







建立新python文档的时候遇到了问题,点击run之后弹出python console,并没有运行程序,个人不是很习惯这种模式,所以切换成了run界面,调整方法如下:
run-edit configurations-executions-取消勾选run with python console即可解决
本章介绍的是逻辑回归问题,主要用于数据的分类
首先介绍分类需要用到的Sigmoid函数:
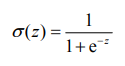
主要利用他的阶跃特性:在x=0时是0.5,x<0时函数值趋于0,x>0时函数值趋于1,以此用于分类,函数值是0和1分为两类
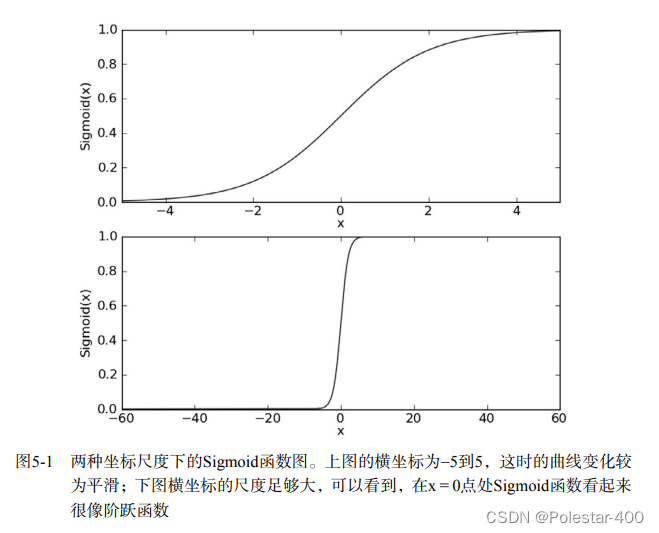
上图截取自课本,可以看出函数在0附近很小的邻域升降不是很陡,但是后面分类函数基本是以0为基准的,所以也无所谓。如果想要更好的结果可以考虑单位阶跃函数等函数,较为简单,这里不做过多介绍。
上面介绍的是分类函数,下面介绍回归系数的选取
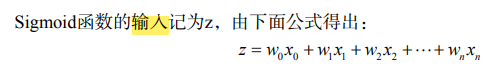
我们想要求的就是这些w0,w1…;x0,x1…是分类器的输入数据
回归系数的选取需要利用梯度上升算法,其基本数学原理较为简单,不作介绍,迭代公式如下
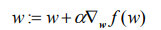
梯度上升算法的伪代码如下
初始化回归系数均为1
for i=1 to R
计算数据集的梯度
使用alpha*梯度更新回归系数
返回回归系数下面是梯度上升算法的代码
def loadDataSet():#得到了数据矩阵和标签矩阵
dataMat = [];labelMat = []
fr = open(r'C:\Users\lenovo\Desktop\ML实战代码\ch05\testSet.txt')#这里相对路径一直找不到文件,改用绝对路径
for line in fr.readlines():
lineArr = line.strip().split()#strip()去除首尾空格,split拆分字符串,默认为空格拆分
dataMat.append([1.0,float(lineArr[0]),float(lineArr[1])])#这里的1.0是x0
labelMat.append(int(lineArr[2]))
return dataMat,labelMat
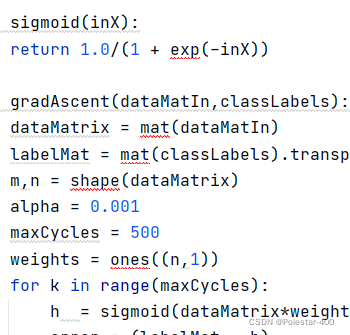
def sigmoid(inX):#实现的是sigmoid函数
return 1.0/(1 + exp(-inX))
def gradAscent(dataMatIn,classLabels):#实现的是梯度上升算法
dataMatrix = mat(dataMatIn)#把list数据类型变成矩阵
labelMat = mat(classLabels).transpose()#transpose是矩阵转置
m,n = shape(dataMatrix)#行、列
alpha = 0.001
maxCycles = 500#迭代次数
weights = ones((n,1))
for k in range(maxCycles):
h = sigmoid(dataMatrix*weights)#维度100*3 * 3*1,相当于给每一维都做了sigmoid,这里是预测值,Sigmoid(数据矩阵x权重),是0/1给聚类
#dataMatrix是样本矩阵,每一行代表着一个数据
error = (labelMat - h)#梯度上升方向,聚类和真实值的误差
weights = weights + alpha * dataMatrix.transpose() * error#维度3*100 * 100*1,权重更新的方向
return weights
#测试代码
# dataArr,labelMat = loadDataSet()
# weights = gradAscent(dataArr,labelMat)
# print(test)
#控制台输出
#[[ 4.12414349]
