







 本文介绍了维护无重复字符滑动窗口的方法,从初始的队列策略,到使用集合减少删除操作,再到利用字典记录元素位置以避免重复删除,逐步提高查找最长无重复子串的效率。
本文介绍了维护无重复字符滑动窗口的方法,从初始的队列策略,到使用集合减少删除操作,再到利用字典记录元素位置以避免重复删除,逐步提高查找最长无重复子串的效率。
🚀总结
本题的核心在于维护一个队列(滑动窗口),保证队列中的字符串始终是无重复的。
对于一个即将要加入队列的新元素 X X X,如果新元素 X X X 在当前队列中出现过,则从 队头 持续删除元素,直到队列中不再包括新元素 X X X,再将新元素 X X X 添加至 队尾。
例如,对于下面的字符串,假设当前队列包括 “cab”,对于即将要加入队列的新元素 “c”,因为在第 2 个位置上出现过字符 “c”,所以需要从 队头 删除元素 “c”,然后再将第 5 个位置上的字符 “c” 添加至队列中。
当窗口滑动完整个字符串,出现过的最长窗口的长度就是本题答案。
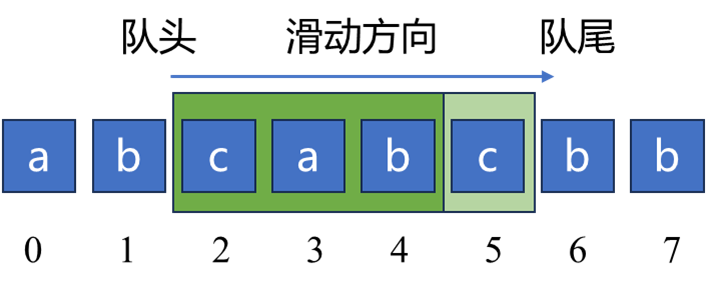
