







一、Java代码运行原理
-
.java编译变成.class文件。
-
类加载器把.class字节码文件加载到JVM中。
-
JVM中的字节码执行引擎从指定的
main()方法开始执行代码。
二、类被加载的时机
代码中使用到这个类的时候就会被加载。包含main()方法入口的主类,一定会在JVM进程启动之后就加载,而其他的类会在执行时用到了再加载。
三、JVM中的两大对象
-
字节码对象:类被加载到内存的时候生成,只有一个,存储类结构信息,放在元数据区,可以被回收,通过
User.class、Class.forName("com.xxx.User")、user.getClass()方式获取。 -
实例对象:是乐观事物在内存中的呈现,可以有多个,一般放在堆中,可以被回收,通过new、反射方式获取。
类实例对象引用Class对象,Class对象双向引用类加载器。系统类加载器引用的class对象在整个JVM生命周期中都不会被回收。
Class对象什么时候被回收?
首先该类在堆中的所有实例对象被回收,其次该类的ClassLoader被回收,最后该类的Class对象没有任何引用就会被回收。
四、类的使用过程
-
加载:把磁盘的.class文件加载到内存。
-
验证:校验是否符合JVM规范。
-
准备:给类和类变量分配内存空间,并给类变量赋默认初始值,就是说在方法区/元数据区中创建Class对象。 -
解析:把符号引用替换成直接引用。
-
初始化:执行类变量的赋值逻辑,来替换掉之前的初始默认值,另外也会执行static静态代码块。 -
使用:通过new、反射等方式实例化后使用。 -
卸载:没有被引用后就会被GC回收,到一次使用到时会再次被加载。
若有父类则会先加载父类,再加载子类。
五、类的创建过程
-
加载父类,为父类类变量分配内存并赋初始值。
-
加载子类,为子类类变量分配内存并赋初始值。
-
执行父类类变量的赋值运算,以及静态代码块(哪个在前哪个先执行)。
-
执行子类类变量的赋值运算,以及静态代码块(哪个在前哪个先执行)。
-
新建父类实例,为父类实例变量分配内存并赋初始值。
-
新建子类实例,为子类实例变量分配内存并赋初始值。
-
执行父类的实例变量赋值运算。
-
执行父类的构造方法。
-
执行子类的实例变量赋值运算。
-
执行子类的构造方法。
六、类加载器
-
启动类加载器:加载JDK安装目录
lib下的核心类。 -
扩展类加载器:加载JDK安装目录
lib/ext下的类。 -
应用程序类加载器:加载
classpath目录下的类,也就是你写的应用程序。 -