# [ 0.48007329]
# [-0.6168482 ]]该算法中权重更新的主要方式为,每一次迭代时计算预测值和标签值的差,并将差值作为下一次更新权重的方向,以此迭代数次,由于算法的特性,该结果必然是全局收敛的。
BTW,建立程序的时候有几个地方一直显示红线:
将import numpy 改成 form numpy import *之后可以跑通
求得决策系数后,要做的就是画图:1.画出样本点 2.画出决策界
def plotBestFit(wei):
import matplotlib.pyplot as plt
weights = wei#getA()是将numpy矩阵转化成数组形式,这里删去了
dataMat, labelMat = loadDataSet()
dataArr = array(dataMat)#转成array类型
n = shape(dataArr)[0]#shape是维度,[0]代表维度的第一个值
xcord1 = [];ycord1 = []
xcord2 = [];ycord2 = []
for i in range(n):#根据标签0/1把数据分到两个矩阵数组中
if int(labelMat[i])==1:
xcord1.append(dataArr[i,1]);ycord1.append(dataArr[i,2])
else:
xcord2.append(dataArr[i,1]);ycord2.append(dataArr[i,2])
fig = plt.figure()
ax = fig.add_subplot(111)#三个参数:总行数、总列数、图的位置
ax.scatter(xcord1,ycord1,s=30,c='red',marker='s')
ax.scatter(xcord2,ycord2,s=30,c='green')
#plt.scatter(x, y, c="b", label="scatter figure") x: x轴上的数值 y: y轴上的数值 c:散点图中的标记的颜色label:标记图形内容的标签文本
x = arange(-3.0,3.0,0.1)#生成一维数组,从-3到3步长0.1
y = (-weights[0]-weights[1]*x)/weights[2]#weights的三个分量分别是三个参数,数值意义还没搞懂
# 0 = w0 + w1x1 + w2y -> y = (-w0 -w1x1)/w2 z = 0时,sigmoid函数取中间值,也就是0.5
#分界线是0=w0x0 + w1x1 + w2x2,这里要画关于x1和x2的分界线所以这一步是求在x1不断变化时x2的值
ax.plot(x,y)
plt.xlabel('X1');plt.ylabel('X2');
plt.show()
#测试代码
# dataArr,labelMat = loadDataSet()
# weights = gradAscent(dataArr,labelMat)
# plotBestFit(weights)#加上getA直接跑不通,查资料后发现删去可以跑通这个函数按顺序做了以下几件事情 1.加载数据 2.根据标签将数据分类存储 3.画图 4.画直线
这里需要重点强调的是决策界的数学含义,即为什么x和y的关系式是那个样子:
由于所有样本点都画出来了,决策界的定义是 0=w0x0+w1x1+w2x2,现在画的图是横轴x1纵轴x2,找决策界函数也要化成x1和x2的函数关系的形式,又因为x0=1,经过简单变换后可以得到该式:y = (-weights[0]-weights[1]*x)/weights[2]
介绍完画图方法后,下面介绍对梯度上升算法的改进:随机梯度上升算法
由于上文提到的梯度上升算法在加入新数据时需要重新进行迭代很麻烦,现采用对数据逐个处理的迭代方案,这样当数据训练完成后,加入新数据时,可以在最后一次迭代的基础上延续,以此来更新权重系数,减小了不必要的计算量。伪代码、实现代码如下
所有回归系数初始化为1
对数据集中每个样本
计算该样本的梯度
使用alpha × gradient更新回归系数值
返回回归系数值def stocGradAscent0(dataMatrix,classLabels):#随机梯度上升算法,来一个更新一次权重系数
m,n = shape(dataMatrix)
alpha = 0.01
weights =ones(n)
