







1. 前置知识
1. 汇编语言两种风格
intel:我们学的NASM就属于Intel风格AT&T:GCC后端工具默认使用这种风格,当然我们也可以加选项改成intel风格
2. 代码
1. 段分布
.text: 存放的是二进制机器码,只读.data: 存放有初始化的全局变量。非默认值.bss:存放未初始化的全局变量,或者默认初始化的全局变量。这一部分在二进制文件中不占硬盘空间,即不会真实存储这些为初始化的变量,而是在程序加载到内存时再分配。当然肯定需要有个标识,告诉该怎么分配内存.rodata:存放只读数据,如常量数据
#include <stdio.h>
int global_var1; // bss
int global_var2 = 0; // bss
int global_var3 = 42; // data
const char* hello = "Hello, world!"; // rodata
int main() // text
{
printf("%s\n", hello); // text
return 0; // text
}
2. 标签
section .data
counter db 10 ; 声明并初始化计数器,counter表示计数器的地址
section .text
global _start
_start:
nop ; No operation, 用于占位
loop_start: ; 标签定义一个循环开始的位置
dec byte [counter] ; 减少计数器的值
jnz loop_start ; 如果计数器非零(ZF=0),跳回到 loop_start
; ... 程序的其余部分
- 标签可以被视为
一个给定位置的名称或者是一个指向特定地址的指针。 可以把他们都当作地址 - 上面的例子定义了两个标签:
counter、loop_start 本地标签:本地标签通常以.开头,只在本地上下文有意义
3. 包含
section .data
%include "data.asm"
section .text
global _start
_start:
%include "code.asm"
include通常用于在一个源文件中插入另一个源文件的内容,等同于C中的#include- 上面的例子就是将
data.asm的内容插入到.data段
section .data
image:
incbin "picture.bmp"
incbin:此伪指令可以用于将一些预先生成的、需要嵌入到程序的二进制数据(如图像、音频、编码的数据文件等)直接加载到汇编程序中。- 其格式为
incbin “filename” [, skip, length]
3. 内存
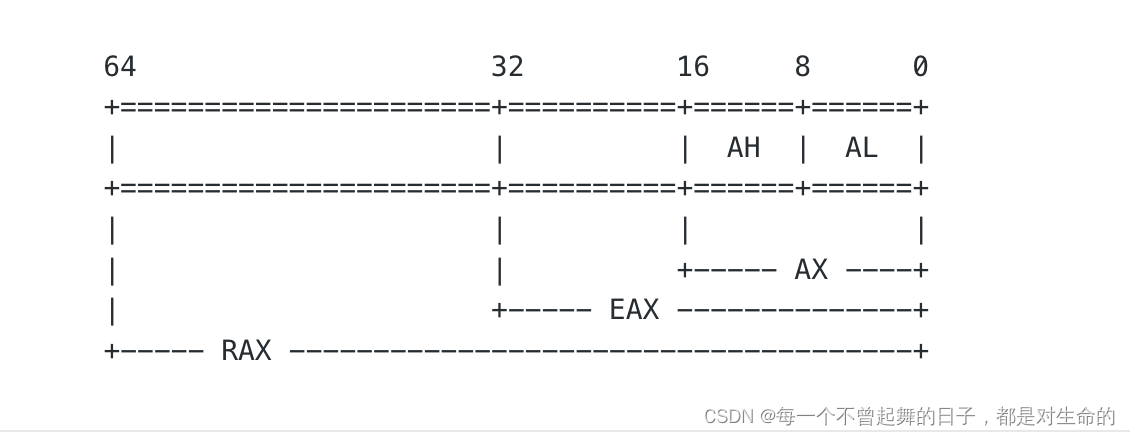
1. 寄存器(在x64架构中)
通用寄存器:
RAX: 累加器。用于进行算数运算,同时也是一部分系统调用(例如sys_write或sys_read)中存储返回值的寄存器。RBX: 基址寄存器。一般用于在间接寻址中保存变量的内存地址。RCX: 计数器寄存器。在循环迭代中常常用作循环计数。RDX: 数据寄存器。通常与RAX配合,用于大数的乘法和除法运算。RSI: 源变址寄存器。在字符串和内存操作中常常用来存储源地址。RDI: 目的变址寄存器。在字符串和内存操作中常常用来存储目的地址。RBP: 基址指针。通常被用作帧指针,指示当前函数帧在堆栈中的位置。RSP: 堆栈指针。始终指向当前栈顶的位置。R8 - R15: 在x64架构中新增的8个通用寄存器,可以通用性地使用。
对于这些寄存器的使用,取决于具体的应用场景和编程约定。例如,某些系统调用可能会使用RDI,RSI,RDX,R10,R8和R9来传递前6个参数。(以上寄存器都是64位)
指令寄存器:
RIP:指令指针,指向下一条要执行的指令。64位
段寄存器:(都是16位)
CS(Code Segment):代码段寄存器,包含当前正在执行的代码的段基址。DS(Data Segment):数据段寄存器,通常包含程序正在操作的数据的段基址。SS(Stack Segment):堆栈段寄存器,包含当前堆栈的段基址。ES(Extra Segment):附加段寄存器,用于存储其他数据段的基址。FSGS
标志寄存器:
RFLAGS(64位):标志寄存器,保存了程序的运行状态
一个简单的汇编例子如下:
section .data
msg db 'Hello, World!', 0
section .text
global _start
_start:
; syscall: write
