







参考文章:硬盘基本知识(磁头、磁道、扇区、柱面)
参考视频:1. mysql面试题-深入理解B+树原理
这里只做简单的笔记,省略一些目前看不懂的,推荐直接查看参考文章的内容,会更加具体。
-
首先我们得知道,数据是存储在磁盘上的,而磁盘就是具体的存储介质
-
磁盘是由多个盘片所组成的,受到硬盘整体体积和生产成本的限制,盘片数量都受到限制,一般都在5片以内。最底层的盘片是0面,依次往上1面、2面……
-
每个盘片都有对应的读/写磁头
-
然后磁盘中存在磁道,磁道是存储一段数据的空间
-
磁道中存在扇区,扇区就是存储数据的具体位置,通常是512字节。(由于不断提高磁盘的大小,部分厂商设定每个扇区的大小是4096字节)
上面稍微写了点磁盘部分内容,接下来看一些深度解析的,注意,这里所说的是B+树,与B树是不同的
B+树就好比在树中节点存储下一个树枝的物理地址,只有叶子节点才是具体数据,而B树是有值存储在树节点上的,下图以33为例,如果是B树可直接发现1、33、65直接拿了33的内容就结束了,而B+数需要进一步深入,才能拿到具体值。
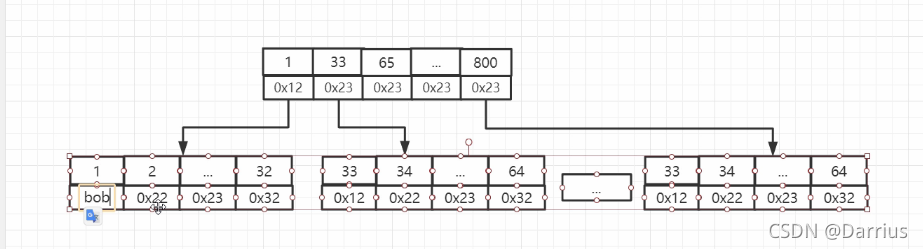
对了,B+树底层还会使用链表方式进行连接,这样在底层数据中就凑成一个链表
结果就变成下图这样
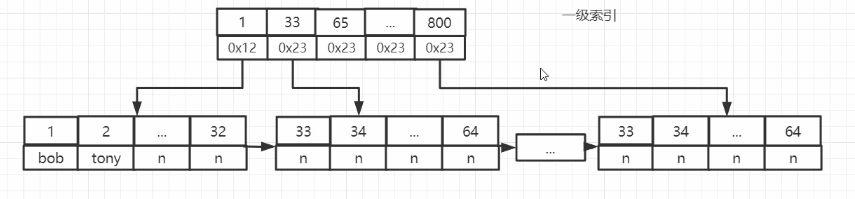
首先我们每个扇区可以存储的容量假设为512bit,假设一条记录需要128bit存储,那么一个扇区可以存储4条记录。在记录增大,那么我们需要访问的扇区也会变多,这样造成的结果是需要多次访问扇区,降低了性能。
重点:这时候我们如果将id字段创建索引来查找,假设id所需要的容量为8bit,那么1个扇区512bit就能存储64个id,当然单独存储id是远远不够的,我们还需要存储剩下的内容的地址,这里也用8bit来存储地址,一个完整的id就需要16bit存储,这样一个扇区就能存储的id为512/16 = 32,将原来扇区存储4条的记录扩大到了32条id,剩下的内容通过地址直接寻址。这就是索引带来的好处之一,具体效果需要根据实际情况来考虑。
这边是使用一次索引所产生的效果,那么如果我们进行套娃处理,将
id索引重新创建索引呢?答案是肯定的,效率还能再次提高,8个
id索引将合并成1个id索引,空间也随之需要更多。(PS:学过操作系统的同学可能这方面更好理解,操作系统中有1级索引、2级索引、多级索引的概念。)
下面来一个实际点的问题
有一个用户表,有800条记录,请问什么办法能一次IO保证查找到对应的记录?
用户表
| 字段 | id | name | no | address |
|---|---|---|---|---|
| 存储bit | 8 | 40 | 8 | 72 |
8+8指的是
id+地址所需要的bit单位
正常存储:一条需要8+8+40+72=128bit,512/128=4,一个扇区可以存储4条记录。
一级索引id:将id创建索引,一条记录需要512/(8+8) = 32,创建一级索引id后一个扇区可以存储32条记录,8bit存储id,8bit存储物理地址。我们一共需要800/8=100条一级索引来存储内容。总计1600bit,3个扇区。
二级索引id:在一级索引的基础上创建id索引,这样8个一级索引id只需要1个二级索引id来表示,即1个二级索引id可以存储32条记录。我们一共需要800/32 = 25条二级索引来存储一级索引。总计400bit,1个扇区。
需要注意二级索引也是需要存储地址的,这样就是使用了25*(8+8) = 400bit空间保证了二级索引的查询在一个扇区内。针对800条记录的问题得以解决。
补充一点,因为一个扇区是可以存储512bit,通过计算 512/(8+8) =32个一级索引
id, 因为一个一级索引有32条记录,因此1个扇区可以存储的记录为32*32 = 1024条记录。如果我们要求3级索引最大的记录数呢?1024*32=32768,可以发现3级索引一个扇区可以存储32768条记录。以此类推,4级索引1048576(104万8576),5级索引33554432(3355万4432),6级索引就能达到1073741824(10亿7374万1824)7级索引达到34359738368(343亿5973万8368),因此千万级开发需要6级索引就能完成一次IO。当然这是有代价的,需要存储空间来存储索引
这里在稍微提一下,因为使用的是
id索引,底层中的排序可能是1、33、65这样有序的,因此算法可以采用二分查找、快排、归并等算法,时间复杂度为O(logn),效率进一步提高
到这里 原本一个扇区存储4条记录,原本需要200个扇区才能解决的问题通过使用了二级索引最后只需要1个扇区即一次IO就能解决。大大提高了效率。














 1096
1096











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









