







学习思路如下:
二、JavaEE部分—题目
❤2、web编程进阶
1、forward与redirect区别,说一下你知道的状态码,redirect的状态码是多少?
2、servlet生命周期,是否单例,为什么是单例。
3、说出Servlet的生命周期,并说出Servlet和CGI的区别。
4、Servlet执行时一般实现哪几个方法?
5、阐述一下阐述Servlet和CGI的区别?
6、说说Servlet接口中有哪些方法?
7、Servlet 3中的异步处理指的是什么?
8、如何在基于Java的Web项目中实现文件上传和下载?
9、服务器收到用户提交的表单数据,到底是调用Servlet的doGet()还是doPost()方法?
10、Servlet中如何获取用户提交的查询参数或表单数据?
11、Servlet中如何获取用户配置的初始化参数以及服务器上下文参数?
12、讲一下redis的主从复制怎么做的?
13、redis为什么读写速率快性能好?
14、redis为什么是单线程?
15、缓存的优点?
16、aof,rdb,优点,区别?
17、redis的List能用做什么场景?
18、说说MVC的各个部分都有那些技术来实现?如何实现?
19、什么是DAO模式?
20、请问Java Web开发的Model 1和Model 2分别指的是什么?
21、你的项目中使用过哪些JSTL标签?
22、使用标签库有什么好处?如何自定义JSP标签?(JSP标签)
答案部分:2)web编程进阶
参考—https://blog.csdn.net/qq_38977097/article/details/88853266
1、forward与redirect区别,说一下你知道的状态码,redirect的状态码是多少?
答:
- 定义:
1)forward:request.getRequestDispatcher("new.jsp").forward(request, response); //转发到new.jsp
2)redirect:response.sendRedirect("new.jsp"); //重定向到new.jsp
3)一个是用request对象调用,一个是用response对象调用 - 区别:
- A)数据共享方面
1)forward:转发页面和转发到的页面可以共享request里面的数据
2)redirect:不能共享数据 - B)地址栏显示方面
1)forward是服务器请求资源,服务器直接访问目标地址的URL,把那个URL的响应内容读取过来,然后把这些内容再发给浏览器。浏览器根本不知道服务器发送的内容从哪里来的,所以它的地址栏还是原来的地址。
2)redirect是服务端根据逻辑,发送一个状态码,告诉浏览器重新去请求那个地址,地址栏显示的是新的URL。 - C)本质区别:转发是服务器行为,重定向是客户端行为。工作流程:
1)转发过程:
客户浏览器发送http请求—>web服务器接受此请求—>调用内部的一个方法在容器内部完成请求处理和转发动作—>将目标资源发送给客户;在这里,转发的路径必须是同一个web容器下的url,其不能转向到其他的web路径上去,中间传递的是自己的容器内的request。在客户浏览器路径栏显示的仍然是其第一次访问的路径,也就是说客户是感觉不到服务器做了转发的。转发行为是浏览器只做了一次访问请求。
2)重定向过程:
客户浏览器发送http请求—>web服务器接受后发送302状态码响应及对应新的location给客户浏览器—>客户浏览器发现 是302响应,则自动再发送一个新的http请求,请求url是新的location地址—>服务器根据此请求寻找资源并发送给客户。在这里 location可以重定向到任意URL,既然是浏览器重新发出了请求,则就没有什么request传递的概念了。在客户浏览器路径栏显示的是其重定向的 路径,客户可以观察到地址的变化的。重定向行为是浏览器做了至少两次的访问请求的。
注意: 重定向,其实是两次request:第一次,客户端request A,服务器响应,并response回来,告诉浏览器,你应该去B。这个时候IE可以看到地址变了,而且历史的回退按钮也亮了。重定向可以访问自己web应用以外的资源。在重定向的过程中,传输的信息会被丢失。
2、servlet生命周期,是否单例,为什么是单例?