for i in range(m):
h = sigmoid(sum(dataMatrix[i]*weights))
error = classLabels[i] - h
weights = weights + alpha * error * dataMatrix[i]
return weights
#测试代码
# dataArr,labelMat = loadDataSet()
# weights = stocGradAscent0(array(dataArr),labelMat)
# plotBestFit(weights)#这里需要把48行的getA()删去这里进行的总共是一次迭代,和之前500次迭代的效果没法比,可以再写一个循环,让其迭代次数变多,从而分类效果更好如下图所示。值得注意的是,虽然随着迭代次数的增加,权重值趋于收敛,但却不是稳定的,书中给出的解释是可能有一些点不是线性可分的,每次迭代的时候都会让权重系数波动。
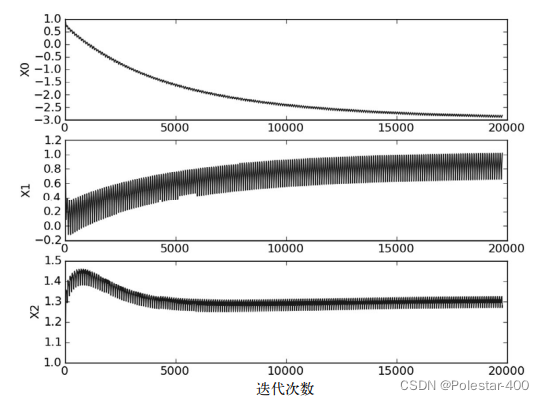
为了对权重波动进行改进,提出了如下的随机梯度上升算法改进版
def stocGradAscent1(dataMatrix,classLabels,numIter=150):#随机梯度上升算法,来一个更新一次权重系数
m,n = shape(dataMatrix)
weights =ones(n)
for j in range(numIter):#相当于把上面的过程重复了150次
dataIndex = list(range(m))
for i in range(m):
alpha = 4/(1.0+j+i)+0.01
randIndex = int(random.uniform(0,len(dataIndex)))#随机生成一个数字
h = sigmoid(sum(dataMatrix[randIndex]*weights))
error = classLabels[randIndex] - h
weights = weights + alpha * error * dataMatrix[randIndex]
#随机选取样本更新回归系数
del(dataIndex[randIndex])
return weights
#测试代码
# dataArr,labelMat = loadDataSet()
# weights = stocGradAscent1(array(dataArr),labelMat)
# plotBestFit(weights)#这里需要把48行的getA()删去
#控制台输出:'range' object doesn't support item deletion
# py3.x range返回的是range对象,不返回数组对象,在94行改成dataIndex = list(range(m))即可可以看出该算法改进的地方主要在于 1.每次的数据点是随机选取的 2.设置系数lamda来控制后输入的数据对整体模型的影响值变小,以此来减小波动。3.设置了迭代次数150
下面介绍逻辑回归的应用:预测死亡率
数据集存在一个问题:有30%的数据是缺失的,而分类算法输入项不能包含缺失的值,文章用0来填补缺失值,这样在迭代到这个值的时候,权重系数不更新(dataMatrix为0),也算是权宜之计。另外由于sigmoid(0)= 0.5所以这样做不会对预测产生不必要的误差。

如果类别标签缺失,那么这一组数据肯定没办法用了,直接舍弃。
下面是回归分类函数
def classifyVector(inX,weights):#简单的分类函数,判断是哪一类
prob = sigmoid(sum(inX*weights))
if prob > 0.5: return 1.0
else: return 0.0
def colicTest():
frTrain = open(r'C:\Users\lenovo\Desktop\ML实战代码\ch05\horseColicTraining.txt')
frTest = open(r'C:\Users\lenovo\Desktop\ML实战代码\ch05\horseColicTest.txt')
trainingSet = []; trainingLabels = []
