






https://www.usenix.org/conference/atc20/presentation/zhao
场景:对Docker registry进行重复数据删除
观察发现:1.容器镜像拥有大量冗余,而现有的重复数据删除技术不适用于Docker registry,会导致极高的layer恢复时间开销。
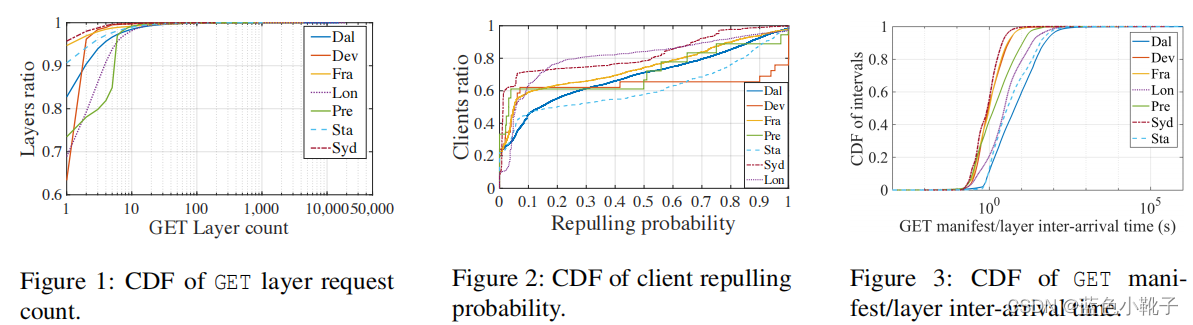
2.大多数layer只会被同一用户获取一次;许多用户只pull一个layer一次;用户对于layer一般要么只pull一次,要么总是repull,所以可以根据一个用户的pull历史来预测他要pull哪些layer。
3.Docker客户机从registry中提取镜像时,首先检索镜像manifest,其中包括对镜像layer的引用。GET manifest 和GET layer 请求之间往往存在秒级的间隔。在此间隔内预测用户需要哪些layer并对layer进行预构造能显著地降低layer恢复的时间开销。
DupHunter的架构如图所示:
DupHunter主要由两部分组成:一个分布式元数据数据库和一个存储服务器集群。
在上传或下载layer时,Docker客户端可以使用registry API与任何DupHunter服务器进行通信。集群中的每个服务器都包含一个API服务和一个后端存储系统。 后端存储系统存储layer并执行重复数据删除,最后将重复数据删除元数据保存在数据库中。
服务器集群中又分为由P-server组成的原始集群服务器(Primary cluster)和由D-sever组成的重删集群服务器(Deduplication cluster)。P-sever负责存储无需进行重复数据删除的完整layer压缩文件副本和manifest副本;D-sever负责对layer压缩文件进行重复数据删除并存储和复制unique文件。
每个D-server的本地存储分为三个部分:layer stage区域、预构建缓存和文件存储。layer stage区域会临时存储新添加的layer完整副本。在对副本进行重复数据删除后,生成的unique文件存储在内容可寻址的文件存储中,并复制到对等服务器以提供冗余。存储了所有文件副本后就会从layer stage区域删除layer副本。
三种技术:
1.Replica deduplication modes:
①basic deduplication mode n (B-mode n):代表DupHunter只保持n个完整的layer副本,并对剩余的R-n个副本进行重复数据删除(R为layer复制级别)。在极端情况下,B-mode R代表不进行重复数据删除,提供了最好的恢复性能但是没有数据减少;B-mode 0代表对所有layer副本进行重复数据删除,提供了最高的重复数据删除率,但增加了恢复开销。
②selective deduplication mode (S-mode):根据layer被pull的频率(即热度)来决定对多少个副本进行重删。在S-mode下,layer完整副本的数量与其热度成正比,这意味着热layer有更多完整的副本,因此可以更快地提供服务,而冷layer则可以更积极地进行重复数据删除。
为了适应不同的模式,DupHunter如前面所说将服务器分为原始集群服务器和重删集群服务器两种,在默认情况下,原始集群服务于所有传入的GET请求。如果不能从原始集群提供服务(例如,节点故障,或DupHunter在B-mode 0或S-mode下运行),请求将被转发到重复数据删除集群,并将重建请求地layer。
2.Parallel layer reconstruction:
DupHunter通过并行性加快了layer重建的速度。
DupHunter将layer的unique文件分发到几个服务器上。一个服务器上属于同一layer的所有文件被称为切片。切片有相应的切片recipe,layer recipe定义重建该layer所需的切片。这些信息存储在DupHunter的元数据数据库中。多个D-server存储着一个layer的不同切片使得D-sever可以并行地重建layer切片,从而提高重建性能。DupHunter在元数据数据库中维护layer和文件的指纹索引。 .
3.Predictive cache prefetch and preconstruction:
