






今天在自己的推荐系统的demo完成之后,想去改进一下推荐算法。在改进之前先梳理一下自己目前完成的工作。
出发点
19年年底的时候读了一篇基于应用的论文,在文中,作者通过爬取网络上的旅游攻略,对攻略中所涉及的景点,运用集合理论抽取出景点之间的直接关系与间接关系。在获取去景点之间的关系之后,应用本体理论,构建本体树。在本体树中,子节点与父节点之间具有直接关系,子节点与最近的祖先节点之间具有间接关系。
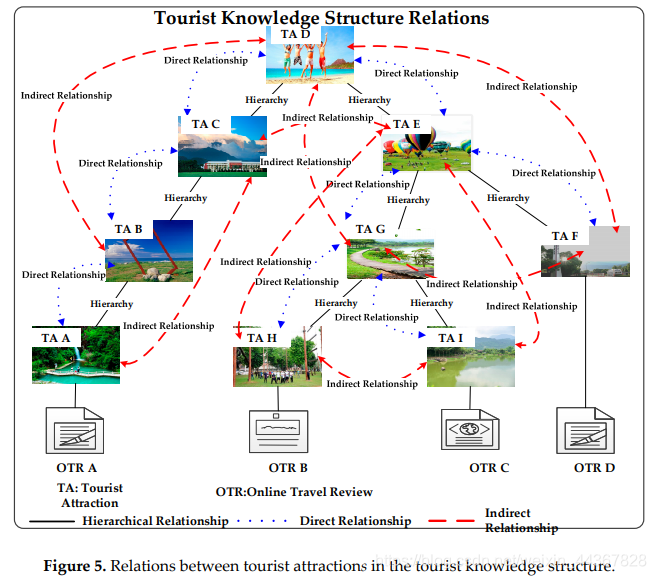
基于以上构建的景点本体树,①当游客位于某一景点A时,可以向其推荐与景点A有直接或间接关系的景点;②当游客选定出发地X和行程结束地Y之后,可以依据本体树规划一条路径,路径上的景点都会与景点X和景点Y有着直接或间接关系。该做法确实会使推荐的精确度有所提高,但忽视了景点之间的距离,也就是说,推荐的“景点路径”在现实中并非一条“完美路径”(或者说最短距离)。
基于以上工作,设计并实施了基于旅游领域本体的推荐系统。系统分为两个模块:①基于当前位置进行景点推荐;②基于起始和终止位置进行行程规划。



梳理
仿照上述论文,想要完成一个相似的推荐系统。
通过网上搜索旅游相关数据集,获取到海南旅游评价数据集。但是从评价数据集中无法抽取景点之间的关系,于是改变思路,收集了海南省的所有4A及以上景点,通过百度查询,分析景点属性,构建了景点本体树。
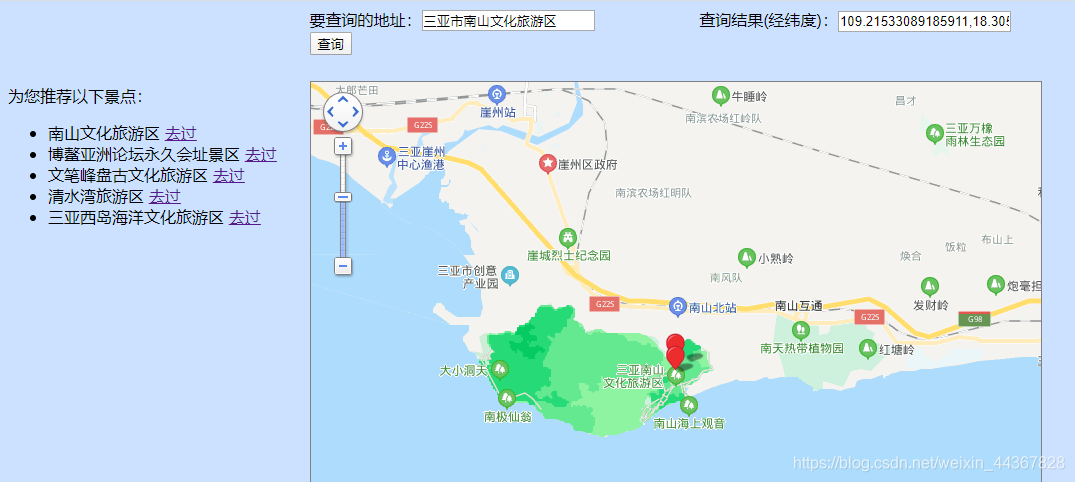
现阶段,在系统的第一个模块—景点推荐中,依据本体相似度计算方法中的Wu and Palmer法,完成了景点推荐。
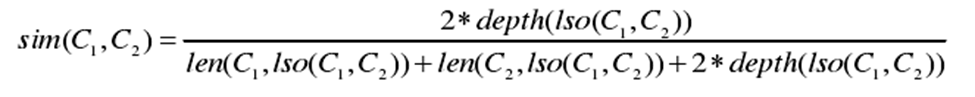
下一步计划
一般推荐系统中,通常包含三个模块:
1.历史数据收集
2.推荐算法
3.产生推荐
最终影响推荐系统好坏的关键因素无疑是推荐算法的选择。
从这三个模块的角度分析本系统:
1.历史数据收集方面,由于系统是基于景点相似度的推荐,无需收集用户大量历史数据。但缺少历史数据的推荐系统必定不是一个好的推荐系统,因此在基于景点相似度的基础上,添加部分用户交互,如“想要去某类型景点”、“驱车最近”、“步行最近”以及在推荐结果后添加“去过”按钮等,帮助用户筛选,在进行简单数据收集的同时帮助用户减轻负担并且其找到满意的推荐结果。
2.推荐算法方面,目前系统的推荐算法是依据相似度计算的计算结果,按照从高到低的顺序产生Top-N结果推荐给用户。所以,推荐算法的改进上,还得依靠相似度算法的改善。**现在有两种方式:**给景点在“类型”属性的基础上,在添加“位置”属性,之后①通过用户交互,让用户选定两个属性的优先级(评分方式),然后依据用户反馈结果动态分配权值,根据所得权值计算景点之间的相似度,继而产生推荐;②给两个属性固定权值,计算相似度产生推荐结果,在推荐结果后面添加“推荐解释”,如“距离最近”、“类型相似”等。
Spot = {
‘type’: , #景点类型
'location': , # 位置
}
3.推荐产生的方式就是对相似度计算的结果进行升序排序,产生Top-N推荐。
总结
这个系统的缺陷和优点都在于历史数据的收集方面。一方面,缺少了历史数据的收集,使得推荐算法无法像协同过滤那样通过k近邻来帮助产生推荐,只能在item的相似度上下功夫。在这种情况下,无疑会使推荐算法过于单一;另一方面,通过用户交互进行的相似度计算会有一种以用户为中心的感觉,并且帮助用户在旅行途中能够更高效地找到心目中理想的景点,从应用的角度出发,这样无疑会更好。
题外
写到这想说句题外话,今天看到一句话“从解决科学问题的角度去考虑发表论文的问题”,而很久之前看到另外一句话“技术的存在是要满足人们的需求的,不是为了进步的而进步的。”而有的时候科学并不适用于满足人们需求,这个时候我们发表的论文又有什么用呢?


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