上述思路的一个明显缺点是:当新元素 X X X 在队列中出现过,并且出现的位置比较靠后时,需要重复多次删除新元素 X X X 及其之前的元素,导致效率降低。因此,本题的一个重要改进是:记录下新元素 X X X 上次出现时的位置,然后直接一次更新新窗口位置,新窗口起点等于新元素 X X X 上次出现时的位置向右一位的位置。
📇题目

⭐思路
方法一:
题目要求求解无重复字符的最长子串,一种容易想到的思路是遍历找到所有的无重复字符串,我们可以维护一个队列 window_elements 来表示无重复字符串。
从左向右依次遍历字符串中的每一个字符,对于一个即将要加入队列 window_elements 队尾 的新元素
X
X
X :
如果新元素
X
X
X 在 队列 window_elements 中已经出现过,则应该持续删除 队头 元素直至队列 window_elements 中不再包括新元素
X
X
X。
然后再将新元素
X
X
X 加入到队列 window_elements 中,计算当前队列 window_elements 的长度,如果大于之前最长的队列长度,则更新结果。
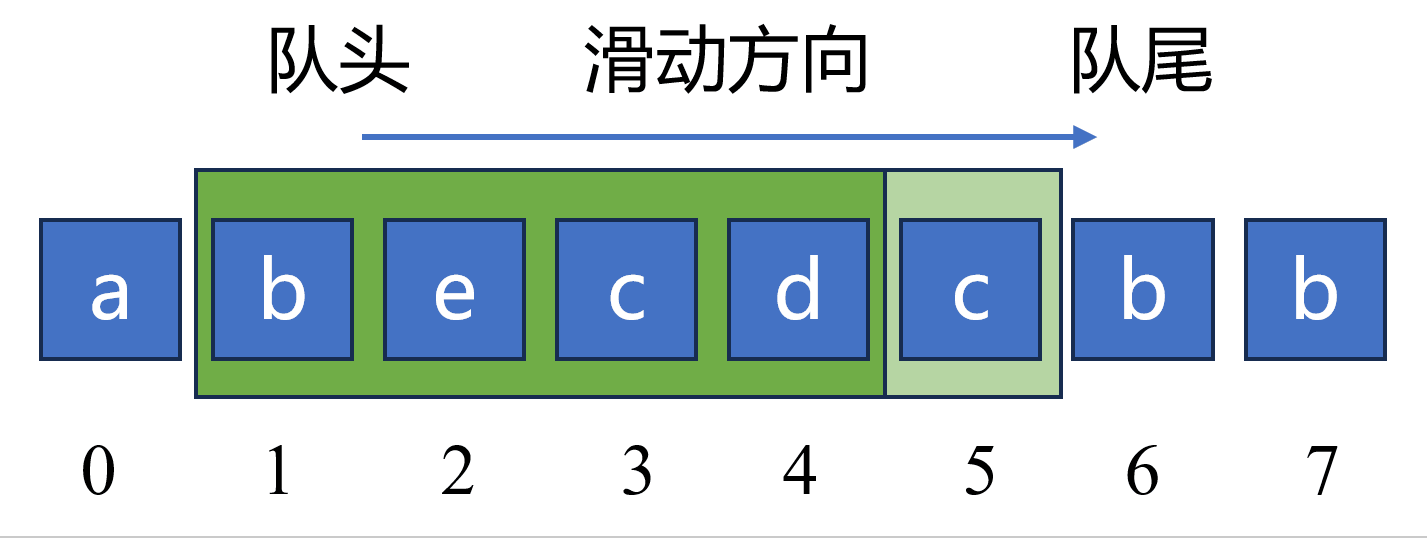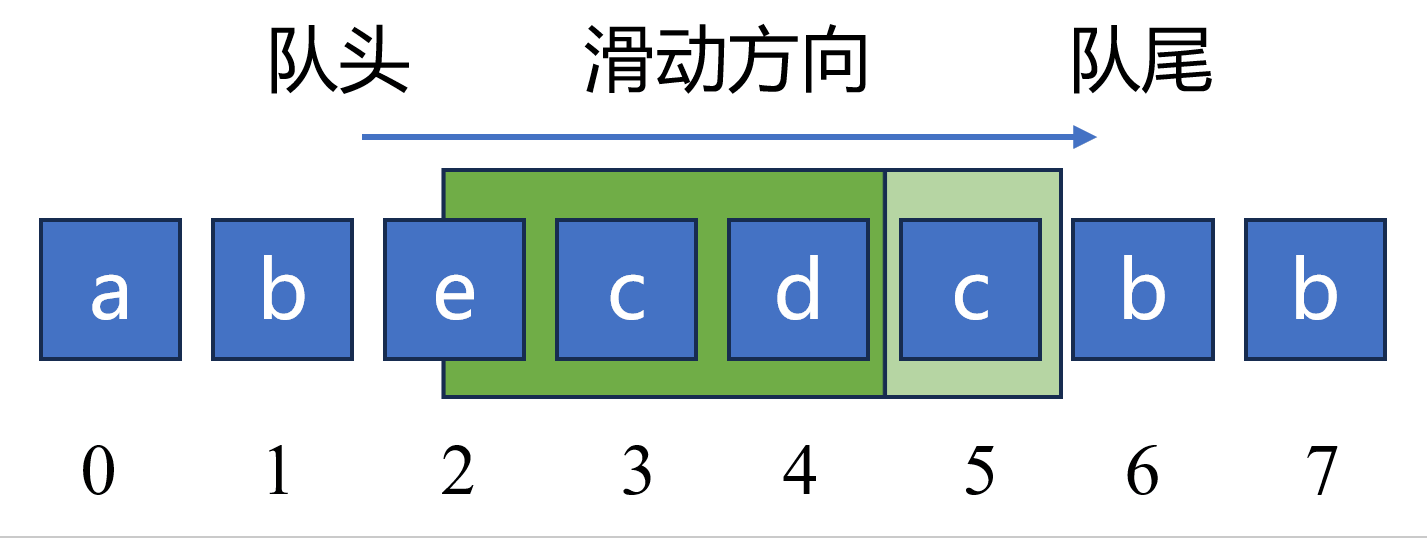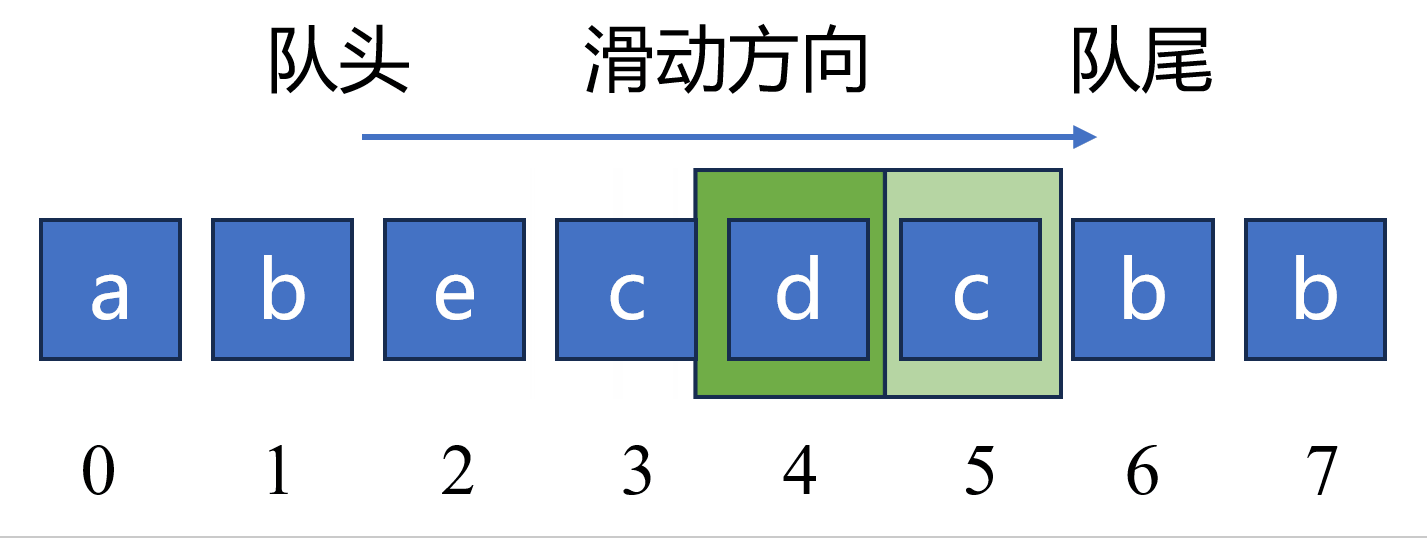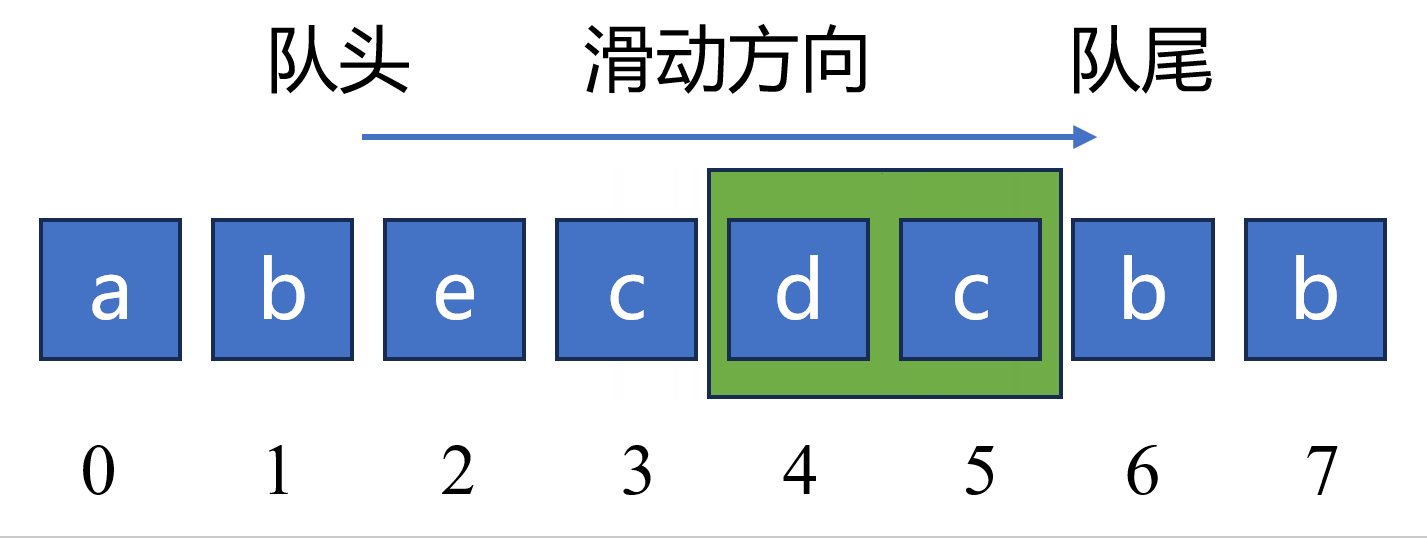