自定义类加载器:根据需要自定义加载指定的类。
七、双亲委派加载机制
-
子类加载器询问父类加载器能否加载?
-
父类加载器询问父父类加载器能否加载?直至顶级类加载器。
-
顶级类加载器发现在自己的加载范围内没有该类,则让父类加载器去加载。
-
父类加载器发现在自己的加载范围也没有找到该类,也继续让子类加载器去加载。
-
这时子类加载器发现自己加载范围内有该类则加载。
这样设计的目的是防止重复加载。
八、JVM构造图
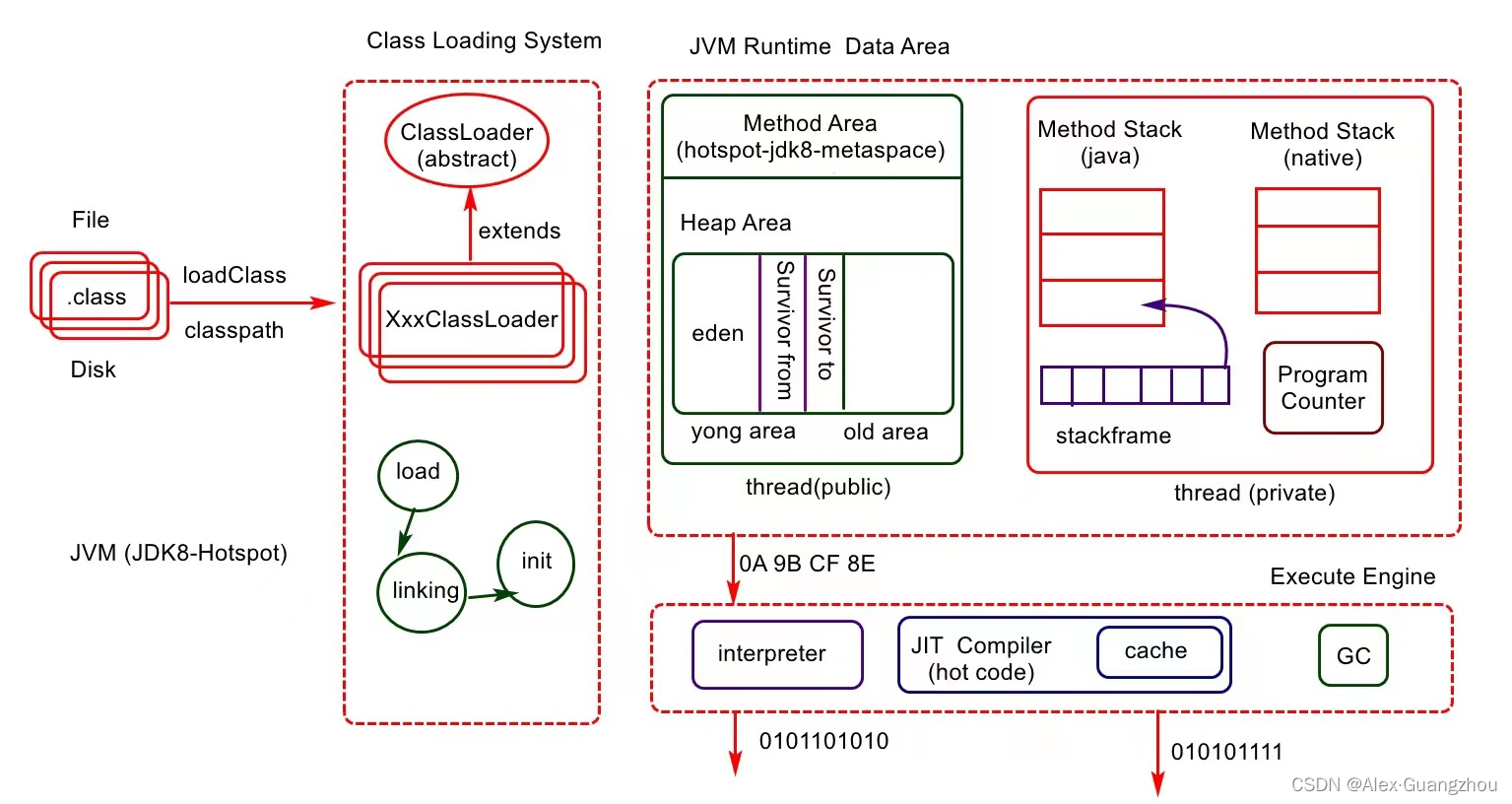
九、线程公有区
-
方法区:也叫永久代,存在于jdk1.8以前的版本,1.8及以后版本用「元数据区」代替,是物理内存中的一块空间。用来存放类结构信息(Class对象)、类变量、常量池等。
-
堆区:用来存放实例对象,包括类变量、实例变量、局部变量引用的对象。分为
年轻代、老年代。年轻代又分为一个Eden区和两个Survivor区。一般一开始创建的对象实例,都会被放在年轻代,经过了15次Minor GC后,依然存在的长期引用对象就会被移到老年代。直至老年代也满了就会发生Full GC。
一些非常大的对象可能会直接分配在老年代。
十、线程私有区
-
Java方法栈:每个线程都有一个方法栈,每个方法会有一个栈帧,里面包含局部变量。方法开始执行,栈帧压入方法栈,执行结束,栈帧弹出方法栈。
-
本地方法栈:Java会通过
native修饰的本地方法,调用操作系统的C/C++类库。这些方法也有一个线程私有的方法栈,作用和Java方法栈一样。 -
程序计数器:每个线程都有一个程序计数器,用来记录字节码执行的位置。
栈就好比如一个桶,压栈和弹栈遵循「先进后出」的顺序。
十一、垃圾回收的区域
-
堆区、方法区(元数据区)都可能会发生GC。堆区回收的实例对象,方法区回收的是Class对象。
-
方法栈不会发生GC,栈帧出栈后即会被销毁,局部变量就不存在了,堆中的对象就会失去引用,垃圾回收线程就会回收堆中没有被引用的对象。
十二、JVM内存核心参数
-
-Xms:堆内存大小
-
-Xmx:堆内存最大大小
-
-Xmn:堆内存中新生代大小,扣除新生代剩下的就是老年代的内存大小
-
-XX:PermSize:永久代(方法区)大小
-
-XX:MaxPermSize:永久代最大大小
-
-Xss:每个线程的栈内存大小
-
-XX:MetaspaceSize:元数据区(1.8版本后,替代了方法区)大小
-
-XX:MaxMetaspaceSize:元数据区最大大小
设置JVM参数方法:
java -Xms512M -Xmx512M -Xmn256M -Xss1M -XX:PermSize=128M -XX:MaxPermSize=128M -jar xxx.jar
十三、JVM调优内容
优化内存分配,降低垃圾回收,特别是Full GC的频率,减少垃圾回收的时间,降低垃圾回收对系统运行的影响。
思路:
-
让
@Service等标注的常驻对象尽快进入老年代,以免留在年轻代占用空间。 -
避免让只使用一两次的短期对象(如
订单对象)进去老年代,从而频繁发生Full GC。
十四、估算JVM内存压力
以支付系统为例,在部署了多个节点情况下,估算评论每个节点的压力:
-
估算高峰期每秒钟处理多少个请求,如30个。
-
估算每个请求处理耗时多久,如1秒,那么1秒之后这个请求产生的对象都是没有被引用,是可以被回收的对象。
-
估算每个请求产生的对象占用多大的内存空间,如支付订单对象,按20个实例变量,Integer类型4个字节,Long类型8字节计算,一个订单对象顶多500字节。
-
那么30个订单就是:30×500字节=15000字节,大概就是15kb。
-
考虑到系统还会创建其他对象,放大10~20倍,也就是每秒钟产生的对象大小在几百kb~1MB之间。
-
那就按照1MB估算,也就是每秒钟大概创建1MB的对象放在年轻代里,1秒钟之后成为垃圾对象,等待回收。
-
结合系统设置的年轻代的大小,就可以估算出大概多久就会占满,发生GC。
十五、JVM常见的设置数值范围
-
机器采用4核8G
-
堆内存3G,年轻代2G
-
方法区(永久代)/元数据区,几百MB,如256M
-
线程栈内存一般保留默认,如512KB到1MB
十六、年轻代的构成
-
一个Eden区(伊甸园区)
-
两个Survivor(幸存区)
-
比例默认是8:1:1
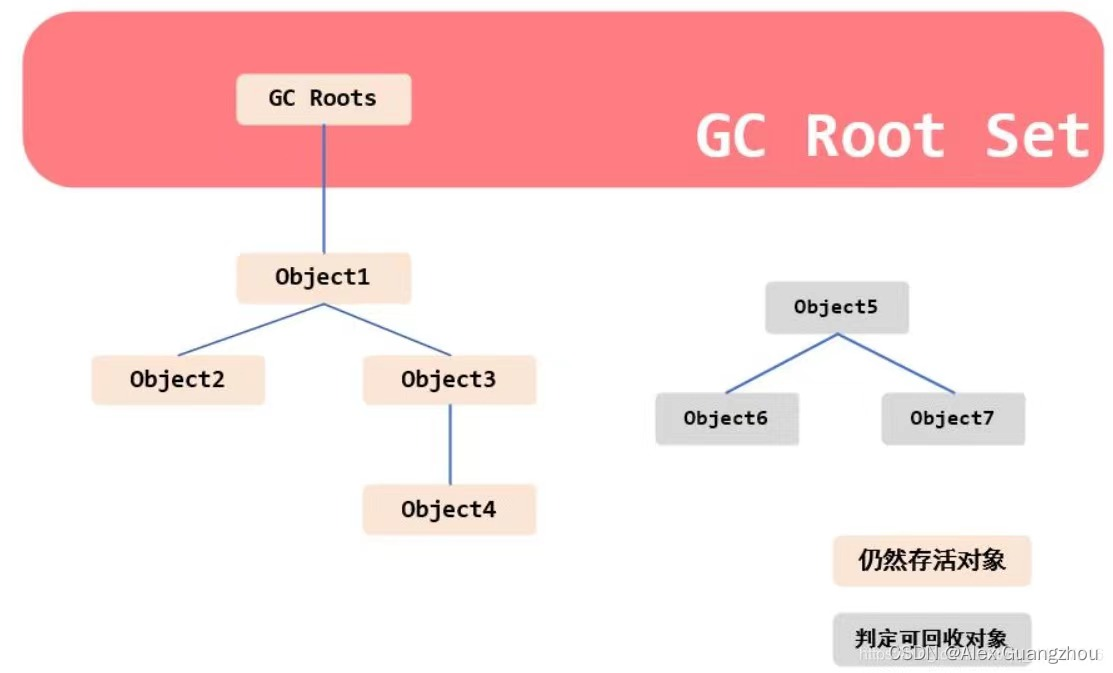
十七、对象是否能被回收
-
可达性分析算法,从
GC Root开始,向下搜索,如果一个对象到GC Root没有任何引用,没有形成引用链,那么该对象可回收。 -
GC Root(
局部变量,静态类变量,实例变量不是)。
十八、引用类型
-
强引用:平常的写法就是强引用,如
Object obj = new Object(),不会被回收 -
软引用:
SoftReference,内存不足会回收 -
弱引用:
WeakReference,会被回收 -
虚引用:省略
有GC Root不回收,没有GC Root会被回收。
