







提示:经验不足的小菜鸟,有不足之处希望可以一起纠正讨论学习,函数整理于开发过程中用到过的,文章内容有借鉴有原创,借鉴之处如有侵权请联系删除。
前言
目前刚开始积累oracle函数,没有做分类,遇到一个加一个,后面融会贯通之后再做总结再做分类
1.Trunc:将数字截尾取整
Trunc(17.991,0)=Trunc(17.991)17,
Trunc(17.991,1)=17.9,
Trunc(sysdate,’Year’)=xxxx-1-1,
Trunc(sysdate,’MM’)=xxxx-xx-1,
Trunc(sysdate,’dd’)=Trunc(sysdate)=xxxx-xx-xx:0:00:00,
2.decode:破解转换
decode(条件,值1,返回值1,值2,返回值2,…值n,返回值n,缺省值)
该函数的含义如下:
1 IF 条件=值1 THEN
2 RETURN(翻译值1)
3 ELSIF 条件=值2 THEN
4 RETURN(翻译值2)
5 ELSIF 条件=值n THEN
6 RETURN(翻译值n)
......
ELSE
RETURN(缺省值)
END IF
decode(字段或字段的运算,值1,值2,值3)
这个函数运行的结果是,当字段或字段的运算的值等于值1时,该函数返回值2,否则返回值3
当然值1,值2,值3也可以是表达式,这个函数使得某些sql语句简单了许多
3.sign():函数根据某个值是0、正数还是负数,分别返回0、1、-1
sign(正数)=1,sign(负数)=-1,sign(0)=0,
4.Ipad()函数:
lpad( string, padded_length, [ pad_string ] );
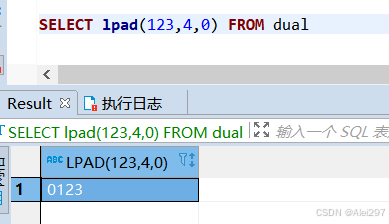
lpad(id,length,value)在id前追加value,总长度为length,总长度小于id长度时函数不生效
SELECT lpad(123,3,0) FROM dual
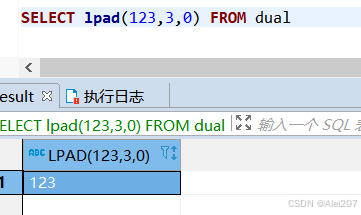
SELECT lpad(123,4,0) FROM dual
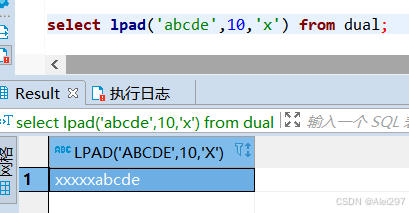
select lpad('abcde',10,'x') from dual
lpad(id,length,value)
第二种用法 去掉value :lpad(id,length) 此时length要小于id的长度才会生效
select lpad('abcde',5) from dual

select lpad('abcde',4) from dual
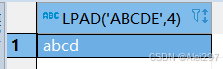
length此时等于4保留id的前四位
5.substr函数:字符截取函数
substr(字符串,截取开始位置,截取长度) //返回截取的字
substr函数在oracle中使用表示被截取的字符串或字符串表达式。和instr()函数不同,instr()函数是要截取的字符串在源字符串中的“位置”,substr()函数是截取字符串的“内容”。
6.to_number()
(1)将char或varchar2类型的string转换为一个number类型的数值,需要注意的是,被转换的字符串必须符合数值类型格式,如果被转换的字符串不符合数值型格式,Oracle将抛出错误提示;
(2)to_number和to_char恰好是两个相反的函数;
select to_number('000012134') from dual;
select to_number('88877') from dual;
(3)如果数字在格式范围内的话,就是正确的,否则就是错误的;如:
select to_number('$12345.678', '$999999.99') from dual;
select to_number('$12345.678', '$999999.999') from dual
(4)可以用来实现进制转换;16进制转换为10进制:
select to_number('19f','xxx') from dual;
select to_number('f','xx') from dual
7.instr()
使用方法一:instr( string1, string2 ) >0 / instr(源字符串, 目标字符串)>0
此用法类似like 如果把大于0改成等于0则相当于 not like
例1.1
SELECT * FROM TABLE T WHERE INSTR(A.COL,'xx')>0
等同于
SELECT * FROM TABLE T WHERE LIKE '%xx%'
使用方法二:instr( string1, string2 ) / instr(源字符串, 目标字符串)字符查找函数
在string1中查找string2返回string1中第一次出现string2的下标
例2.1
select instr('helloworld','l') from dual --返回的结果是3,oracle中下标从1开始