mov eax, 1 ; sys_write
mov edi, 1 ; file descriptor: stdout
lea rsi, [rel msg] ; buffer address: msg
mov edx, 13 ; message length
syscall ; perform syscall
; syscall: exit
xor edi, edi ; exit status code:
2. 寻址
在 x64 架构中,使用 NASM 汇编,支持的寻址方式如下:
-
立即寻址(Immediate addressing):操作的数据直接包含在指令中。比如:
mov rax, 123 ; rax = 123 -
寄存器寻址(Register addressing):操作数存储在寄存器中。例如:
add rax, rbx ; rax = rax + rbx -
直接寻址(Direct addressing):操作的数据在内存中的某个具体位置,其地址在指令中直接给出。例如:
mov eax, [someVariable] ; eax = contents of memory at address someVariable -
间接寻址(Indirect addressing):操作数存储在由另一个寄存器指定的内存地址中。例如:
mov eax, [rbx] ; eax = contents of memory at address stored in rbx -
基址寻址(Base addressing):操作数的地址是某个寄存器的值加上一个常量偏移量。例如:
mov eax, [rbx+4] ; eax = contents of memory at address (rbx + 4) -
索引寻址(Indexed addressing):操作数地址由基址加上索引值乘以元素大小给出。它通常被用来处理数组。例如:
mov eax, [rbx+rcx*4] ; eax = contents of memory at address (rbx + rcx*4) -
基址变址寻址(Base-indexed addressing):使用一个基址加上一个偏移量,再加上一个索引。例如:
mov eax, [rbx+rcx+4] ; eax = contents of memory at address (rbx + rcx + 4)
以上就是在 NASM 中使用的基于 x64 架构的寻址方式的简单介绍。选择哪种寻址方式取决于你需要在哪里获取数据或者指令应该如何计算操作数的地址。
4. 指令
1. 操作数类型
立即数(imm):以常量出现在指令中,只能是源操作数寄存器(reg):数据存放在寄存器中,指令中给出寄存器名内存(mem):数据存在于内存单元中,指令中给出内存地址
2. 操作
-
数据移动指令
mov:复制(移动)源操作数到目标操作数。push:将数据压入堆栈。pop:从堆栈中弹出数据。
-
算数指令
add:两个操作数相加,结果保存到目标操作数中。sub:两个操作数相减,结果保存到目标操作数中。inc:将操作数的值加一。dec:将操作数的值减一。imul:相乘操作。idiv:相除操作。
-
逻辑运算指令
and:逻辑与操作。or:逻辑或操作。xor:逻辑异或操作。not:逻辑非操作。
-
控制流指令
jmp:无条件跳转到指定的代码地址。je,jne,jg,jge,jl,jle:基于某个条件跳转。call:调用一个子程序/函数,通常会跳转到一个代码地址,并将返回地址压入堆栈以方便返回。ret:从子程序/函数返回,通常会弹出一个值作为下一个要执行的代码地址。loop: 循环指令
-
比较和测试指令
cmp:比较两个操作数。test:逻辑与测试。
-
字符串操作指令
movs,cmps,scas,lods,stos:对字符串进行操作的一组指令。
-
转换指令
cwde,cdqe,cwd,cdq,cqo:转换字宽度的一组指令。
5. 数据
High Addresses ---> .----------------------.
| Environment |
|----------------------|
| | Functions and variable are declared
| STACK | on the stack.
base pointer -> | - - - - - - - - - - -|
| | |
| v |
: :
. . The stack grows down into unused space
. Empty . while the heap grows up.