如果我GC Root,但是是软引用或者弱引用,也可能被回收。
十九、垃圾回收算法
-
复制算法:用在年轻代,把幸存对象从E区复制到S区,在清空E区。
-
标记整理算法:用在老年代,标记幸存的对象,并整理移动到一起,清空余下的内存,避免产生过多的内存碎片。
-
标记清除算法:用在老年代,会产生大量内存碎片。
二十、对象何时由年轻代进入老年代?
-
默认15次Minor GC后仍未回收掉的
-
动态年龄判断,年龄1+年龄2+年龄n的对象总大小大于S区大小的一半,那大于等于年龄n的对象都会移到老年代。
-
大对象直接进去老年代,如1M以上
-
Minor GC后存活对象总大小大于S区大小,直接转移到老年代
二十一、何时触发Minor GC?
- Minor GC的触发时常发生,当年轻代的Eden区满了就会触发一次Minor GC
二十二、何时触发Full GC?
-
在执行Minor GC前,会检查老年代剩余空间是否大于年轻代里所有对象总大小。
-
没配置空间担保机制(未开启
HanderPromotionFailure参数),如果不大于,则执行Full GC。 -
配置了空间担保机制,再判断老年代剩余空间是否大于历次Minor GC后进入老年代的平均大小,如果不大于,则执行Full GC。如果大于,则冒险执行Minor GC。
-
上面冒险进行了Minor GC后,如果存活对象大小大于Survivor区,需要转移到老年代,若这时老年代剩余空间不够,就是空间担保失败,则执行Full GC。
-
如果方法区(元数据区)达到了最大的内存阈值,也会触发Full GC。
-
老年代使用率达到了92%的阈值,也会触发Full GC。
在jdk1.6之后废除了-XX:HandlePromotionFailure参数(默认开启空间担保),只要判断“老年代可用空间” > “年轻代对象总和”,或者“老年代可用空间” > “历次Minor GC升入老年代对象的平均大小”,两个条件满足其中一个就可以进行Minor GC,不需要提前触发Full GC。
二十三、垃圾回收器
-
Seril:年轻代,单线程,效率低 -
Serial Old:老年代,单线程,效率低 -
ParNew:年轻代,多CPU并行回收 -
CMS:老年代,多线程并发回收 -
G1:最新的,并行与并发兼备,适合年轻代和老年代分代回收,适合超大内存的机器,适合要求低延迟的业务场景。
二十四、Stop The World
垃圾回收线程进行GC时,会停止所有工作线程。
二十五、如何做到仅仅发生Young GC(Minor GC),几乎没有Full GC?