例2.2
select instr('helloworld','lo') from dual --返回的结果是4,lo中取l所在下标

使用方法三:instr( string1, string2 ,start_position,times) instr(源字符串, 目标字符串,开始位子,第几次出现)
| – | h | e | l | l | o | w | o | r | l | d |
|---|---|---|---|---|---|---|---|---|---|---|
| 正序 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 倒序 | -10 | -9 | -8 | -7 | -6 | -5 | -4 | -3 | -2 | -1 |
例3.1
1 select instr('helloworld','l',2,2) from dual;
--返回结果:4 :在"helloworld"的第2(e)号位置开始,查找第二次出现的“l”的位置
2 select instr('helloworld','l',3,2) from dual;
--返回结果:4 :在"helloworld"的第3(l)号位置开始,查找第二次出现的“l”的位置
3 select instr('helloworld','l',4,2) from dual;
--返回结果:9 :在"helloworld"的第4(l)号位置开始,查找第二次出现的“l”的位置
4 select instr('helloworld','l',-1,1) from dual;
--返回结果:9 :在"helloworld"的倒数第1(d)号位置开始,往回查找第一次出现的“l”
5 select instr('helloworld','l',-2,2) from dual;
--返回结果:4 :在"helloworld"的倒数第1(d)号位置开始,往回查找第二次出现的“l”的位置
6 select instr('helloworld','l',2,3) from dual;
--返回结果:9 :在"helloworld"的第2(e)号位置开始,查找第三次出现的“l”的位置
7 select instr('helloworld','l',-2,3) from dual;
--返回结果:3 :在"helloworld"的倒数第2(l)号位置开始,往回查找第三次出现的“l”
8.CASE 流程控制语句 流程控制函数
1.simple CASE(简单形式) 类似DECODE函数
simple case的表达式:
写法一
case expr
when compare1 then value1
when compare2 then value2
when compare3 then value3
else defualtvalue
end alias
decode(expr ,compare1 ,value1,compare2 ,value2,compare3 ,value3,defualtvalue ) alias
--两个语句返回的结果是一样的
每个when单个值匹配, 当expr匹配到compare时返回then后面value,匹配不到值的时候就返回else中的defualtvalue,decode函数也是这个用法
也跟switch case类似语句
最多支持255个参数,其中每对When…Then算作2个参数
2.searched CASE(查询形式)
searched case的表达式:
case
when condition1 then returnvalue1
when condition2 then returnvalue2
when condition3 then returnvalue3
else defualtvalue
end
case
when expr > comparevalue1 then returnvalue1
when expr = comparevalue2 then returnvalue2*x
when expr in (comparevalue3 ,comparevalue4 ) then returnvalue3
else defualtvalue
end
实例
select
fname,
fweight,
(case
when fweight <40 then 'thin'
when fweight > 50 then 'fat'
else 'ok'
end ) as isnormal
from T_person
condition1 是条件表达式与expr>comparevalue1一样
最多支持255个参数,其中每对When…Then算作2个参数
9 MERGE INTO 一个roll out 项目遇到的,自己没有写过,先贴着
转自https://blog.csdn.net/lanxingbudui/article/details/123126895,
merge into table_name alias1 --目标表 可以用别名