答:Servlet并不是单例,只是容器让它只实例化一次,表现出来的是单例的效果而已。
1)加载和实例化:
当Servlet容器启动或客户端发送一个请求时,Servlet容器会查找内存中是否存在该Servlet实例,若存在,则直接读取该实例响应请求;如果不存在,就创建一个Servlet实例。
2) 初始化:
实例化后,Servlet容器将调用Servlet的init()方法进行初始化(一些准备工作或资源预加载工作)。
3)服务:
初始化后,Servlet处于能响应请求的就绪状态。当接收到客户端请求时,调用service()的方法处理客户端请求,HttpServlet的service()方法会根据不同的请求,转调不同的doXxx()方法。
4)销毁:
当Servlet容器关闭时,Servlet实例也随时销毁。其间,Servlet容器会调用Servlet 的destroy()方法去判断该Servlet是否应当被释放(或回收资源)。
3、说出Servlet的生命周期,并说出Servlet和CGI的区别。
答:
-
1)Servlet 生命周期:
1、加载
2、实例化
3、初始化
4、处理请求
5、销毁 -
2)Servlet与CGI的区别:
Servlet处于服务器进程中,它通过多线程方式运行其service方法,一个实例可以服务于多个请求,并且其实例一般不会销毁,而CGI对每个请求都产生新的进程,服务完成后就销毁,所以效率上低于servlet。 -
3)Servlet与JSP的比较:
有许多相似之处,都可以生成动态网页。
JSP的优点是擅长于网页制作,生成动态页面比较直观,缺点是不容易跟踪与排错。
Servlet是纯Java语言,擅长于处理流程和业务逻辑,缺点是生成动态网页不直观。
4、Servlet执行时一般实现哪几个方法?
答:
- Servlet类要继承的GenericServlet与HttpServlet类和一般要实现的几个方法:GenericServlet与HttpServlet类;
- GenericServlet类是一个实现了Servlet的基本特征和功能的基类,其完整名称为javax.servlet.GenericServlet,它实现了Servlet和ServletConfig接口。
- HttpServlet类是GenericServlet的子类,其完整名称为javax.servlet.HttpServlet,它提供了处理HTTP协议的基本构架。如果一个Servlet类要充分使用Http协议的功能,就应该继承HttpServlet。在HttpServlet类及其子类中,除可以调用HttpServlet类内部新定义的方法外,还可以调用包括Servlet,ServletConfig接口和GenericServlet类中的一些方法。
- Servlet执行时一般要实现的方法
public void init(ServletConfig config)
public ServletConfig getServletConfig()
public String getServletInfo()
public void service(ServletRequest request,ServletResponse response)
public void destroy()
1)init ()方法在servlet的生命周期中仅执行一次,在servlet引擎创建servlet对象后执行。Servlet在调用init方法时,会传递一个包含servlet的配置和运行环境信息的ServletConfig对象。如果初始化代码中要使用到ServletConfig对象,则初始化代码就只能在Servlet的init方法中编写,而不能在构造方法中编写。缺省的init()方法通常是符合要求的,不过也可以根据需要进行 override,比如管理服务器端资源,初始化数据库连接等,缺省的inti()方法设置了servlet的初始化参数,并用它 的ServeltConfig对象参数来启动配置,所以覆盖init()方法时,应调用super.init()以确保仍然执行这些任务。
2)service ()方法是servlet的核心,用于响应对Servlet的访问请求。对于HttpServlet,每当客户请求一个 HttpServlet对象,该对象的service()方法就要被调用,HttpServlet缺省的service()方法的服务功能就是调用与 HTTP请求的方法相应的do功能,doPost()和doGet(),所以对于HttpServlet,一般都是重写doPost()和doGet() 方法。
3)destroy()方法在servlet的生命周期中也仅执行一次,即在服务器停止卸载servlet之前被调用,把servlet作为 服务器进程的一部分关闭。缺省的destroy()方法通常是符合要求的,但也可以override,来完成与init方法相反的功能。比如在卸载servlet时将统计数字保存在文件 中,或是关闭数据库连接或IO流。
4)getServletConfig()方法返回一个servletConfig对象,该对象用来返回初始化参数和servletContext。servletContext接口提供有关servlet的环境信息。
5)getServletInfo()方法提供有关servlet的描述信息,如作者,版本,版权。可以对它进行覆盖。
6)doxxx方法 客户端可以用HTTP协议中规定的各种请求方式来访问Servlet,Servlet采取不同的访问方式进行处理。不管那种请求方式访问Servlet,Servlet引擎都会调用Servlet的service方法,service方法是所有请求方式的入口。
doGet 用于处理Get请求
doPost用于处理Post请求
doHead用于处理Head请求
doPut 用于处理Put请求
doDelete 用于处理Delete请求
doTrace 用于处理Trace请求
doOptions用于处理OPTIONS请求
5、阐述一下阐述Servlet和CGI的区别?
答:参考—https://www.cnblogs.com/MuyouSome/p/3938203.html
概括来讲,Servlet可以完成和CGI相同的功能。
- Servlet被服务器实例化后,容器运行其init方法,请求到达时运行其service方法,service方法自动派遣运行与请求对应的doXXX方法(doGet,doPost)等,当服务器决定将实例销毁的时候调用其destroy方法。
- servlet处于服务器进程中,它通过多线程方式运行其service方法,一个实例可以服务于多个请求,并且其实例一般不会销毁,而CGI对每个请求都产生新的进程,服务完成后就销毁,所以效率上低于servlet。
6、说说Servlet接口中有哪些方法?
