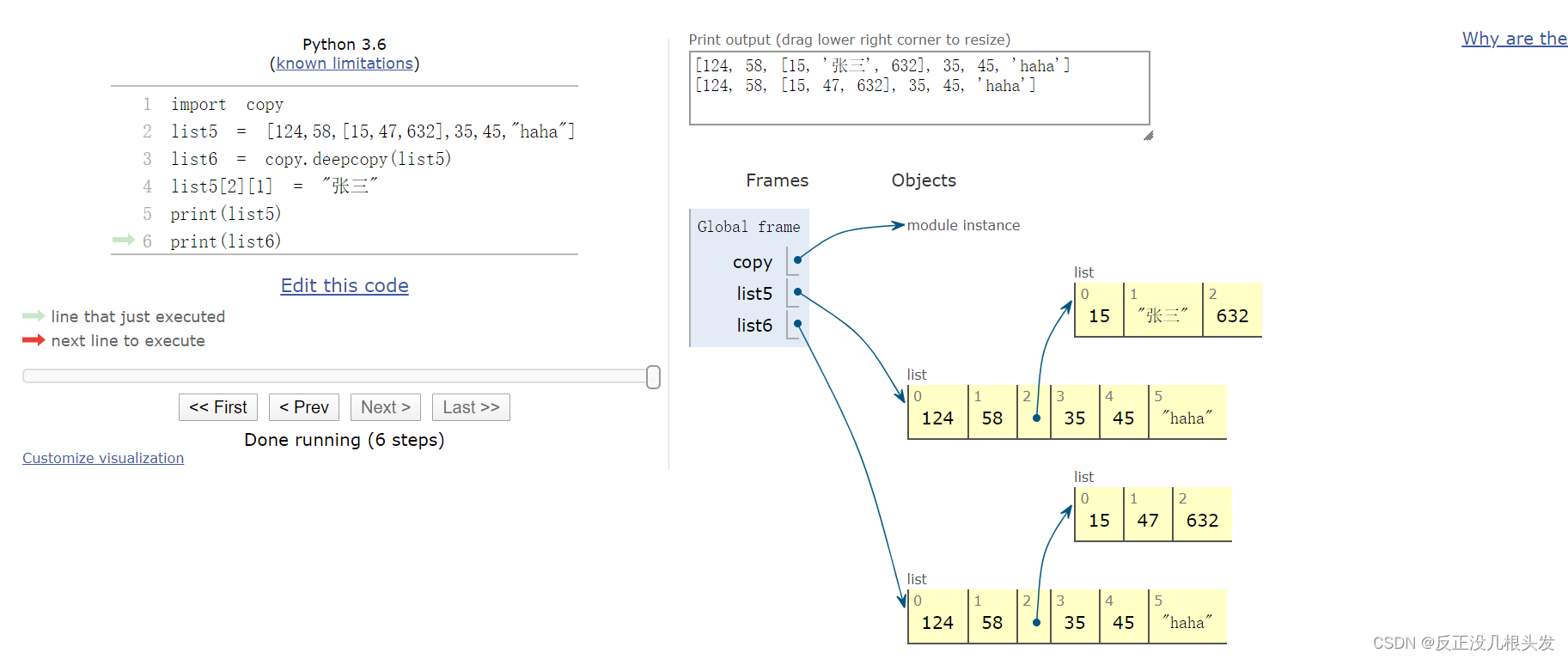
3、深拷贝:对于二维列表,要考虑深拷贝
导入copy模块,使用deepcopy()
import copy
list5 = [124,58,[15,47,632],35,45,"haha"]
list6 = copy.deepcopy(list5)
list5[2][1] = "张三"
print(list5)
print(list6)
内存图
十三、filter和map方法
filter是一个内置类,筛选出满足要求的数据
filter()内置类中有两个参数,第一个参数是函数,第二个参数是一个可迭代对象
ages = [10,12,50,41,62,71,25,36,48,26]
list1 = filter(lambda ele:ele > 30,ages)
print(list(list1)) # [50, 41, 62, 71, 36, 48]
map方法:可以对所有数据进行相同的操作
ages = [10,12,50,41,62,71,25,36,48,26]
list2 = map(lambda ele:ele + 3,ages)
print(list(list2)) # [13, 15, 53, 44, 65, 74, 28, 39, 51, 29]
十四、装饰器
在不改变函数名的情况下,添加新功能,使用了闭包函数
def outer(fn):
def inner(*args):
print("数学运算的结果是:",end="")
fn(*args)
return inner
@outer
def add(a,b):
print(a+b)
add(2,5) # 数学运算的结果是:7
@outer
def jian(a,b,c):
print(a-b-c)
jian(52,20,12) # 数学运算的结果是:20
一个函数被多个装饰器修饰,从离它最近的装饰器开始执行,原函数只执行一次
def outer1(fn):
def inner1():
fn()
print("可能是张三的")
return inner1
def outer2(fn):
def inner2():
fn()
print("可能是李四的")
return inner2
@outer2
@outer1
def sing():
print("这是谁的书?")
sing()
输出
这是谁的书?
可能是张三的
可能是李四的
Python的异常处理机制
try…except结构
try
可能出现异常的代码
except 异常类型
异常处理
try:
n1 = int(input('请输入第一个整数:'))
n2 = int(input('请输入第二个整数:'))
result = n1 / n2
print(result, type(result))
except ZeroDivisionError:
print('除数不能为0!')
except ValueError:
print('输入只能是数字!')
可以采用多个except结构,捕获多个异常
先子类异常,再父类异常,为避免遗漏,可在最后加一个BaseException
try…except…else结构
如果try中没有抛异常,则执行else块
如果try中抛异常,则执行except块
try…except…else…finally结构
finally无论是否发生异常都会执行,常用来释放try块中申请的资源
Python中常见的异常类型
ZeroDivisionError 除(取模)零
IndexError 序列中没有此索引
KeyError 映射中没有这个键
NameError 未声明/初始化对象(没有属性)
SyntaxError Python语法错误
ValueError 传入无效的参数
traceback模块的使用
import traceback
try:
print('------------')
print(1/0)
except:
traceback.print_exc()
会在控制台打印出错信息
内置函数:
input(str类型):输入函数 括号内的是所要输入内容的提示内容 返回的也是str类型
print():输出函数
range():
对象列表不包含stop
range(stop):创建[0,stop]之间的整数序列,步长为1
range(start,stop):创建[start,stop]之间的整数序列,步长为1
range(start,stop,step):创建[start,stop]之间的整数序列,步长为step
可以使用list(range对象)查看range对象中的整数序列
chr():返回类型是String 可以二进制转字符串
ord():返回类型是int 可以得到字符的原始值
其他方法
id(变量名):获取变量的内存地址
type(变量名):获取变量的类型
str():将int或float型转化为str型
类似的有int(),float()















 754
754











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