结合系统的运行,根据内存的占用情况,GC后的对象存活情况,合理分配Eden、Survivor、老年代的内存大小,合理设置一些参数,即可做到。
二十六、ParNew原理(复制算法)
-
新对象优先放在E区。
-
发生第一次Minor GC,存活对象移到S1区,清空E区。
-
新对象继续放在E区。
-
发生第二次Minor GC,把E区和S1区的存活对象移到S2区,清空E区和S1区。
-
新对象又放在E区。
-
发生第三次Minor GC,把E区和S2区的存活对象移到S1区,清空E区和S2区。
-
如此循环往复,每经历过一次Minor GC,对象年龄就累计增加一岁。
ParNew垃圾回收器和Serial垃圾回收器相比,是并行的,默认有多少个核就我多少个线程回收,所以在多核CPU时是占优势的。
二十七、CMS原理(标记清理算法)
标记清理算法,就是从GC Root出发使用可达性分析算法,判断老年代里面的各个对象是否存活。先把垃圾对象都标记出来,然后一次性把垃圾对象都清理掉,最后再整理剩余的存活对象挨着放到一起。分为4个阶段:
-
初始标记:工作线程停止,进入STW,只标记被GC Root直接引用的对象,速度很快。
-
并发标记:工作线程继续运行,对老年代所有对象进行GC Root追踪,速度很慢。
-
重新标记:工作线程停止,进去STW,对第二阶段中被程序系统运行变动过的少数对象进行标记,速度很快。
-
并发清理:工作线程不停止,并发清理掉上面标记出来的垃圾对象,速度很慢。另外这时工作线程运行产生的垃圾对象无法被清理,成为「浮动垃圾」。
-
碎片整理:把回收后存活的大批对象整理到一起,避免产生过多内存碎片。
二十八、为什么Full GC 要比Minor GC慢很多?
-
年轻代里面99%都是垃圾对象,通过GC Root追踪到1%的存活对象很快,复制到S区也很快,整块E区都清除也很快。
-
老年代里面存活对象很多,在并发标记阶段完成GC Root追踪很耗时,另外清理内存中零散的垃圾对象也很慢。清理完后还要把存活对象整理到一块,也很慢。在并发清理的时候,万一有对象一进来,但空间不够放了,这时候就会切换
Serial Old回收器,速度更慢。
二十九、G1原理
-
分为一个个区(
Region),Region由G1动态分配给年轻代、老年代。 -
G1计算每一个Region内可回收的的对象大小和预估时间,在垃圾回收的时候,挑选“最少时间内能回收最多对象”的Region进行回收。
-
关键参数
-XX:MaxGCPauseMills控制系统停顿时间。 -
每个Region大小由G1自动分配,最多2048个,大小是2的倍数,如1M/2M/4M等。如堆大小是4096M,则除以2048,则每个Region是2M。
-
初始时默认新生代占堆内存
5%,随着系统不断运行,G1不断给新生代添加更多的Region,最多不超过60%。 -
新生代垃圾回收后又会有空余出Region,动态地被分配给其他区。
-
新生代也会有E区和两个S区,一样是在
新生代的Eden满的时候触发新生代垃圾回收,也是用「复制算法」,也会停止工作线程,进入STW状态。 -
但这里的Young GC不是回收新生代的所有空间,而是根据设定的最大的停顿时间,
只回收部分性价比最高的Region。 -
新生代对象一样也是在熬过了一定次数的Minor GC后,或者是触发了动态年龄判定规则后,或者是存活对象在Survivor区放不下后,转移到老年代中。
-
但是这里大对象不再进入老年代,而是分配到单独的Region。
-
当老年代对象越来越多,占据堆内存的45%的时候,会触发新生代+老年代的混合垃圾回收,即
Mixed GC。
G1垃圾回收器最大的优势就是可以让用户设置最大系统停顿时间,减少由Stop The World对系统带来的卡顿,它能根据设定的停顿时间去回收部分的Region,不会像ParNew、CMS回收大内存时因为存活对象过多而导致太慢。因此G1特别适合用在要求
低延迟、大堆内存的场景。