答:Servlet接口定义了5个方法,其中前三个方法与Servlet生命周期相关:
- void init(ServletConfig config) throws ServletException
- void service(ServletRequest req, ServletResponse resp) throws ServletException, java.io.IOException
- void destory()
- java.lang.String getServletInfo()
- ServletConfig getServletConfig()
运行机制: Web容器加载Servlet并将其实例化后,Servlet生命周期开始,容器运行其init()方法进行Servlet的初始化;请求到达时调用Servlet的service()方法,service()方法会根据需要调用与请求对应的doGet或doPost等方法;当服务器关闭或项目被卸载时服务器会将Servlet实例销毁,此时会调用Servlet的destroy()方法。
7、Servlet 3中的异步处理指的是什么?
答:如果一个任务处理时间相当长,那么Servlet或Filter会一直占用着请求处理线程直到任务结束,随着并发用户的增加,容器将会遭遇线程超出的风险,这种情况下很多的请求将会被堆积起来而后续的请求可能会遭遇拒绝服务,直到有资源可以处理请求为止。
- 异步特性可以帮助应用节省容器中的线程,适合执行时间长而且用户需要得到结果的任务,当用户不需要得到结果则直接将一个Runnable对象交给Executor并立即返回即可。
- 下面是一个支持异步处理请求的Servlet的例子:
package chimomo.learning.java.code.jsp;
import javax.servlet.AsyncContext;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
@WebServlet(urlPatterns = {"/async"}, asyncSupported = true)
public class AsyncServlet extends HttpServlet {
private static final long serialVersionUID = 1L;
@Override
public void doGet(HttpServletRequest req, HttpServletResponse resp) {
// 开启Tomcat异步Servlet支持
req.setAttribute("org.apache.catalina.ASYNC_SUPPORTED", true);
// 启动异步处理的上下文
final AsyncContext ctx = req.startAsync();
// ctx.setTimeout(30000);
ctx.start(() -> {
// 在此处添加异步处理的代码
ctx.complete();
});
}
}
8、如何在Java的Web项目中实现文件上传和下载?
答:框架是基于spring+myBatis的。参考—https://www.cnblogs.com/xiaziteng/p/5695158.html
- 前台页面的部分代码:html
- 前台页面的部分代码:css
- 上传功能的方法:upload()
- 下载功能的方法:download()
9、服务器收到用户提交的表单数据,到底是调用Servlet的doGet()还是doPost()方法?
答:HTML的元素有一个method属性,用来指定提交表单的方式,其值可以是get或post。
定义: 我们自定义的Servlet一般情况下会重写doGet()或doPost()两个方法之一或全部,如果是GET请求就调用doGet()方法,如果是POST请求就调用doPost()方法。
- 那为什么这样呢?
- 我们自定义的Servlet通常继承自HttpServlet,HttpServlet继承自GenericServlet并重写了其中的service()方法,该方法是Servlet接口中定义的。HttpServlet重写的service()方法会先获取用户请求的方法,然后根据请求方法调用doGet()、doPost()、doPut()、doDelete()等方法,如果在自定义Servlet中重写了这些方法,那么显然会调用重写过的(自定义的)方法,这显然是对模板方法模式的应用。当然,自定义Servlet中也可以直接重写service()方法,那么不管是哪种方式的请求,都可以通过自己的代码进行处理,这对于不区分请求方法的场景比较合适。
10、Servlet中如何获取用户提交的查询参数或表单数据?
答:
- 可以通过请求对象的getParameterValues()方法获得。
- 可以通过请求对象的getParameterMap()获得一个参数名和参数值的映射(Map)。
- 可以通过请求对象(HttpServletRequest)的getParameter()方法通过参数名获得参数值。如果有包含多个值的参数(例如复选框)
11、Servlet中如何获取用户配置的初始化参数以及服务器上下文参数?
答:
-
可以通过重写Servlet接口的init(ServletConfig)方法,并通过ServletConfig对象的getInitParameter()方法来获取Servlet的初始化参数。
-
可以通过ServletConfig对象的getServletContext()方法获取ServletContext对象,并通过该对象的getInitParameter()方法来获取服务器上下文参数。ServletContext对象也可以在处理用户请求的方法(如doGet()方法)中通过请求对象的getServletContext()方法来获得。
12、讲一下redis的主从复制怎么做的?