. .
. . (other memory maps do occur here, such
. . as dynamic libraries, and different memory
: : allocate)
| ^ |
| | |
brk point -> | - - - - - - - - - - -| Dynamic memory is declared on the heap
| HEAP |
| |
|----------------------|
| BSS | Uninitialized data (BSS)
|----------------------|
| Data | Initialized data (DS)
|----------------------|
| Text | Binary code
Low Addresses ----> '----------------------'
1. 内存分段
在汇编语言层面,变量主要体现为内存的确定位置。
在 NASM 汇编中,你可以通过 SECTION 或者 SEGMENT 关键字把变量定义在不同的段区。以下是一些常见的段区:
- .data 段:用于存储程序中已初始化的全局变量和静态变量。
SECTION .data var1 db 10 ; 定义一个字节变量var1并初始化值为10 var2 dd 1000 ; 定义一个双字变量var2并初始化值为1000 arry db 1, 2, 3, 4, 5 ; 定义了一个长度为5的字节数组,在访问时通过基址加上偏移的方式访问各元素。 - .bss 段:用于声明未初始化的全局变量和静态变量,这些变量在程序开始执行前自动初始化为0。声明变量使用
resb,resw,resd,resq等伪指令。SECTION .bss var3 resb 1 ; 定义一个字节变量var3 var4 resd 1 ; 定义一个双字变量var4 b resq 2. ; 2个DQ空间 blen equ $ - b. ; resq*2=16 - .text 段:是程序代码段,会包含程序的可执行指令。
SECTION .text global _start ; 声明一个全局入口 _start: ; 你的汇编代码 - .rodata 段:用于存储只读数据,比如你的程序中的常量字符串。
SECTION .rodata msg db "Hello, World", 0 ; 定义一个字符串常量msg。 每个字符一个字节,0在c语言表示字符串结尾 screenWidth equ 1024 ; 定义一个符号,名字叫做screenWidth,代表数值为1024
- x86/x64架构采用小端数据存储,
var dd 0x12345678这个四字节变量在内存中从低位地址到高位地址依次是0x78,0x56,0x34,0x12。在访问大于一个字节的内存时需要小心处理字节的顺序。 - 变量定义在
.bss和.data段中 - 常量在
.rodata段中
2. 声明内存分配的伪指令
- db:Define Byte,定义一个字节大内存空间
myConst db 12 ; 声明一个名为 myConst 的字节常量,值为12 - dw:Define Word,定义一个两字节大的内存空间。
myConst dw 1234 ; 声明一个名为 myConst 的字常量,值为1234 - dd:Define Double Word,定义一个四字节大的内存空间。
var dd 12345678 ; 声明一个名为var 的双字变量,值为12345678 - dq:Define Quad Word,定义一个八字节大的内存空间。
myConst dq 123456789012345678 ; 声明一个名为 myConst 的四字常量,值为123456789012345678 - dt:Define Ten Bytes,定义一个十字节大的内存空间。
3. equ伪指令
equ在 NASM 汇编中用于声明一个符号。- 在汇编阶段,这些由
equ定义的符号将被替换为它们代表的实际值。 - 类似于在高级编程语言中,我们定义的预处理宏或者常量。
- 它是伪指令,不占内存
例如,如果你写下以下代码:
PI equ 3.14
times 2*PI
在汇编阶段,这将被视为:
times 2*3.14
这样的特性使得 equ 成为定义常量值、内存大小或其他需要在编译阶段进行代替的符号的理想选择。
equ定义的是符号以及其对应的值,不分配内存;db,dw,dd,dq定义的是内存中的数据,即变量或者说是内存分配的常量,会占用实际的内存空间。
4. times 伪指令
在 NASM 汇编中,times 是一种伪指令,它的功能是重复指定的汇编指令或数据定义指定的次数。