如下图,当队列元素包括 “becd” 时,对于新元素 “c” ,因为 “c” 已经在队列中出现过,所以应该持续从 队头 删除元素 “bec”,然后再将元素 “c” 添加至队列中。此时,队列长度由原来的 4 更新为 2。
根据以上思路可以实现如下代码,使用一个列表来实现队列的功能,通过 pop() 函数和 append() 函数分别实现 队头 元素删除和 队尾 元素添加。
class Solution:
def lengthOfLongestSubstring(self, s: str) -> int:
res = 0 # 初始化结果为 0
window_elements = [] # 定义 window_elements 存储队列元素
for char in s: # 遍历字符串中的每一个字符
while char in window_elements: # 如果字符在队列中出现过
window_elements.pop(0) # 删除 队头 的元素
window_elements.append(char) # 将新元素添加至队尾
res = max(res, len(window_elements)) # 更新结果
return res

尽管以上代码可以解决该题目,但是这种解法效率不高(如上图)。这主要是以下两个原因导致的:
window_elements.pop(0)操作效率很低,它在Python中的时间复杂度为 O(n)。这是因为每次调用pop(0)时,列表中剩余的所有元素都需要向前移动一个位置。- 在
while char in window_elements循环中,每次都需要遍历整个window_elements来检查是否存在重复字符。这一操作的时间复杂度也是 O(n)。
方法二:
根据以上代码中存在的问题,我们发现,在 Python 中使用列表来实现队列效率是非常低的。
如果新元素 X X X 在原始队列中出现过,并且出现的位置在原始队列中比较靠后,那么就需要迭代很多次进行删除操作,直至原始队列中没有再出现过新元素 X X X。
一种改进思路是:用集合替代原来的列表,即用表示无重复子串。
使用集合 char_set 表示无重复子串,对于一个即将加入集合的新元素
X
X
X ,如果新元素
X
X
X 在集合中出现过,则应该持续删除 队头 元素直至队列 window_elements 中不再包括新元素
X
X
X。