答:通过持久化功能,Redis保证了即使在服务器宕机情况下数据的丢失非常少。
- 如果某台服务器出现了硬盘故障、系统崩溃等等,不仅仅是数据丢失,很可能对业务造成灾难性打击。为了避免单点故障通常的做法是将数据复制多个副本保存在不同的服务器上,这样即使有其中一台服务器出现故障,其他服务器依然可以继续提供服务。当然Redis提供了多种高可用方案包括:主从复制、哨兵模式的主从复制、以及集群。
主从复制:
在主从复制中,数据库分为两类,一类是主库(master),另一类是同步主库数据的从库(slave)。
主库可以进行读写操作,当写操作导致数据变化时会自动同步到从库。而从库一般是只读的(特定情况也可以写,通过参数slave-read- only指定),并接受来自主库的数据,一个主库可拥有多个从库,而一个从库只能有一个主库。
这样就使得redis的主从架构有了两种模式:一类是一主多从,二类是“链式主从复制”–主->从->主-从。
13、redis为什么读写速率快性能好?
答:
1)Redis将数据存储在内存上,避免了频繁的IO操作。
2)Redis其本身采用字典的数据结构,时间复杂度为O(1),且其采用渐进式的扩容手段。
3)Redis是单线程的,避免了上下文切换带来的消耗,采用网络IO多路复用技术来保证在多连接的时候, 系统的高吞吐量。
14、redis为什么是单线程?
答:因为Redis是基于内存的操作,CPU不是Redis的瓶颈,Redis的瓶颈最有可能是机器内存的大小或者网络带宽。
既然单线程容易实现,而且CPU不会成为瓶颈,那就顺理成章地采用单线程的方案了(毕竟采用多线程会有很多麻烦!,避免使用锁)。
正是由于在单线程模式的情况下已经很快了,就没有必要在使用多线程了!但是,我们使用单线程的方式是无法发挥多核CPU 性能,不过我们可以通过在单机开多个Redis 实例来完善!
- 警告: 这里我们一直在强调的单线程,只是在处理我们的网络请求的时候只有一个线程来处理,一个正式的Redis Server运行的时候肯定是不止一个线程的,这里需要大家明确的注意一下!
15、缓存的优点?
答:原理:先查询缓存中有没有要的数据,如果有,就直接返回缓存中的数据。
如果缓存中没有要的数据,才去查询数据库,将得到数据先存放到缓存中,然后再返回给php。
- 优点:
1、 加快了响应速度
2、 减少了对数据库的读操作,数据库的压力降低 - 缺点:
1、 内存的成本高
2、 内存容量相对硬盘小
3、 缓存中的数据可能与数据库中数据不一致
4、 因为内存断电就清空数据,存放到内存中的数据可能丢失
16、aof,rdb,优点,区别?
答:Redis是一个支持持久化的内存数据库,可以将内存中的数据同步到磁盘保证持久化。
- 定义: Redis是一种高级key-value数据库。数据可以持久化,支持的数据类型很丰富,有字符串,链表,集 合和有序集合。支持在服务器端计算集合的并,交和补集(difference)等,还支持多种排序功能。所以Redis也可以被看成是一个数据结构服务器。Redis为了保证效率,数据缓存在内存中,Redis 会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,以保证数据的持久化。
- Redis的持久化策略:2种
1)AOF: 把所有的对Redis的服务器进行修改的命令都存到一个文件里,命令的集合。
2)RDB: 快照形式是直接把内存中的数据保存到一个 dump文件中,定时保存,保存策略。
3)Redis默认是快照RDB的持久化方式当 Redis 重启时,它会优先使用 AOF 文件来还原数据集,因为 AOF 文件保存的数据集通常比 RDB 文件所保存的数据集更完整。你甚至可以关闭持久化功能,让数据只在服务器运行时存。 - 区别:
1)RDB持久化是指在指定的时间间隔内将内存中的数据集快照写入磁盘,实际操作过程是fork一个子进程,先将数据集写入临时文件,写入成功后,再替换之前的文件,用二进制压缩存储。
2)AOF持久化以日志的形式记录服务器所处理的每一个写、删除操作,查询操作不会记录,以文本的方式记录,文件查看操作记录。 - 选择:
1) 如果你非常关心你的数据,但仍然可以承受数分钟以内的数据丢失, 那么你可以只使用 RDB 持久。AOF 将 Redis 执行的每一条命令追加到磁盘中,处理巨大的写入会降低 Redis 的性能,不知道你是否可以接受。
2) 数据库备份和灾难恢复:定时生成 RDB 快照(snapshot)非常便于进行数据库备份, 并且 RDB 恢复数据集的速度也要比 AOF 恢复的速度要快。Redis 支持同时开启 RDB 和 AOF,系统重启后,Redis 会优先使用 AOF 来恢复数据,这样丢失的数据会最少。
17、redis的List能用做什么场景?