-
数据段中的使用:
times可以用来定义重复的数据。section .data ones db 1 ; 定义一个字节的数据大小为1 bigspace times 1000 db 0 ; 定义一个包含1000个字节的数据,每个字节初始化为0 -
代码段中的使用:
times可以用来重复指定的汇编指令。section .text global _start _start: times 5 mov al, 'A' ; 执行5次mov al, 'A' 指令
注意:上述代码段中的用法仅作为times概念理解,实际上这段代码并没有意义,因为连续执行相同的mov指令并不会有特别的效果,因为每次执行都会覆盖原有内容。在实际编程中,times通常用于数据定义,如初始化一个具有相同初始值的大数组。
总的来说,times 是一种在汇编期间进行循环展开的方法,它可以用来定义大块的重复数据,或者重复执行同一条指令。
5. $和$$符号的含义
-
$:$表示当前指令的地址。这在给向前或者向后跳转的指令填写距离的时候很有用,因为你可以用 $ 来代表当前的位置,然后和目标指令的标签计算距离。mov eax, $ ; 将当前指令的地址赋给 eax -
$$:$$表示当前段的开始地址。它通常用来计算相对于段开始的偏移。这在一些需要处理相对地址的操作中比较有用。mov eax, $$ ; 将当前段开始的地址赋给 eax
6. %assign和%define宏与处理器命令
在 NASM 汇编中,%assign 和 %define 是宏预处理器指令,用于定义和赋值符号。
-
%define是用来定义一个宏常量或者宏。定义后,当汇编器在后续的代码中遇到这个宏时,就会用其定义的字符串替换。典型用法如下:%define BUFFER_SIZE 1024 mov eax, BUFFER_SIZE ; 预处理阶段会替换成 mov eax, 1024 -
%assign是用来给一个符号赋值一个表达式,然后可以在后续中用这个符号来引用这个表达式。典型用法如下:%assign BUFFER_SIZE 1024 mov eax, BUFFER_SIZE ; 预处理阶段会替换成 mov eax, 1024
- 两者的主要区别在于
%assign通常用于数值或者可以计算的表达式,而%define更多的是用于字符串替换。比如你可以在%assign中写一个算术表达式,而%define则不解析它的内容,直接做文本替换。
%assign SIZE 1024 * 2 ;size=2048
%define SIZE_DEF 1024 * 2 ;size="1024 * 2"
7. 前缀指令rep
-
rep是一种前缀指令,通常与串操作指令(如movs,stos,cmps,scas,lods等)一起使用,用于对字符串进行重复操作。 -
rep指令的功能是:只要cx或ecx(根据地址大小,16位环境下使用cx,32位环境下使用ecx)的值不为0,就重复执行后面的指令,并且每执行一次,cx或ecx的值自减1。
下面是一个例子,使用 rep 前缀指令来赋值字符串前四个字节。假设我们要将字符串的前四个字节赋值为 'A':
section .data
buffer db '12345678' ; 原始字符串
section .text
global _start
_start:
mov ecx, 4 ; 要复制的字节数量
mov al, 'A' ; 要复制的字节值
lea edi, [buffer] ; 目标字符串的地址
rep stosb ; 执行赋值操作
; 假设用 `_start` 函数作为程序的起点,
; 你可以在这里添加你想要的代码,
; 比如将更改后的字符串打印到控制台。
; 程序退出
mov eax, 0x60
xor edi, edi ; 参数
syscall ; 调用系统退出
rep stosb 指令的作用是将 AL 寄存器的内容存储到由 EDI 寄存器指向的内存位置,然后 EDI 将根据标志寄存器中的方向标志(Direction Flag)增加或减少。如果方向标志为 0(默认),EDI 加1,如果为 1,EDI 减1。然后 ECX 减 1。当 ECX 变为 0 时,rep 指令就会停止重复。因此,上述代码的效果就是将 'A' 复制4次到 buffer。
此外,还有两个与 rep 类似的重复前缀:
-
repe或repz:只要zx标志(零标志)为真,并且cx或ecx的值不为 0,就重复执行后面的指令。这种情况常与cmpsb,cmpsw, 或scas等指令配合使用。 -
repne或repnz:只要zx标志(零标志)为假,并且cx或ecx的值不为 0,就重复执行后面的指令。这种情况常与cmpsb,cmpsw, 或scas等指令配合使用。