但与之前方法不同的是,我们不再使用 pop(0) 来删除 队头 元素,而是使用指针变量 left 指向 队头,通过 remove(char_set[left]) 来实现,这样就避免了 Python 中列表删除效率过低的问题。
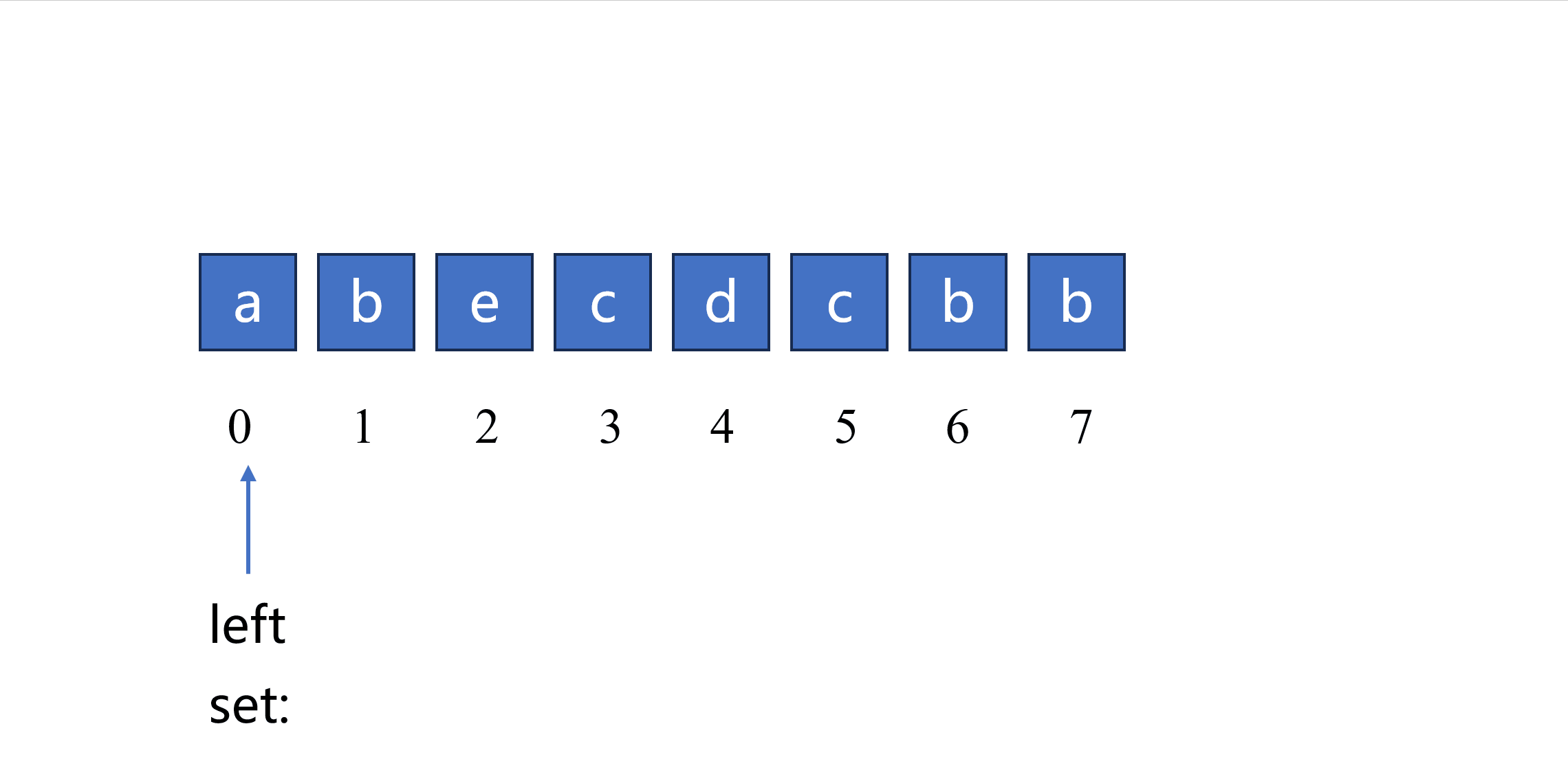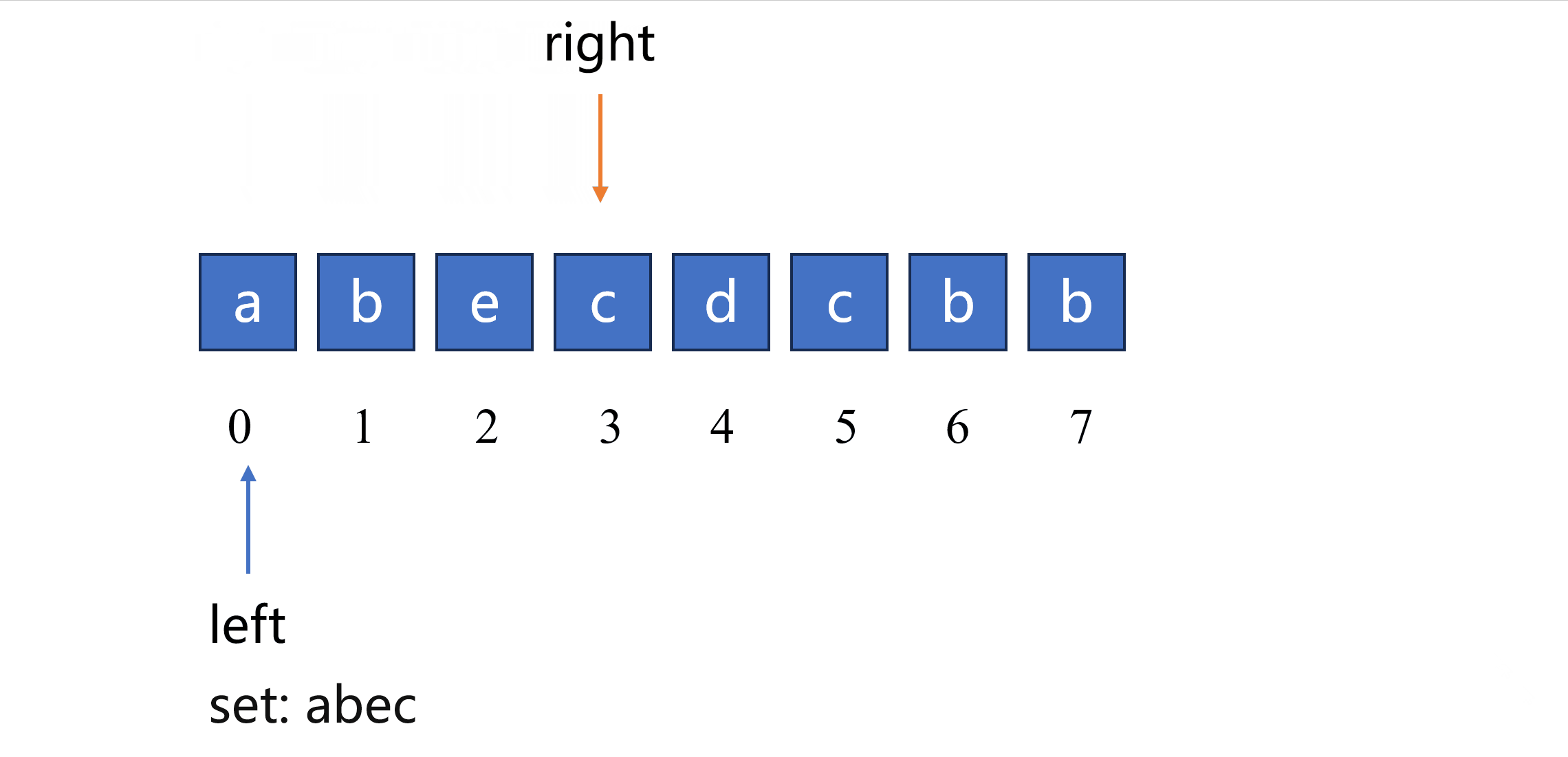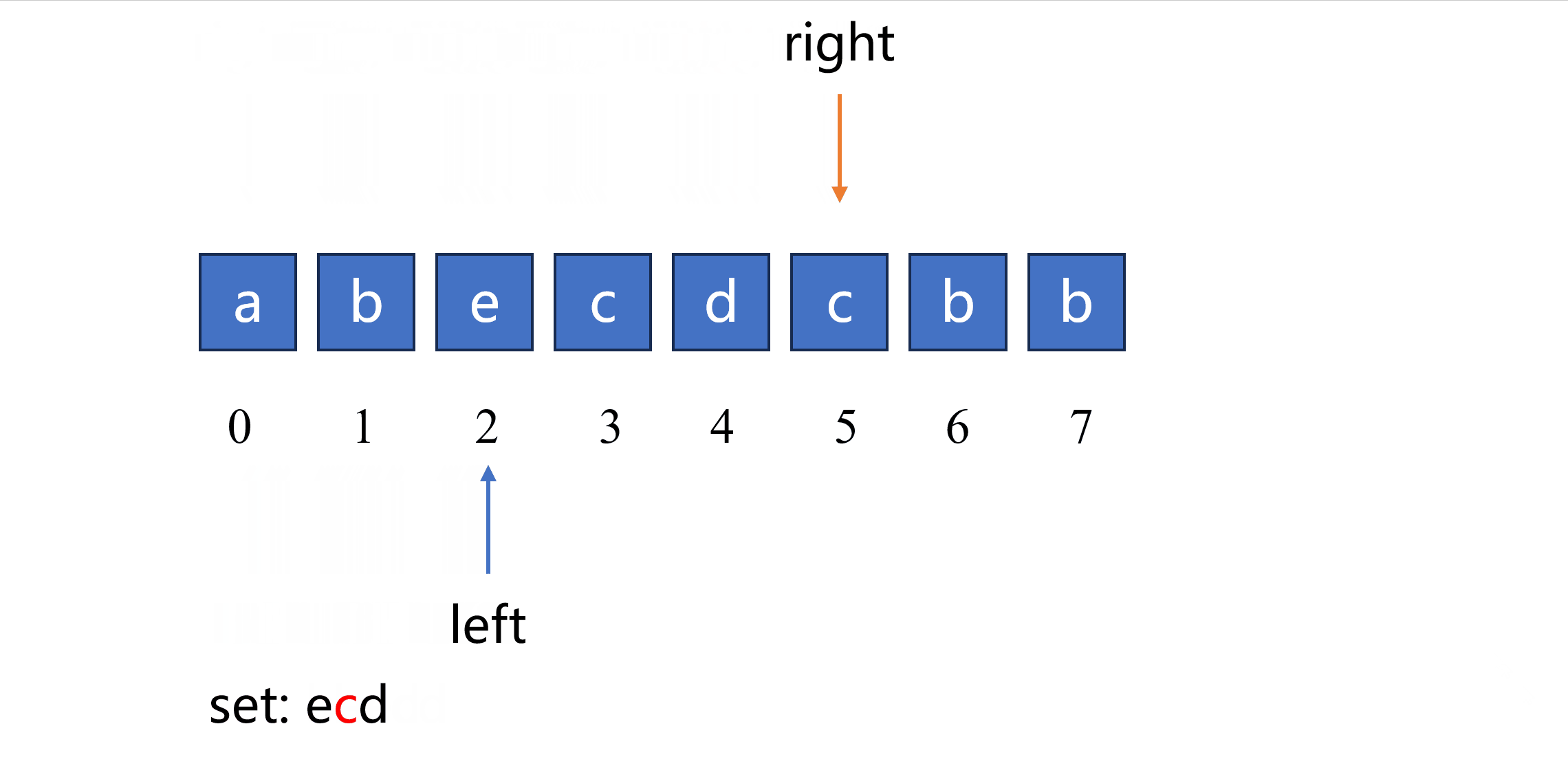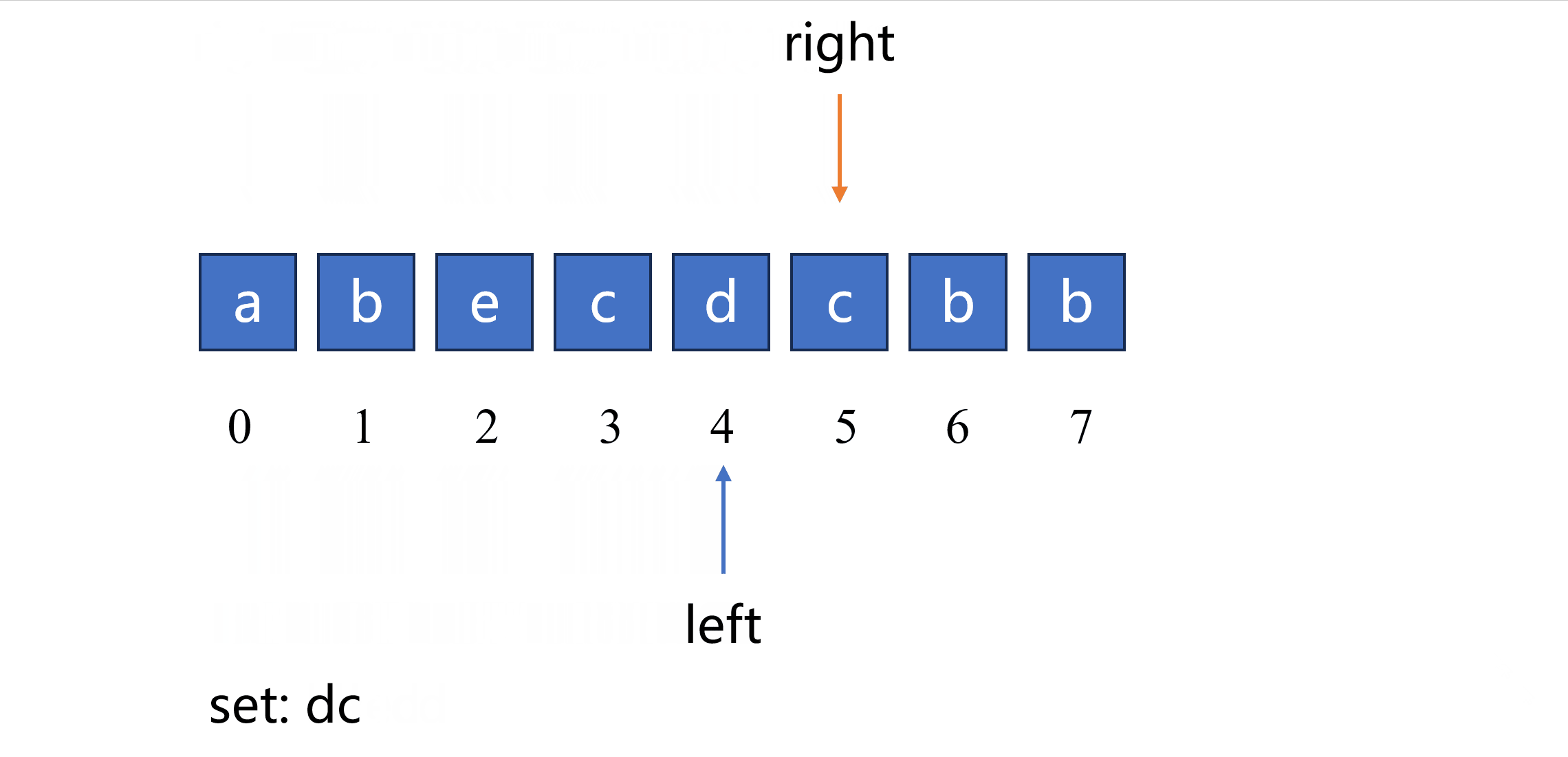
根据以上思路可以实现如下代码,使用一个集合来实现队列的功能,通过 remove(s[left]) 函数和 add(s[right]) 函数分别实现 队头 元素删除和 队尾 元素添加。
class Solution:
def lengthOfLongestSubstring(self, s: str) -> int:
char_set = set() # 定义集合 char_set 表示无重复子串
res = 0 # 初始化结果为 0
left = 0 # 初始化左指针为 left
for right in range(len(s)): # 遍历字符串中的每一个字符