答:Redis得list应用场景非常多,是Redis最重要的数据结构之一,如twitter的关注列表,粉丝列表等都可以用Redis的list结构来实现。
- List 就是链表,使用List结构,我们可以轻松地实现最新消息排行等功能。
- Redis还提供了操作List中某一段的api,你可以直接查询,删除List中某一段的元素。
- List的另一个应用就是消息队列,可以利用List的PUSH操作,将任务存在List中,然后工作线程再用POP操作将任务取出进行执行。
18、说说MVC的各个部分都有那些技术来实现?如何实现?
答:M(DAO)层,就相当于后台;V(jsp),相当于前台;C(control)层,相当于控制页面跳转;MVC模式的目的是实现Web系统的职能分工。
- 技术:
1)M: hibernate/mybatis/ibatis
2)C: severlet/struts/spring action
3)V: jsp/FreeMarker/tails/taglib/EL/Velocity - 实现:
1)Model层实现系统中的业务逻辑,通常可以用JavaBean或EJB来实现。
2)View层用于与用户的交互,通常用JSP来实现。
3)Controller层是Model与View之间沟通的桥梁,它可以分派用户的请求并选择恰当的视图以用于显示,同时它也可以解释用户的输入并将它们映射为模型层可执行的操作。
19、什么是DAO(Data Access Object)模式?
答:DAO是为数据库或其他持久化机制提供了抽象接口的对象,在不暴露底层持久化方案实现细节的前提下提供了各种数据访问操作。
- 在实际的开发中,应该将所有对数据源的访问操作进行抽象化后封装在一个公共API中。用程序设计语言来说,就是建立一个接口,接口中定义了此应用程序中将会用到的所有事务方法。在这个应用程序中,当需要和数据源进行交互的时候则使用这个接口,并且编写一个单独的类来实现这个接口,在逻辑上该类对应一个特定的数据存储。
- DAO模式实际上包含了两个模式:
- 一是Data Accessor(数据访问器)
- 二是Data Object(数据对象)
- 前者要解决如何访问数据的问题,而后者要解决的是如何用对象封装数据。
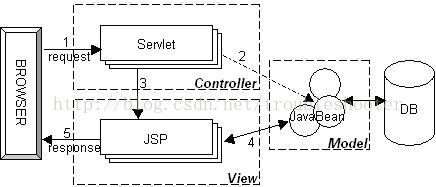
20、请问Java Web开发的Model 1和Model 2分别指的是什么?
答:
1)Model 1是以页面为中心的Java Web开发,使用JSP+JavaBean技术将页面显示逻辑和业务逻辑处理分开,JSP实现页面显示,JavaBean对象用来保存数据和实现业务逻辑。
2)Model 2是基于MVC(模型-视图-控制器,Model-View-Controller)架构模式的开发模型,实现了模型和视图的彻底分离,利于团队开发和代码复用,如下图所示。
21、你的项目中使用过哪些JSTL标签?
答:
- 项目中主要使用了JSTL的核心标签库,包括<c:if>、<c:choose>、<c:when>、<c:otherwise>、<c:forEach>等,主要用于构造循环和分支结构以控制显示逻辑。
- 说明: 虽然JSTL标签库提供了core、sql、fmt、xml等标签库,但是实际开发中建议只使用核心标签库(core),而且最好只使用分支和循环标签并辅以表达式语言(EL),这样才能真正做到数据显示和业务逻辑的分离,这才是最佳实践。
22、使用标签库有什么好处?如何自定义JSP标签?(JSP标签)
答:
1)使用标签库的好处包括以下几个方面:
- 分离JSP页面的内容和逻辑,简化了Web开发;
- 开发者可以创建自定义标签来封装业务逻辑和显示逻辑;
- 标签具有很好的可移植性、可维护性和可重用性;
- 避免了对Scriptlet(小脚本)的使用(很多公司的项目开发都不允许在JSP中书写小脚本)
2)自定义JSP标签包括以下几个步骤:
- 编写一个Java类实现实现Tag/BodyTag/IterationTag接口(开发中通常不直接实现这些接口而是继承TagSupport/BodyTagSupport/
SimpleTagSupport类,这是对缺省适配模式的应用),重写doStartTag()、doEndTag()等方法,定义标签要完成的功能; - 编写扩展名为tld的标签描述文件对自定义标签进行部署,tld文件通常放在WEB-INF文件夹下或其子目录中;
- 在JSP页面中使用taglib指令引用该标签库;














 1493
1493











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









