







简介
Elasticsearch是一个基于Apache Lucene™的开源搜索引擎。无论在开源还是专有领域,Lucene可以被认为是迄今为止最先进、性能最好的、功能最全的搜索引擎库。
特点:
分布式的实时文件存储,每个字段都被索引并可被搜索
分布式的实时分析搜索引擎–做不规则查询
可以扩展到上百台服务器,处理PB级结构化或非结构化数据
Elasticsearch也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
ES能做什么?
全文检索(全部字段)、模糊查询(搜索)、数据分析(提供分析语法,例如聚合)
Solr、ES区别
全文检索、搜索、分析。基于lucene
- Solr 利用 Zookeeper 进行分布式管理,而 Elasticsearch 自身带有分布式协调管理功能;
- Solr 支持更多格式的数据,而 Elasticsearch 仅支持json文件格式;
- Solr 官方提供的功能更多,而 Elasticsearch 本身更注重于核心功能,高级功能多有第三方插件提供;
- Solr 在传统的搜索应用中表现好于 Elasticsearch,但在处理实时搜索应用时效率明显低于 Elasticsearch-----附近的人
Lucene是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎
搜索引擎产品简介
安装准备
安装Centos7、建议内存2G以上、安装java1.8环境
Java环境安装
-
解压安装包
[root@localhost jdk1.8]# tar -zxvf jdk-8u171-linux-x64.tar.gz -
设置Java环境变量
[root@localhost jdk1.8.0_171]# vi /etc/profile
在文件最后添加
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/LIB:$JRE_HOME/LIB:$CLASSPATH
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
[root@localhost jdk1.8.0_171]# source /etc/profile
[root@localhost jdk1.8.0_171]# java -version
es环境的安装实践
-
解压和配置
tar -zxvf elasticsearch-6.3.1.tar.gz
然后进入config文件夹
vi jvm.options
修改initial和maximum

设置浏览器访问
Vi elasticsearch.yml
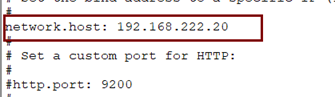
-
启动
需要用非root用户启动

useradd es新增用户
su es切换用户 -
权限不足,就修改文件访问权限
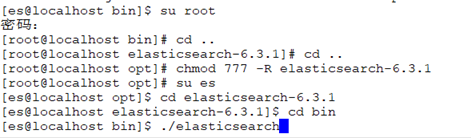
-
嫌弃配置不够

修改配置:最大线程数和最大文件数
vi /etc/security/limits.conf
* hard nofile 655360
* soft nofile 131072
* hard nproc 4096
* soft nproc 2048
nofile - 打开文件的最大数目
noproc - 进线程的最大数目
soft 指的是当前系统生效的设置值
hard 表明系统中所能设定的最大值

修改配置:虚拟内存
vi /etc/sysctl.conf
vm.max_map_count=655360
fs.file-max=655360
vm.max_map_count=655360,因此缺省配置下,单个jvm能开启的最大线程数为其一半
file-max是设置 系统所有进程一共可以打开的文件数量
刷新一下文件sysctl -p
- 集群配置
Vi elasticsearch.yml
cluster.name: aubin-cluster #必须相同
# 集群名称(不能重复)
node.name: els1(必须不同)
# 节点名称,仅仅是描述名称,用于在日志中区分(自定义)
#指定了该节点可能成为 master 节点,还可以是数据节点
node.master: true
node.data: true
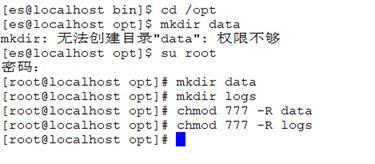
path.data: /opt/data
# 数据的默认存放路径(自定义)
path.logs: /opt/logs
# 日志的默认存放路径
network.host: 192.168.0.1
# 当前节点的IP地址
http.port: 9200
# 对外提供服务的端口
transport.tcp.port: 9300
#9300为集群服务的端口
discovery.zen.ping.unicast.hosts: ["172.18.68.11", "172.18.68.12","172.18.68.13"]
# 集群个节点IP地址,也可以使用域名,需要各节点能够解析
discovery.zen.minimum_master_nodes: 2
# 为了避免脑裂,集群主节点数最少为 半数+1
注意:清空data和logs数据
关闭程序
[elk1@localhost bin]$ ps -ef|grep elastic

[elk1@localhost bin]$ kill 10097
ik分词器和kibana
1 将容器中的ik分词器打包
tar -zcvf ik-6.8.1.tar.gz ik
-
将容器中的ik分词器拷贝到普通目录下
docker cp elasticsearch:/usr/share/elasticsearch/plugins/ik-6.8.1.tar.gz /opt
docker cp 容器名:/容器内路径/文件名 宿主机路径 -
将ik分词器从普通目录下拷贝到容器的pulgins目录下,然后解压
docker exec -it 容器id /bin/bash
进入pulgins
mkdir ik
退出容器
将ik插件拷贝到容器的ik目录下
docker cp 插件文件 容器id:/usr/share/elasticsearch/plugins/ik/
重新进入容器
解压
重启es
注意插件版本和es版本必须保持一直 -
kibana的安装
将集群配置文件elasticsearch.yml重新改成单机配置
重启,在退出命令行的状态下启动es,将日志写入nohup.out
nohup ./elasticsearch &
或者后台启动
[elk1@localhost bin]$ ./elasticsearch -d
将kibana软件上传到服务器,解压
config/kibana.yml
修改kibana配置文件,将kibana的es的9200端口地址配置到kibana中,配置kibana的外网ip
0.0.0.0

启动kibana
nohup ./kibana &
学习小结
- 集群cluster
Es集群的能被选举为主节点的机器的数量一般不少于半数+1,这是为了防止”脑裂”的发生 - 节点node
单机es在启动时需要注意- es对机器的启动用户权限是有要求的,不能用root用户
- es对机器的线程数、内存、文件数都是有要求的
- 主节点,加入节点,删除节点
- 从节点,具体工作,比如数据查询
- 分片,复制片
- 片是实际的物理单元,每一个分片其实是一个lucen实例
- 复制片为了保证数据的安全性设置的,当复制片的数量不能有足够的机器支撑,节点状态变为黄色
- 一般查询操作由复制片完成,因为查询压力大,由复制片负载主片的压力
- 写入操作,先由主片运行,然后同步给复制片,在这个过程中有两种模式:
- Async异步(马上给成功信息,不过不一定立即执行成功了,只是异步执行中)
- Sync同步(执行成功后返回成功信息)
- 索引(库)
索引相当于mysql中的库的概念,是一个逻辑单元,一般一个索引包含5个片 - type(表)
- document(数据)
- field(字段)














 2229
2229











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