三十、G1混合回收过程(Mixed GC)
-
初始标记:停止工作线程,从GC Root开始搜索,标记能直接引用的对象。
-
并发标记:允许工作线程执行,对第一阶段标记的对象进行GC Root追踪,找出所有存活的对象。并且记录对对象的修改,如哪个对象被新建了,哪个对象失去了引用。
-
最终标记:停止工作线程,根据上面并发标记阶段记录的对象修改,最终标记哪些是垃圾对象,哪些是存活对象。
-
混合回收:会停止所有工作线程,先计算回收性价比,也就是计算每个Region中垃圾对象数和执行垃圾回收的预期性能和效率,再根据设定的系统停顿时间,选择性价比最高的部分Region进行回收。(注意:
在混合回收时,无论是新生代还是老年代,都是采用复制算法,即把存活对象拷贝到空余Region,然后在清理要回收的Region,但是这个时候要是没有空余的Region了,就会触发回收失败,这时候就会切换到Serial Old单线程回收器,这效率是非常慢的。)
老年代占用大小达到堆内存45%的时候就会触发Mixed GC,不仅仅回收老年代,还会回收新生代、以及大对象的Region。而且最后的混合回收阶段回执行多次,也就是先停止工作,执行一次混合回收,接着恢复系统运行,然后再次停止工作,执行混合回收,默认是如此反复执行8次。但如果新生代回收空闲出来的Region达到默认的堆内存的5%,就会停止混合回收。
三十一、G1常用参数
-
-XX:+UseG1GC:指定使用G1垃圾回收器
-
-XX:MaxGCPauseMills:每次GC系统最大停顿时间(关键),默认200ms
-
-XX:G1HeapRegionSize:每个Region大小
-
-XX:G1NewSizePercent:初始化时默认新生代对堆内存占比,默认5%
-
-XX:G1MaxNewSizePercent:最多新生代对堆内存的占比,默认60%
-
-XX:SurvivorRatio:新生代E区和两个S区的比例,默认是8,即8:1:1
-
-XX:MaxTenuringThreshold:在新生代能躲过GC的最大年龄,默认是15
-
-XX:InitiatingHeapOccupancyPercent:触发混合回收的老年代对堆内存的占比,默认45%
-
-XX:G1MixedGCCountTarget:混合回收阶段执行几次混合回收,默认8次
-
-XX:G1HeapWastePercent:空余的Region达到对堆内存占比多少会停止混合回收,默认5%
-
-XX:G1MixedGCLiveThresholdPercent:选择Region进行回收的时候,必须存活对象低于多少占比的Region才能回收,默认是85%
三十二、JVM调优思路
jvm优化的主旋律就是,尽量让短命对象在新生代回收掉,长期存活对象早进入老年代,G1的优化思路亦是如此。
-
首先是根据具体业务系统,合理分配老年代和新生代的大小、新生代Eden和Survivor区大小
-
其次是根据具体业务系统,合理设置G1的
MaxGCPauseMills大小。太小容易造成回收频繁,影响系统的吞吐量。太大会增大系统的停顿时间,影响用户体验
JVM内存优化就是,了解自己的系统运行的内存模型,估算合理的单位时间内产生的对象大小,然后分配合理的新生代和老年代内存空间,尽可能让普通的对象在新生代中,不进入老年代。
三十三、传统垃圾回收器和G1垃圾回收器调优的区别
调优思路还是减少耗时的垃圾回收,也就是避免对象进入老年代。
传统的垃圾收集器是通过调整s区和e区的大小来控制,而G1则比较先进,直接指定一个期望的停顿时间。
选择停顿时间的标准是既不能频繁触发minor gc,也不能一次回收过多的对象,所以还得通过工具来调试出一个最适合自己系统的停顿时间。
通过工具检测,要得出一个停顿多久可以回收多少的内存大小的指标。根据这个指标和业务系统生成垃圾的速率设置合理的停顿时间。
三十四、为什么说G1垃圾回收器调整系统停顿时间参数很重要?
