







废话不多说了,直接入题。
有如下问题:在字符串s=abcabaaaabaabcac
中寻找是否有与字符串p=abaabcac相匹配的。
方法一:暴力求解
这个方法很简单,就不过多介绍了,看图就能明白

方法二:KMP算法
下面我们来改进一下上面的算法:
假如匹配到了如下步骤:
a b c a b a a a a b a a b c a c
a b a a b c a c
如果按照上面的思路,又要从字符串p的p[0]开始判断,但是我们观察一下绿色部分,他们是子串abaa中相同的前缀和后缀
既然如此,我们就不用从同开始判断了,可以从p[1]开始判断,即下面的蓝色部分
a b c a b a a a a b a a b c a c
a b a a b c a c
再附上一张动图
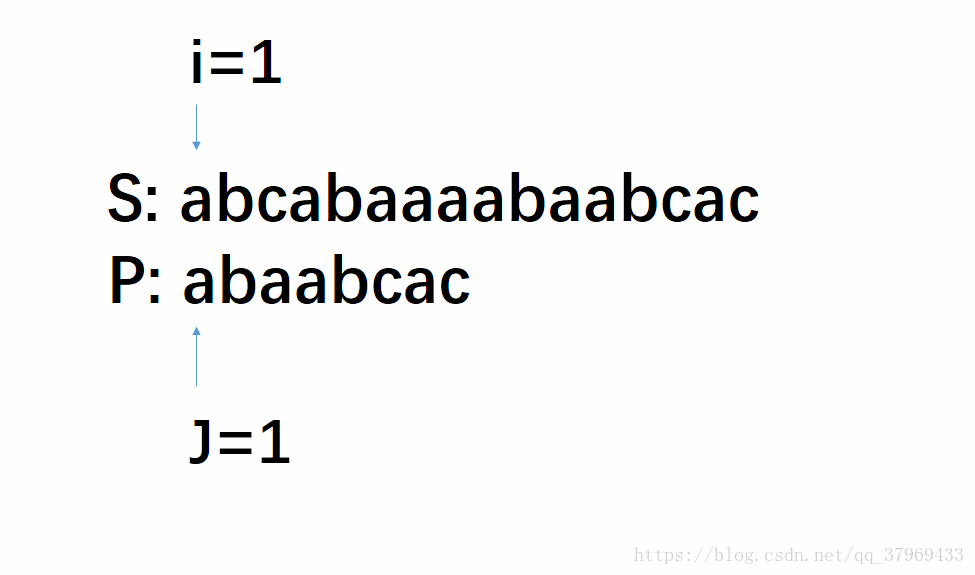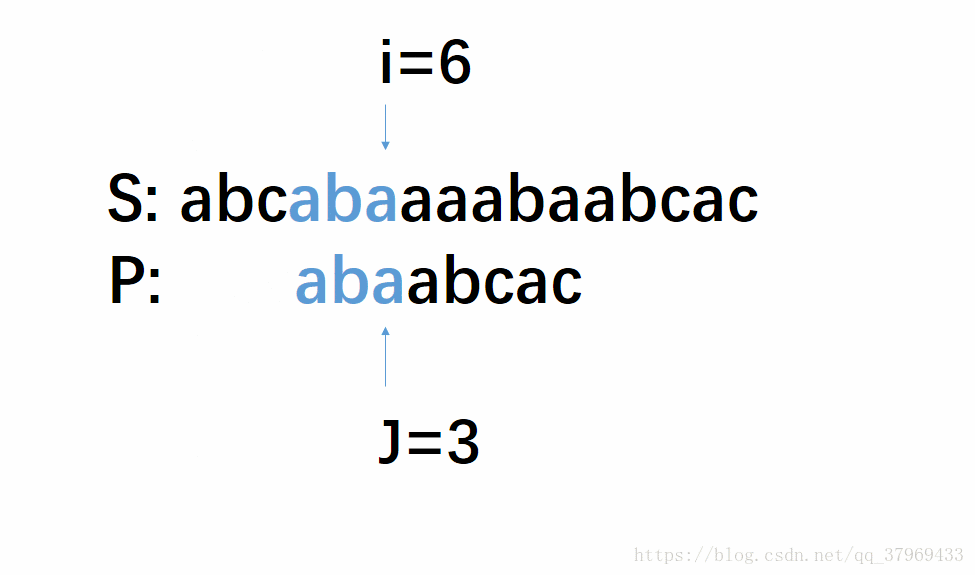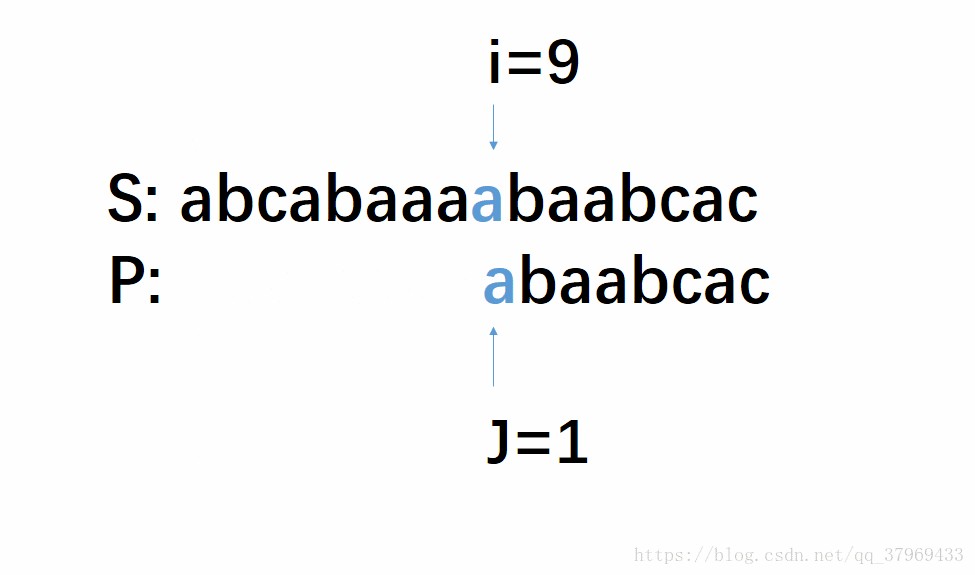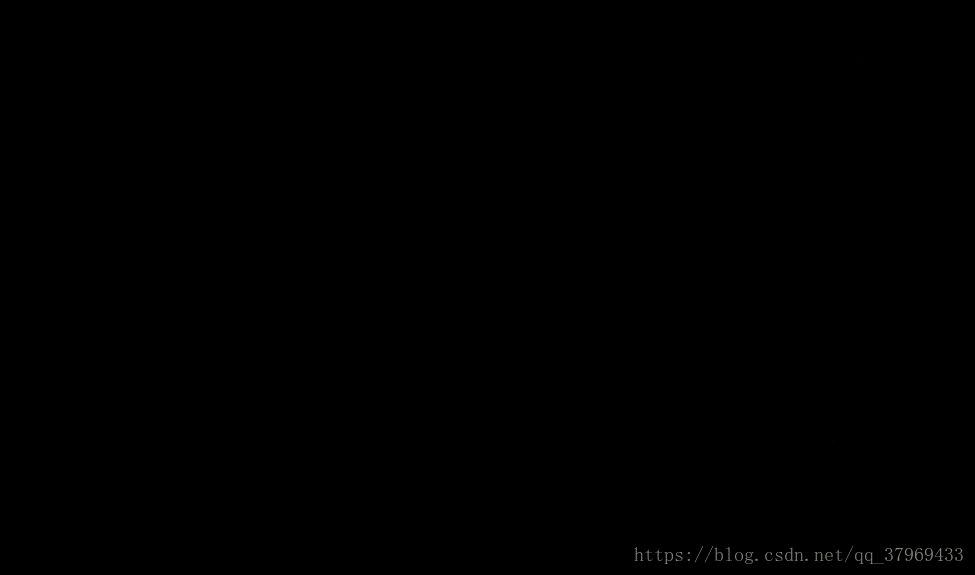
下面我们就来分析一下这个算法
相比暴力求解:
暴力求解: 每次失配,S串的索引i定位的本次尝试匹配的第一个字符的后一个。P串的索引j定位到1;T(n)=O(n*m)
KMP算法: 每次失配,S串的索引i不动,P串的索引j定位到某个数。T(n)=O(n+m),时间效率明显提高
那么如何定位呢?答案就在我们刚刚提到的前缀和后缀
a b c a b a a a a b a a b c a c
a b a a b c a c
如果某次比较失败,即s[i]!=p[j], 而正好子串有相同的前缀和后缀,则可以直接移到前缀的后一个字符开始比较,如上。
澄清几个概念:
1、子串:是不包括匹配失败的字符的前一段,即 a b a a b 中的 a b a a,不包括匹配失败的 b
2、前缀后一个字符:即a b a a 中前缀a 的后一个字符 b(若没有相同的前缀和后缀此时就从头开始判断,与暴力破解一样)
所以,我们首先要做的就是求每一个子串的前缀和后缀相等的最大值,先看算法,再解析
public static void Next(String str, int[] next) {
//D A B C D A B D E
int pLen = str.length();
next[0] = -1;
int k = -1;
int j = 0;
while (j < pLen - 1) {
if (k == -1 || str.charAt(j) == str.charAt(k)) {