for line in frTrain.readlines():#一行一行读取数据,读取到的一行内容放到一个字符串变量中
currLine = line.strip().split('\t')#先strip()去除首尾空格,再split拆分字符串,默认为空格拆分
# test = line.strip()
# currLine = test.split('\t')
lineArr = []
for i in range(21):
lineArr.append(float(currLine[i]))#把刚才的字符串一项一项放到list里面
trainingSet.append(lineArr)#append是把里面的参数当成一个元素放到list中去
trainingLabels.append(float(currLine[21]))#currline最后一列是标签
# 下面是测试精确度的代码
trainingWeights = stocGradAscent1(array(trainingSet),trainingLabels,500)
errorCount = 0;numTestVec = 0.0
for line in frTest.readlines():
numTestVec += 1.0
currLine = line.strip().split('\t')
lineArr = []
for i in range(21):
lineArr.append(float(currLine[i]))
if int(classifyVector(array(lineArr),trainingWeights)) != int(currLine[21]):
errorCount += 1
errorRate = (float(errorCount)/numTestVec)
print('the error rate of the this test is:%f'%errorRate)
return errorRate
def multiTest():
numTests = 10;errorSum=0.0
for k in range(numTests):
errorSum += colicTest()
print('after %d iteractions the average error rate is:%f' %(numTests,errorSum/float(numTests)))对数据的处理过程如下:1.读取训练集(按行读取,每一行都是数字+制表符分隔的形式) 2.将刚刚按行读取的数据放入列表中(这里用了列表的嵌套,外层以文件中每行为单位,内层以文件中每行的每个元素为单位) 3.计算权重系数 4.读取测试集 5.调用测试函数,计算误差
最后的multiTest函数实际相当于重复测试,重复了十遍。
最后误差还是蛮大的,平均到了33%左右,但是这是是数据有30%缺失的情况下进行的,而且文章说调整迭代次数和改进梯度下降法的步长,会有提升。
步长就不调整了,不想做调参工程师,这里尝试调整迭代次数算一下:
次数为1000时:
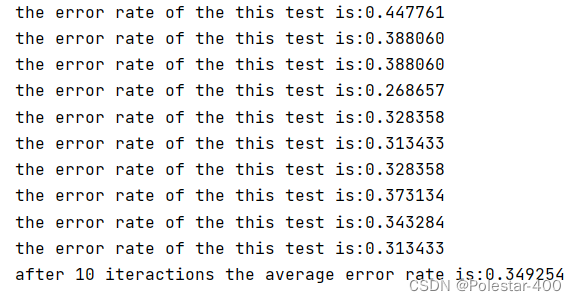
笑死,误差更大了,虽然有26%证明了误差下界降低了
次数为2000时:
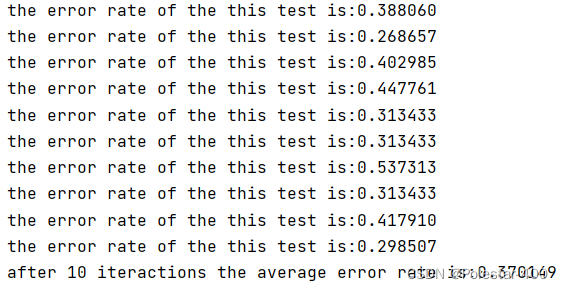
3000:
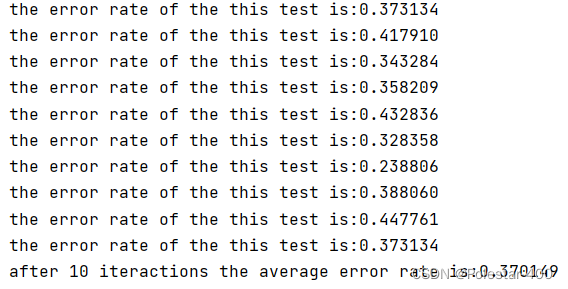
250:
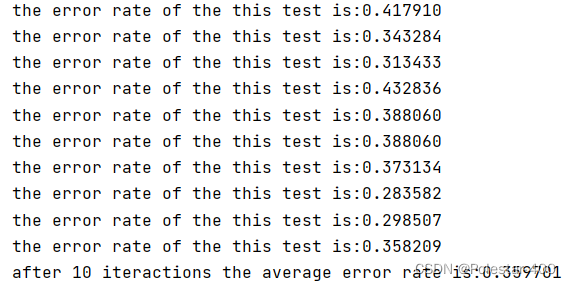
这波啊,属于是调参侠了。无解。
有一种猜测可能是在改进的梯度上升算法里面出了问题,由于py2和py3的版本问题,原文中的
dataIndex = range(m)需要改成dataIndex = list(range(m))才能运行,这就导致后面del之后的数据并不能正确反应在函数的活动数据集中,相当于每一次del之后,都只是将最后一个数据删掉了,而没有删掉对应刚刚用过的数据,暂时还没想到对应的解决办法。或许可以尝试新的数据类型来删除,回头在研究一下。
本章结束。
参考资料:理解逻辑回归的原理


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