-
过小,每次能回收的Region太少,会频繁触发GC。
-
过大,每次能回收的Region太多,存活对象太多,可能新生代gc过后 存活对象太多,导致survivor放不下,进入老年代 或者因为动态年龄进入老年代。
其实Mixed GC就是由于最大系统停顿时间设置得不合理导致的。
三十五、一些名词解释
-
Young GC、Minor GC相同,都是指年轻代的GC
-
Old GC单指老年代的GC
-
Full GC是针对年轻代、老年代、永久代(方法区)的整体的GC
-
Mixed GC是
G1垃圾回收器中针对年轻代、老年代以及大对象的Region执行的整体的混合回收,是G1特有的名词 -
Major GC,有人把它等同于Old GC,有人把它等同于Full GC
三十六、JVM调优常用命令行工具
-
jps | grep cipos-work,查看java进程PID。
-
jstat -gc PID,查看JVM内存使用情况以及GC情况。
-
jmap -heap PID,打印堆内存参数。
-
jmap -histo PID | grep com.suntek,查看内存对象的大小。
-
jmap -dump:live,format=b,file=dump.hprof PID,生成堆内存快照。
-
jhat dump.hprof -port 7000,启动jhat服务器,以图形化方式分析堆内存对象分布方式。
-
jstack,查看线程快照
-
jconsole,可视化监控
-
jvisualvm,可视化监控,可分析堆内存快照
-
常用监控平台,Zabbix,Open-Falcon
-
MAT工具,分析堆内存快照,找到当时当时占用内存最大的对象是谁,有谁在引用它
三十七、明确JVM运行情况
-
新生代对象增长的速率
-
Young GC的触发速率
-
Young GC的耗时
-
每次Young GC后有多少对象存活
-
每次Young GC后有多少对象进入老年代
-
老年代对象增长的速率
-
Full GC的触发频率
-
Full GC的耗时
三十八、JVM终极面试问题
-
你们生产环境的系统的JVM参数怎么设置的?为什么要这么设置?
-
你在生产环境中的JVM优化经验可以聊聊?
-
说说你在生产环境解决过的JVM OOM问题?
三十九、内存泄露
很多对象使用过后仍是存活的,还引用着,没有及时被回收掉,占用的内存得不到释放。
四十、内存溢出(OOM)
-
内存溢出,即内存放不下了就会发生OOM
-
方法区(元数据区)、堆内存、java线程栈内存都可能会发生OOM
四十一、方法区(元数据)OOM原因
方法区(元数据区)主要放的是Class对象自己常量池等,Class对象能被回收的前提是:类加载器被回收、所有的实例被回收。此处发生OOM原因:
-
没有合理设置大小,通常
256M或512M够用 -
用cglib等技术胡乱创建了很多动态代理增强类。
四十二、线程栈内存OOM原因
无论是不是同一个方法每调用一次都会产生一个栈帧压入栈中,方法递归调用时写得不好就会出问题。
线程栈内存通常1M足够
四十三、堆内存OOM原因
新对象优先放在年轻代的Eden区,每次Young GC过后,满足年龄次数、符合动态年龄判断规则、大于Survivor区的对象都会进入到老年代,老年代的大小达到一定阈值就会触发Full GC,回收完后空间仍然不够放就会OOM。
四十四、造成OOM的一些案例
-
告警计算系统,计算造成后推送到kafka让其他系统消费,kafka故障推送失败后数据留在内存中,造成堆内存溢出。
-
系统启动时没有设置元数据的大小,采用系统默认的,导致元数据区内存不够用,设置成125m后正常。
-
使用Cglib的Enhancer类实现动态代理机制的时候,没有把Enhancer对象缓存起来,导致不断创建新的增强子类,从而元数据区内存溢出。
-
采集核心日志推送ES,在推送失败在catch中重复调用推送方法,导致线程栈内存溢出。
-
max-http-header-size表示最大允许请求头大小,默认是8kb,由tomcat线程引用,设置多大就会创建多大的byte数组,请求外部系统timeout设置为4秒,外部系统挂了请求就会阻塞4秒,并发过多导致堆内存溢出,解决方法是timeout设置为1秒,调小max-http-header-size参数。
-
查询数据库不加where条件导致查询数据太多而堆内存溢出。
-
Kafka消费者批量拉取消息放入List中,再list放入队列中去进行也许处理,导致积压大量超大对象,造成Full GC。改成用定长阻塞队列,直接把数据一条条放入队列,不再包装成list,队列放满就停止拉取,等业务逻辑处理完再继续拉取。
















 120
120











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