为了降低layer的访问延迟,DupHunter分别在原始集群和重复数据删除集群中使用了一个缓存层。每个P-server都有一个in-memory的基于用户行为的预取缓存,以减少磁盘I/Os。当收到来自用户的GET manifest请求时,DupHunter预测镜像中实际需要提取哪些layer,并在缓存中预取它们。此外,为了减少layer恢复开销,每个D-server都有一个on-disk的基于用户行为的预构造缓存。与预取缓存一样,当接收到GET manifest请求时,DupHunter预测镜像中的哪些layer将被提取,预构造这些layer,并将它们加载到预构造缓存中。为了准确地预测要预取哪些layer,DupHunter维护了两个映射:ILmap和ULmap。ILmap存储镜像和layer之间的映射,而ULmap跟踪用户的访问历史,即用户pull了哪些layer以及pull它们的次数。
具体过程:
1.对layer进行重复数据删除:
①DupHunter中有一个layer索引,在接收到PUT layer请求后,DupHunter首先检查layer索引中的layer指纹,以确保没有存储相同的layer。然后DupHunter会在P-server上复制layer r次,并将剩余的R−r个layer副本提交给D−服务器。这些复制副本临时存储在D-server的layer stage区域中。成功存储了副本后,DupHunter就会通知客户端请求完成。
②文件级重复数据删除。副本进入layer stage区域后,其中一个D-server就会解压该layer并启动重复数据删除。首先从tar archive中提取文件条目,每个文件条目由文件头和关联的文件内容组成,文件头包含诸如文件名、路径、大小、模式和所有者信息等元数据。DupHunter将在切片recipe中记录每个文件头以用于恢复完整的layer archive。然后根据文件内容计算文件的哈希函数值作为文件的ID,并检查该ID是否已经存在在文件索引中。如果已存在则删除当前文件内容,不存在就将文件内容分配给一个D-server存储到文件存储区中,并把文件ID加入索引中。索引记录不同文件ID对应的副本存储在哪个D-server中。
③对layer进行划分。DupHunter采用了一个贪婪地打包算法将layer划分为大小相似的切片,并让他们均匀分布在D-server上。对于一个layer副本,首先计算每个D-server上存储该layer引用的文件的总大小,然后将当前最大的unique文件分配给最小的分区,知道分配完当前副本,再对下一个副本进行划分和分配。这样还确保了同一文件的两个副本永远不会放在同一个节点上
④复制unique文件制造冗余实现容错。复制每个切片并将切片副本存入其他D-server中。文件复制后,DupHunter将新的切片recipe添加到元数据数据库中。DupHunter还为layer创建了一个layer recipe,并将其存储在元数据数据库中。layer recipe记录了存储该layer切片的所有D-server,它们可以用于恢复工作。当需要重建一个layer时,将选择一个D-server作为恢复主服务器,负责收集所有切片并重建layer。
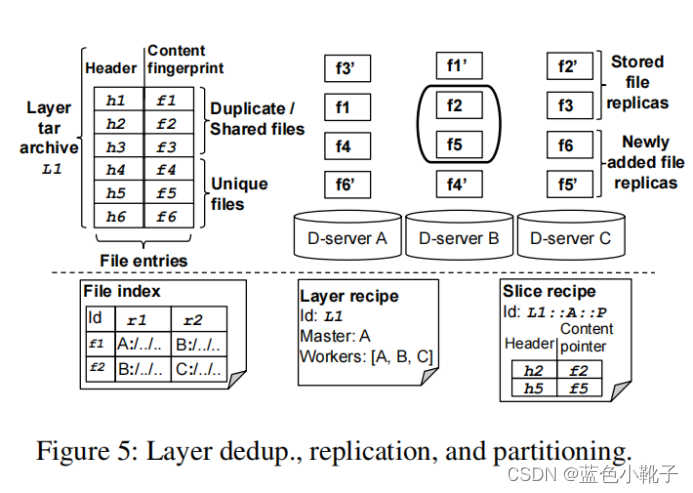
layer L1分为f1-f6六个unique文件和(f1,f4),(f2,f5),(f3,f6)三个原始切片。元数据数据库中存储File index(文件ID和副本物理存储地址的映射),Layer recipe(存储重建layer所需的切片的服务器)和Slice recipe(切片包含的文件信息).
图5显示了一个重复数据删除过程的示例。该示例假设B-mode 1具有3路复制,也就是说,每个unique文件都有两个分布在两个不同的D-server上的副本。文件f1、f2和f3已经存储在DupHunter中,而f1’、f2’和f3’是它们对应的副本。layer L1正在被push,其中包含文件f1-f6。f1、f2和f3是L1和其他layer之间的共享文件,因此在文件级重复数据删除时被丢弃。唯一的文件f4、f5和f6被添加到系统中,并复制到D-server A、B和C中。
复制完成后,服务器B中分别包含f2、f5、f1’和f4’。f2和f5一起构成L1的原始切片,表示为L1::B::P。这个切片Id包含切片属于的layer的Id(L1),存储切片的节点(B)和备份级别(P 代表primary)。B上的两个备份文件副本f1’和f4’形成备份切片L1::B::B(backup)。在layer恢复过程中,可以通过使用原始切片和备份切片的任意组合来恢复L1,以实现最大的并行性。
2.恢复layer
恢复工作包括切片恢复和layer恢复两个阶段。根据图五的重删过程,恢复过程如下:

首先根据 L1的layer recipe得知恢复L1所需要的D-server为A,B,C.选择存储的切片最大的服务器作为恢复的主服务器(假定此例为A)。A发送GET请求给B和C获取B和C中的切片,如果缺少原始切片则找到其备份切片并GET。
在收到GET切片请求后,B和C的切片构造函数开始重建它们的主片,并将它们发送给A,如图6所示。同时,A指示其本地的切片构造函数恢复其针对L1的主切片。要构造layer切片,切片构造函数首先从元数据数据库中获取切片recipe。配方由层Id、主机地址和备份级别(例如L1::A::P)的组成。根据recipe,切片构造函数通过连接每个文件头和相应的文件内容来创建一个切片tar文件;然后压缩切片并将其传递给主服务器。主服务器将所有压缩切片连接为一个layer的压缩tarball,并将其发送回客户端。
层恢复性能对于保持低pull延迟至关重要。因此,DupHunter在服务器上并行化切片重建,并避免在磁盘上生成中间文件,以减少磁盘的I/O。
预取和预构造缓存
ILmap:镜像所需要的所有layer。
ULmap:为每个用户保存用户已经pull过的layer即pull次数的记录。
DupHunter会为每个用户保存一个repull概率:
![]() 。RL是用户之前repull过的layer的集合(即,pull计数>1),L是用户曾经pull过的所有layer的集合。DupHunter在每次收到GET layer请求时都会更新pull计数。
。RL是用户之前repull过的layer的集合(即,pull计数>1),L是用户曾经pull过的所有layer的集合。DupHunter在每次收到GET layer请求时都会更新pull计数。
接收到GET manifest请求时,DupHunter首先计算用户需要的layer集合S△=ILmap-ULmap,S△中包含的layer提取到缓存中。然后将用户的repull概率和预定义的阈值
比较,如果
就将该用户归类为repull用户并计算用户请求的镜像中过去已经pull过的layer:S∩=ILmap∩ULmap,把S∩中包含的layer也提取到缓存中。

如图所示,DupHunter为5级2层存储,请求按照层级从上到下传递。
在GET layer请求到达时,DupHunter首先确定负责该层的P-server,并搜索预取缓存。如果存在该layer,则将从缓存提供服务。否则,将从layer存储中提供服务。
如果由于相应的P-server出现故障,无法从原始集群提供服务,该请求将被转发到重复数据删除集群。在这种情况下,DupHunter将首先查找layer recipe。如果找不到recipe,则意味着该layer尚未完成重复数据删除,DupHunter将从负责的D-server的某个layer stage区域为该layer提供服务。如果存在layer recipe,DupHunter将联系负责恢复的D-server检查layer是否在其预构造缓存中。不存在的话就让负责恢复的D-server重建layer。
可能的改进工作:本文为文件及重复数据删除,未来可以尝试在D-server上进行块级重复数据删除以提高重复数据删除率,当然难免导致恢复性能变差。还可以在与纠删码结合减少副本的冗余,这样会降低pull性能,但是在预取和预构造缓存的作用下会有所缓和。














 1270
1270











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