++k;
++j;
next[j] = k;
} else {
k = next[k];
}
}
}你也会意识到next 数组各值的含义:代表当前字符之前的字符串中,有多大长度的相同前缀后缀。例如如果next [j] = k, 代表 j 之前的字符串中有最大长度为 k 的相同前缀后缀。
此也意味着在某个字符失配时,该字符对应的next 值会告诉你下一步匹配中,模式串应该跳到哪个位置(跳到next [j] 的位置)。如果next [j] 等于0或-1,则跳到模式串的开头字符
建议:next数组的建立自己上机跑一遍,推导推导,这样好理解一些
准备工作做好之后就可以写代码了
public static void Next(String str, int[] next) {
//D A B C D A B D E
int pLen = str.length();
next[0] = -1;
int k = -1;
int j = 0;
while (j < pLen - 1) {
//p[k]表示前缀,p[j]表示后缀
if (k == -1 || str.charAt(j) == str.charAt(k)) {
++k;
++j;
next[j] = k;
} else {
k = next[k];
}
}
}
public static boolean kmp(String str, String pat, int[] next) {
int i = 0, j = 0;
int sLen = str.length();
int pLen = pat.length();
while (i < sLen && j < pLen) {
if (j == -1 || str.charAt(i) == pat.charAt(j)) {
i++;
j++;
} else {
j = next[j]; //这条语句下面有解释
}
}
if (j == pLen) {
return true;
}
return false;
}解释一下其中一条语句
j = next[ j ]

这个地方不太好理解,可以多上机跑一下,自己动手推导推导
参考资料
https://blog.csdn.net/v_JULY_v/article/details/7041827
https://blog.csdn.net/qq_37969433/article/details/82947411















 123
123











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