while s[right] in char_set: # 如果字符在队列中出现过
char_set.remove(s[left]) # 从集合中删除出现过的字符
left += 1 # 左指针右移一位
char_set.add(s[right]) # 将新元素添加至集合
res = max(res, right - left + 1) # 更新结果
return res

方法三:
方法二解决了方法一中列表删除元素效率低的问题,效率有所提升(如上图),但是仍然没有解决使用 while 语句重复判断队列中是否仍然存在当前新元素的问题。
当发现新元素 X X X 在原始队列中出现过,我们希望不要再逐一删除原始队列中新元素 X X X 及其之前的元素,而是直接一次性更新窗口的新起点。因此我们需要知道新元素 X X X 出现在原始队列中的哪个位置,也就是说队列不仅要记录元素,而且要记录元素的索引,一种容易想到的方法是使用 字典。
使用字典 last_loc 来记录出现过的每个元素及其索引,对于一个即将加入队列的新元素
X
X
X ,如果新元素
X
X
X 出现过,并且上次出现的位置在窗口起点的右侧,则说明当前新元素
X
X
X 在窗口内。此时,我们不再逐一删除窗口内新元素
X
X
X 及其之前的所有元素,而是直接更新窗口起点位置,新的窗口起点位置等于新元素
X
X
X 在窗口中出现的位置右边一位的位置。
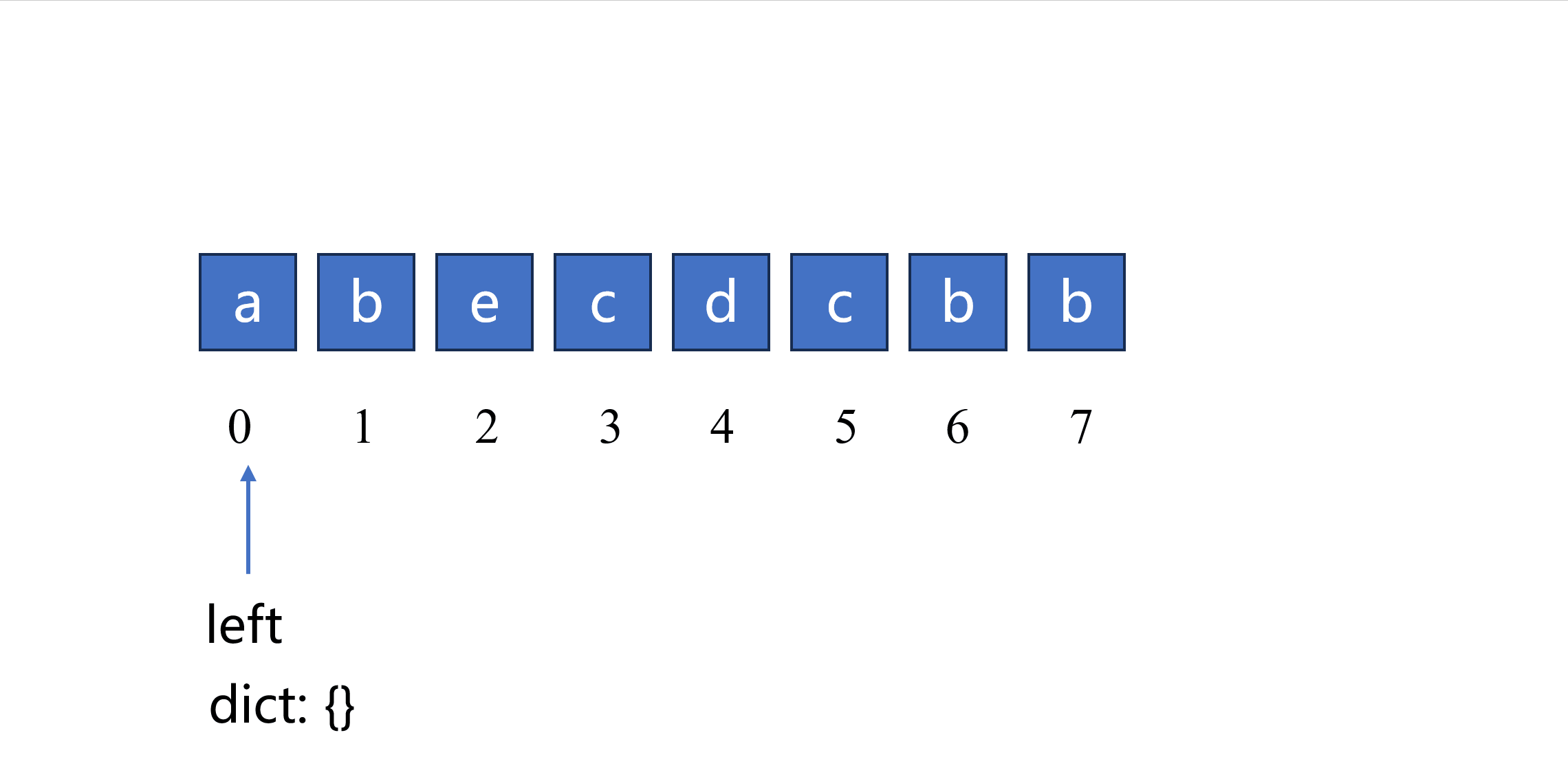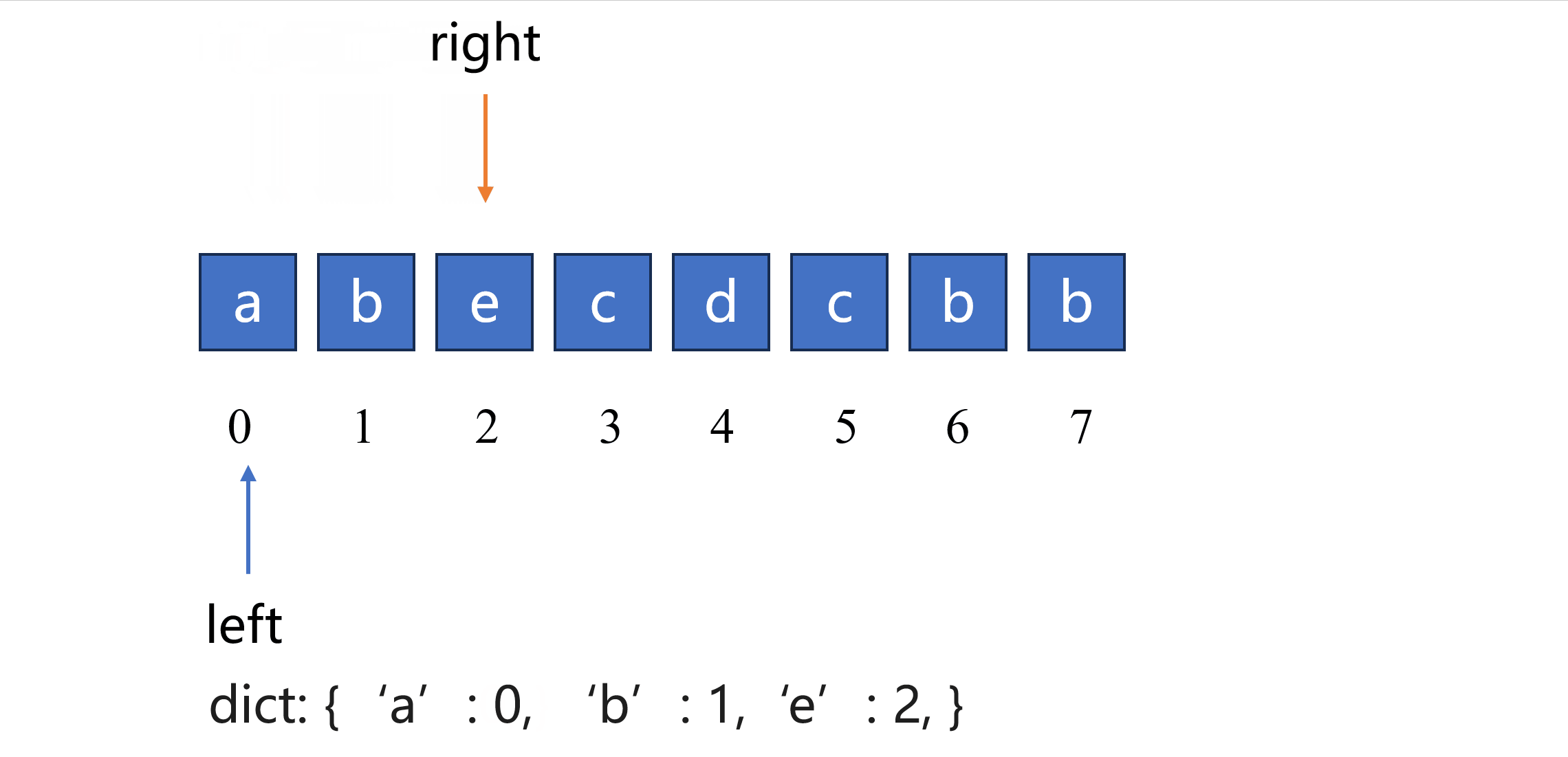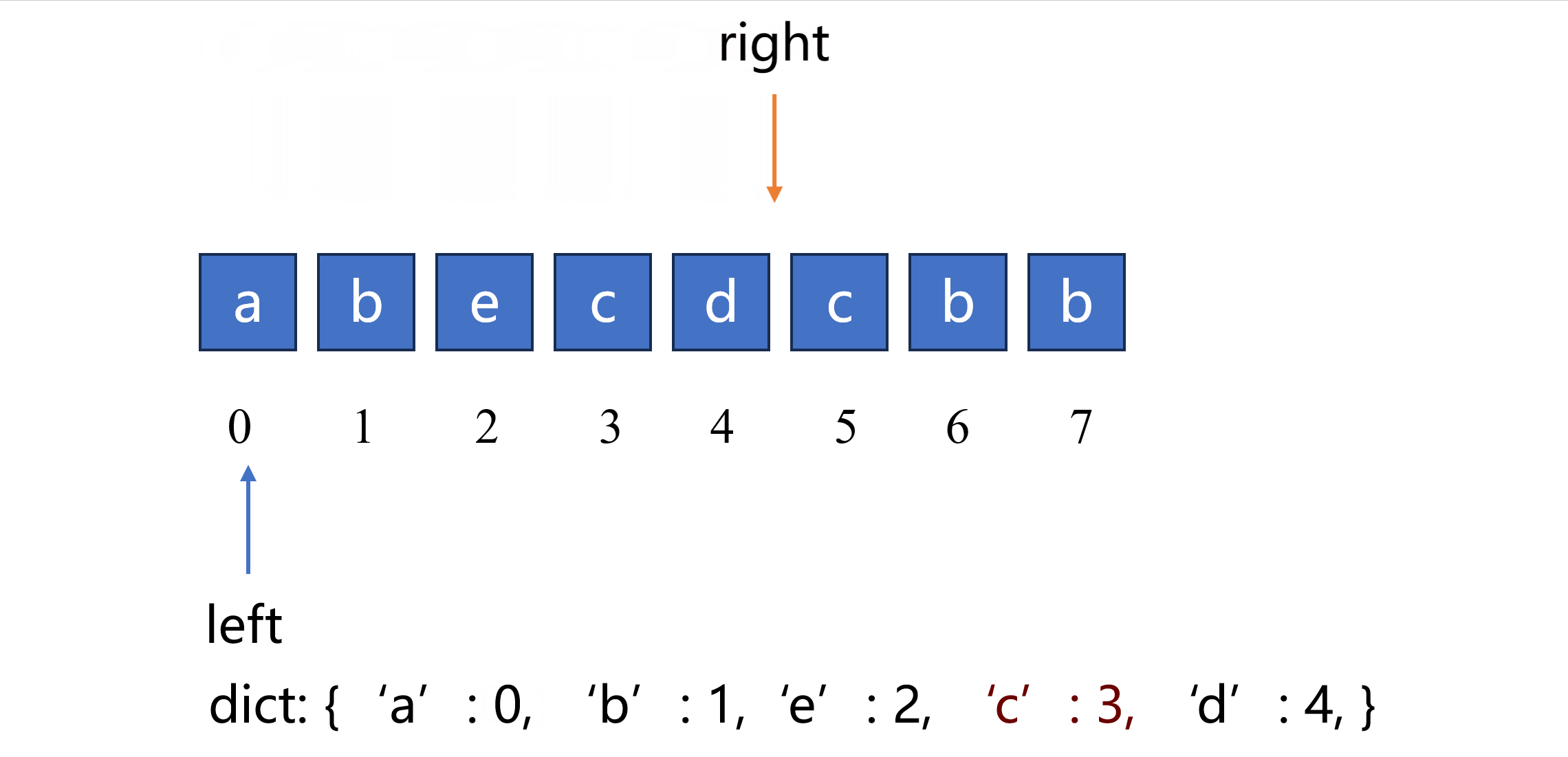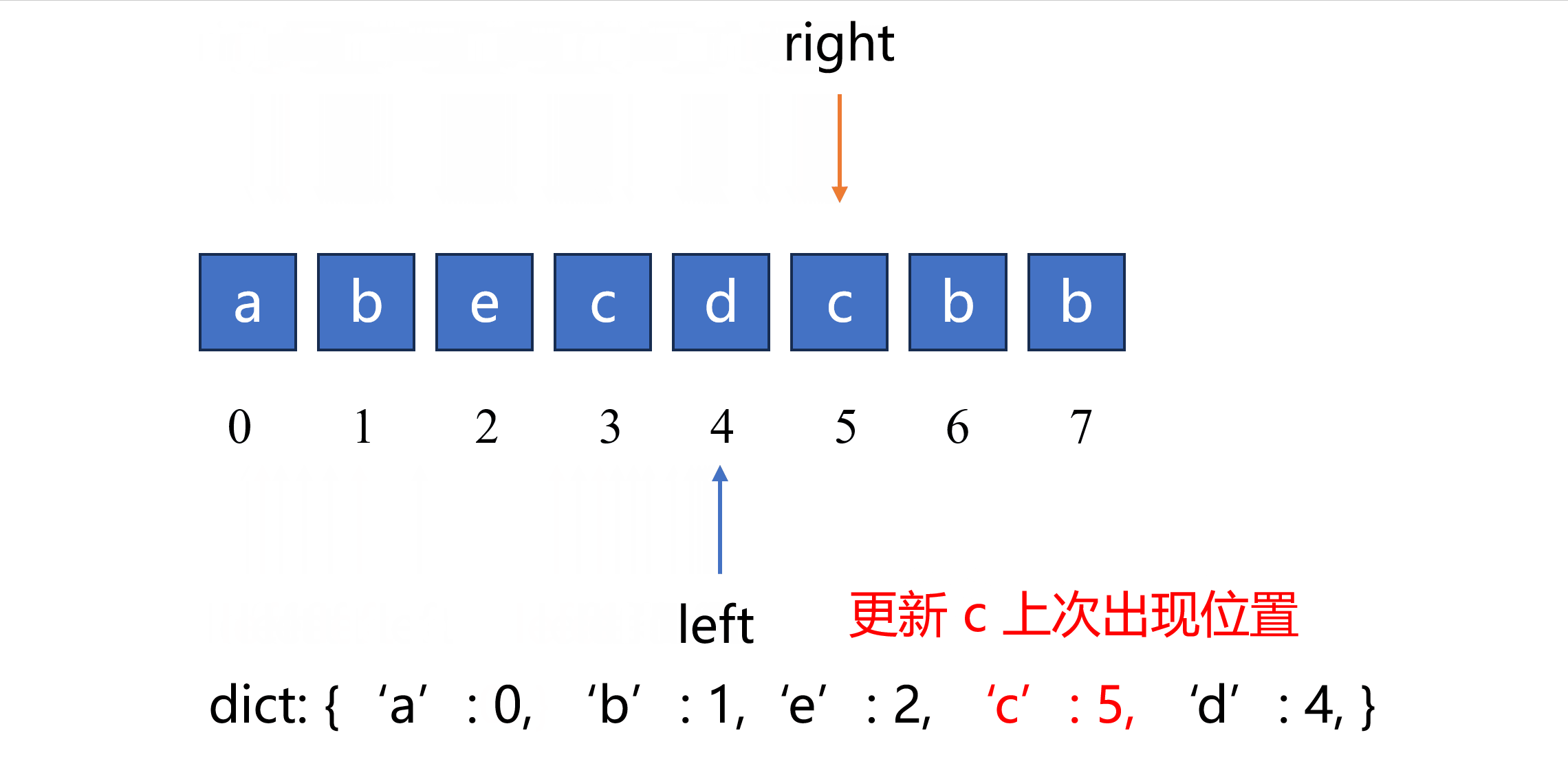
根据以上思路可以实现如下代码,使用一个字典来记录元素上次出现过的位置。
class Solution:
def lengthOfLongestSubstring(self, s: str) -> int:
res = 0 # 初始化结果为 0
last_loc = {} # 定义字典 last_loc 用于存储无重复字串信息
left = 0 # 窗口的起始位置
for right, char in enumerate(s): # 遍历字符串中的每一个字符
# 如果字符已经在窗口中,更新窗口起始位置
if char in last_loc and last_loc[char] >= left:
left = last_loc[char] + 1
# 更新字符的最新位置
last_loc[char] = right
# 更新结果
res = max(res, right - left + 1)
return res

🛠️代码
class Solution:
def lengthOfLongestSubstring(self, s: str) -> int:
res = 0 # 初始化结果为 0
last_loc = {} # 定义字典 last_loc 用于存储无重复字串信息
left = 0 # 窗口的起始位置
for right, char in enumerate(s): # 遍历字符串中的每一个字符
# 如果字符已经在窗口中,更新窗口起始位置
if char in last_loc and last_loc[char] >= left:
left = last_loc[char] + 1
# 更新字符的最新位置
last_loc[char] = right
# 更新结果
res = max(res, right - left + 1)
return res















 158
158











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