8. 结构体如何实现
在汇编语言中,并没有直接定义结构体的语法,但是我们可以使用数据定义指令(如 db, dw, dd, dq)以及各种标签和偏移来创建类似结构体的复合数据类型。
下面是在 NASM 汇编语言中定义和操作结构体的一个例子:
例如,我们要定义一个类似 C 语言中的如下结构体:
struct MyStruct {
int id;
char name[10];
};
在汇编中,可以这样定义:
section .data
MyStruct:
.id dd 1 ; 4 bytes for integer value
.name db 'nasm' ; 10 bytes for char array
.endStruct
然后我们可以使用标签定位每个元素,并对其进行操作。例如我们可以改变 id 的值:
mov [MyStruct.id], dword 2
或者改变 name 的值:
mov [MyStruct.name], byte "x"
在 NASM 汇编中,. 前缀被用于定义一个局部标签,这个局部标签只在距离它最近的上一个非局部标签(没有以.开头的标签)之后可见。
在上面例子中, .id 和 .name 是 MyStruct 的局部标签。在 MyStruct 之后的代码中,你可以通过 MyStruct.id 访问 id 域,通过 MyStruct.name 访问 name 域。当然你还可以定义一个新的结构,并且使用相同的局部标签名。例如:
Section .data
MyStruct:
.id dd 1
.name db 'nasm'
YourStruct:
.id dd 2
.name db 'assembly'
在这个例子中,.id 和 .name 在YourStruct中重新开始,且不会引起重定义错误。你可以通过YourStruct.id和YourStruct.name来访问这个新结构的字段。这种方式使代码更加结构化,易于理解和维护。
6. 函数
1. 宏的定义
在汇编语言中,我们可以使用 %macro 和 %endmacro 指令来定义一个宏。宏可以包含任意的代码片段,并用一个自定义的名字来标识它,然后可以在需要的地方通过这个名字来使用宏。
以下是一个在 NASM 汇编中定义和使用宏的例子:
; 定义宏
%macro print 1
mov eax, 4 ; sys_write 的系统调用号为4
mov ebx, 1 ; 文件描述符 1 —— stdout
mov ecx, %1 ; 要打印的字符串
mov edx, %1len ; 要打印的字符串长度
int 0x80 ; 执行系统调用
%endmacro
section .data
Msg db 'Hello, World!',0xA ; 0xA 不包括在长度计数中
Len equ $-Msg
section .text
global _start
_start:
print Msg ; 使用宏
mov eax, 1
xor ebx, ebx
int 0x80
在此示例中,我们定义了一个名为 print 的宏,该宏接收一个参数(用 %1 表示),将这个参数打印到 stdout。我们可以通过将字符串名传递给 print 宏来使用它,就像在 _start: 标签下那样。
注意,%macro 指令之后的 1 表示该宏需要一个参数。如果你的宏需要多个参数,你可以通过改变这个数字,而且可以用 %1、%2 等来访问这些参数。
此外,%1len 是 NASM 的一个特性,它可以返回宏参数的长度,这在处理字符串时非常有用。当我们传递 Msg 作为参数到 print时,%1len 就被替换成了 Msg 的长度,也就是字符串 ‘Hello, World!’ 的字符数。这个长度在编译期就被确定下来,不会在运行期改变。
2. 规定宏的参数个数
; 定义一个接受两个参数的宏
%macro sum 2
mov eax, %1
add eax, %2
%endmacro
section .text
global _start
_start:
sum 5, 3 ; 调用宏,参数为5和3
在此示例中,sum是一个宏,它接受两个参数(表示为%1和%2)。此宏将第一个参数和第二个参数相加,然后将结果存入eax寄存器。
使用sum 5, 3,%1是5
3. 宏的重载
在汇编语言中,特别是在 NASM 中,没有直接支持宏重载的功能。
有一些间接的方法可以模拟"宏重载"的效果。一种常见的方法是根据参数数量的不同来改变宏的行为。NASM 这样支持:
%macro say 0-2 ; 0-2 表示该宏可以接受0个,1个或2个参数
%if %0 == 0 ; %0 用来获取宏参数的数量
%define msg "Hello, World!"