using (table|view|sub_query) alias2 --数据源表 可以是表、视图、子查询
on (join condition) --关联条件
when matched then --当关联条件成立时 更新,删除,插入的where部分为可选
--更新
update table_name set col1=colvalue where……
--删除
delete from table_name where col2=colvalue where……
--可以只更新不删除 也可以只删除不更新。
--如果更新和删除同时存在,删除的条件一定要在更新的条件内,否则数据不能删除。
when not matched then --当关联条件不成立时
--插入
insert (col3) values (col3values) where……
when not matched by source then --当源表不存在,目标表存在的数据删除
delete;
语句讲解
1、on后面的关联条件成立时,可以update、delete。
2、on后面的关联条件不成立时,可以insert。
3、当源表中不存在数据,而目标表中存在的数据可以删除。
注意事项:
1、只会操作“操作表”,源表不会有任何变化。
2、不一定要把update,delete,insert 操作都写全,可以根据实际情况。
3、merge into效率很高,强烈建议使用,尤其是在一次性提交事务中,可以先建一个临时表,更新完后,清空数据,这样update锁表的几率很小了。
4、Merge语句还有一个强大的功能是通过OUTPUT子句,可以将刚刚做过变动的数据进行输出。我们在上面的Merge语句后加入OUTPUT子句。
5、可以使用TOP关键字限制目标表被操作的行,如图8所示。在图2的语句基础上加上了TOP关键字,我们看到只有两行被更新
10 replace()
函数:replace()
含义:替换字符串
用法:replace(原字段,“原字段旧内容“,“原字段新内容“)
11 in,exists
Oracle中的EXISTS和IN操作符都用于查询某个集合的值是否存在于另一个集合中,但它们在处理效率和用法上存在显著差异。
EXISTS通常用于子查询,它检查子查询是否至少返回一行数据。如果子查询返回至少一行数据,那么主查询将返回满足条件的记录。
EXISTS的查询效率较高,因为在执行子查询之前,系统会先将主查询挂起,待子查询执行完毕后,
存放在临时表中再执行主查询。例如,当外表(即主查询)的数据量非常大而内表(即子查询)的数据量较小时,使用EXISTS的效率更高。
IN操作符也用于子查询,但它是将子查询的结果与主查询进行比较,检查主查询中的字段是否在子查询的结果中。
当处理大表和复杂查询时,IN可能会导致性能下降。例如,当内表的数据量非常大而外表的数据量较小时,使用IN可能更有优势。
IN操作符用于匹配某个值是否在一个集合中,而EXISTS操作符用于判断子查询返回的结果集是否非空。
IN操作符会将集合中的值进行去重,而EXISTS操作符不会。
此外,IN操作符的执行效率相对较低,因为需要先计算出集合的所有值,而EXISTS操作符可以在子查询得到第一个匹配项时就停止查询,效率较高。
综上所述,选择使用EXISTS还是IN主要考虑查询效率问题。
如果外表的数据量非常大而内表的数据量较小时,通常使用EXISTS效率更高;
反之,如果内表的数据量非常大而外表的数据量较小时,使用IN可能更有优势
12 not in,not exists
Oracle中的NOT EXISTS和NOT IN在处理查询时存在显著的区别,主要体现在查询效率和处理空值的方式上。
查询效率:NOT EXISTS通常比NOT IN效率更高。这是因为当使用NOT IN时,内外表都可能进行全表扫描,且无法使用索引,导致查询速度较慢。
相比之下,NOT EXISTS的子查询仍然能够使用表上的索引,从而提高了查询效率。
此外,如果查询语句使用了NOT IN,那么内外表都可能进行全表扫描,没有用到索引,而NOT EXISTS的子查询依然能用到表上的索引,因此无论哪个表更大,使用NOT EXISTS都比使用NOT IN要快。
处理空值的方式:对于NOT EXISTS查询,内表存在空值对查询结果没有影响,而外表存在空值的那条记录最终会输出。
而对于NOT IN查询,内表存在空值将导致最终的查询结果为空,且外表存在空值的那条记录最终将被过滤,其他数据不受影响。
综上所述,虽然NOT EXISTS和NOT IN在语法上可能看起来相似,但在实际应用中,选择使用哪一个取决于具体的查询需求和数据库结构。
在大多数情况下,为了提高查询效率,推荐使用NOT EXISTS而不是NOT IN,尤其是在处理包含大量数据的表时。
13 ABS函数
获取数字的绝对值
SELECT ABS(10) FROM DUAL; – 返回 10
SELECT ABS(-10) FROM DUAL; – 返回 10

















 1023
1023

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