%elif %0 == 1
%define msg %1
%else
%define msg "Too many arguments"
%endif
mov eax, 4
mov ebx, 1
mov ecx, msg
mov edx, msglen
int 0x80
%endmacro
如上的代码,say 宏可以接受0个、1个或2个参数,并根据参数数量的不同采取不同的行为,实际上就模拟了"宏重载"的效果。
不过要注意,这样的方法在复杂的程序中可能会导致代码难以理解和维护,所以应当谨慎使用。
在需要进行底层编程的时候,如果有“宏重载”的需求,可能需要考虑使用更高级的语言或者 assembly 的宏处理工具,例如使用 C/C++ 可以更便捷地处理此类需求。
4. 宏中使用本地标签%%
在 NASM 汇编中,本地标签(或称局部标签)常常在宏定义中使用,主要用来创建在宏内部唯一,但在宏的实例之间不唯一的标签名。
对于宏内部的代码流程控制,我们通常需要使用跳转指令,而跳转指令又需要标签。如果我们在不同的宏或者宏的多个实例中使用相同名称的标签,就会造成标签重复定义的问题。为了解决这个问题,NASM 提供了一个特性,允许我们在宏定义中使用 %% 前缀来创建本地标签。
以下是一个在 NASM 中创建和使用本地标签的例子:
%macro do_something 0
mov eax, 1
%%loop: ; 一个本地标签
add eax, eax
cmp eax, 1024
jl %%loop ; 使用本地标签
%endmacro
section .text
global _start
_start:
do_something ; 调用宏第一次
do_something ; 调用宏第二次
在这个例子中,我们定义了一个名为 do_something 的宏,该宏包含一个本地标签 %%loop 和一个跳转指令 jl,该跳转指令在 eax 小于1024时,跳转到 %%loop 标签处执行代码。我们可以多次调用这个宏,每次调用这个宏时,宏内的 %%loop 都为新生成的代码块创建一个新的,唯一的标签。
使用本地标签,我们可以在宏定义中包含更复杂的控制流程,而不需要担心标签重复定义的问题。同时,由于标签名在不同宏实例中可以相同,这也使得我们可以编写更通用,更有复用性的宏。
5. 函数运行栈

call: 将IP寄存器内容入栈,跳转到目标函数ret:弹出值到IP寄存器,跳转回调用方,继续执行
6. 函数调用
- 在Linux下,函数的参数主要通过
RDI,RSI,RDX,RCX,R8,R9这些寄存器传递,如果参数多于这些寄存器的数量,那么剩余的参数会通过堆栈传递。 - 函数的返回值通常通过
RAX寄存器返回。
以下是一个在 NASM 中的示例,包含定义和调用函数:
section .data
value1 dq 5
value2 dq 3
result dq 0
section .text
global _start
_start:
; 把参数放在寄存器中
mov rdi, [value1]
mov rsi, [value2]
; 调用函数
call add_two_numbers
; 函数返回后,结果在 rax 寄存器中
mov [result], rax
; 退出程序
mov eax, 60
xor edi, edi
syscall
; 函数: add_two_numbers
; 参数: rdi = num1, rsi = num2
; 返回: rax = num1 + num2
add_two_numbers:
; 函数体
add rdi, rsi
mov rax, rdi
ret ; 返回
在上述代码中,我们定义了一个函数add_two_numbers,它接受两个参数,返回它们的和。函数的参数通过rdi和rsi寄存器传递,返回值存储在rax寄存器中。call指令用于执行函数调用,ret指令用于从函数返回。
7. 函数的保护现场处理
在 NASM 风格的 x86-64(也叫 AMD64)汇编中,保存现场和恢复现场的代码示例如下:
section .text
global _start
_start:
; 保存现场
push rax
push rbx
; 这里是函数调用等操作
; ...
; 恢复现场
pop rbx
pop rax
; 退出程序
mov eax, 60
xor edi, edi
syscall
- 通过
push指令将rax和rbx寄存器的当前值保存到堆栈中,该过程被称为"保存现场"。 - 然后在函数调用结束后,我们通过
pop指令将rbx和rax寄存器的值从堆栈中恢复,这就是"恢复现场"。 mov eax, 60将系统调用号设置为 60(SYS_exit是 Linux 下的系统调用,代表请求操作系统退出程序),xor edi, edi是把edi寄存器清零,代表退出状态码为 0,最后syscall指令执行系统调用。
8. 函数调用的相关命令
-
call: 此指令用于跳转到函数或子程序。它首先将下一条指令的地址(即返回地址)压入堆栈,然后跳转到目标函数的首地址开始执行。比如,call functionName。 -
ret: 此指令用于从函数或子程序返回。它从堆栈中弹出一个值,然后将此值作为即将要执行的下一条指令的地址,即跳转回函数调用前的点。如果在call之前堆栈有被正确设定,ret就能正常返回。 -
enter、leave: 保护现场和恢复现场的命令
9. 调用libc函数规范
- 参数从左到右,依次使用
RDI、RSI、RDX、RCX、R8、R9寄存器传递参数 - 如果还不够,参数从右到左依次入栈
- 返回值
RAX或RDX:RAX















 726
726











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









